-
-
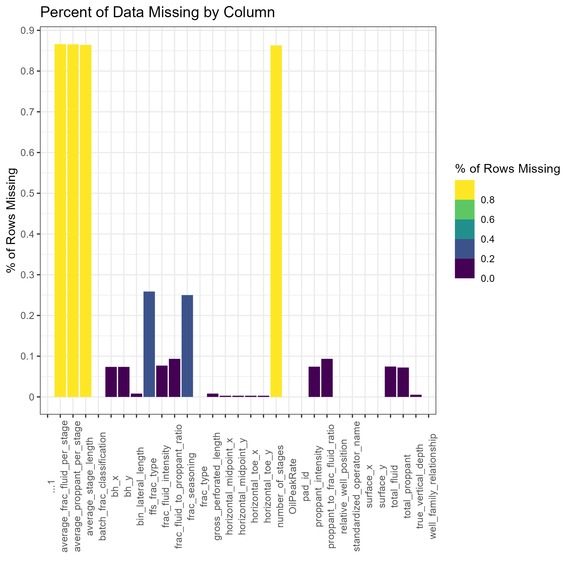
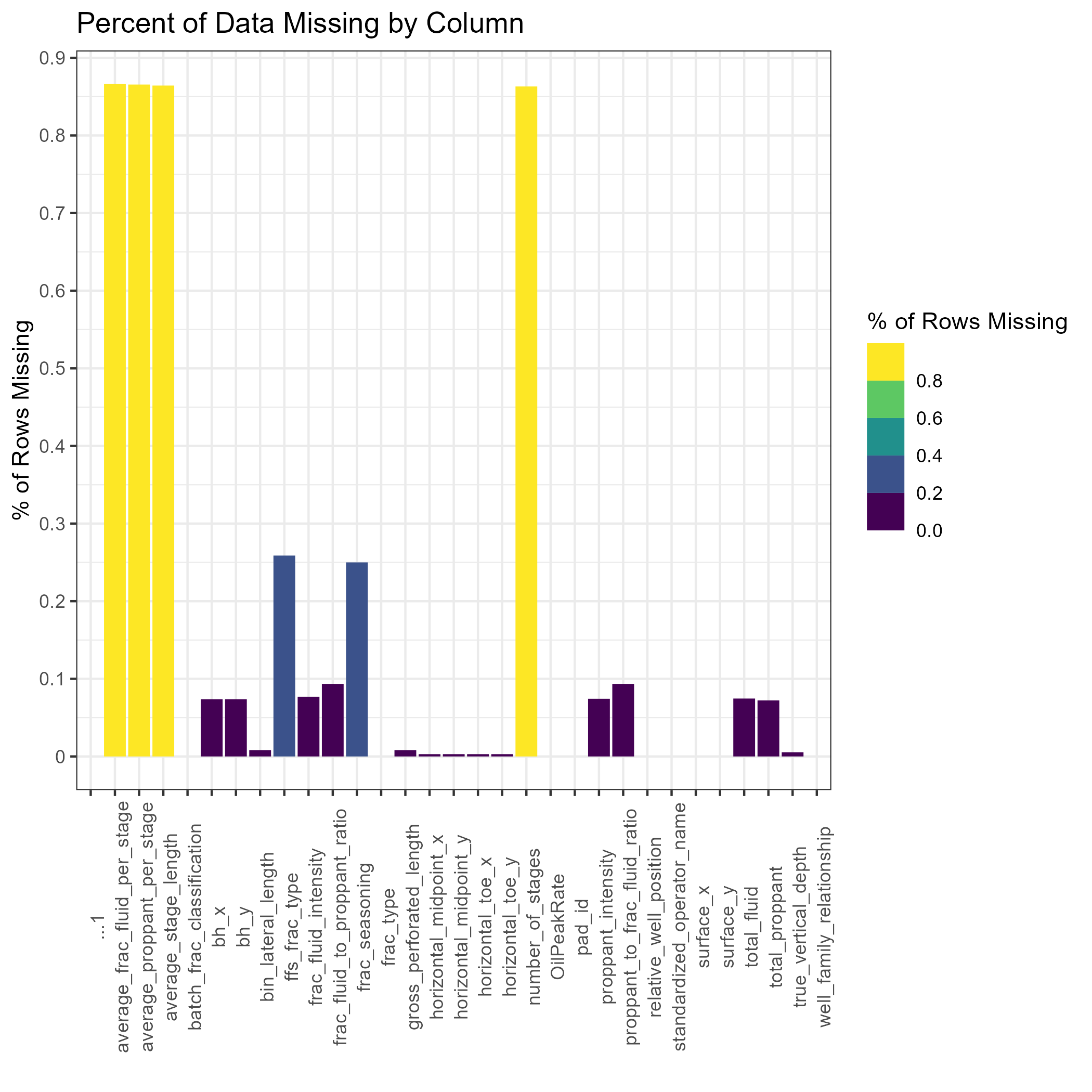
Missing Data by Row
-
-
-
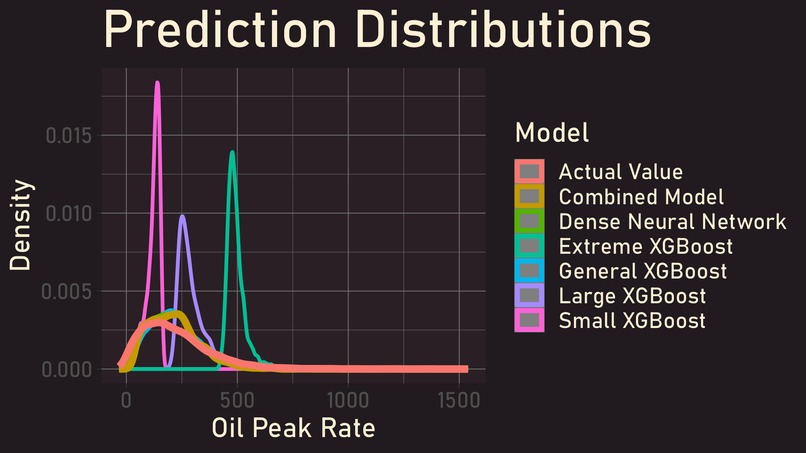
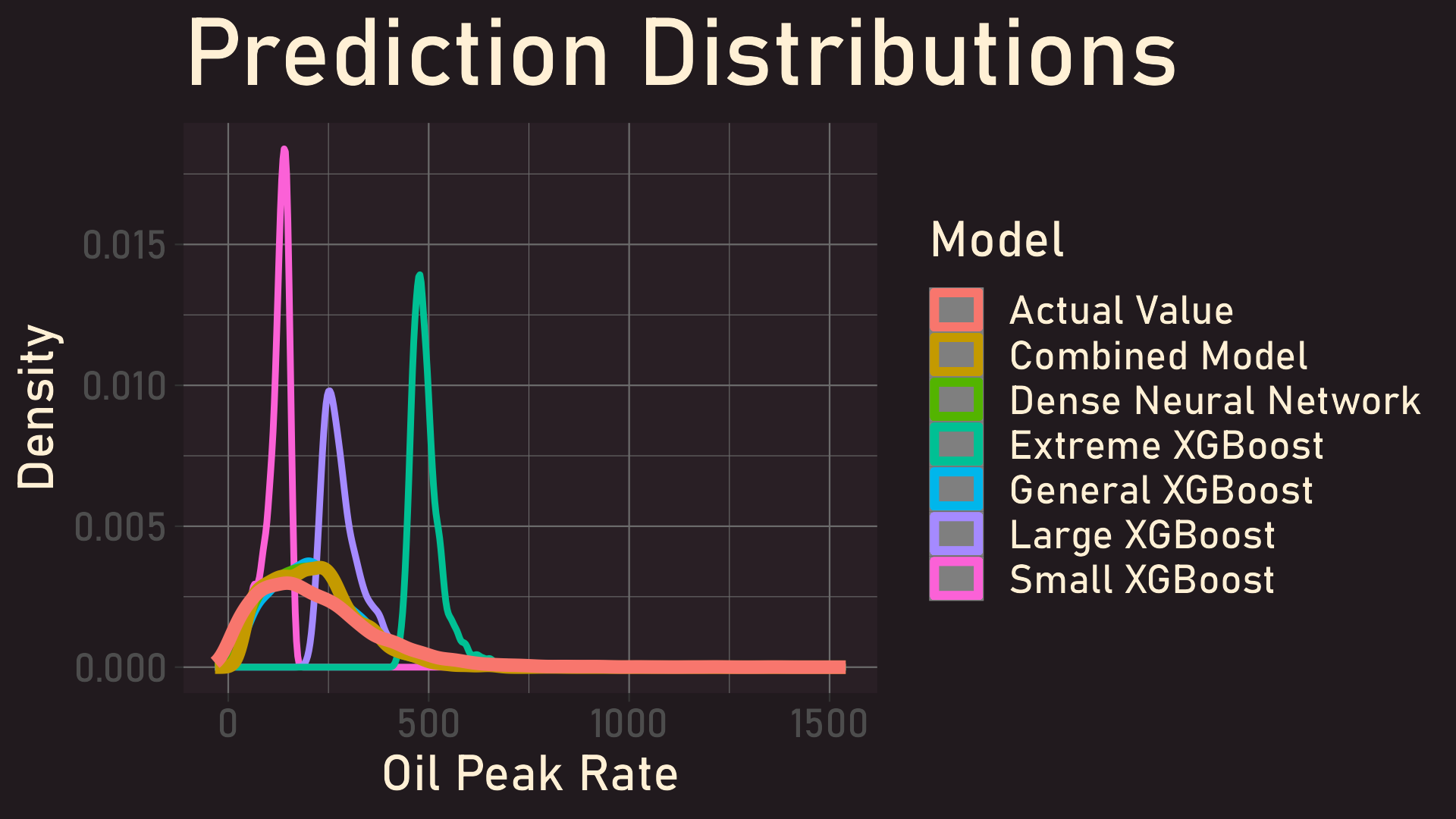
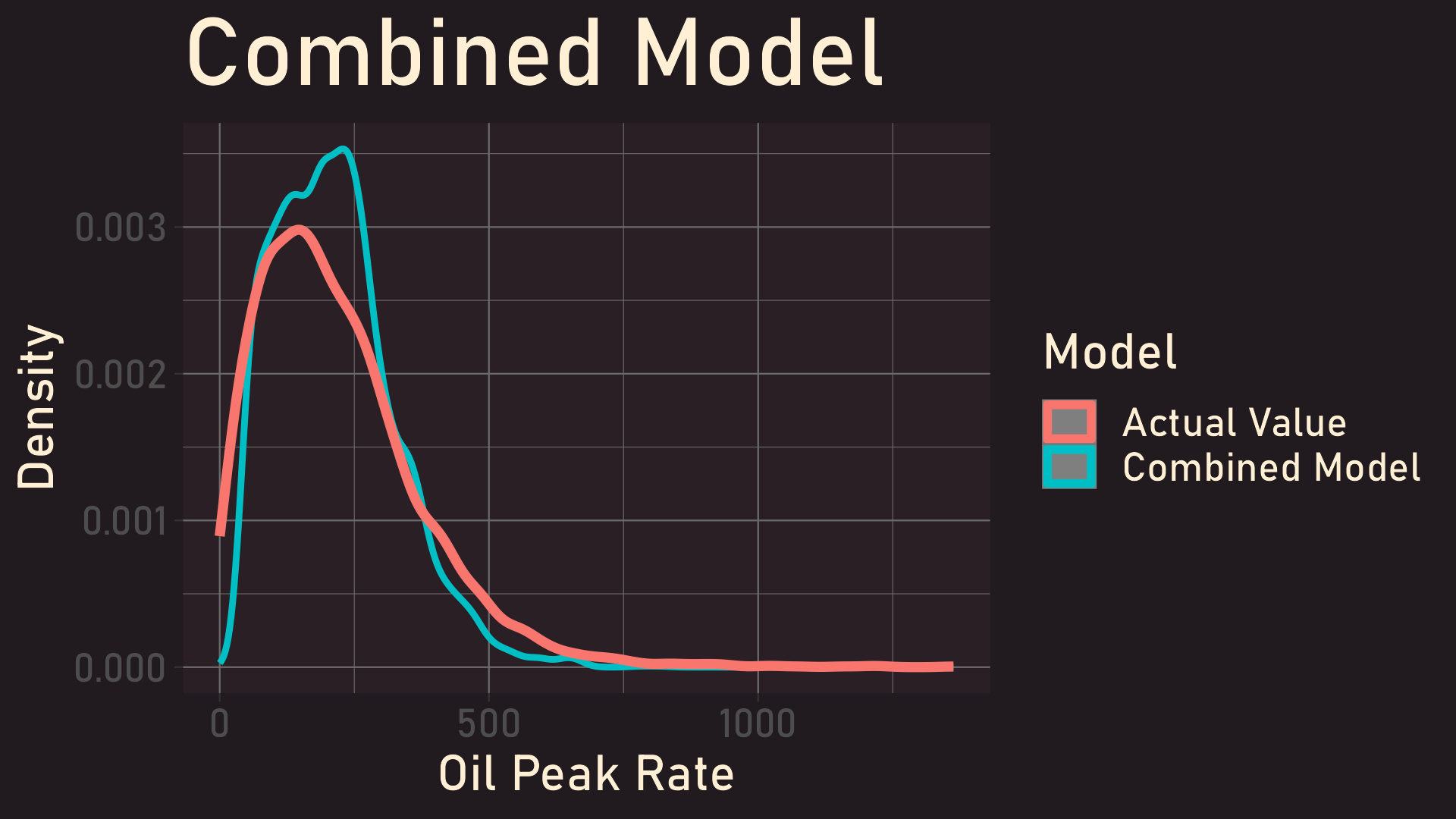
Prediction Distributions on Holdout Set
-
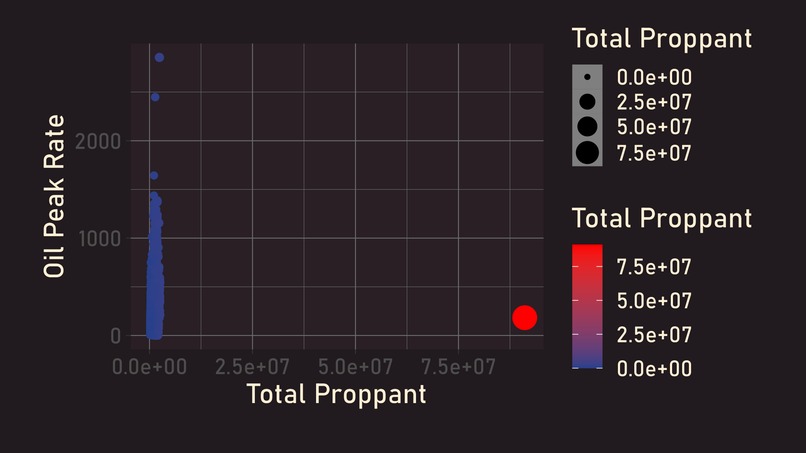
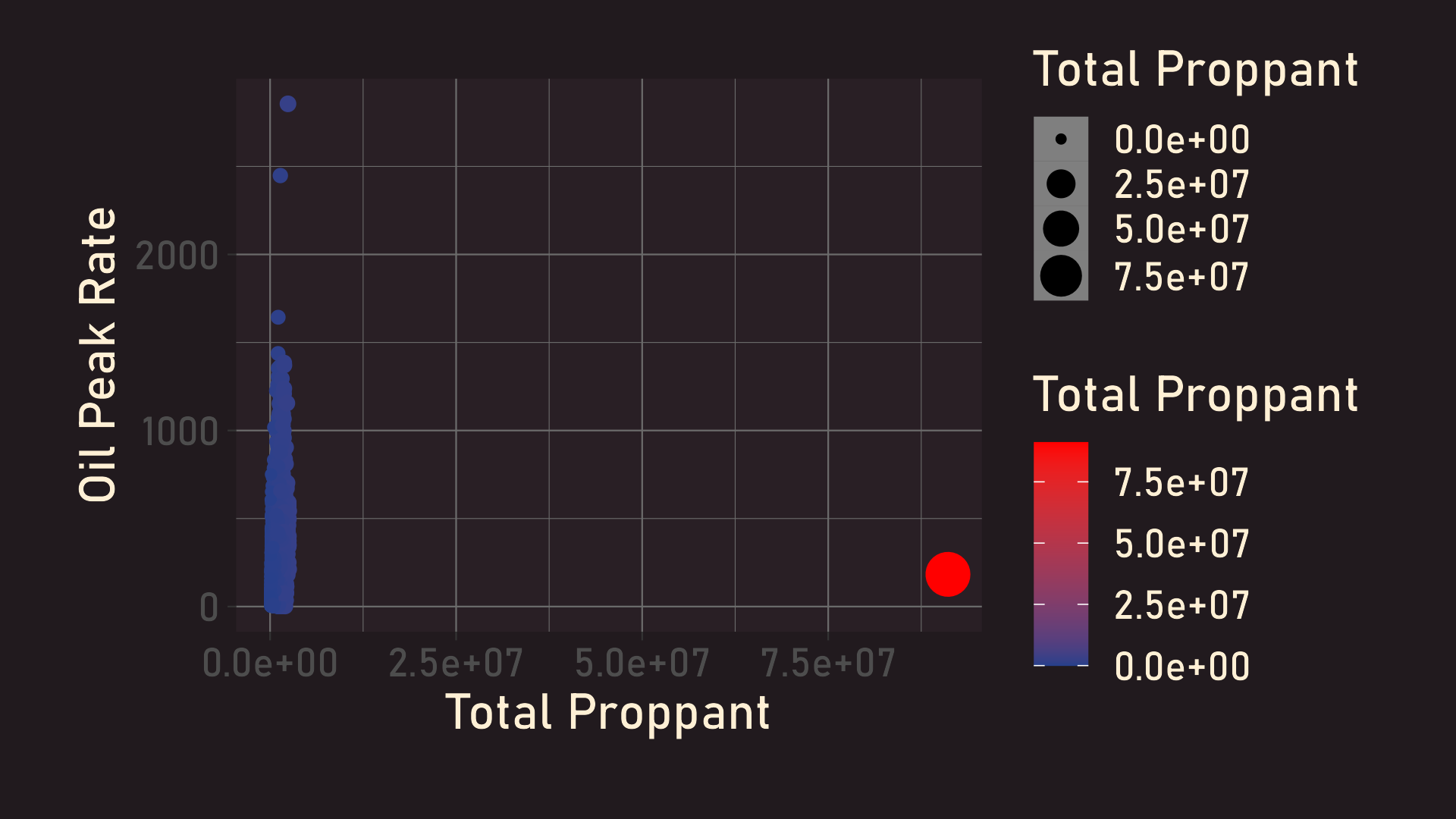
Outlier Detection
-
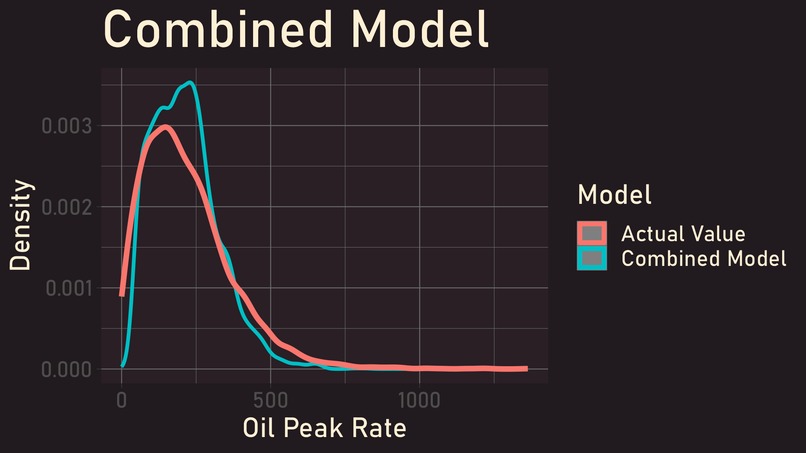
Prediction Distributions on Holdout Set
-
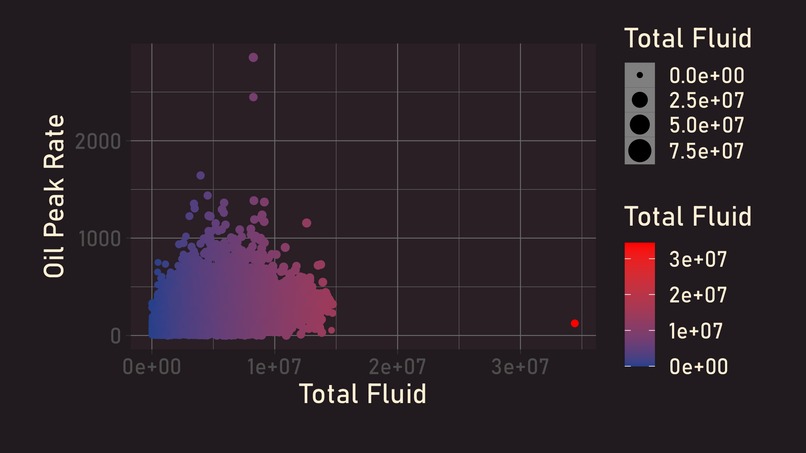
