-
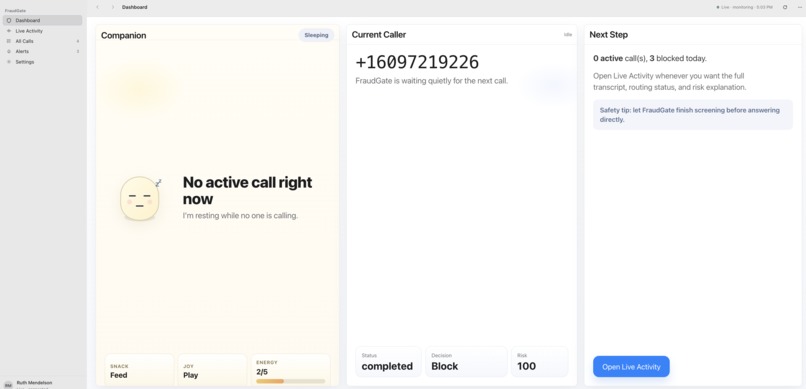
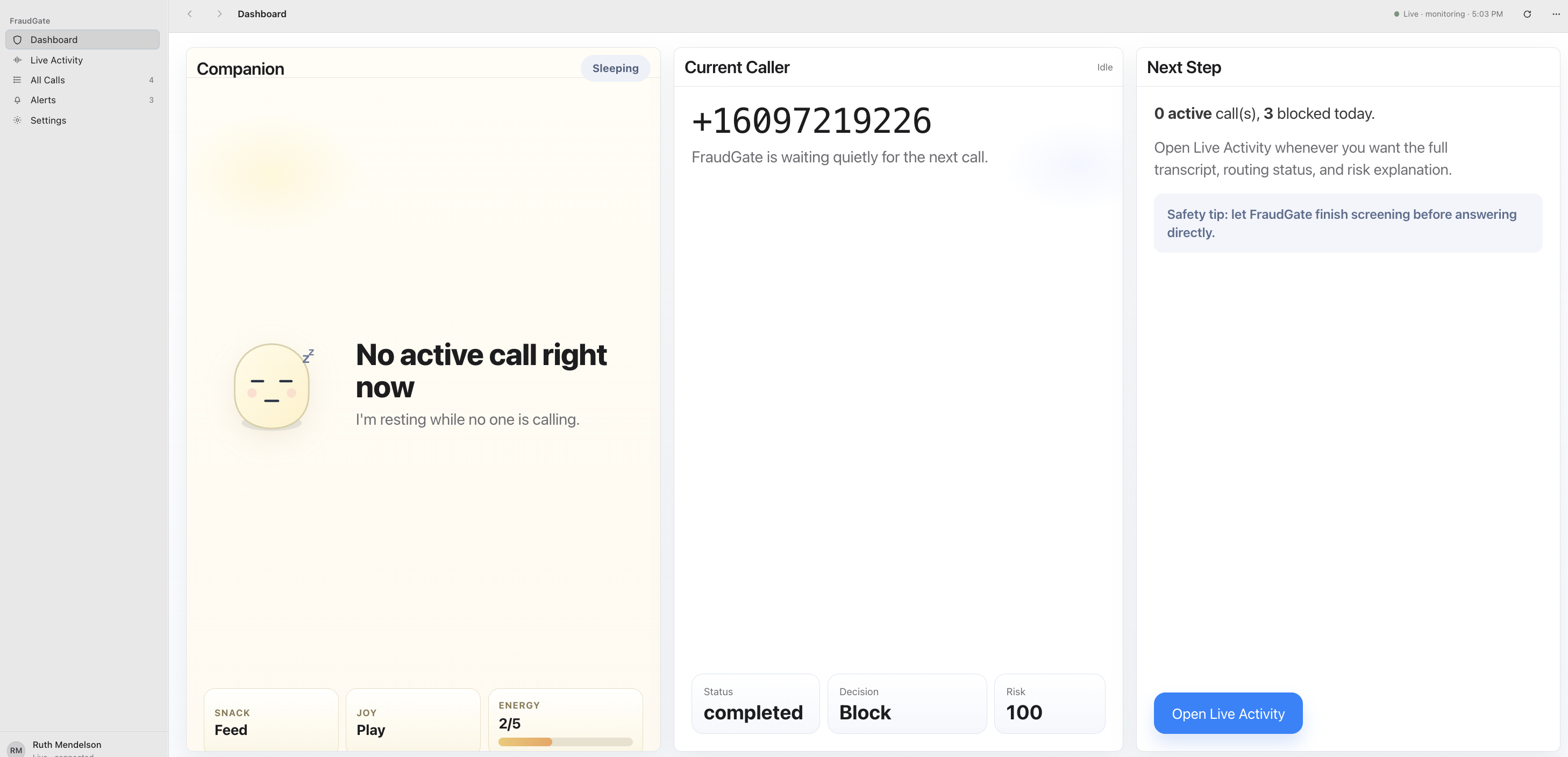
The dashboard
-
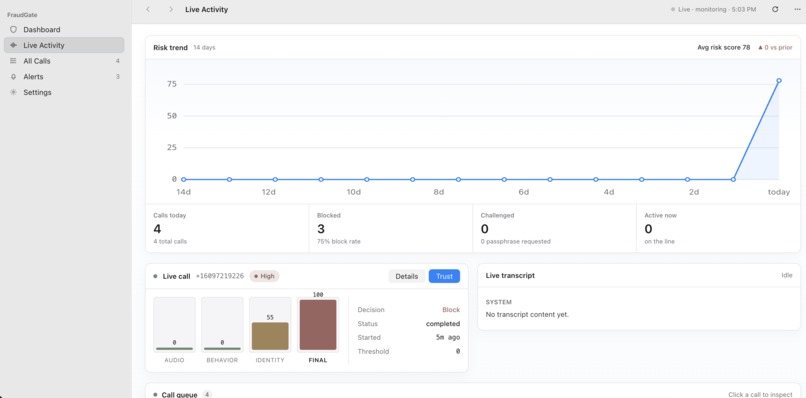
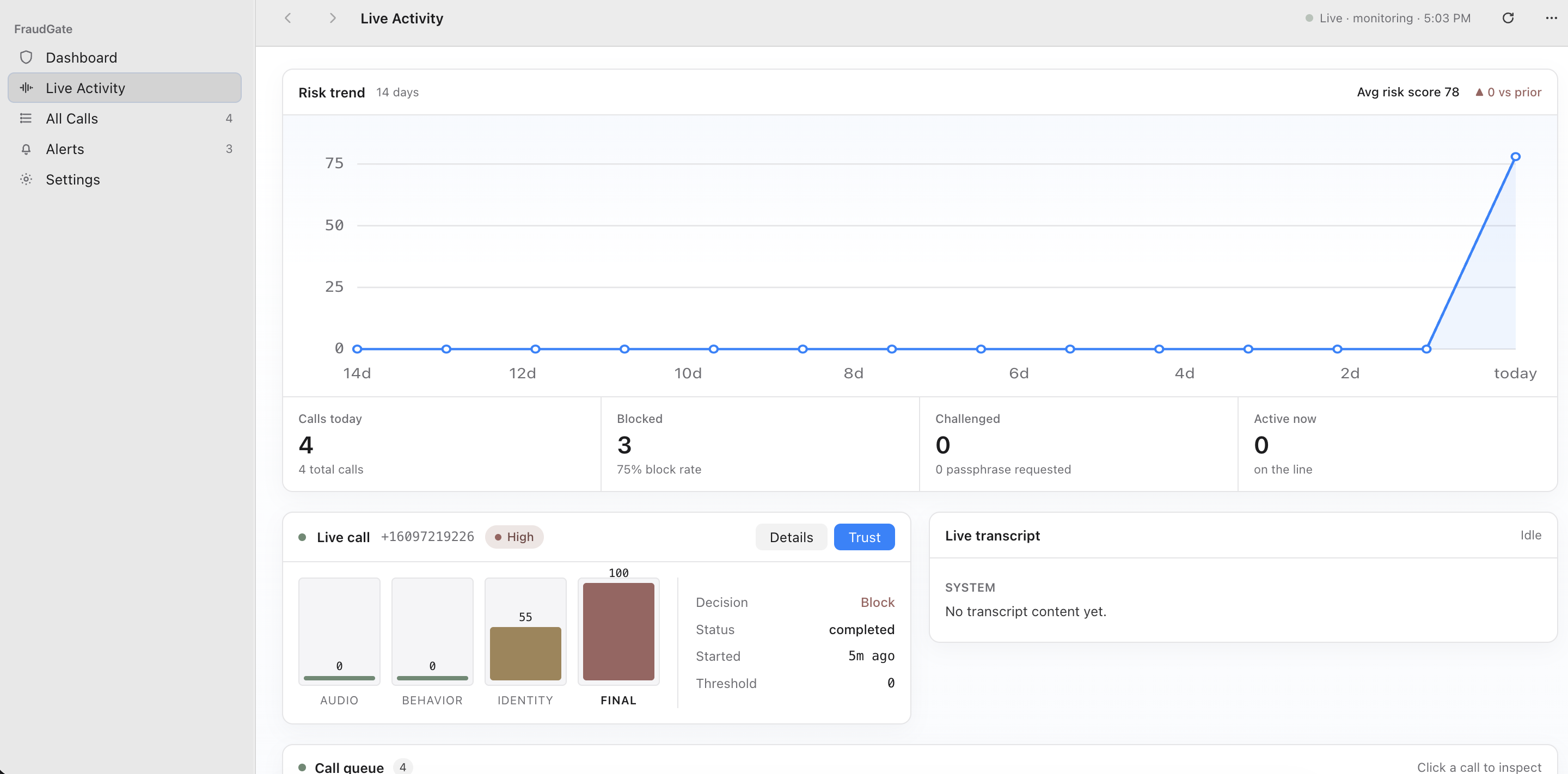
Analytics
Video Link This is the YT channel. Click on it and find the RidgeHacks2026 video! Thanks
Inspiration
FraudGate was inspired by the growing threat of AI voice scams, especially against elderly people. Voice cloning can now make a scammer sound like a family member, a bank representative, or an emergency contact. The most dangerous part is that these scams do not just trick technology. They exploit trust, fear, and urgency.
