-
-
Prioritization
-
Priority Tuner
-
Audit
-
AI Jury
-
Brief
-
Evidence
Inspiration
Architectural code review is the kind of thing senior engineers do well and nobody else does at all. You hand a codebase to a staff engineer, they spend a couple of hours, and you get back a memo: here are the things that matter, here's why, here's what to do about each one given how your team thinks about tradeoffs. That memo is enormously valuable and almost nobody has access to it, because senior engineers are expensive and rare.
The obvious move is to throw an LLM at it. The non-obvious problem is that LLMs alone aren't very good at this: they hallucinate metrics, they don't know what "stable" or "fragile" really mean in your codebase, and they have no idea which tradeoffs your team actually cares about. So we built FORUM: it combines deterministic static analysis (which knows the structural facts) with multi-agent debate (which produces judgment), and then expresses your team's values as weights that bias both ranking and aggregation.
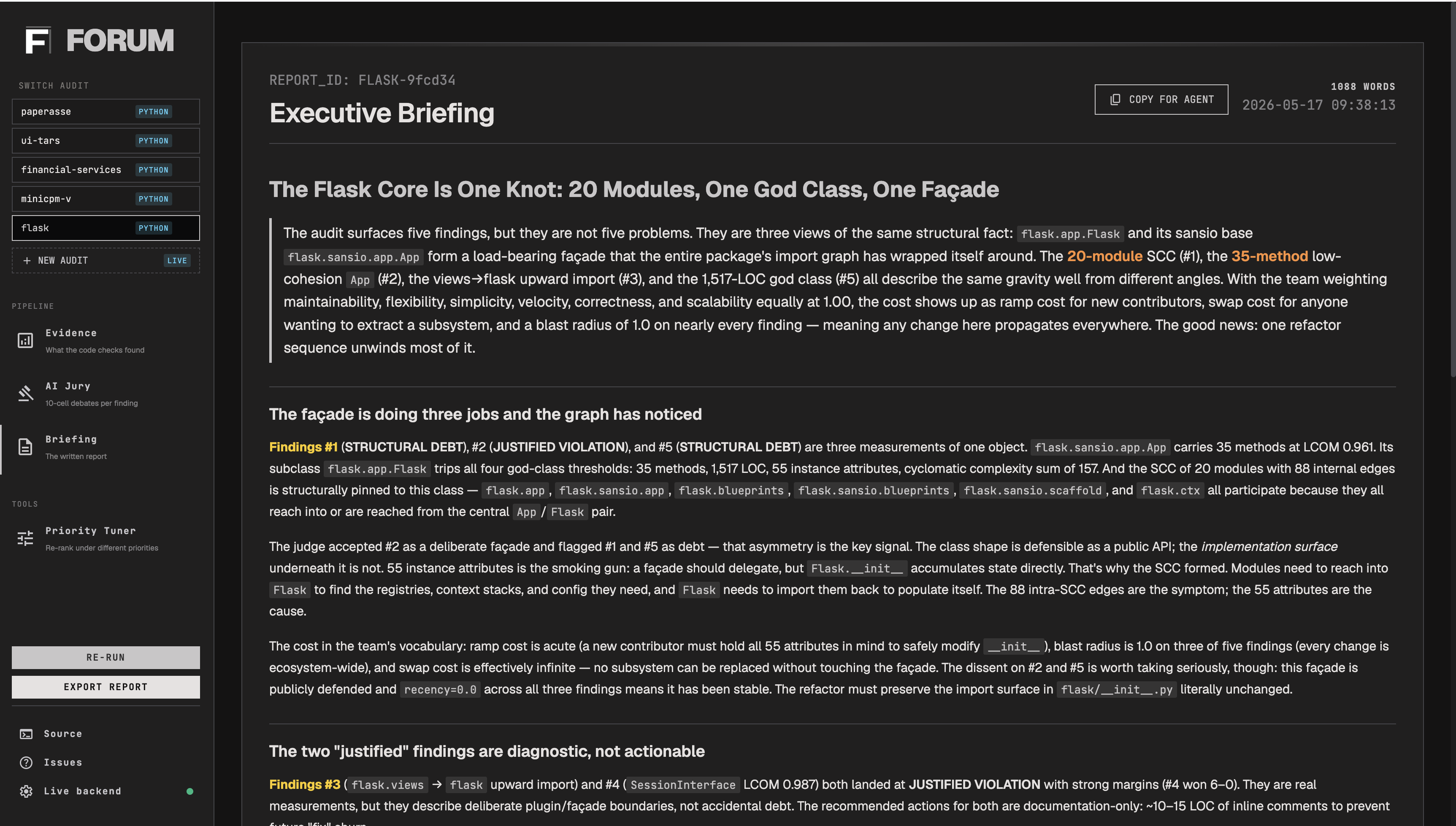
Essentially, FORUM audits Python or C repos and produces a values-aware architectural briefing in about 90 seconds, for under fifty cents.
