-
-
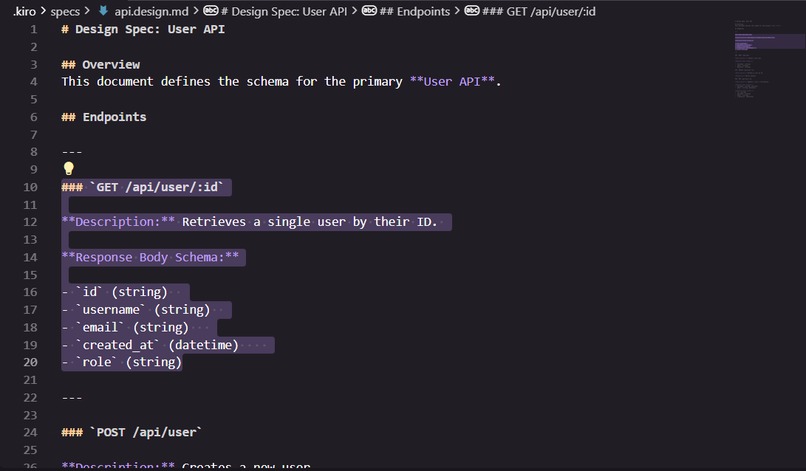
FrankenSpec Design Document (User API)
-
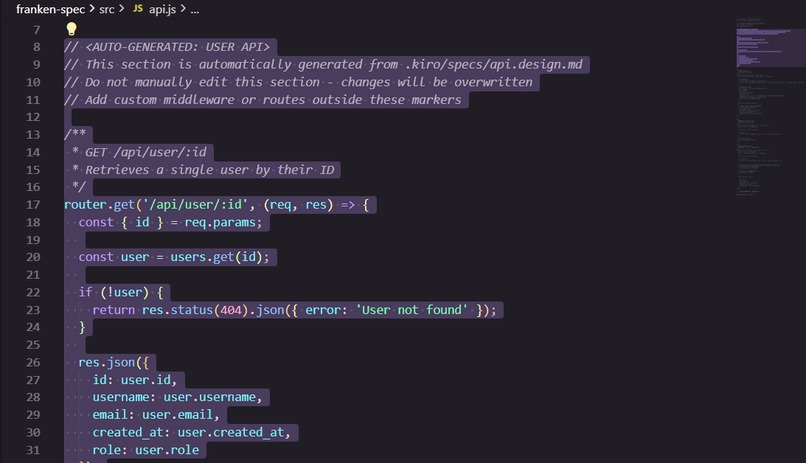
Auto-Generated Express API from FrankenSpec
-
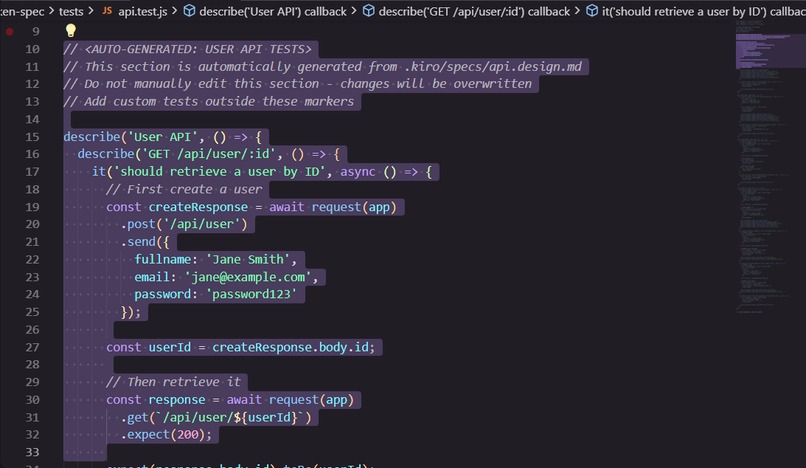
Auto-Generated Test Suite (User API Tests)
-
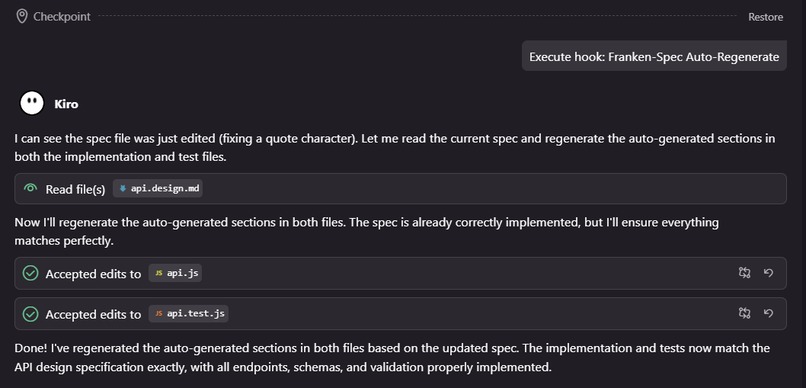
Real-Time Code Regeneration via FrankenSpec Hook




Inspiration
Modern API development moves fast, but documentation often drifts away from implementation. Teams continuously update schemas, endpoints, and data models, yet the source code and tests rarely keep pace. The result is Spec Drift — broken assumptions, unclear contracts, failed integrations, and onboarding delays.
FrankenSpec was inspired by the belief that design specs should be executable and enforceable, not static text.
What it does
FrankenSpec turns a simple Markdown design document into a living source of truth. Whenever a spec file is modified and saved, FrankenSpec automatically:
Reads the API specification.
Regenerates the corresponding source code inside your implementation files.
Regenerates the associated test files with full coverage.
Updates only the regions between AUTO-GENERATED markers, preserving all custom logic.
As a result, design, implementation, and tests remain synchronized automatically, without manual rewrites.
How we built it
We combined three key components:
A design spec format using Markdown (*.design.md) to define endpoints, request schemas, response schemas, and behaviors.
A Kiro hook that listens for “file saved” events and triggers code generation.
A regeneration engine that:
Reads the updated spec.
Finds the matching code and test files.
Regenerates only the AUTO-GENERATED regions (not full overwrite).
Ensures endpoints, schemas, and validation logic match the spec exactly.
Generates comprehensive tests automatically.