Outlier Detection
-
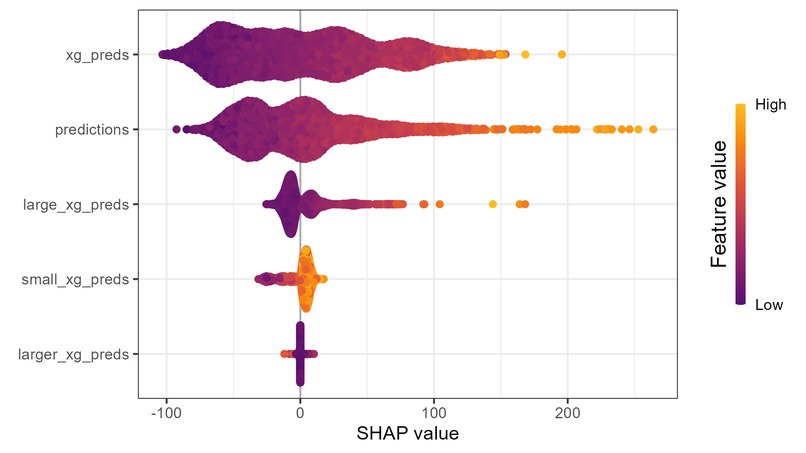
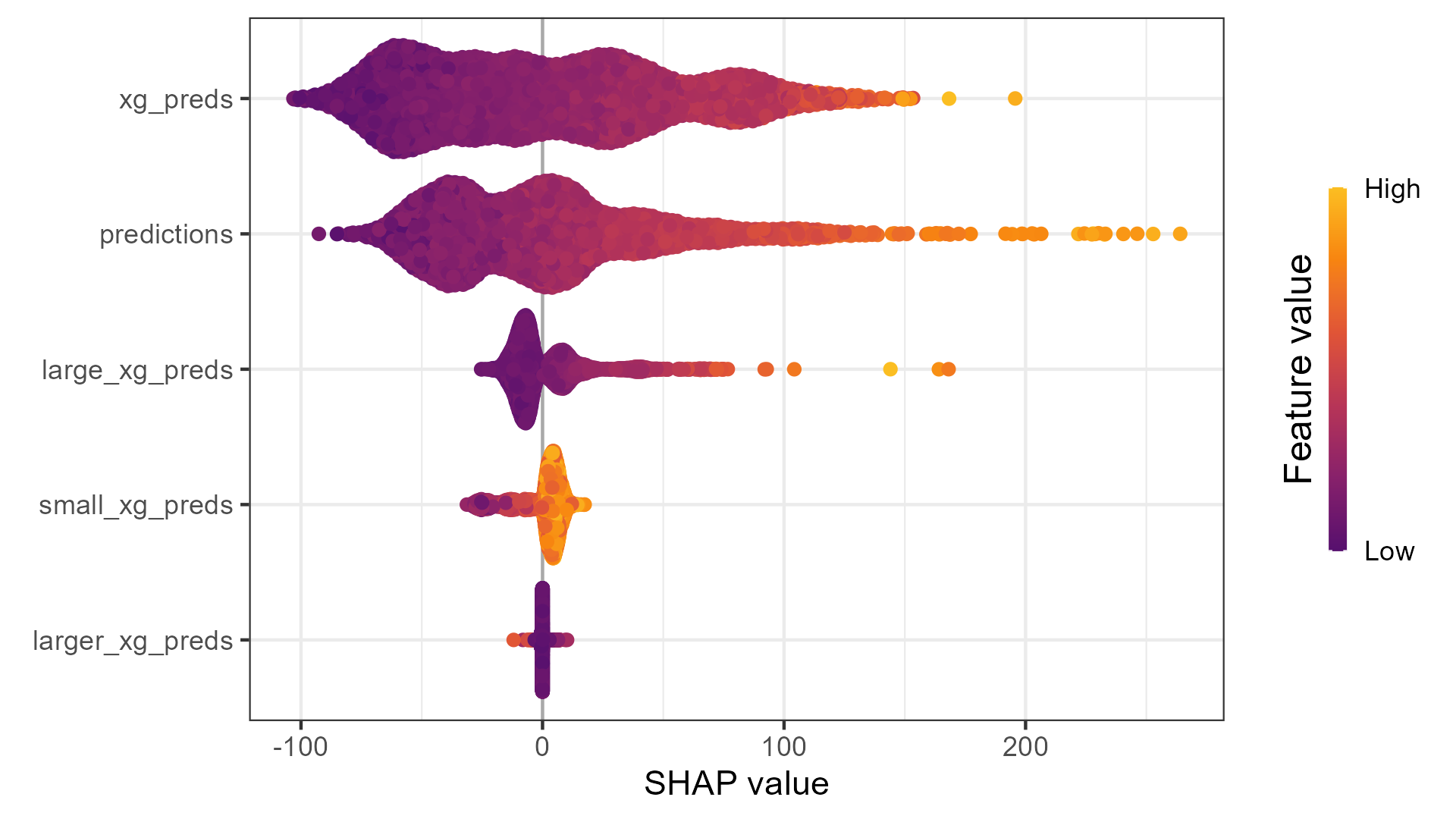
SHAP Values for Full Models
-
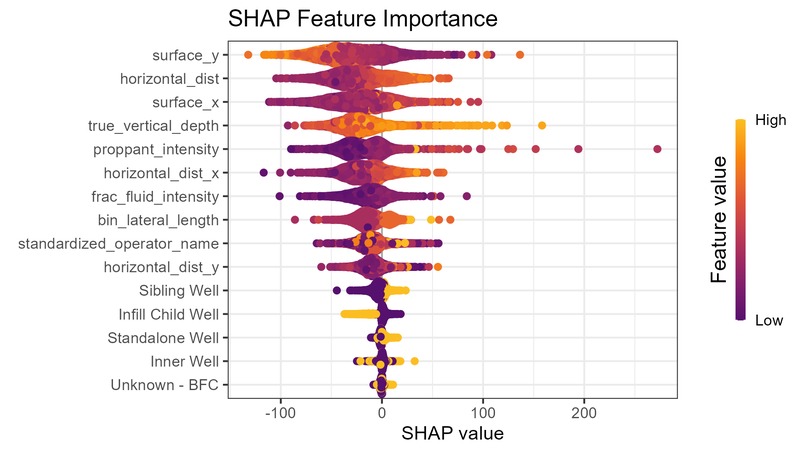
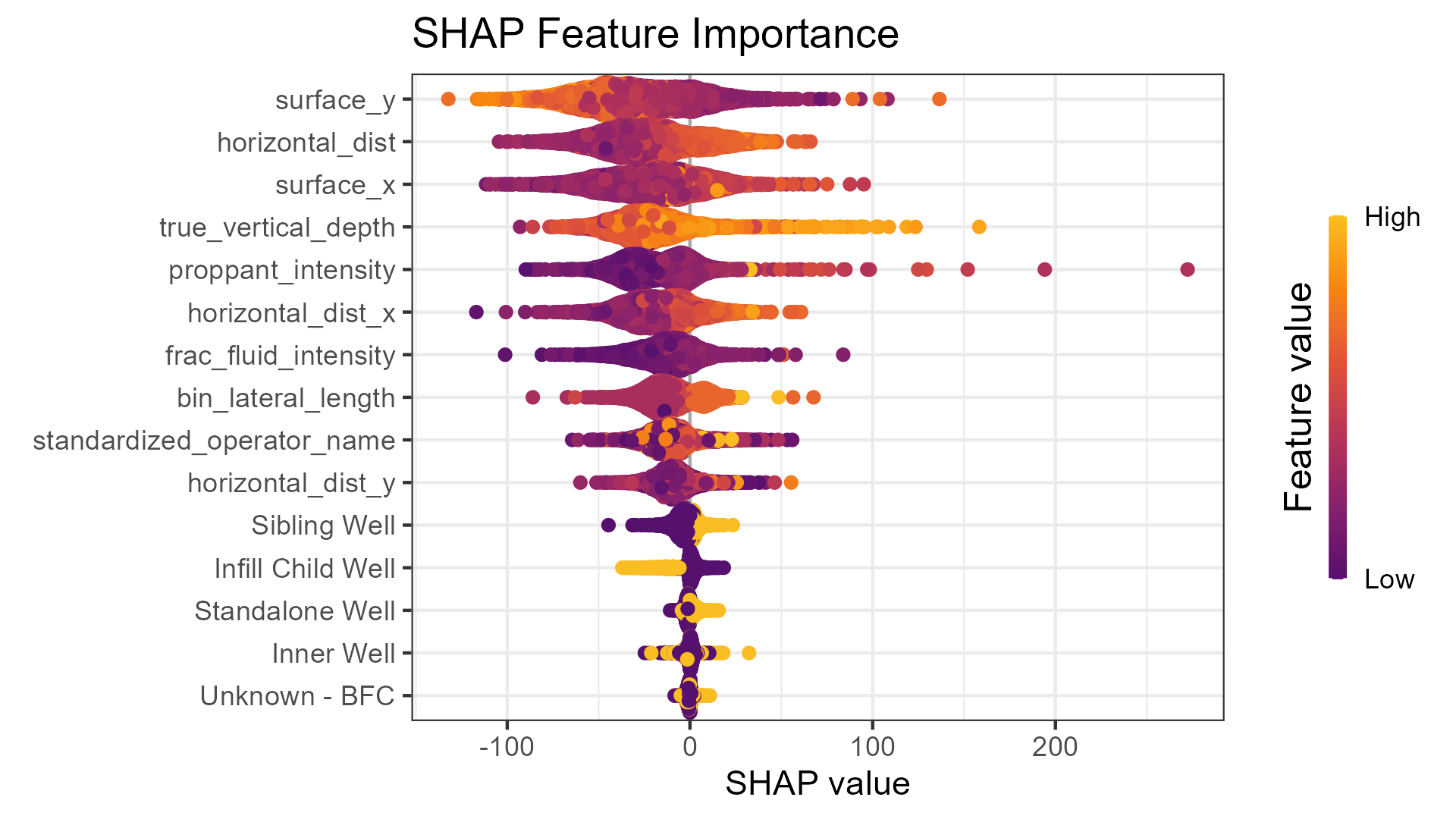
SHAP Values
-
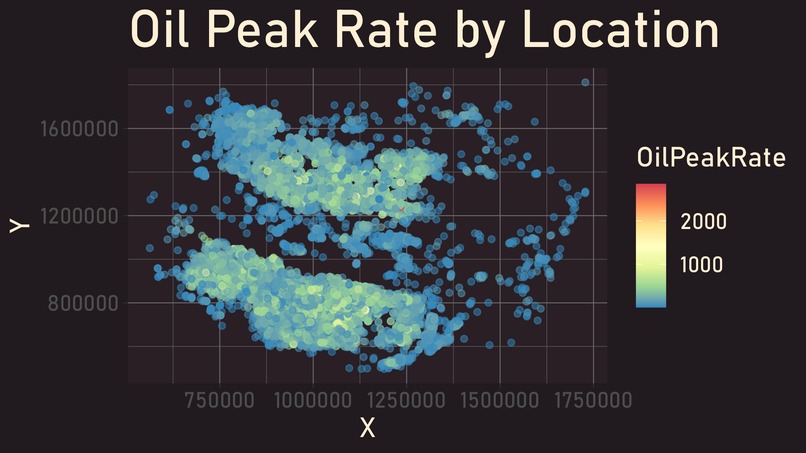
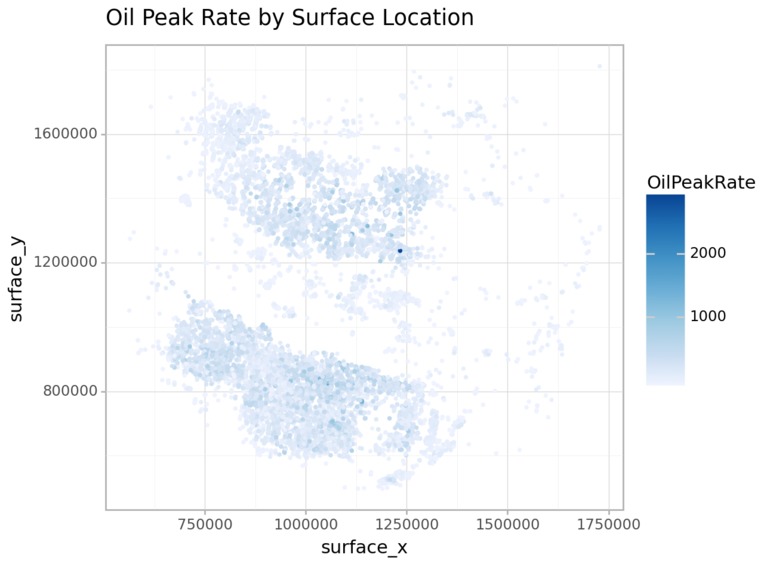
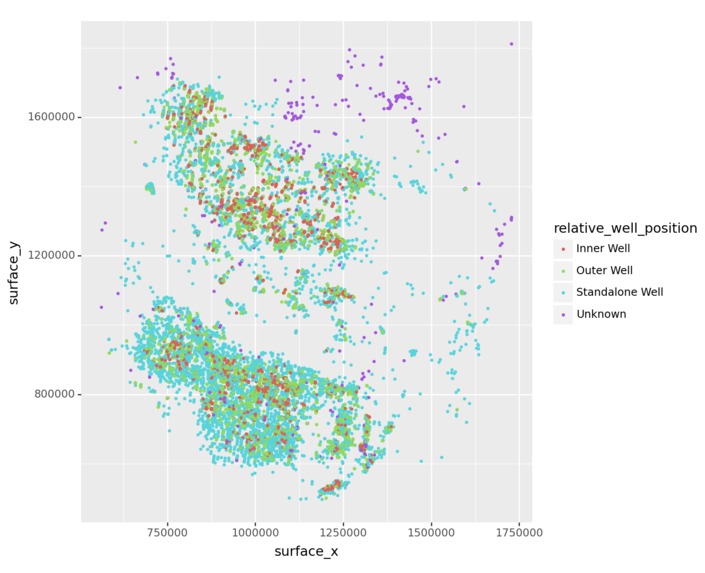
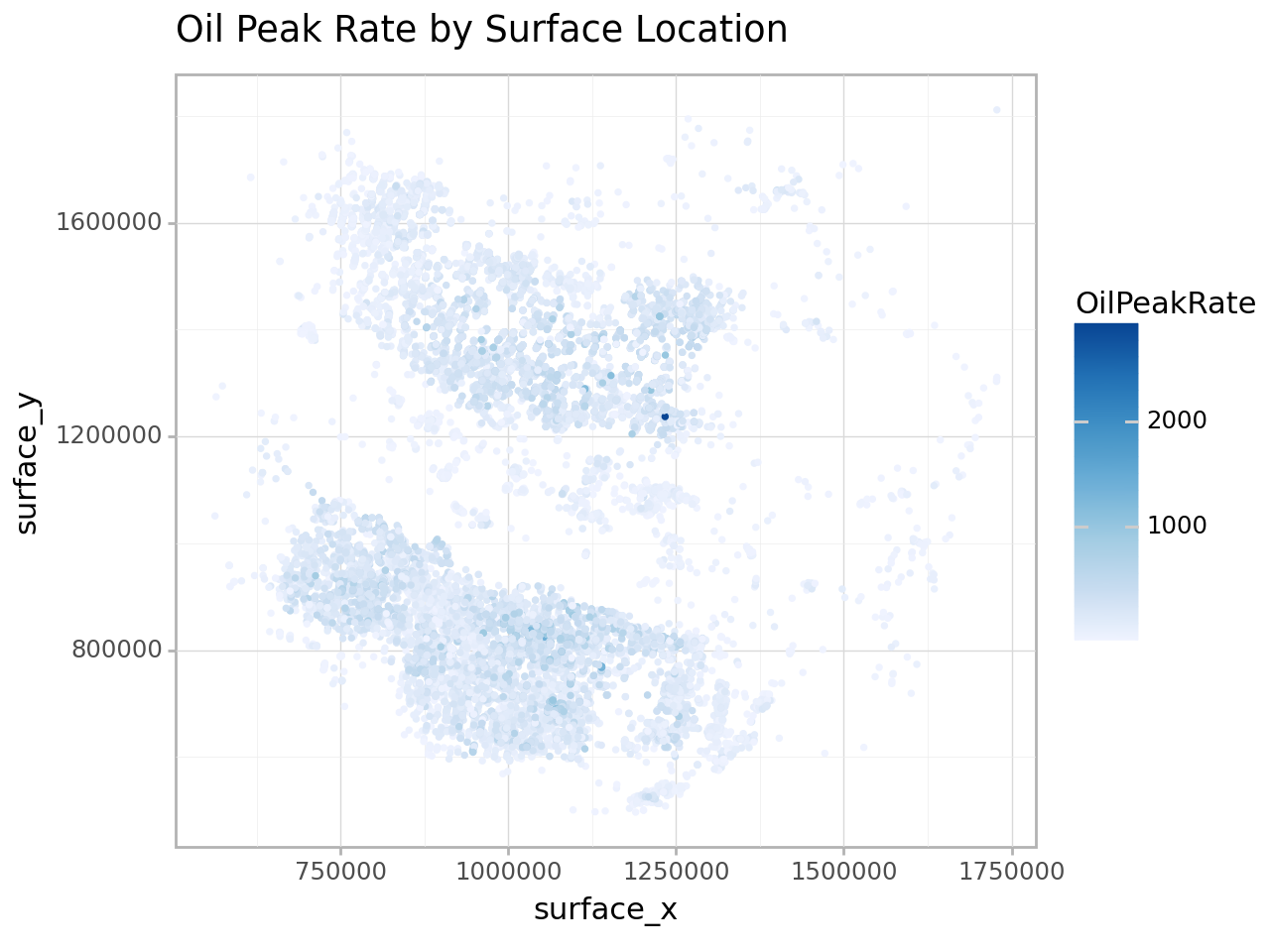
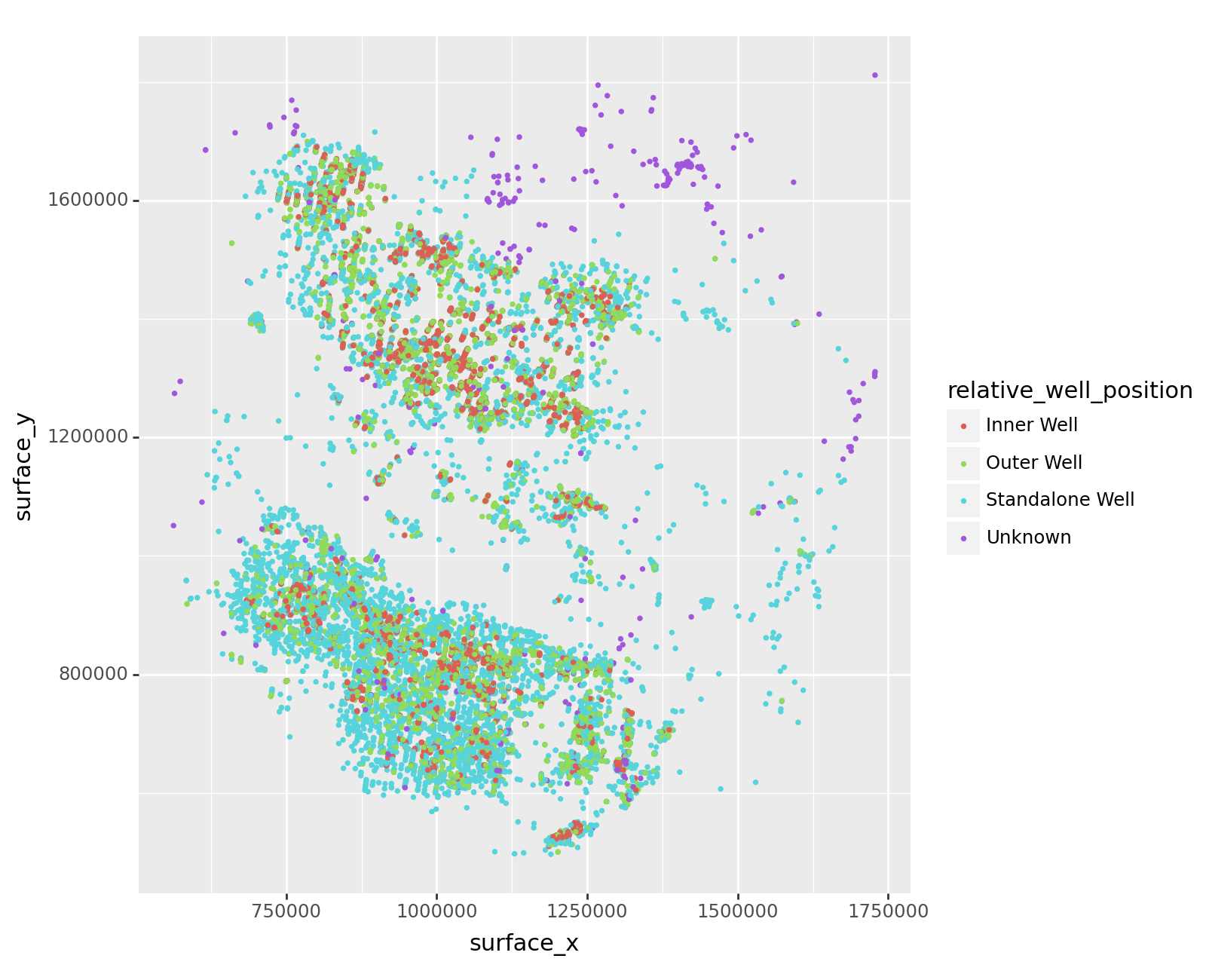
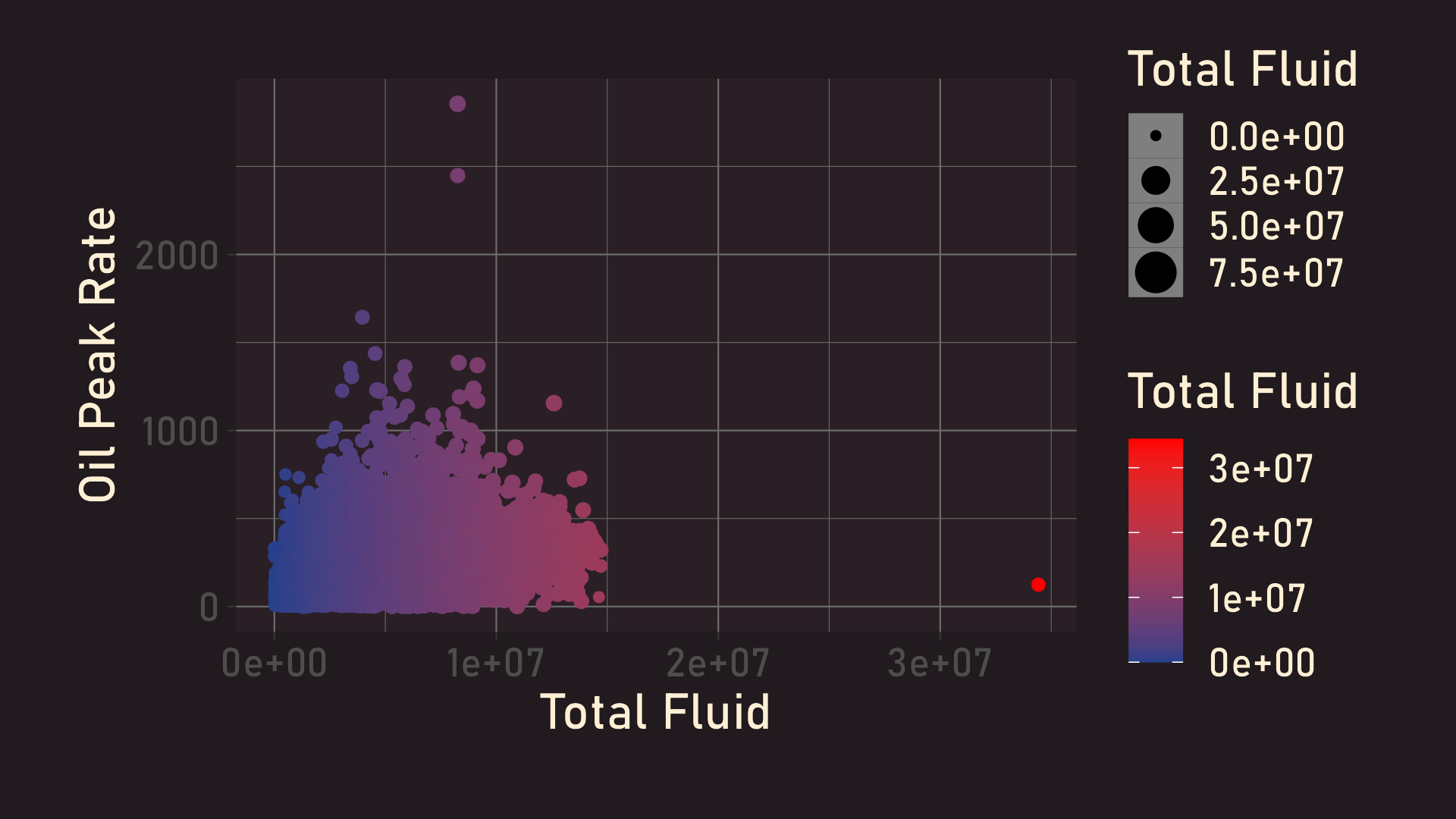
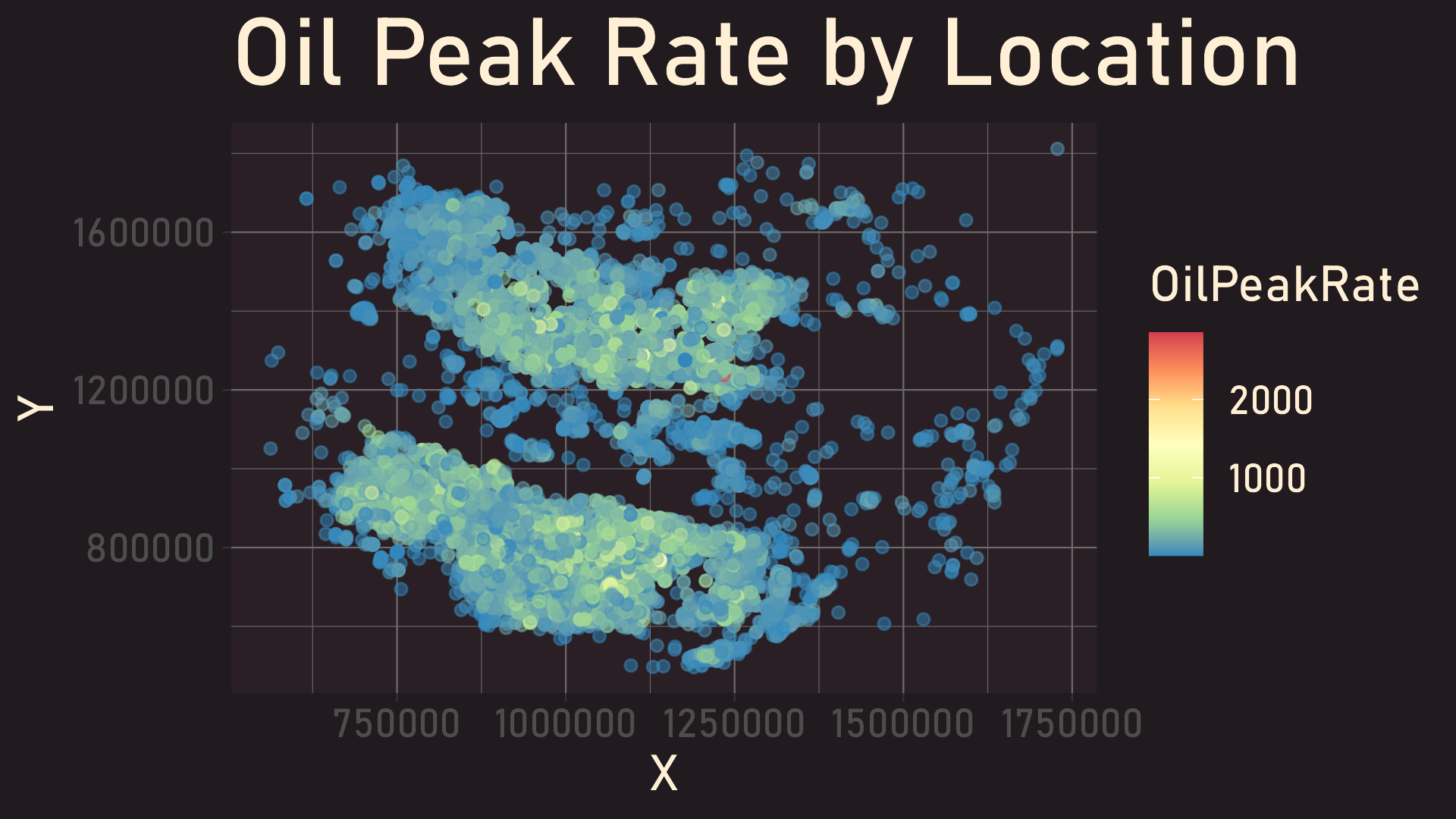
