-
-
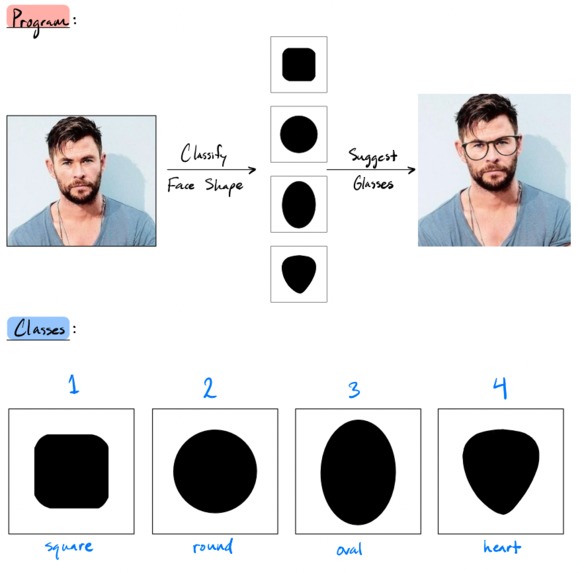
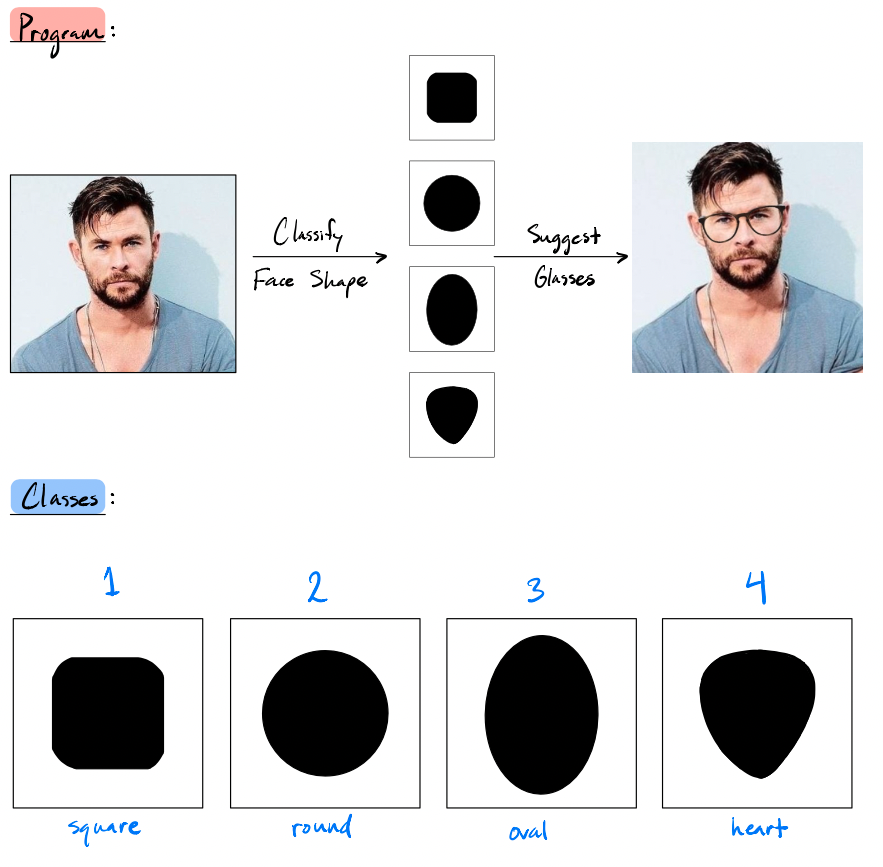
Classification of face shape
-
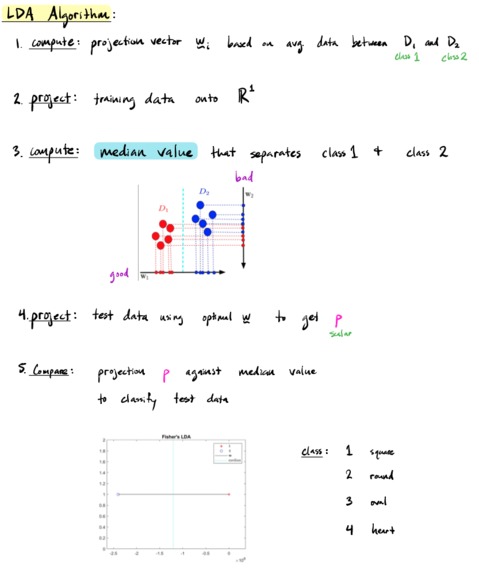
