
Inspiration
CrowdStrike documented a breakout time — the window from initial access to full lateral movement — of seven minutes. Horizon3's autonomous AI agent achieved full privilege escalation in sixty seconds. MIT published research showing AI-driven attack workflows running forty-seven times faster than human operators.
Meanwhile, the average DFIR analyst still pulls up their toolkit manually, types command-line flags from memory, and spends twenty to forty minutes correlating a single alert before they can make a decision.
That gap is what Fossick Intelligence was built to close. Not just automating the commands — automating the reasoning. The question was not "can we run Volatility faster?" It was "can we build something that thinks like a senior analyst and is honest about what it doesn't know?"
What It Does
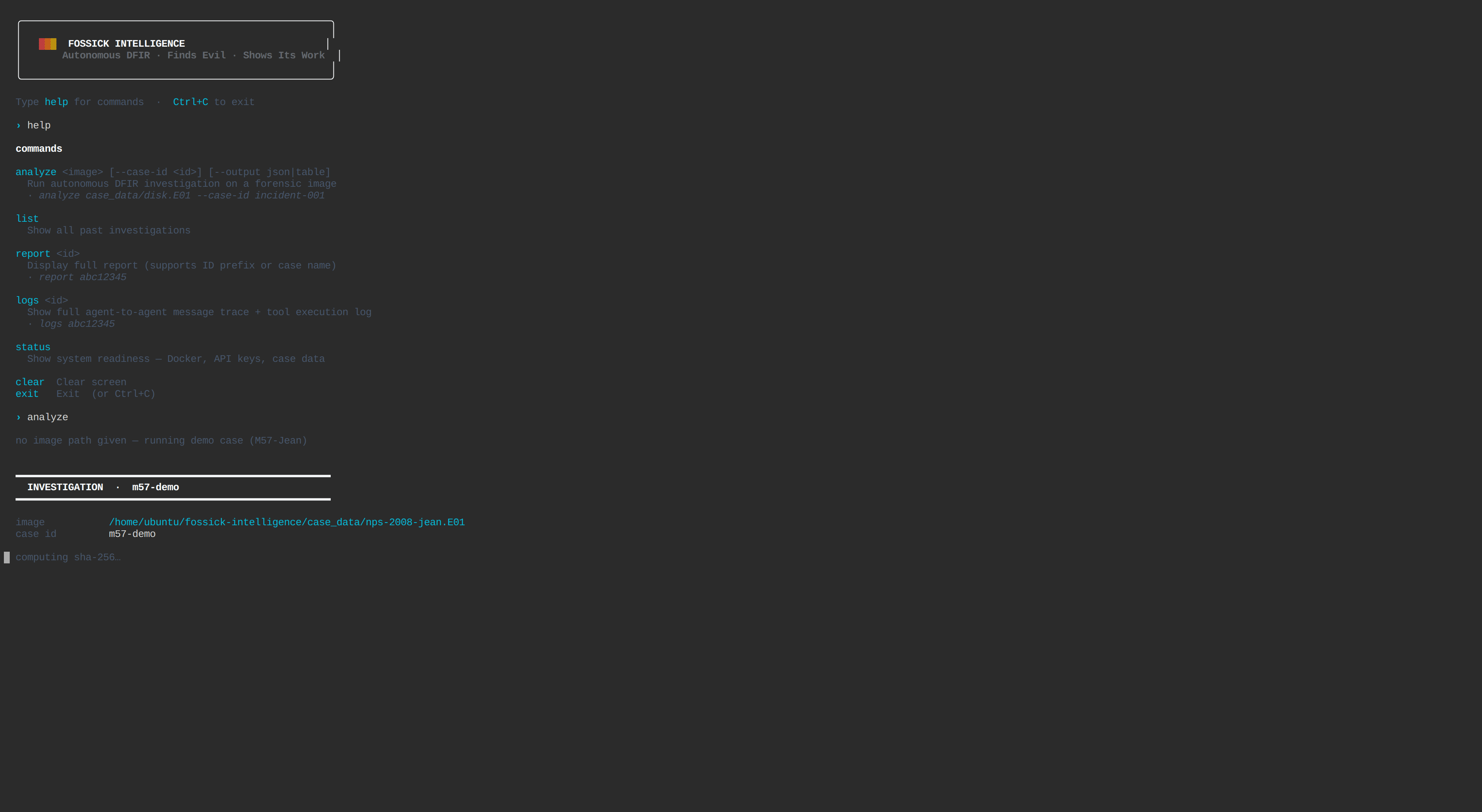