This architecture ensures that engineers write specs once, and the rest of the system stays aligned.
Challenges we ran into
Ensuring that regenerated code never overwrites custom logic outside AUTO-GENERATED markers.
Making the hook reliably detect file saves and trigger correctly inside Kiro.
Designing a usable format for specs that is simple enough for humans but expressive enough for automation.
Ensuring tests reflect real API behaviors (validation, partial updates, 404 conditions, etc.).
Accomplishments that we're proud of
We achieved true auto-sync between specs, implementation, and test coverage.
We proved that Markdown documents can become executable truth sources, not merely documentation.
We eliminated hours of manual rewriting that teams normally spend updating both code and tests after spec changes.
We demonstrated a framework that could evolve into a universal standard for iterative product development.
What we learned
Code generation is powerful only when it respects real workflows, meaning: partial rewrites, stable boundaries, and full preservation of custom code.
Developers are more productive when specs are not passive, but active artifacts that enforce correctness.
API evolution becomes dramatically safer and faster when both code and tests are tied directly to spec changes.
What's next for FrankenSpec
Support for multi-service specs, aggregation, and shared schemas.
Support for database migrations, data models, and event schemas.
CI integration to automatically:
Reject PRs when implementation diverges from spec.
Block merges if tests or contracts are missing.
UI layer for real-time visualization of drift and auto-fixes.
Expand beyond REST APIs into GraphQL, events, internal service contracts, and async workflows.
Built With
- express.js
- javascript
- kiroide
- markdown
- mcp
- mocha
- node.js
- supertest

Log in or sign up for Devpost to join the conversation.