The idea came from a real family-style scam scenario where a cloned voice pretended to be a loved one in trouble. That made the problem feel urgent: people should not have to personally detect deepfakes during a stressful phone call. They need a protective layer before the call reaches them.
What it does
FraudGate is an AI voice authenticity system that screens calls and estimates whether a voice was likely produced by a real human body or generated synthetically.
Instead of only asking whether a voice sounds fake, FraudGate asks whether the speech follows the biology and physics of human speech production.
It analyzes features such as:
- Pitch contour
- Jitter
- Shimmer
- Formants
- Energy envelope
- Pause timing
- MFCCs
- Delta MFCCs
- Delta-delta MFCCs
These features represent vocal fold vibration, vocal tract resonance, breathing rhythm, and articulation movement.
The system outputs:
- Human probability
- AI probability
- Risk flags
- A decision such as connect, challenge, or block
How we built it
We designed FraudGate as a call-screening and voice-authenticity pipeline.
First, incoming audio is captured as a waveform. The waveform is broken into short time windows and analyzed in frequency space. From there, we extract speech-science features connected to human anatomy and biomechanics.
The model architecture is dual-stream.
One stream analyzes raw audio directly using a deep acoustic encoder. The second stream analyzes explicit biomechanics-based features such as pitch, formants, MFCCs, jitter, shimmer, and timing patterns. These two streams are fused into a classifier that outputs human vs AI probability.
For the prototype, we focused on proving the full pipeline:
- Live or simulated call audio
- Feature extraction
- Risk scoring
- Explainable flags
- Dashboard-style output
The long-term model is designed to train on real human speech, synthetic speech, and eventually articulatory datasets such as X-ray, MRI, or EMA speech data.
Challenges we ran into
The hardest challenge was making the project scientifically credible without overclaiming. Deepfake voice detection is an arms race, and no system should claim perfect detection. We had to frame FraudGate as a risk-screening system that uses biological evidence, not as a magic detector.
Another challenge was connecting human anatomy to machine learning in a practical way. Features like formants, jitter, shimmer, and MFCC dynamics are meaningful, but they need to be converted into stable numerical inputs for a model.
Live call integration was also challenging because phone audio is low quality. Real calls include compression, low sampling rates, background noise, packet loss, and microphone distortion. That means the model has to work under realistic phone conditions, not just clean audio files.
Accomplishments that we're proud of
We are proud that FraudGate connects computer science with speech biology in a meaningful way. The project is not just a chatbot or generic classifier. It is based on the physical process of human speech: lungs, vocal folds, vocal tract resonance, tongue movement, jaw motion, and timing constraints.
We are also proud of the dual-stream model design. Combining raw audio learning with explicit biomechanics features makes the system more explainable and more defensible.
Another major accomplishment was designing FraudGate as a practical safety product. The goal is not only to detect AI voices in a lab. The goal is to stop dangerous calls before they reach vulnerable users.
What we learned
We learned that human speech contains much more information than words. A voice carries physical evidence of how it was produced.
We learned how pitch, formants, MFCCs, jitter, shimmer, energy, and pauses can represent different parts of the speech system.
Pitch relates to vocal fold vibration. Formants relate to vocal tract shape. MFCCs summarize the spectral fingerprint of speech. Delta and delta-delta MFCCs capture movement and acceleration over time.
We also learned that current call-screening systems mostly focus on spam, unknown numbers, robocalls, and transcripts. FraudGate is different because it focuses on whether the voice itself is authentic.
What's next for FraudGate
Next, we want to train and evaluate a real production-grade model on large datasets of bona fide human speech and synthetic speech.
We also want to add phone-call augmentation so the model learns from realistic call conditions like:
- 8 kHz audio
- μ-law compression
- Background noise
- Packet loss
- Low-quality microphones
A major future step is using articulatory speech datasets, such as X-ray, MRI, or EMA data, to teach the model what biologically plausible tongue, jaw, lip, and vocal tract movement looks like.
We also want to expand the call-screening system so it can integrate with real phone infrastructure, support caregiver alerts, challenge suspicious callers with verification questions, and protect elderly users from cloned-family-member scams in real time.
FraudGate’s long-term goal is to become a voice authenticity layer for phone calls: not just asking who is calling, but whether the voice itself can be trusted.
Built With
- javascript
- python
- tensorflow
- ts


Log in or sign up for Devpost to join the conversation.