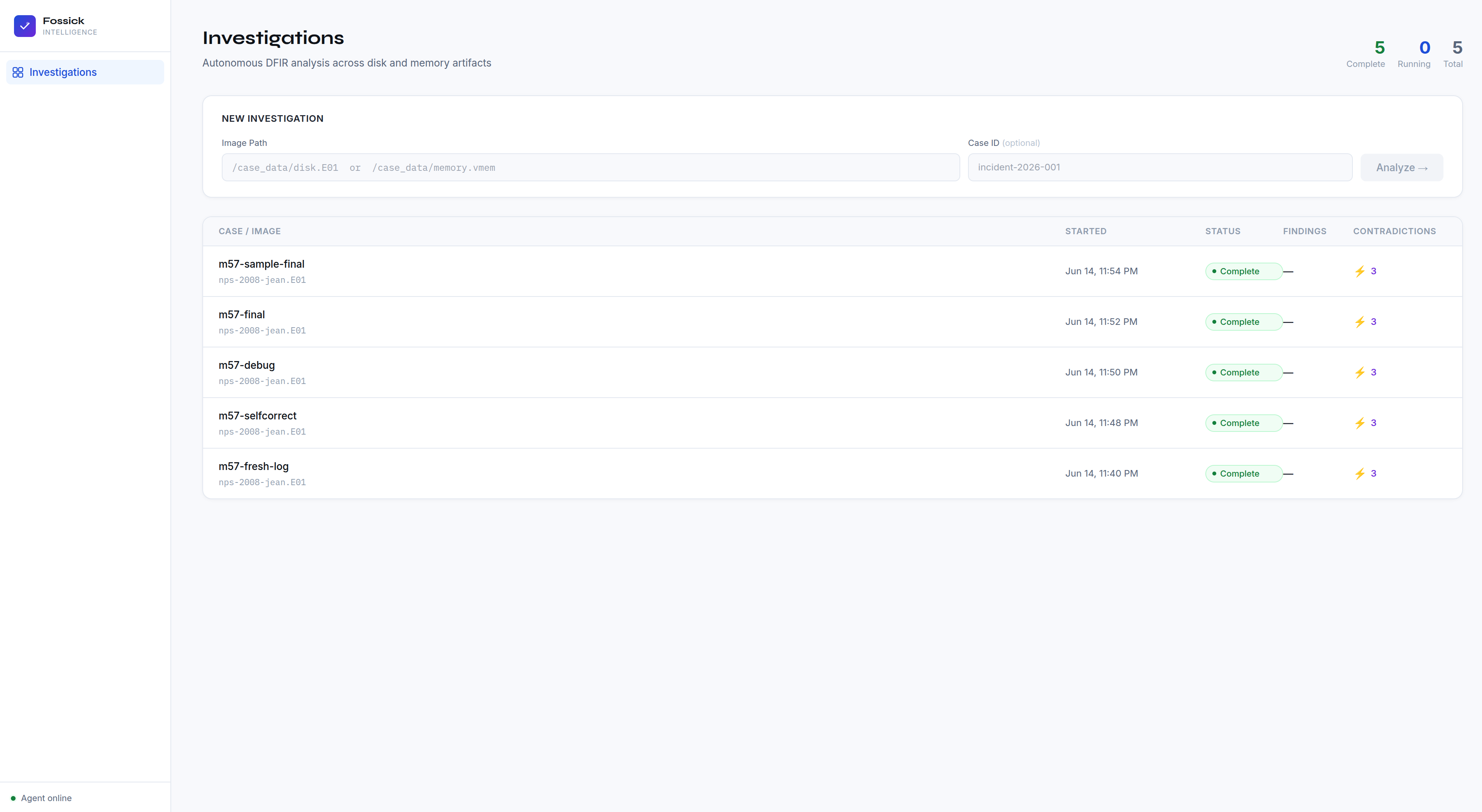
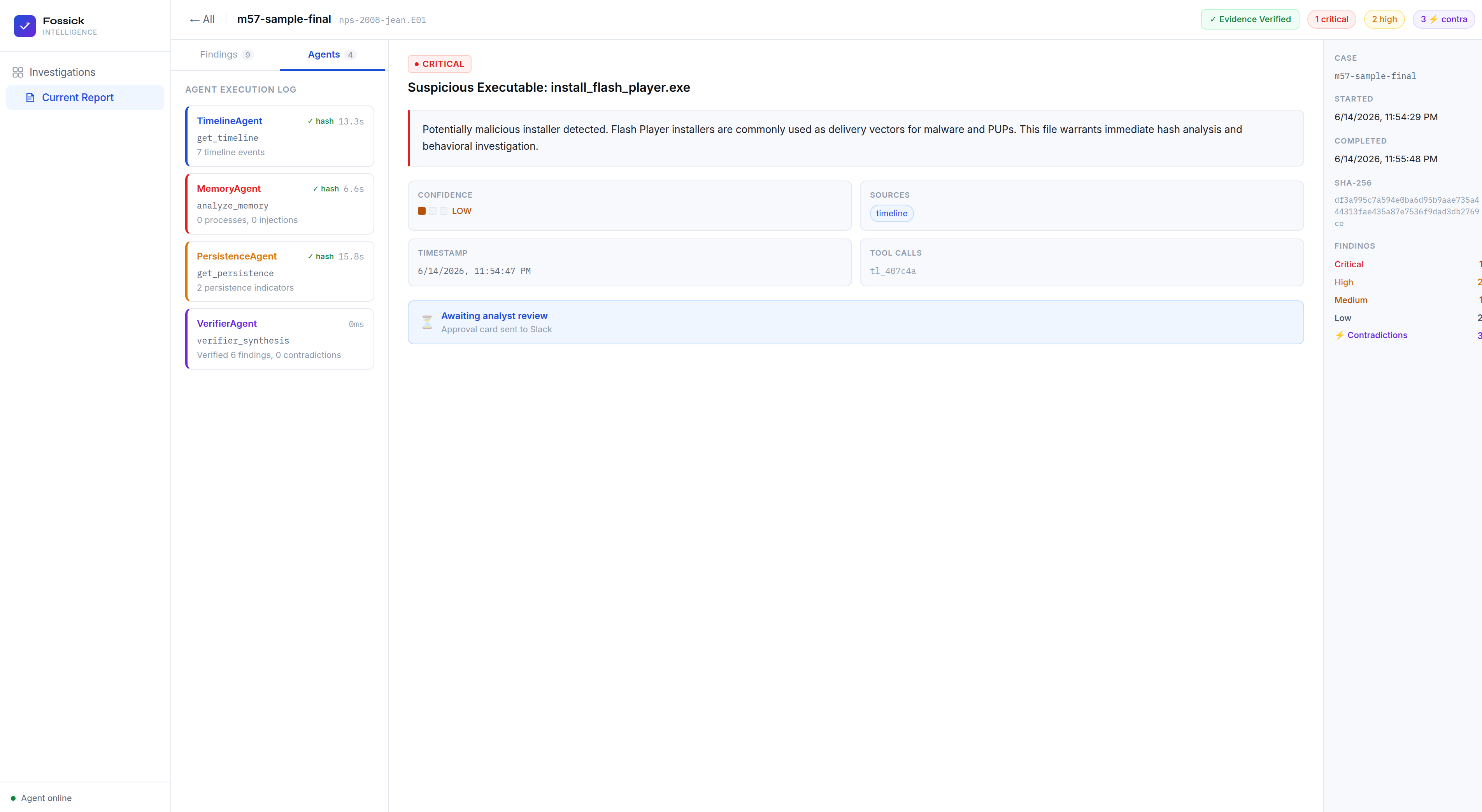
Fossick Intelligence is an autonomous DFIR platform you run from a single terminal command. You type fossick, point it at a forensic image, and four specialized agents investigate in parallel, streaming findings to your terminal as each one completes. By the time the last agent finishes, your Slack channel already has alerts and your web dashboard has a full traceable report.