What it does
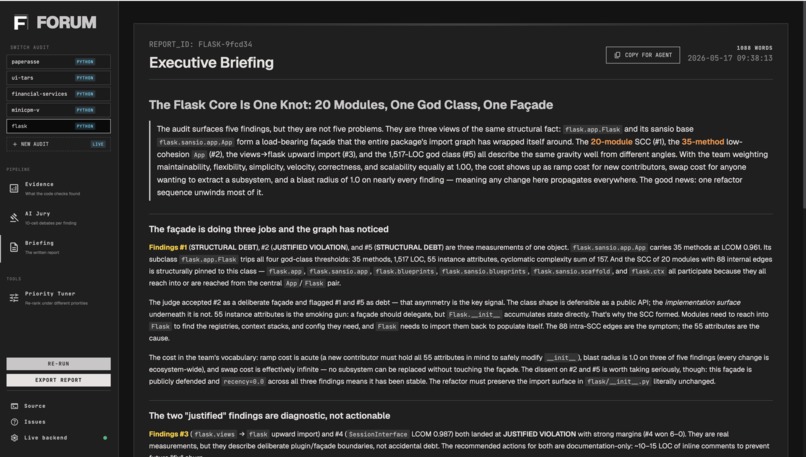
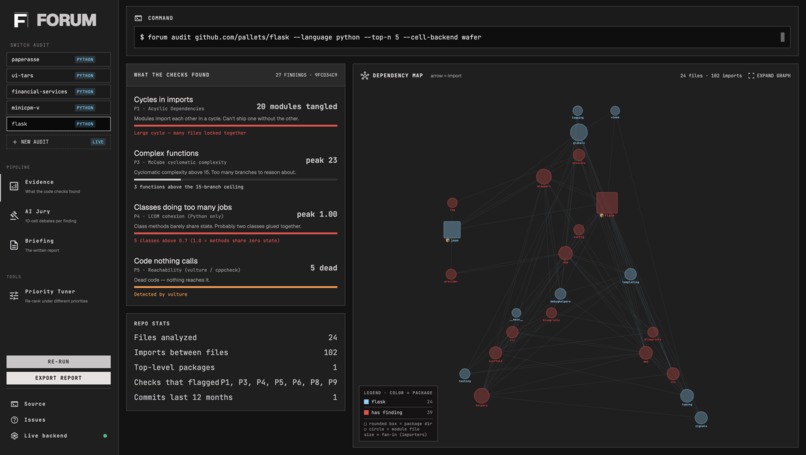
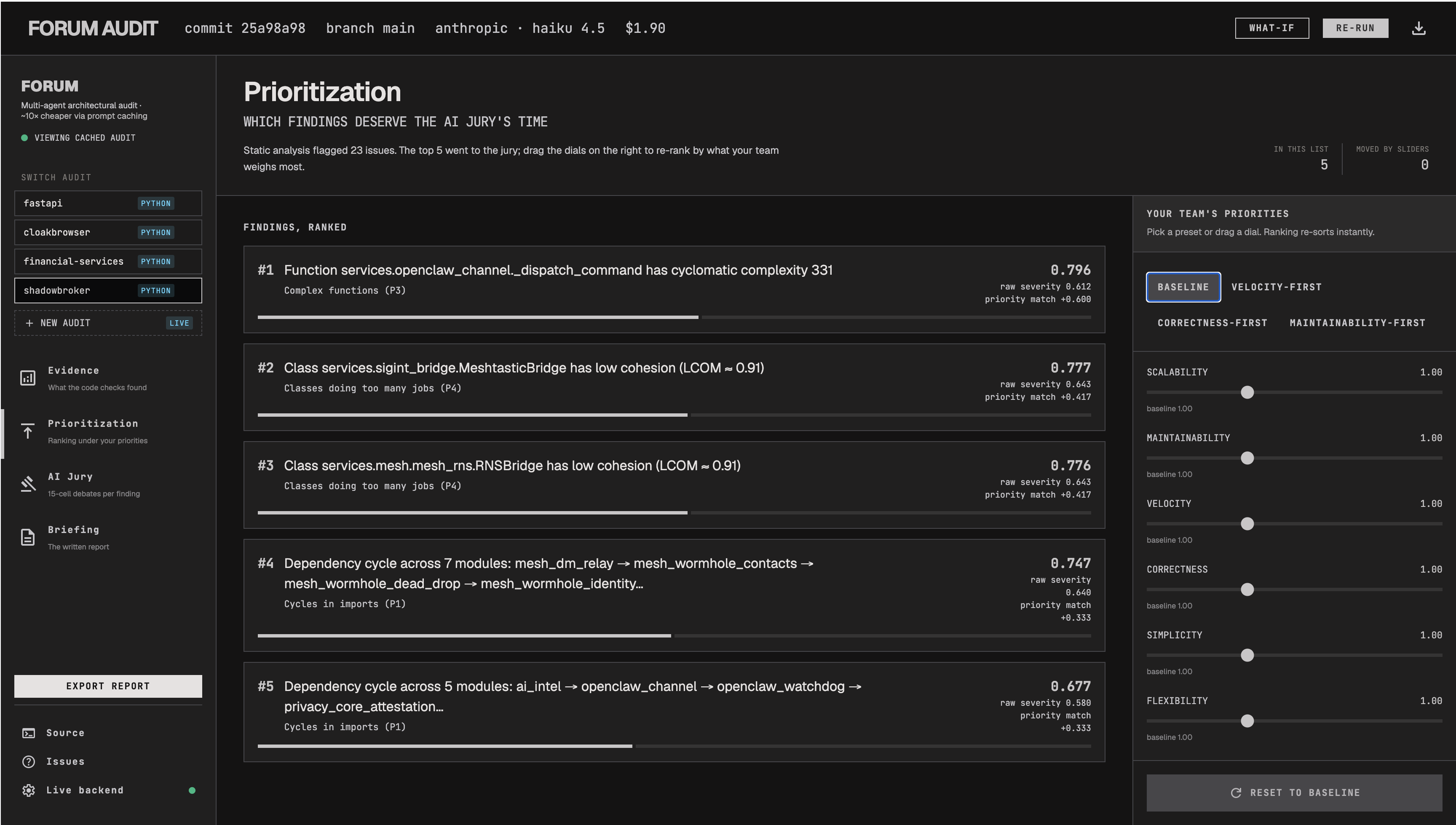
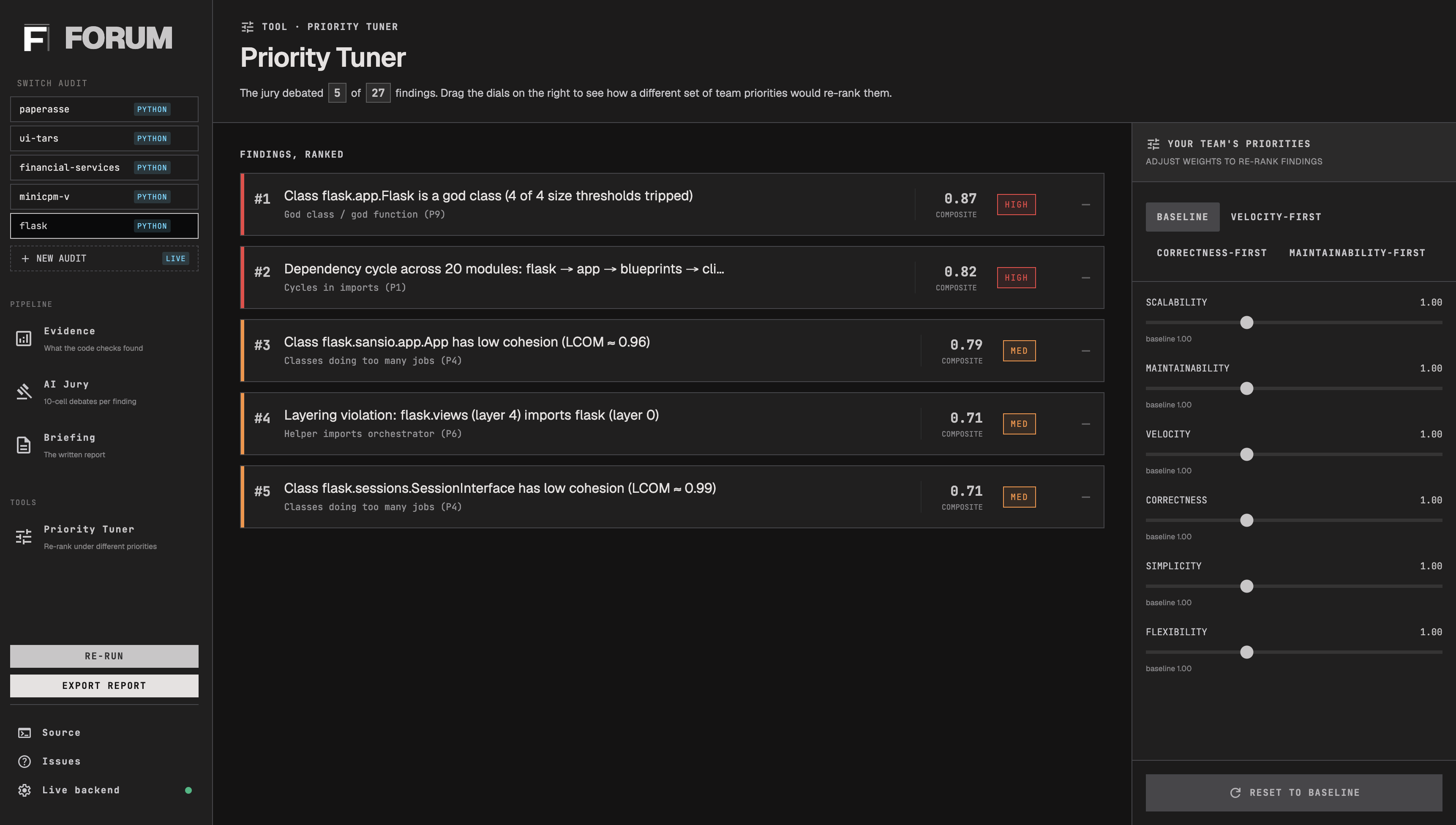
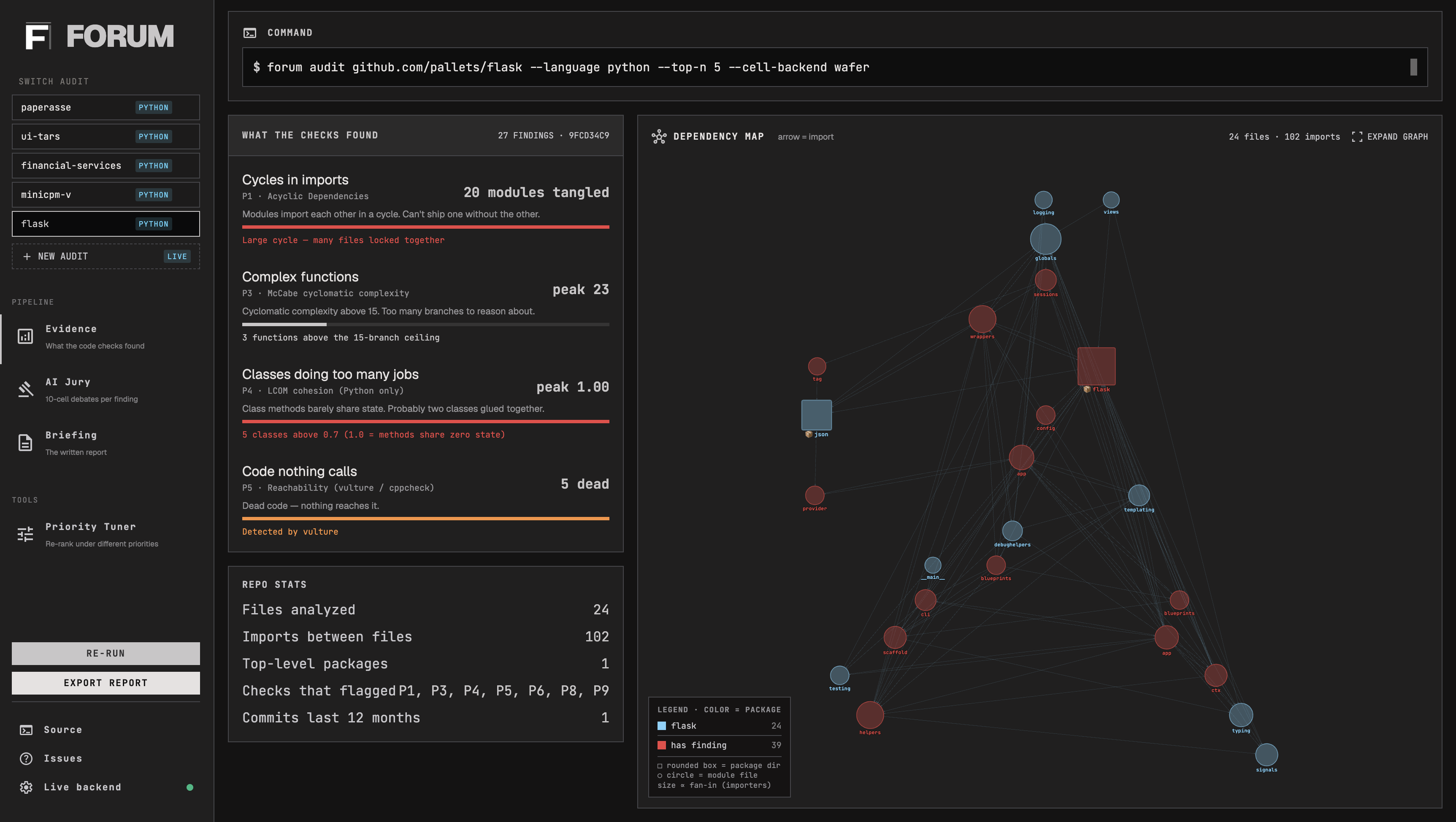
FORUM is a CLI tool: forum audit analyzes a Python or C repository and writes a self-contained audit directory (evidence.json, prioritized.json, verdicts.json, report.md, graph.svg, metrics.json), printing a word markdown briefing to stdout in about 90 seconds for