-

Design of the expertise part
Lauzhack 2017 - Credit Suisse Money Laundering Pattern Recognition Algorithm
Github Folder: https://github.com/glederrey/lauzhack_2017 Last hash: 53d47808a2c861168224d326d98597ae738b83da
Introduction
Our project aims to provide a prototype of a solution for money laundering detection. Our approach is a mixture of heuristics and machine learning and features a combination of unsupervised methods and human supervision.
In general, human supervision has the potential to greatly improve recognition. However, creating a large dataset of labeled instances is not only difficult, costly and time-consuming, but sometimes even impossible. However, it is possible to create approaches that feature a feedback loop: the system generates some results in an unsupervised manner, a user (who is an expert in the field) reviews some of the results and gives feedback on them, and the system attempts to improve its recognition based on that feedback.
In the following sections, we will first describe the general methodology of our idea and then proceed to the parts we have actually implemented. We will also discuss how our solution can scale with the data.
Overview of approach
Our approach consists of two parts: an unsupervised, largely rule-based system which detects "suspicious" clients, i.e. those who are, according to our criteria, more likely to be engaged in money laundering, and a feedback part which receives feedback from an expert in the field.
Our method basically assumes the existence of three types of laundering schemes:
- The "cycle" scheme, where a chain of clients circulate an almost constant amount of money (except for minor decreases for 'fees') in a very short time frame (hours or a few days) back to the client who originally started the chain of transactions.
- The "path" scheme, where a chain of clients send almost the same amount of money to a destination within a short time frame.
- The "time" scheme, where a client repeatedly sends an almost constant amount of money to the same destination.
We also consider a more complicated case of the cycle scheme, in which a client circulates their money through different cycles instead of a single cycle of almost constant value. This case is much more complicated than the original cycle case, but we will come up with a simple heuristic to detect some of these types of fraud.
Unsupervised "Suspicion Scores"
Finding all the paths and all the cycles in a graph is highly costly and unscalable. What we need is a measure that can help us prune our space, enabling us to run our path or cycle detection algorithms only on certain vertices or subgraphs. This is the idea behind suspicion scores.
The classification of a client as suspicious as per each of the schemes is made using rule-based criteria. The criteria are as follows:
- For the cycle case, an outgoing transaction, earlier and slightly greater than an incoming transaction of almost equal value, makes a client suspicious. What would make them even more suspicious is sending/receiving this money to/from another client which is "financially distant" from them, i.e. not among the clients they usually send to or receive from. This financial distance is calculated based on Node2Vec, a method for creating vector representations of graphs that builds upon the famous Word2Vec and attempts to create embeddings that put neighbouring nodes closer together in the latent space. For the more difficult case of having a smart launderer with multiple cycles around them, we try to aggregate their transactions in a set time frame and see if they had a great amount of money circulation without a considerable change in their account's credit; however, this is obviously not a complete solution since the problem is likely NP-hard (we couldn't analyse it completely in the limited time of the challenge).
- For the path case, it is based on the "inner nodes" of the path - namely clients who receive an amount of money and send most of it away very quickly. Obviously, this will have some overlap with the cycle case, since all the clients except the client starting the transaction chain will be behaving in the same way.
- For the time scheme, we will simply look for quickly repeated transactions between a pair of clients.
Obviously, this system supports the addition of more criteria for building the suspicious list and the suspicion scores.
The top-ranking members of the suspicious lists then can be given to graph algorithms to actually attempt to find paths/cycles for them. In addition, a total suspicion score equaling a weighted sum of suspicion scores (not implemented in our work here) will be used to create a final ranking of all the suspicious clients; they will then be presented to the expert, ordered based on their total suspicion score.
