-
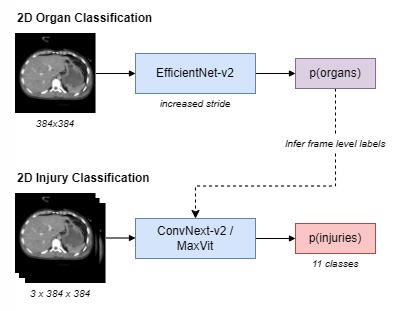
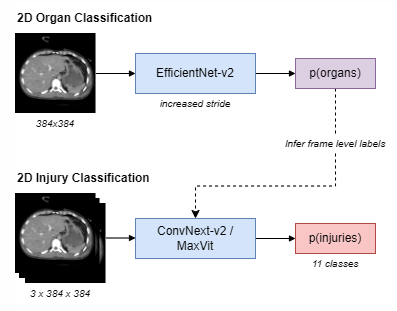
2D Model
-
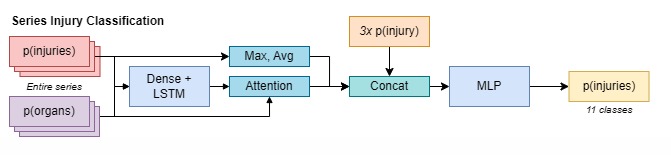
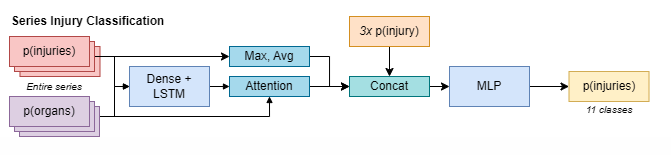
RNN Model
Introduction
The detection of abdominal trauma from Computed Tomography (CT) is an important area in the application of AI in medical imaging. The accuracy of deep learning models in analysis of 3D images heavily depends on the quality and representation of the training data. Therefore, using the appropriate method to sample frames from volumetric CT scans becomes an important step in model training. Different frame sampling techniques are developed to process sequential data types like video, specifically uniform sampling, random sampling, and attention-based sampling. Uniform sampling selects frames at regular intervals throughout the series. Random sampling involves randomly selecting frames to introduce variability into the training data. Attention-based sampling uses attention mechanisms to dynamically select frames based on their relevance. In this project, we aim to investigate these three different frame sampling strategies for the detection of organ-level injuries in abdominal CT scans. Through analyzing and comparing the effects of different sampling techniques on model’s accuracy, robustness, and efficiency, we aim to uncover insights that can inform the development of more effective sampling approaches for abdominal trauma detection.
Related Work
The importance of frame sampling in achieving good model performance on CT scans was noted by Theo Viel in his blog post about working with the RSNA abominable trauma detection dataset. Theo noticed the presence of label noise and repetitive information in 3D CT scans and proposed to use a rule-based approach to sample frames as a pre-processing step. Theo’s pipeline involves using a convolutional neural network model to infer the organs inside every frame, then sample either randomly or uniformly based on the organs type. Theo’s prediction pipeline achieved 2nd place in the RSNA abdominal trauma detection competition.
Data
We will be using a subset of the Abdominal Trama Detection dataset created by the Radiological Society of North America (RSNA) originally for the Kaggle competition of the same name. The dataset contains the abdominal CT scans of patients that captures 11 types of injuries. Two binary injury types bowel and extravasation and three injury types kidney, liver, and spleen with three target levels. The size of the original dataset in DICOM format is about 400GB. We plan to use a 15GB subset dataset conveniently converted to PNG.
Methodology
We aim to investigate and compare three distinct types of sampling strategies - uniform sampling, random sampling, and attention-based sampling - for optimizing the detection of organ-level injuries in abdominal CT scans. First, we will select and preprocess a subset of the RSNA abdominal dataset to ensure compatibility with our limited computing resources. We will then implement the deep learning model pipeline proposed by Theo, which consist a 2D image classification stage and a RNN series classification stage. In the original pipeline, every CT frame is first feed into an EfficientNet to predict which organs are present. Then, frames are sampled and grouped by 3 before they are fed into a ConvNeXt model to predict probability of injuries. Finally, injuries probabilities are extracted for every 1/2 frame and are feed into a RNN model that aggregate the results to produce the probability of injuries of the patient. Cross entropy loss was used as the loss function. The model designed in shown in the images.
Within the same pipeline, we will experiment with three different types of sampling strategies - uniform sampling, random sampling, and attention-based sampling. We think all three methods can have their advantages and disadvantages in presenting informative frames. We will train and evaluate. our deep learning pipeline using each of the frame sampling strategies. After analyzing the results, we want to propose an optimal frame sampling strategy for the use case of abdominal CT scans.
Metrics
We want to evaluate the three sampling strategies based on their accuracy, robustness, and efficiency. We will use classification accuracy and F1-score as an indication of accuracy, performance on noisy dataset as an indication of robustness, and training time as an indication of efficiency. Our base goal is to achieve a classification accuracy similar to the baseline performance of Theo’s existing approach. Our target goal is to be able to produce and analyze experiment results on the proposed sampling strategies. Our stretch goal is to improve upon the baseline performance by integrating the optimal sampling strategy.
Ethics
Advancing AI assisted medical diagnosis systems has the potential to improve equal access to healthcare. Currently, the high initial investment to train medical professionals and the limitation in the amount of doctors' attention are significant barriers to accessible healthcare. AI diagnostic systems have the potential to lower the cost to access high quality healthcare.
The major stakeholders in this project will be the medical professionals and the patient. The result of the model's prediction will have significant implementations for the appropriate treatment for patients. Under high stake medical situations, false negative predictions are more serious than false positive predictions. The first case can be resolved through cross examination with medical professionals, but the latter case might cause the negligence of fatal medical problems.
Group Members:
Yiran Shi ( cs login: yshi28 ); Futao Wei ( cs login: fwei5); Jianjun Zhang ( cs login: jzhan508);
Division of labor
Briefly outline who will be responsible for which part(s) of the project. Yiran Shi, will be responsible for implementing sampling strategies, designing experiments to measure robustness, and report experiment results. Futao Wei, will be responsible for implementing the model training pipeline and designing experiments to measure strategy accuracy. Jianjun Zhang, will be responsible for implementing the model training pipeline and designing experiments to measure strategy efficiency.




Log in or sign up for Devpost to join the conversation.