under fifty cents. You configure how the briefing ranks findings with a six-dimensional value weight vector: scalability, maintainability, velocity, correctness, simplicity and flexibility, so the same evidence produces a different briefing under different weights.
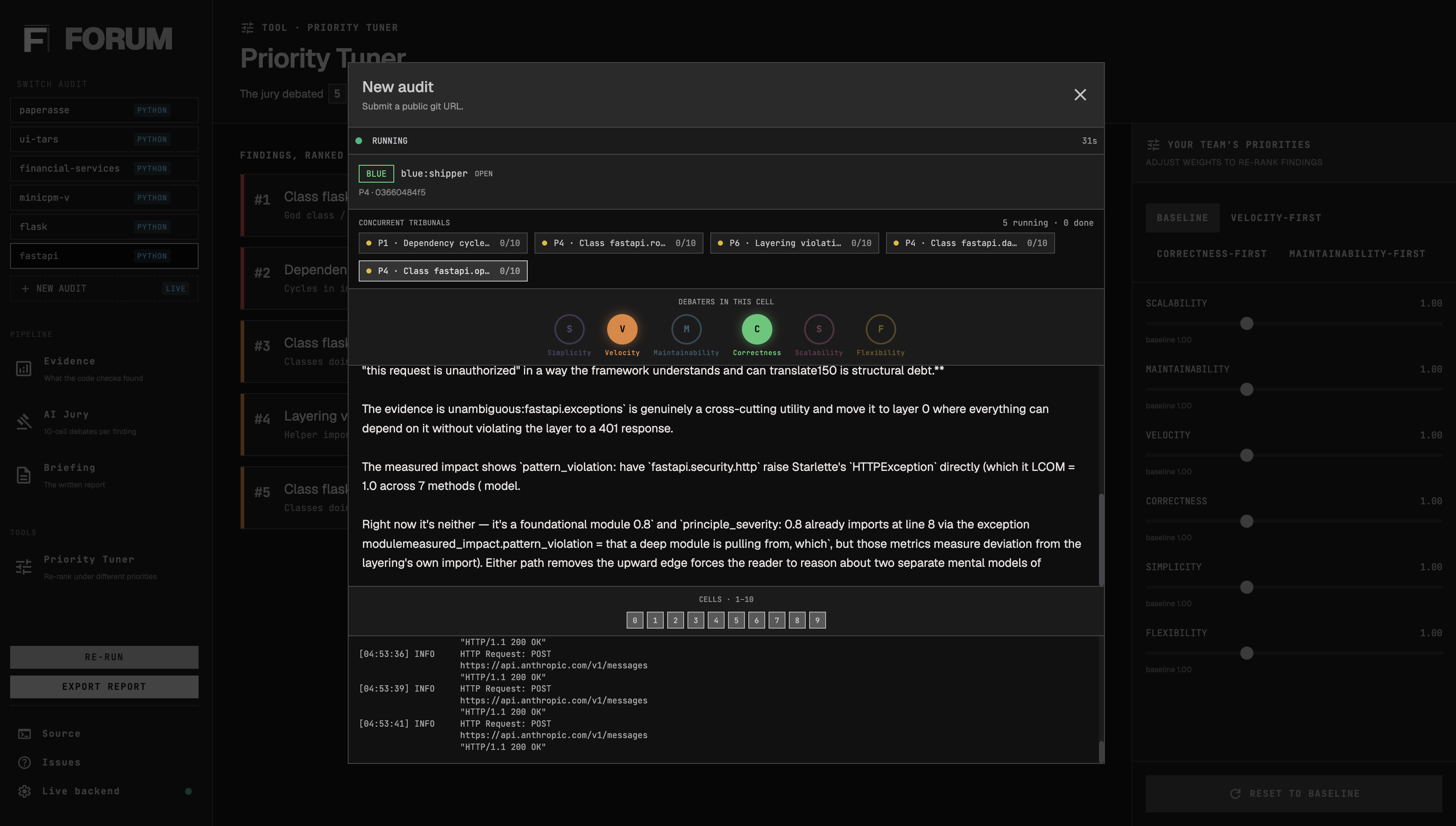
For the purposes of this hackathon, a FastAPI server wraps the CLI as a subprocess and streams its output via SSE; the browser UI (Cytoscape dependency graph, sliders that re-project