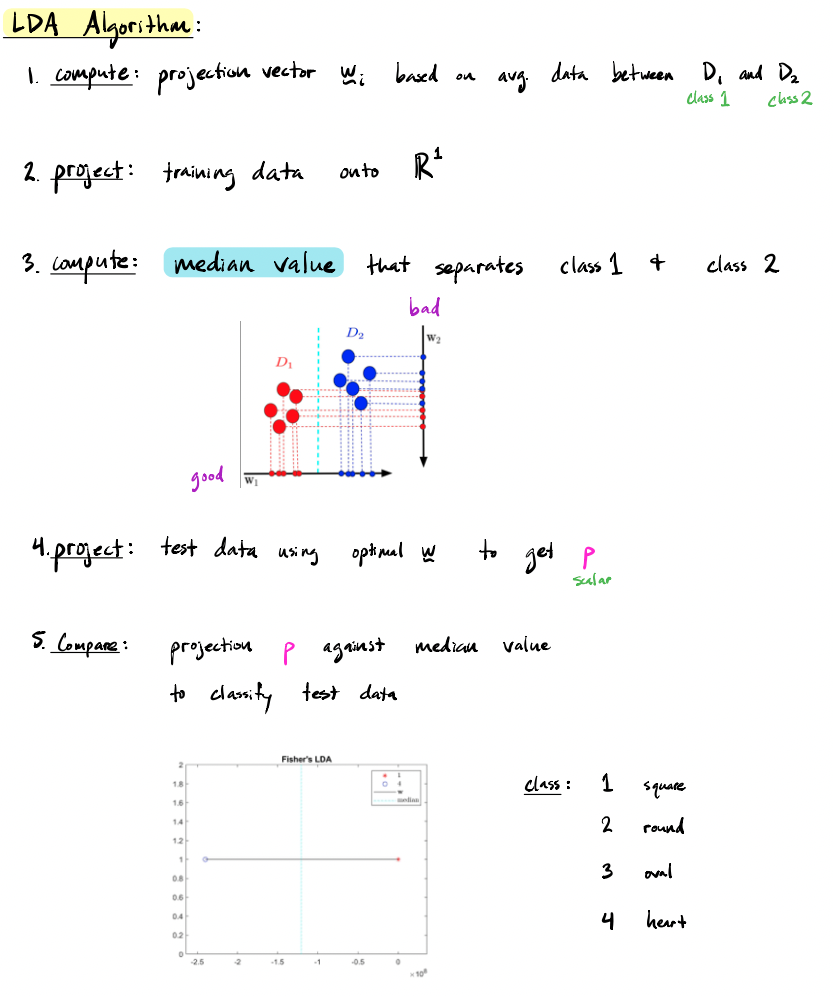
LDA technical explanation
-
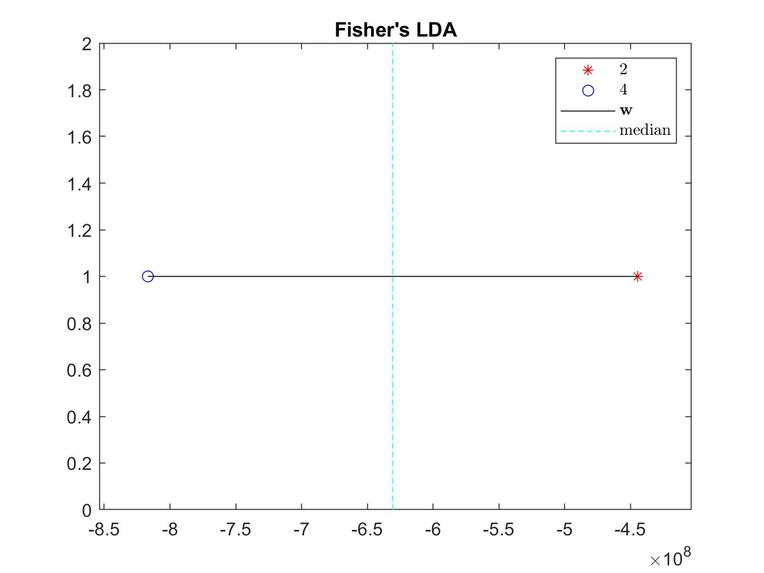
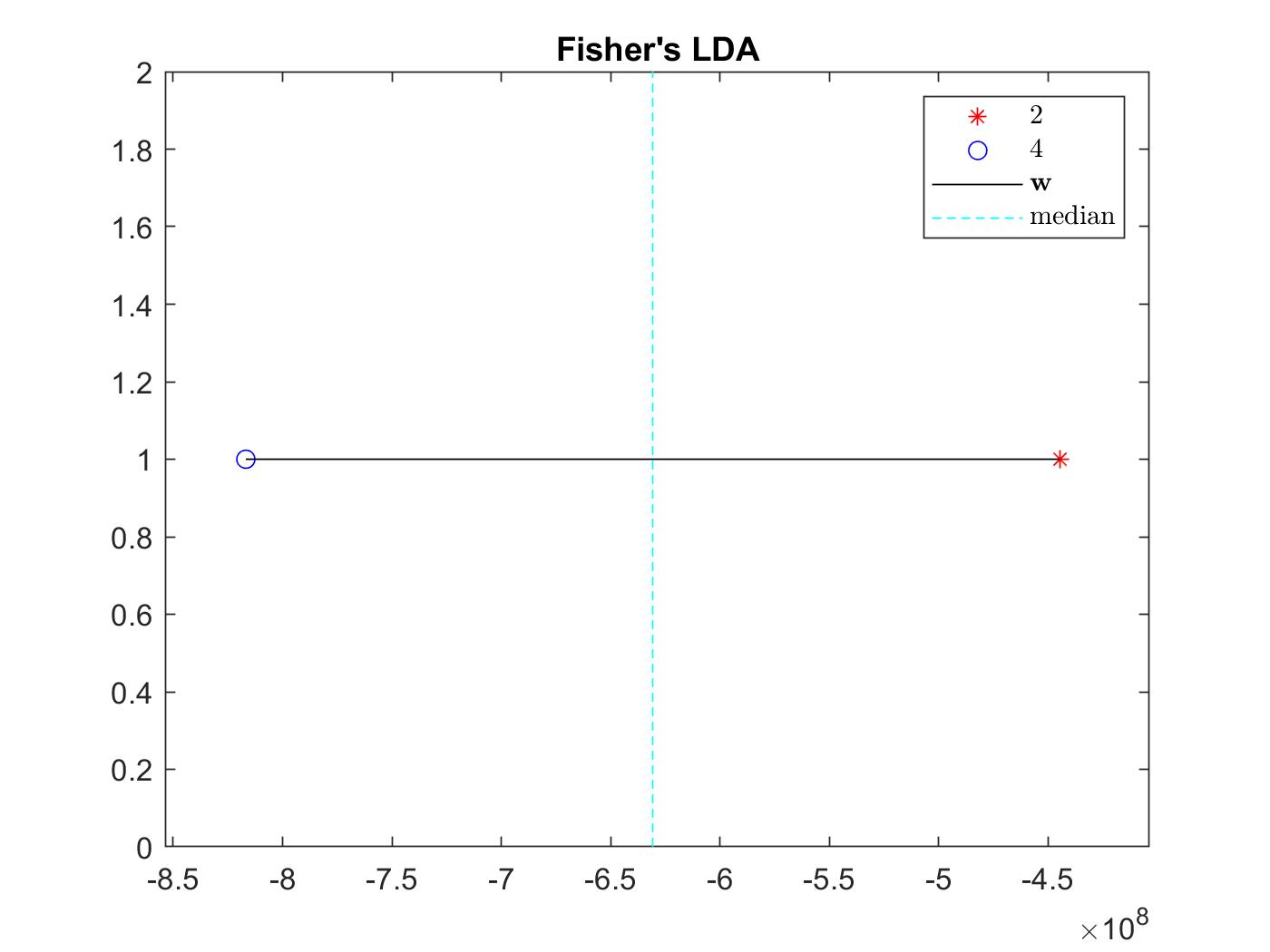
An example of an LDA projection. 2 represents a round face shape and 4 represents a heart face shape. The dotted line represents the median.
