-
Landing page
-
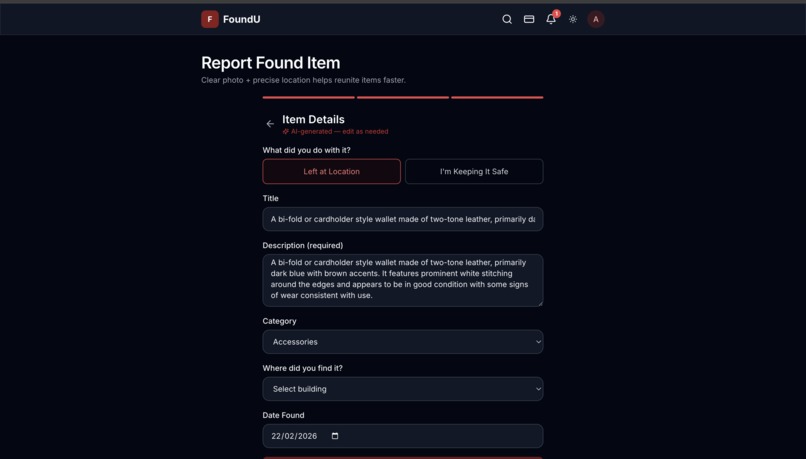
Ai analysis
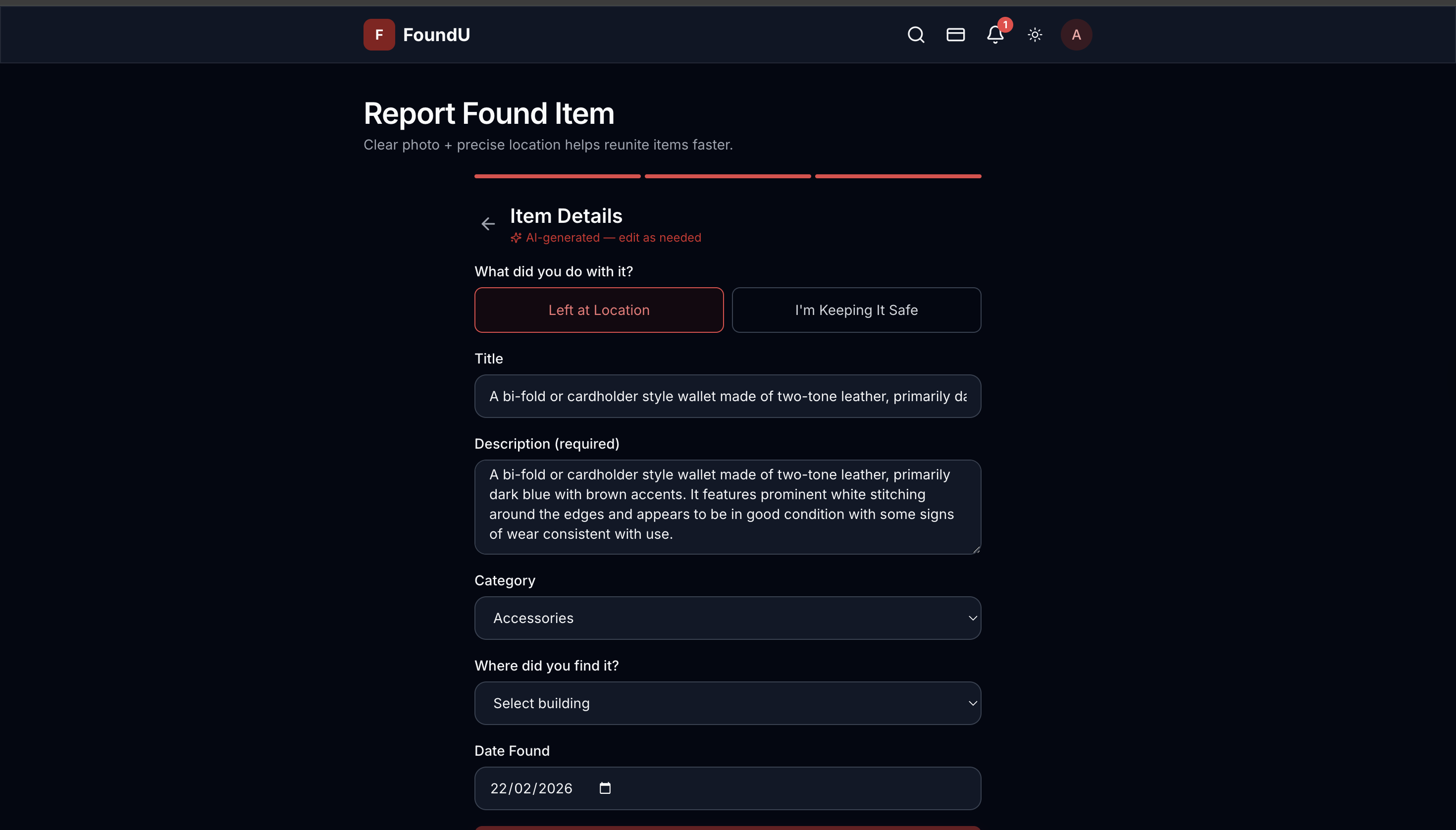
FoundU
AI-Powered Lost & Found for University Campuses
Inspiration
Every semester, thousands of items are lost across university campuses: AirPods left in lecture halls, wallets dropped in dining commons, UCards forgotten at the library. The existing lost-and-found systems are fragmented, manual, and frustrating. Students scroll through endless Instagram and Snapchat stories, which can take days or even weeks to get a match.