rankings client-side, live per-tribunal progress) is a viewer on top of the JSON artifacts the CLI writes. Every measurement, cost number, and verdict you see in a screenshot came out of the same command you'd run on the terminal.
Under the hood there are four layers:
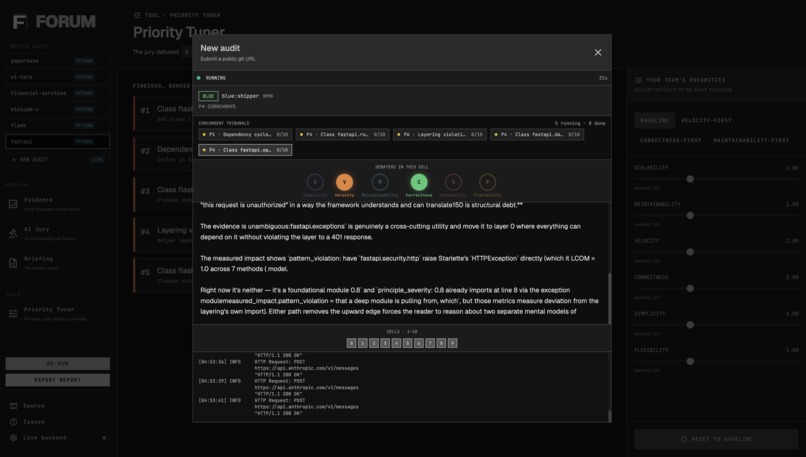
- Layer 1: Evidence. Ten deterministic checkers (acyclic deps, stable deps, cyclomatic complexity, LCOM cohesion, dead code, layering, common-closure via co-change, stable abstractions, god-class/function, jscpd duplication) run in parallel and produce a list of "decision points" — concrete structural facts about the code, each with measured impact. A module-level import graph built once at the start of Layer 1 backs three of the checkers (cycles, stability, layering) and is also rendered in the UI's Evidence view as a Cytoscape.js map - nodes colored by package, sized by fan-in, ringed red when a finding names them to visually ground our tool.