-
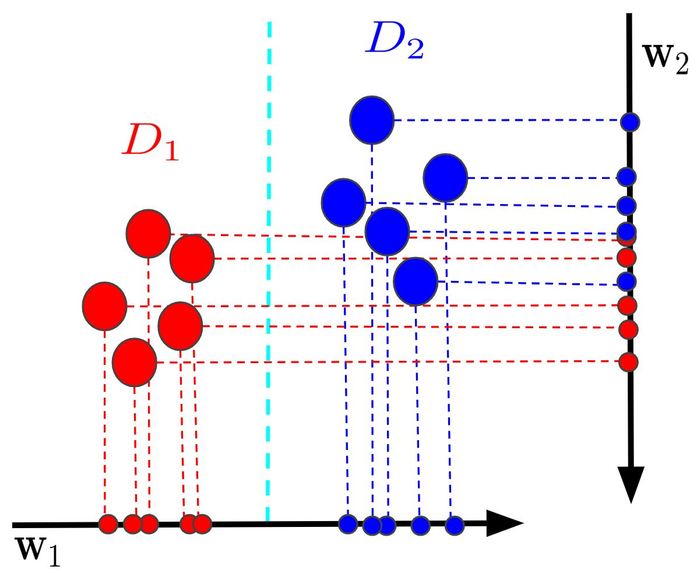
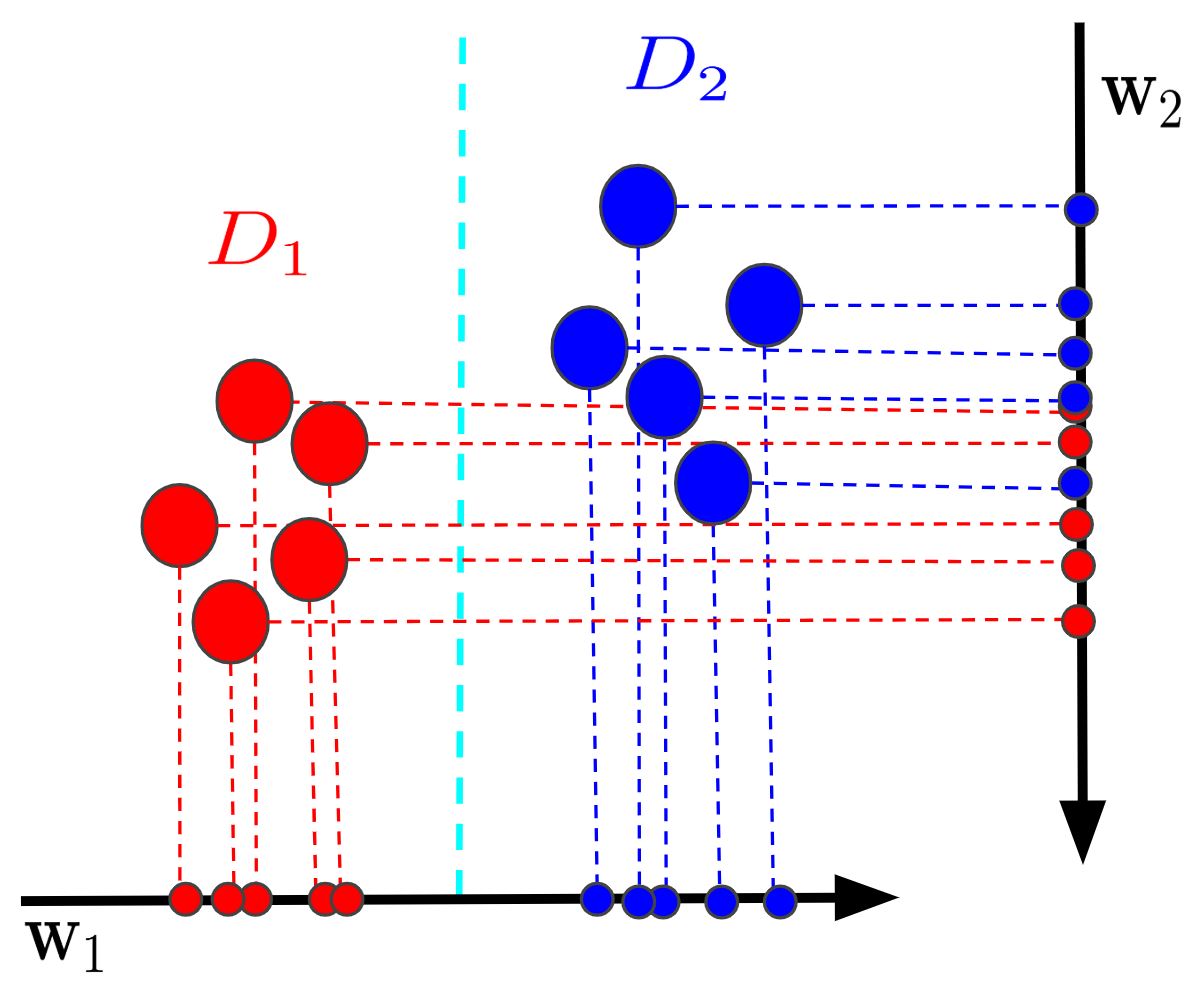
W1 and W2 represent examples of different projection models. W1 is a better projection model because D1 and D2 are in distinct groups.