Oil Peak Rate by Location
What it does
In this Datathon project, we were tasked with predicting how much time it would take for an oil well to reach maximum production after popping it. Under our validation/testing set, we were able to reach a Root Mean Squared Error of 94.9, a number we are very proud of! We were given several categorical and numerical variables describing the well and its measurements along with xy coordinates.
We experimented with many models using an 80-20 train/test split and aimed to reduce the root-mean-squared error (RMSE) of our result. This ended up involving several models and instances of feature engineering. Our final program uses XGBoost to combine various machine learning methods to determine a final prediction.
Our workflow consisted of first cleaning the data:
- Removing columns that we found had large amounts of missing data
- Using one-hot encoding on categorical data.
Next, we used two machine learning approaches:
- XGBoost's gradient boosting, a classical machine learning algorithm
- A dense neural network that first encodes similar categories of data before concatenating them and feeding the data through more dense layers. Both utilize Gaussian probability density functions to accurately predict the oil flow rate. Finally, we combined both algorithms into one by having them vote on a final oil flow prediction using an overarching XGBoost algorithm.
How we built it
We split this problem into several stages. Ben was in charge of video production, data cleaning, and training the XGBoost model. With the cleaned data, we decided to each work on a different machine-learning model and select the ones that seemed most promising. Ian was in charge of the dense neural network and the Gaussian probability density function. Lauren used Random Forests for her model and Jonathan built an MLPRegressor neural net to predict the oil rate. Ultimately, the XGBoost and dense neural network proved to be the most effective at predicting the peak oil rate flow so we decided to use both models for our final solution.
Challenges we ran into
One of the features that we found to be a strong predictor of oil flow was the number of stages which was sadly missing from a large part of our dataset so we had to discard it. However, since the data was mostly clean, we were able to utilize a wide range of machine learning techniques in the creation of our final model.
What we learned
We learned a lot of new machine learning technologies such as XGBoost, Pytorch, Tensorflow, and more! We also were able to use a lot of new machine learning technique that greatly helped not only our project but also contributed to our knowledge.
What's next for Frack Around and Find out
We want to add more machine learning models into our combined XGBoost model to increase its accuracy. In addition, we would like to analyze further some of the features that were lacking from the original dataset such as the number of stages.

Log in or sign up for Devpost to join the conversation.