The four agents:
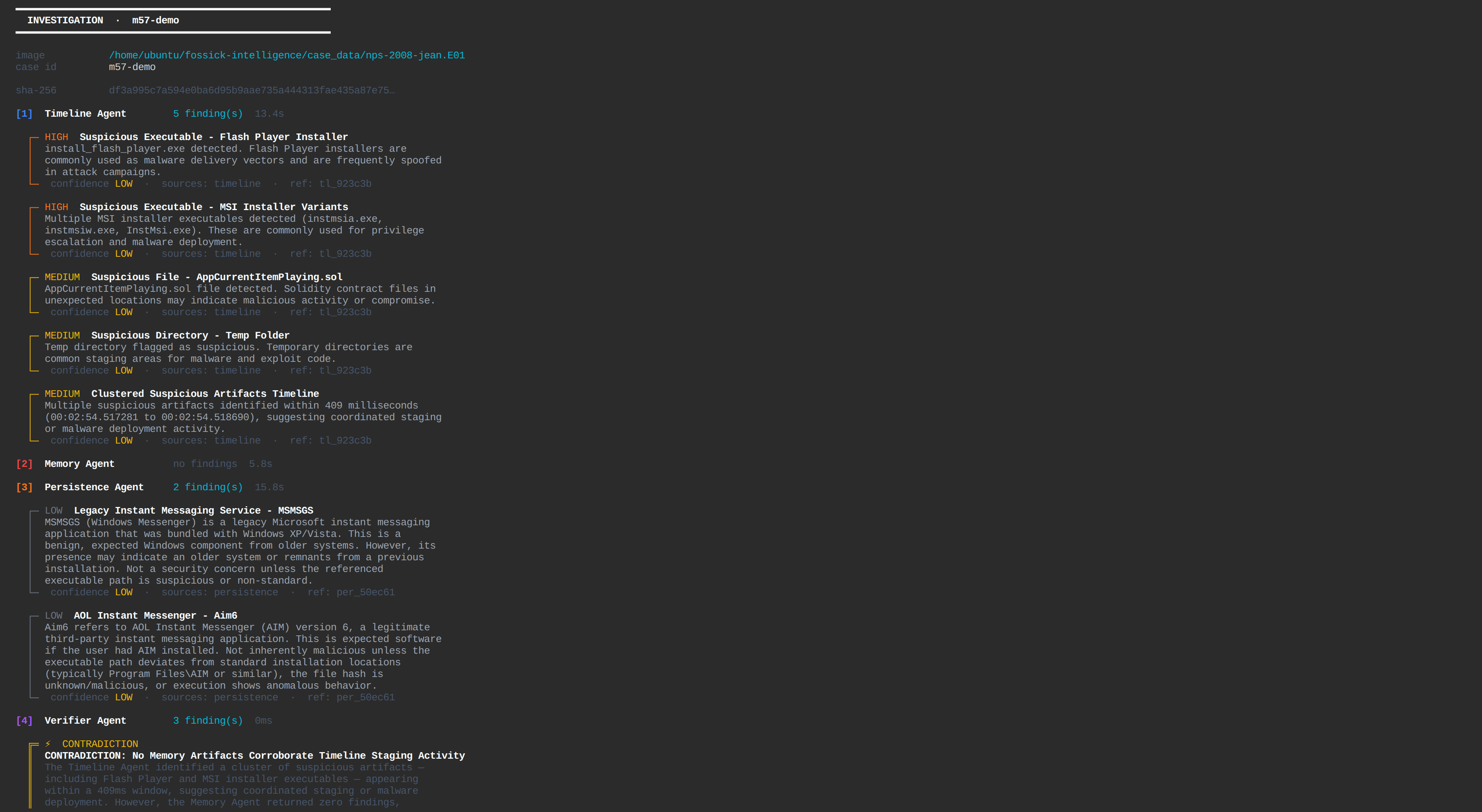
The Timeline Agent mounts multi-segment EWF disk images and runs SleuthKit's fls to build a filesystem artifact timeline — flagging suspicious executables, unusual file types in user directories, and known malware staging locations.