-
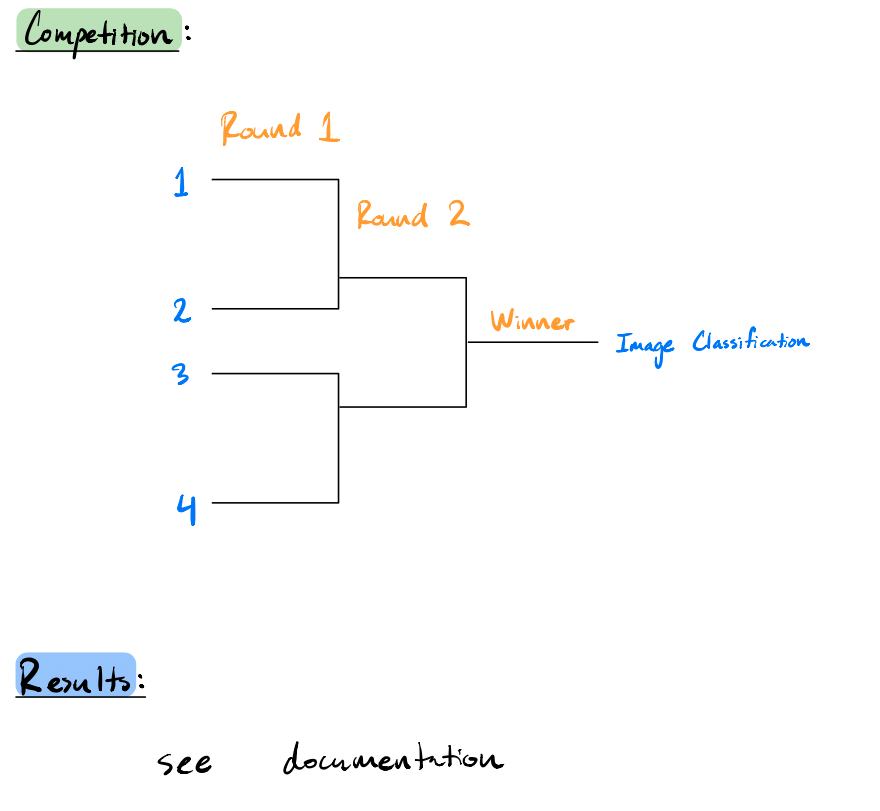
Tiered-bracket results
-

Data for our test datasets. Recognize anyone?

Inspiration
Math, glasses, and AR!
- Consumers try on lots of glasses because they are unsure of their face shape and what frames best suit them
- Mathematical models that classify and categorize different entities
- Instagram and Snapchat AR filters that use faces as targets
What it does
Our product
An algorithm written in Matlab that can classify and determine a face shape (round, oval, square, heart)!
Our project aims provides a dynamic solution for problems that glasses retailers and glasses consumers face.
Problems relevant to a glasses consumer
- Difficult to discern face shape (round, oval, heart, square, etc).
- Difficult to find glasses frame that suits face shape → have to try on a lot of glasses.
- During a pandemic, consumers don’t want to go to a brick and mortar store to try on glasses.
Problems relevant to a glasses retailer
- During a pandemic, there may be less consumers going to a brick and mortar store. Our product allows a consumer’s online shopping experience more holistic. Current glasses frames AR allow consumers to try on frames, but may not suggest frames based on a face shape.