We asked ourselves: What if finding your lost belongings was as easy as posting a photo? That question became FoundU — an AI-powered platform that uses computer vision and semantic search to automatically match lost items with found reports, turning a painful process into something that just works.
What it does
FoundU is a full-stack web application that lets university students report lost and found items with minimal effort. When a user uploads a photo of an item, our AI pipeline:
- Analyzes the image using Google Gemini's vision model to detect objects, colors, brand, and condition
- Generates a semantic embedding that captures the item's meaning in a 768-dimensional vector space
- Automatically matches the item against all existing reports using cosine similarity search powered by pgvector
- Notifies both parties when a potential match is found, along with a confidence score
The platform also supports:
- Reverse image search — snap a photo of something you found and instantly see if anyone's looking for it
- Smart categorization — AI auto-fills category, description, and metadata from a single photo
- Ownership verification — AI-generated verification questions help confirm rightful owners during the claim process
- Real-time feed — an Instagram-style scrollable feed of all campus lost-and-found activity
- UCard fast-track — dedicated Gemini vision pipeline that extracts SPIRE ID, first name, and last name from UMass ID card photos, with Argon2id-hashed storage for privacy
How we built it
Frontend: Next.js 14 (App Router) with TypeScript, TailwindCSS, Framer Motion for animations, React Query for server state, and Zod for runtime type validation of every API response. Deployed on Vercel.
Backend: Hono (lightweight TypeScript web framework) running on Node.js, with Drizzle ORM for type-safe database access, and a comprehensive middleware stack for auth, rate limiting, and validation. Deployed on Render.
AI Pipeline: Google Gemini 2.5 Flash for vision analysis and UCard OCR extraction, Gemini Embedding 001 for semantic embeddings (768 dimensions via Matryoshka truncation), all orchestrated through a custom pipeline that processes uploads in real-time.
Database: PostgreSQL on Supabase with the pgvector extension for high-performance vector similarity search using HNSW indexing.
Storage: AWS S3 (dual-bucket quarantine/main pattern) with CloudFront CDN for image delivery. Images are processed through Sharp (resize, compress, thumbnail generation) before storage.
Auth: Google OAuth via NextAuth.js on the frontend, with JWT token exchange to the backend. The backend issues its own access/refresh token pair for stateless authentication. Restricted to @umass.edu email domain.
Infrastructure: Monorepo managed with pnpm workspaces, with shared internal packages for AI utilities (@foundu/ai) and database schema (@foundu/db).
Challenges we ran into
DNS resolution on Windows: Supabase's direct database hostname resolved to IPv6-only addresses, which silently failed on Windows networks without IPv6 support. We debugged this by comparing
nslookup(which bypasses the Windows DNS Client) againstping(which usesgetaddrinfo), and solved it by switching to Supabase's connection pooler.API contract mismatches: The backend returned camelCase responses wrapped in a
{ success, data }envelope, while the frontend expected snake_case flat objects. We wrote contract tests that validate every response shape against the frontend's Zod schemas, catching mismatches before they hit production.AI output normalization: The vision model returns categories like "Electronics" (title case) while our schema expects "electronics" (lowercase). FormData fields come back as
nullrather thanundefined. Dates can be null in the database but the UI assumed they were always strings. Each small mismatch caused subtle runtime errors that we systematically tracked down and fixed.
Accomplishments that we're proud of
End-to-end AI matching works: You can photograph a found item, and within seconds the platform identifies what it is, generates a semantic embedding, and surfaces the most likely owner — all automatically.
Contract-tested API: Our test suite validates that every backend response exactly matches the frontend's Zod schemas. If the API shape drifts, tests catch it before users do.
Production-grade auth flow: Self-healing token management that handles Google OAuth → backend JWT exchange, automatic refresh, and graceful recovery from expired sessions — all transparent to the user.
Zero-downtime embedding backfill: We built tooling to regenerate embeddings for existing items when we switched AI models, ensuring no data was left behind with stale zero-vectors.
Privacy-first UCard handling: SPIRE IDs extracted from UCard photos are never stored in plaintext, instead they are immediately hashed with Argon2id plus a server-side pepper before hitting the database.
What we learned
Defense in depth for types: TypeScript catches compile-time errors, but runtime mismatches between frontend and backend are where real bugs hide. Zod schemas at the boundary are essential.
AI APIs are a moving target: Models get deprecated, rate limits shift, and SDK support lags behind the REST API. Building with fallbacks and raw HTTP as an escape hatch is critical.
The last 10% is 90% of the work: Getting the AI pipeline to return something took a day. Getting it to return the right thing in the right format with proper error handling took much longer.
Monorepo tooling pays off: Sharing types, AI utilities, and configs across frontend and backend in a single repo with pnpm workspaces made iterative testing easy.
What's next for FoundU
- Multi-campus support — expand beyond UMass Amherst to a network of universities with campus-specific feeds
- Mobile app — React Native wrapper for a native experience with camera integration
- Analytics dashboard — campus administrators can view trends, recovery rates, and hotspot locations
- Community trust scores — reputation system for reliable finders to build campus trust
Built With
- drizzle-orm
- framer-motion
- google-gemini-ai-(vision-+-embeddings)
- hono
- next.js-14
- nextauth.js
- pgvector
- pnpm-workspaces
- postgresql
- react-query
- render
- supabase
- tailwindcss
- typescript
- vercel
- zod

Log in or sign up for Devpost to join the conversation.