The Memory Agent runs Volatility3 against RAM captures — process lists, network connections, code injection indicators. When given a disk image instead of memory, it returns zero findings honestly rather than fabricating output.
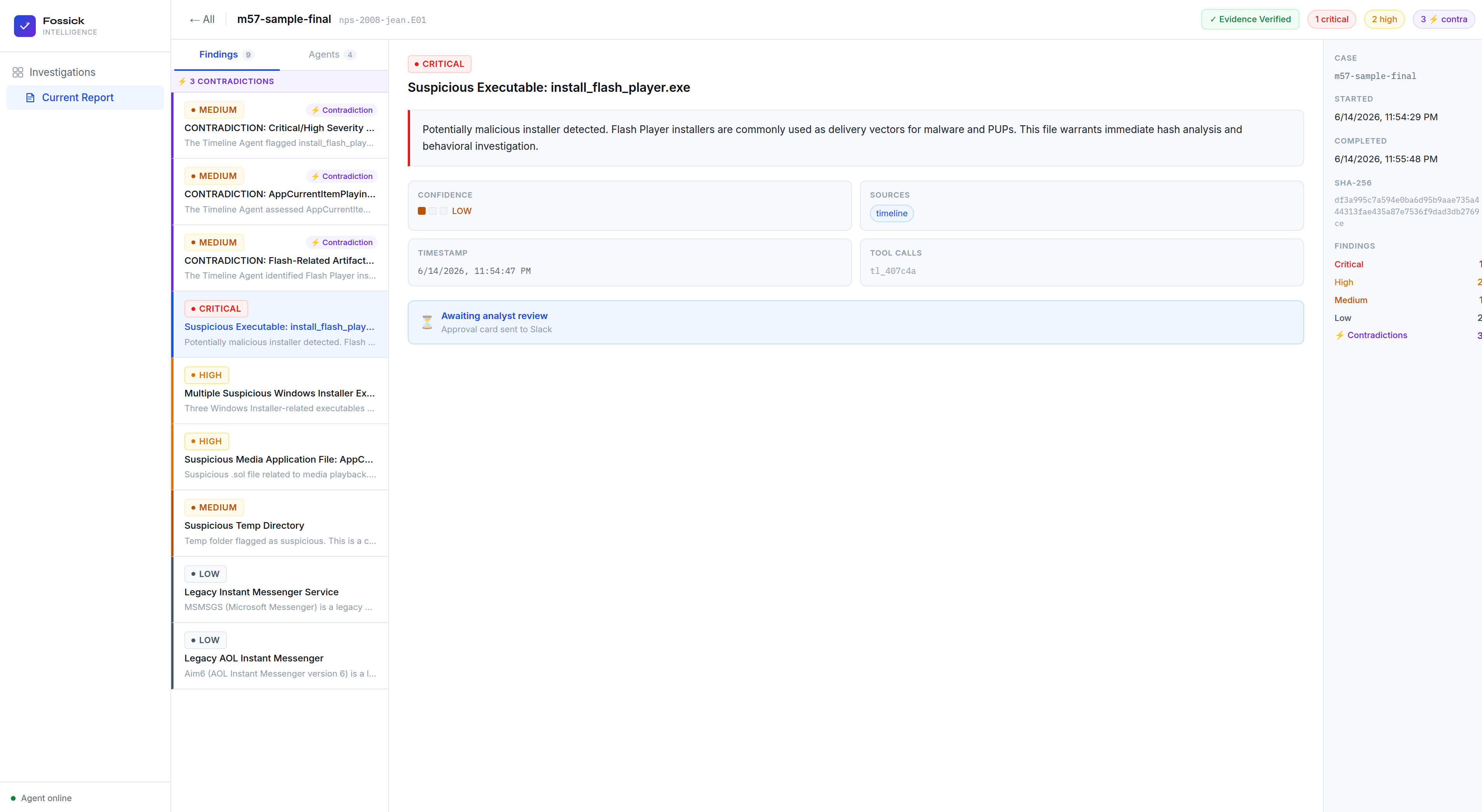
The Persistence Agent extracts NTUSER.DAT registry hives using icat, parses them with regipy to find Run and RunOnce key entries, and separately scans every Windows Startup folder for suspicious executables. On the M57-Jean test case it found two HKCU Run key entries — MSMSGS and Aim6 — and confirmed all four Startup folders were empty of non-standard executables. Two real findings, zero false positives.