Expert feedback
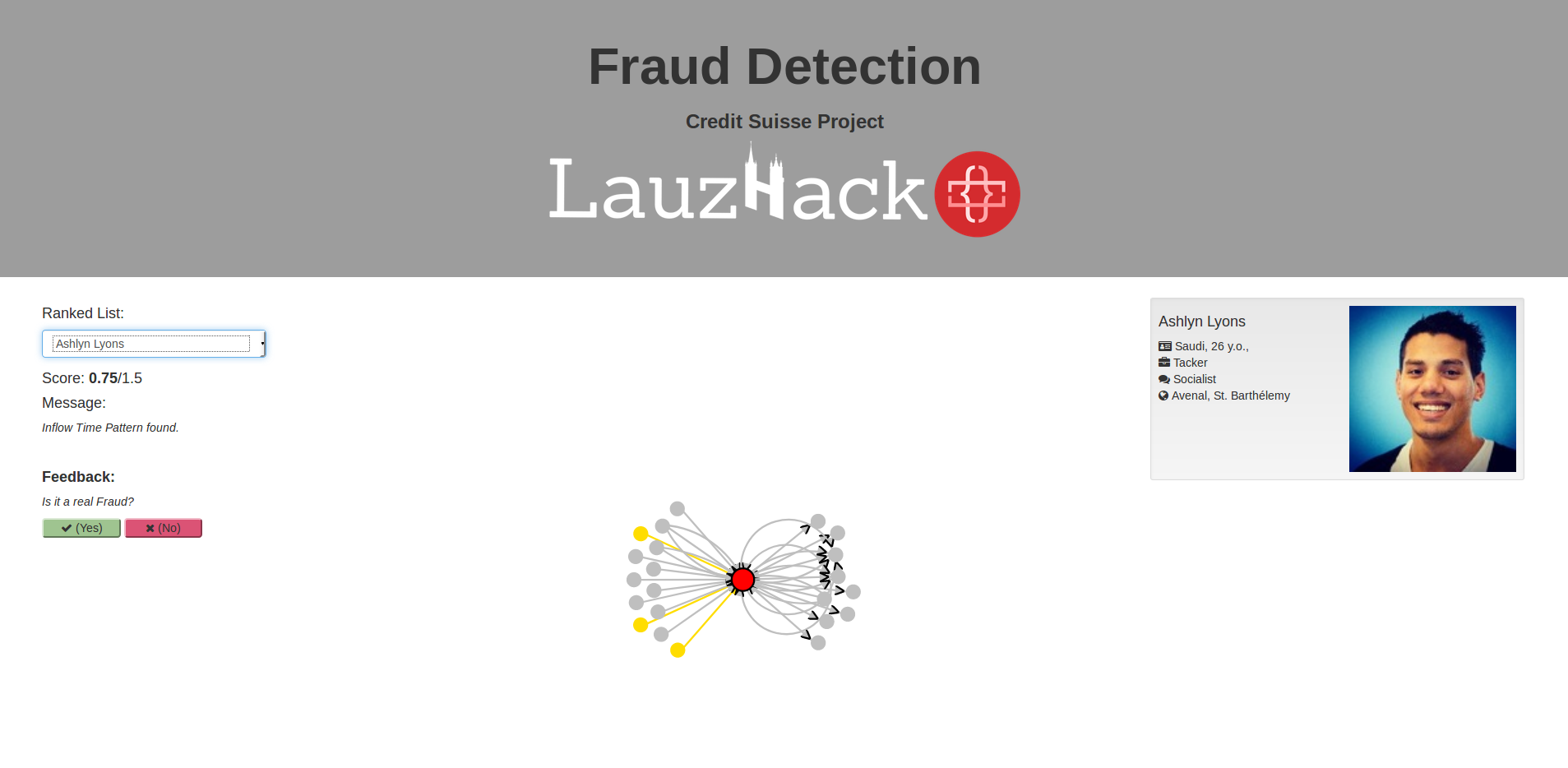
An essential part of our method is the visualisation of the suspicious lists, which we have done using D3 and JavaScript and can be viewed at http://178.62.87.199/lauzhack_2017/viz/index.html. The expert can view each suspect, their total suspicion score, and an extraction of the graph around their node (which in case of the very top ranking ones will also include extracted cycles/paths, depending on which suspicion criteria they satisfied). The expert is then presented with an option to provide feedback on that suspect; they can either classify it as actually criminal or as innocent, or they can leave it be. The system in its complete version will take these as labels, and adjust the weights of the scoring criteria to be able to rank the criminals higher in its lists.
Results
Our results based on a comparison between actually computed cycles and the suspicious list for the cycle scheme show that this rule-based scheme actually has relatively good recall of the real cycles and also provides us with relatively few suspicious clients, so the method can be expected to be scalable. We expect that an implementation using Apache Spark will enable our solution to scale relatively well.

Log in or sign up for Devpost to join the conversation.