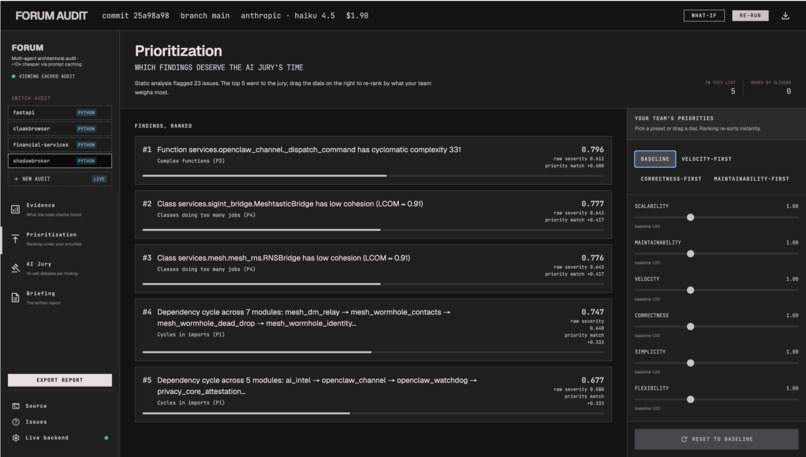
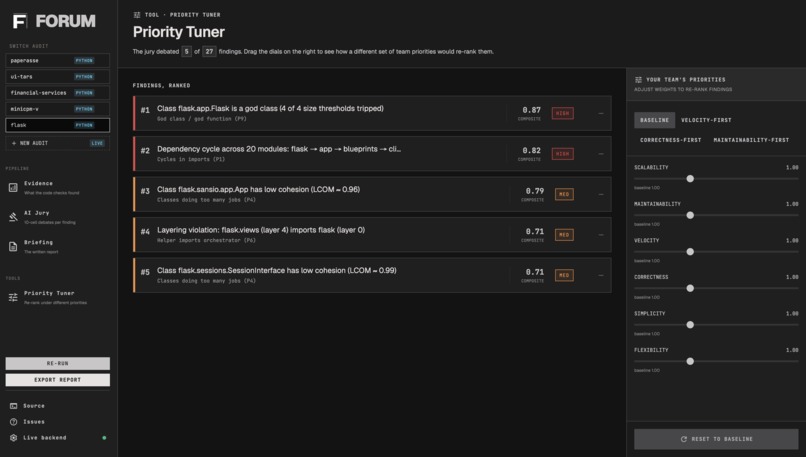
- Layer 1.5: Prioritization. Every decision point gets a composite score combining structural severity with how much your weight vector cares about the principle it violates. Adjusting a slider re-ranks the list client-side via the same math the backend uses, so you can play with weights without re-running anything.
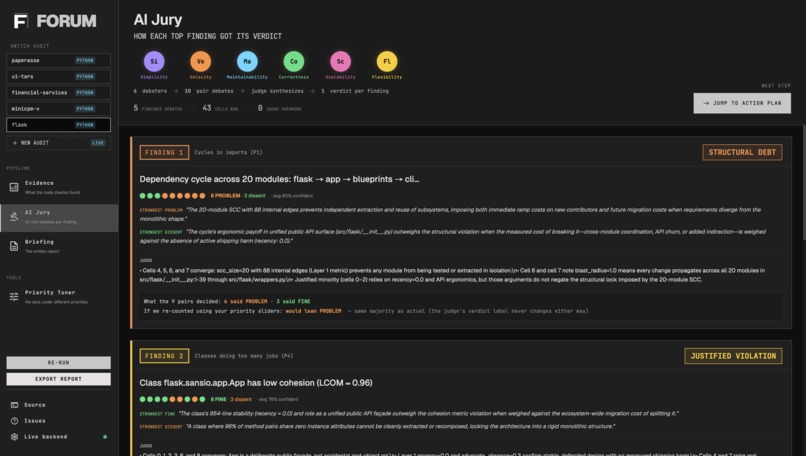
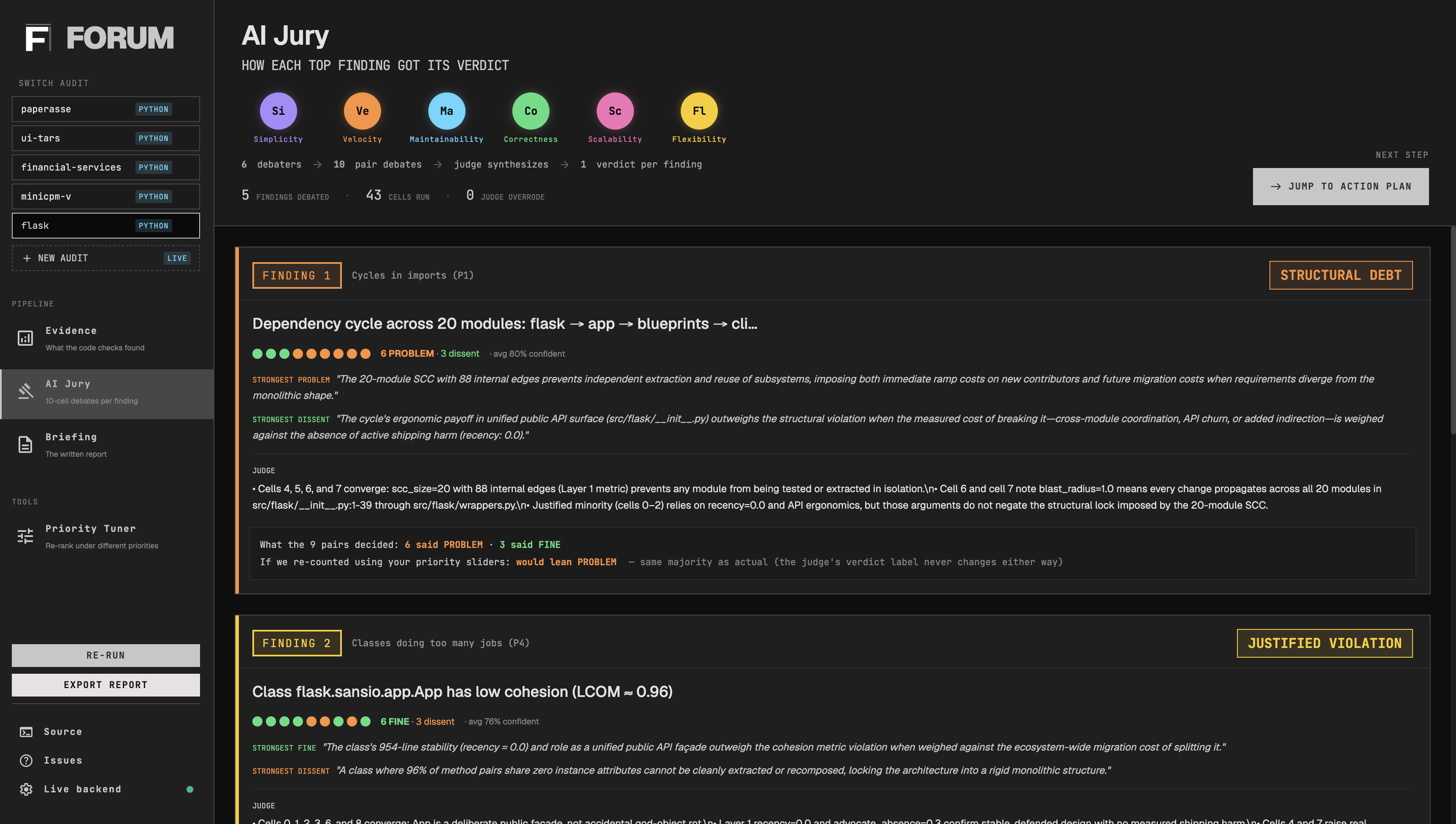
- Layer 2: Jury. For each top-ranked decision point, FORUM convenes a tribunal: fifteen LLM "debate cells," each a debate between two of six monomaniacal value personas (the Simplifier vs the Scaler, the Verifier vs the Shipper, etc.). Each cell votes debt or justified with a confidence and a value_lens that records which value drove the verdict. A Sonnet 4.6 judge then reads the transcripts and returns the literal verdict.
- Layer 3: Briefing. One Opus 4.7 call writes the markdown report, opening with whichever finding most aligns with the team's top-weighted values. Verdicts pass through literally; only the ordering and narrative voice are LLM-generated.
Finally, FORUM provides a what-if probe that re-projects any cached audit under alternate weights to show which dissents would have become salient.
Why we picked this workflow to optimize
Multi-agent ensemble judgment is everywhere right now. Every "AI code reviewer," "AI second opinion," "AI panel of experts" product is some flavor of "spin up N specialist agents, have them debate, aggregate." It's a great pattern for hard subjective questions. It's also, in its naive form, slow and expensive in ways that scale linearly with the panel size.
We measured our own first cut and it cost about $4 per audit and took about six minutes. That's not a usable product. The question we ended up spending most of the project on was: how cheaply can you actually run a 15-agent debate panel without degrading the verdict?
The answer turned out to be three compounding accelerations on top of the same workload:
- Cache-first prompt architecture. Anthropic's prompt cache reads at ~10% of input rate, but only if you hit a contiguous prefix ≥ 1,024 tokens that matches exactly across calls. The naive prompt format puts everything in one flat user message and varies the prompt slightly per agent, so nothing ever caches. We split every cell's prompt into three layers:
[ SYSTEM CACHED ] codebase + git summary (~3,500 tok — same for every cell in the audit) [ USER CACHED ] decision-point evidence (~2,000 tok — same for every cell in the tribunal) [ TAIL — uncached ] red/blue persona + temperature (~80 tok — varies per cell)
Cell 0 writes the cache (paying the 1.25× write premium). Cells 1–14 read it. Logged per-cell metrics from a recent run:
cell 0: 0.0% hit · read= 0t created= 5512t uncached= 84t $0.0192 cell 1: 81.7% hit · read= 5512t created= 0t uncached= 87t $0.0023 cell 2: 81.7% hit · read= 5512t created= 0t uncached= 91t $0.0023 ... warm-cache cells (≥1): 81.7% hit rate across 14 cells
The 15-cell tribunal's total input cost ends up around 2.5× the cost of a single cell, not 15×.
Speculative stopping. Most tribunals don't need all 15 votes. Once six cells have voted the same side with average confidence ≥ 0.7, the rest are cancelled cleanly. On clear verdicts (~70% of findings) this saves another 40% of the cell budget.
Parallel orchestration. The ten Layer-1 checkers are independent - most are I/O-bound (pydriller walking git history, AST parsing). We dispatch them through a thread pool. Layer-2 tribunals run as concurrent asyncio tasks, with per-tribunal partial writes to verdicts.json so the live UI can render the moment any one tribunal finishes.
The before/after
This is what we ended up with, measured against our own first uncached implementation of the same workflow:
$$ \begin{array}{|l|l|l|l|} \textbf{Metric} & \textbf{Naive baseline} & \textbf{Optimized} & \textbf{Speedup} \\ \text{Cost per full audit} & \sim\$4.20 & \sim\$0.42 & 10\times \\ \text{End-to-end wall-clock} & \sim 6\text{ min} & \sim 90\text{ s} & 4\times \\ \text{Cells per tribunal} & 15\text{ (always)} & 6\text{--}10\text{ (speculative)} & 1.5\text{--}2.5\times \\ \text{Layer-1 wall-clock} & \text{sequential } (\sim 24\text{ s}) & \text{parallel } (\sim 11\text{ s}) & \sim 2\times \\ \text{Cache-read ratio (warm cells)} & 0\% & 82\% & - \end{array} $$
How we built it
Backend: Python 3.12, Click CLI, Pydantic schemas, NetworkX for the import graph, radon and lizard for complexity, pydriller for co-change mining, jscpd (Node) for duplication. Inference through the Anthropic SDK with cache_control blocks on system and user prefixes; a parallel Wafer (GLM-5.1) backend so the 15-cell fanout can run on cheaper inference when latency budget allows.