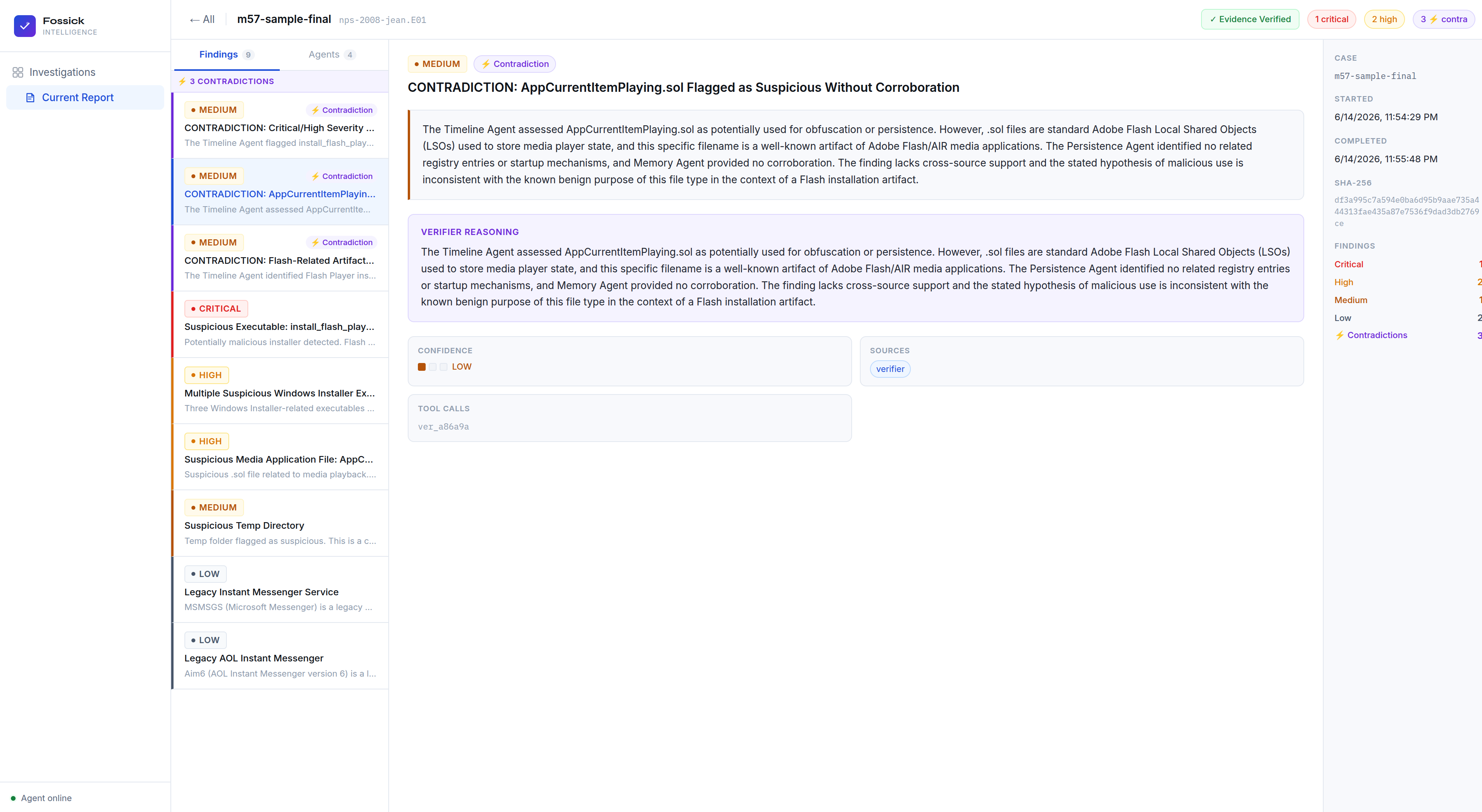
The Verifier Agent is the piece that makes Fossick different from running the tools manually. It receives all three agents' outputs and cross-references them. If the Timeline Agent flags a Flash Player installer as high severity but the Persistence Agent finds zero registry Run keys and the Memory Agent finds no injected processes, the Verifier flags this as a contradiction: "If this file were actively malicious and executed, we would expect residual artifacts. Their absence significantly weakens this finding." That is the kind of reasoning that prevents false incident escalations at three in the morning.
Every finding includes its confidence level — HIGH, MEDIUM, or LOW based on how many independent sources corroborate it — and the exact tool call ID that produced the evidence. Every finding is traceable. Nothing is fabricated.
How We Built It

The Custom MCP Server
The most important architectural decision was building a Custom MCP Server rather than giving the agents raw shell access. Each forensic tool is wrapped as a typed Python function:
get_timeline(image_path, earliest, latest, artifact_types)— mounts EWF, runs fls, returns structured JSONanalyze_memory(image_path, plugins)— runs Volatility3 plugins, returns structured process and network dataget_persistence(image_path)— extracts and parses registry hives, scans Startup folders, returns structured indicatorsverify_file_hash(image_path, expected_sha256)— SHA-256 verification
Raw tool output never reaches the LLM. Plaso produces millions of lines of CSV. Volatility dumps thousands of rows. Passing that directly to a language model guarantees hallucination through context overflow. Instead, each MCP tool parses its output to structured JSON with a hard limit of fifty findings per call. The model reasons about structured data, not raw text.
Evidence integrity built into the protocol