- Brick and mortar stores can only contain a finite amount of glasses to try on. Retailers may have a lot of additional or limited frame styles that they can sell
Our solution
- Glasses retailers can use integrate our dataset and algorithm onto their website or app to classify a consumer’s face shape and suggest ideal frames.
How we built it
- Make data sets for each face shape.
- Used ZenniOptical's Finding the Best Glasses for Your Face Shape guide to determine what shapes we wanted to classify our faces into (round, oval, square, heart).
- Found 10 images each shape (minimum)
- Standardized images to correct dimensions
- convert images to black and white, 400 x 400px, .tiff file format
- Created standard shapes for face outline in Procreate
- Used Matlab to perform Linear Discriminant Analysis (LDA)
- See this PDF for more information about the technical aspects that we implemented!
- Created classification algorithm to sort each image into the four face shapes
- Set up training data for each class that we pre-categorized
- Computes the projection vector and median value that separates each class
- Classify new test images (including Cody the Crab, Byte the Shark, and Crypto the Clam) not already in our datasets using the training data
Challenges we ran into
- Traning dataset
- We used Google Image Search and found bias. For example, when searching for "round face", the results contained a lot of homogenous images of women celebrities.
- Had to have a criteria for a good image. We had to consider how hair, facial hair, emotions (smiling vs. not smiling), glasses would affect our training dataset.
- When building our dataset, we had to arbitrarily classify what face shape we though a face was.
- We had to standardardize and format our images before entering them in our dataset. Luckily, we both had iPads with Procreate that we could use for image editing but this toil could be reduced with ML in the future.
- Algorithm
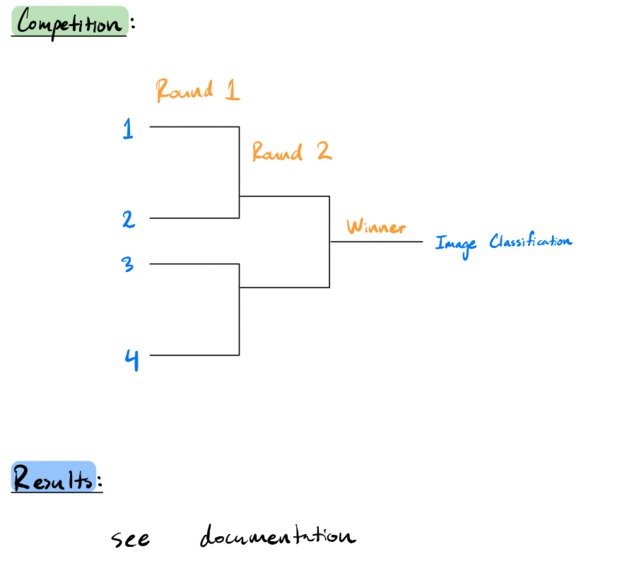
- LDA can only be used to classify between two classes, but we had four classes. As a workaround, we implemented a tiered-bracket system with multiple rounds. Each round represents comparing the data between two different classes. The final winner would be considered the final classification of the image's face shape. With four classes, each image would have to be compared against three pairs of datasets.
Accomplishments that we're proud of
- This was each team member's first hackathon!
- Peer programming! We learned how to work together and bounce ideas off of each other.
- Our project plan. Before jumping into the technical bits, we created a Notion page with assigned tasks, minimizing toil and vagueness.
- Our business plan and insight into future expansions. We recognized that our product could be marketed to both retailers and consumers.
- We increased our graphics and image manipulation skills via Procreate.
What we learned
- Creating a training dataset can be biased, arbitrary, subjective, and time-consuming. Using ML and AR can reduce the subjectiveness.
- The larger the training dataset, the better. When we increased our training dataset from 10 to 11 images our category, our accuracy increased from 25% to 33%!
- For example, in classifying cats vs. dogs, LDA algorithm can have around 95% accuracy when using 90 images of cats and 90 images of dogs in our training dataset.
What's next for Find Your Main Frame
Future feature releases will include a front-end AR for consumers with an algorithm that can present ideal glasses and glasses frames sortable by
- cost
- best-selling frames
- limited-edition frames
- for brick and mortar stores: optional smart display that consumers can use in-person
Built With
- excel
- github
- google-drive
- matlab
- notion
- procreate
- teamwork
- zoom




Log in or sign up for Devpost to join the conversation.