Server: FastAPI with SSE streaming. The CLI emits FORUM_EVENT-prefixed JSON lines on stdout, the server forwards them to the browser, and the UI re-fetches partial artifacts as each tribunal completes.
Frontend: vanilla JS, Tailwind via CDN, Cytoscape.js + dagre for the dependency graph, marked + DOMPurify for the briefing. No build step, statically hostable on GitHub Pages.
Implementation details:
- Every part of the pipeline that can be deterministic is. audit-dir hash is content-keyed, persona pairings are a fixed schedule, temperature is a linear ramp by cell index, sort tie-breakers are explicit. Same repo + same weights = same audit, which means cache hits work and audits are diffable across weight changes.
- prioritized.json and verdicts.json write atomically via tmpfile + os.replace so a killed process can't leave half-written JSON.
- The verdict aggregator returns three outcomes (debt / justified / contested) rather than two. O(ur first version silently defaulted ties to "justified," which turned out to be hiding ~12% of cases where the panel was genuinely split.
- forum audit --replay re-emits a cached audit at demo pace with zero API calls, as a backstop for flaky-WiFi demos.
Challenges we ran into
Cancelling cells cleanly. Speculative stopping is conceptually simple, but the cancelled tasks need to be awaited or Python warns "Task was destroyed but it is pending!" and (on some httpx versions) leaks the connection. gather(*pending, return_exceptions=True) after the cancel call was non-negotiable.
The second was rate limits. Fifteen cells fanning out concurrently slammed Anthropic's 30K-input-tokens-per-minute Tier-1 cap and the cell failure rate hit ~85%. Adding a per-backend semaphore (3 in-flight max) plus a minimum-interval pacer plus exponential-backoff retries on 429/5xx took the failure rate to under 2%.
Accomplishments we're proud of
The cost number is the obvious one, and it's nice that it's auditable rather than estimated. But the thing we're more proud of is that the three accelerations compose cleanly: caching gives ~10× on cost, speculative stopping gives ~1.7× on top, parallel checkers give ~2× on Layer-1 wall-clock, and concurrent tribunals give another ~5× on Layer-2 wall-clock. None of them conflict — they multiply.
We're also proud that the values lens actually changes the output. On the FastAPI codebase, FORUM correctly identifies the known routing.py ↔ dependencies/utils.py cycle as the top finding under "we value maintainability," and correctly de-ranks it under "we value velocity" because the cycle has been stable for two-plus years and refactoring would block 18 modules. Same evidence, different briefing.
Generalizability
The pieces are decoupled by design. cache/prompt_cache.py is a ~400-line wrapper around the Anthropic SDK that any project can drop in — it exposes call_multiturn(system_cached=..., user_cached_prefix=..., turns=[...]) and accounts cost automatically, including the no-cache counterfactual. The OpenAI-compatible mirror (cache/wafer_cache.py) gives the same surface for any other provider.
jury/speculative.py's run_tribunal_speculative is generic over panel size, stopping threshold, and vote schema. We use it for code review; the same machinery would work for content moderation panels, legal QA ensembles, claim adjudication, or any "N agents debate, M agree to stop" pattern. jury/aggregate.py exposes the aggregator and stopping predicate as pure functions.
A team applying the same acceleration pattern to a different multi-agent workflow could lift any of these three pieces in isolation. The pattern — cache-first prompt layering + speculative stopping + parallel orchestration — is the real artifact; FORUM is one application of it.
What we learned
Prompt caching is an architecture, not an optimization. The 10× win came from designing the prompt for the cache, not from caching an existing prompt.
The hardest part of multi-agent systems isn't getting them to work — it's getting them to stop working when the verdict is obvious. Speculative stopping was a bigger lever than any model swap we tried.
Honest measurement is a feature. Logging no_cache_cost_usd alongside actual_cost_usd on every run kept us from over-claiming, and let us catch the timestamp-in-prompt regression the moment it happened.
What's next
The most exciting next step is cache-aware diff-mode audits. Run FORUM against a PR diff with the parent-branch audit's cache already warmed. Early measurements suggest ~30× cost reduction on small PRs because the cache is fully populated by the time the PR audit starts.
Beyond that: cross-tribunal cache sharing (repeated sub-prefixes across tribunals lifted into system-cached, projecting another ~30% savings), more languages (TypeScript and Go parsers are partially there), and extracting the acceleration harness into a standalone package so other teams can apply the same pattern to non-code workflows.
Built With
python · anthropic (Opus 4.7, Sonnet 4.6, Haiku 4.5) · prompt-caching · wafer (GLM-5.1) · openai-sdk · asyncio · fastapi · sse · click · pydantic · networkx · radon · lizard · pydriller · jscpd · cytoscape.js · dagre · marked · dompurify · tailwindcss
Built With
- asyncio
- click
- cytoscape.js
- dagre
- dompurify
- fastapi
- haiku
- jscpd
- lizard
- marked
- networkx
- openai-sdk
- prompt-caching
- pydantic
- pydriller
- python
- radon
- sonnet-4.6
- sse
- wafer


Log in or sign up for Devpost to join the conversation.