Every MCP tool call wraps its execution in an EvidenceContext — a context manager that computes the SHA-256 of the forensic image before the tool runs and verifies it matches after. If anything modified the image during analysis, EvidenceSpoliationError raises immediately and the investigation halts. The hash is recorded in every finding's evidence_ref field and in the full audit log. Judges and courts can verify the hash independently. Nothing was touched.
The forensic image is mounted inside Docker as a read-only volume (-v /case_data:/case_data:ro). Tools cannot write to it regardless of what the agent instructs. This is not a prompt instruction — it is an OS-level mount flag. An agent attempting to write to the image receives a filesystem permission error, not a soft refusal from a guardrail.
Docker for forensic tool isolation
Volatility3, SleuthKit, ewfmount, and regipy all run inside a Docker container built on Ubuntu 22.04. The --privileged flag is required for FUSE-based EWF mounting and is the only elevated permission the container holds.
The interactive CLI

The fossick command opens a persistent REPL with tab completion and command history. Findings stream to the terminal as each agent completes — you see Timeline findings while Persistence is still running. The terminal uses true-color ANSI with bordered finding blocks, confidence bars, and word-wrapped descriptions. It looks like a product, not a script.
Slack as the operations surface

Every high and medium severity finding posts a structured card to Slack in real time. Low-confidence findings get interactive Approve and Dismiss buttons. When an analyst taps a button, the card updates using Slack's response_url and the decision writes back to the database immediately. The web dashboard reflects it within five seconds.
The React dashboard

A three-panel report viewer. Left panel shows all findings ranked by severity with contradiction flags inline. Center panel shows full finding detail — description, Verifier reasoning, confidence indicators, tool call references, and the analyst's Slack decision. Right sidebar shows case metadata, SHA-256, findings breakdown, and Slack activity. The terminal is how you start an investigation. The dashboard is how your team works through it.
Challenges
MCP stdio protocol under asyncio
The MCP server communicates over stdio, but Python's asyncio event loop and Docker's stdin pipe do not play well together when you write all messages at once via proc.communicate(). The server would process the initialization message and exit before receiving the tool call. The fix was writing messages one at a time with proc.stdin.write() and await proc.stdin.drain(), then reading responses line by line with a 150-second timeout. This took longer to debug than the entire persistence agent implementation.
Multi-segment EWF with FUSE in Docker
The M57-Jean image is split across two files — E01 and E02. SleuthKit's fls reads the first segment for partition metadata but fails when it hits an offset that lives in the second segment. The initial fix was ewfmount presenting both segments as a single raw device — but FUSE in Docker produced I/O errors even with --privileged. The final solution bypasses FUSE entirely: pass both segment paths directly to fls, mmls, and icat as positional arguments. SleuthKit supports multi-segment EWF natively — the FUSE layer was adding a step that wasn't needed.
Registry hive parsing false positives
The first version of the persistence startup scanner used fls -r to recursively list the entire filesystem and set an in_startup flag whenever it saw a directory named "Startup." This caused it to flag every .exe and .dll in Windows system32 as a Startup item — 673 false positives including most of the Windows OS. The fix was a two-pass approach: first find all Startup directory inodes via fls -r, then call fls non-recursively on each inode to get only direct children. Result: zero false positives on the M57-Jean image.
Registry hive parsing without Plaso
Plaso failed to install reliably in the Ubuntu 22.04 container. Rather than ship a broken install, we used icat to extract NTUSER.DAT hives directly by inode and parsed them with regipy. This gives us Run key persistence with full key paths and values. The timeline uses SleuthKit's native fls and mactime instead. The result is more reliable than a Plaso installation that half-works.
Accomplishments
The moment that felt like a real product was running the full investigation against the M57-Jean image and watching findings stream in: Timeline Agent surfaces the Flash installer and MSI staging artifacts, Persistence Agent finds the MSMSGS and Aim6 Run key entries, Verifier catches the contradiction between the Flash finding and the absence of memory and persistence corroboration, Slack receives the cards, an analyst dismisses one finding, and the dashboard reflects it — all in under ninety seconds on a remote EC2 instance.
The thing we are most proud of technically is the Verifier agent. Writing a system that automatically catches its own agents being wrong — that flags when findings lack cross-source corroboration and explains why in plain English — is harder than writing the agents themselves. Most DFIR tools give you a list of findings and leave the correlation to you. Fossick tells you when it is not sure and why.
What We Learned
Building this made clear that "agentic" in a security context has a specific meaning: the agent has to be willing to find nothing. A system that always produces findings is useless in DFIR. False positives cause more damage than missed alerts because they erode analyst trust and lead to alarm fatigue. The Verifier's job is not to validate findings — it is to challenge them. That design decision came from thinking about what a senior analyst actually does when reviewing a junior analyst's work.
We also learned that the MCP Server architecture is genuinely the right answer here. When we gave agents raw shell access early in development, the quality of findings dropped immediately because the models started reasoning about raw terminal output instead of structured data. Wrapping every tool in a typed function returning clean JSON made the analysis dramatically more accurate and eliminated an entire class of hallucinations.
What's Next
- Memory image support — the Memory Agent is fully built but needs a RAM capture to show its real value. The next test case will include a
vmemfile alongside the disk image - Real firewall integration —
block_ipandisolate_hostare currently logged as simulated actions. Connecting to pfSense or CrowdStrike Falcon's API is the next step - Multi-investigator teams — the current dashboard is single-tenant. Adding user roles, assignment, and shift handoff notes makes this deployable in a real SOC
- Plaso timeline — getting Plaso installed correctly in the container would add browser history, USB connections, and LNK file analysis on top of the filesystem timeline we have now

Log in or sign up for Devpost to join the conversation.