-
-

Agent A surfaces a CRITICAL allergy flag, ranks all alternatives by safety for this specific patient, and asks the doctor to choose.
-
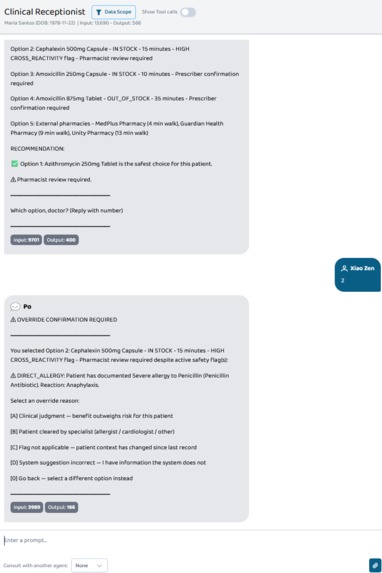
When a doctor selects a flagged option, the system blocks auto-approval and requires a stated clinical reason before dispensing proceeds.
-
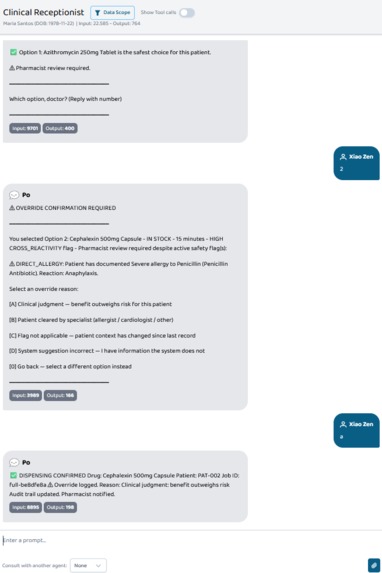
Doctor-led override recorded to HMAC-signed audit trail: the system records, it doesn't decide.
-
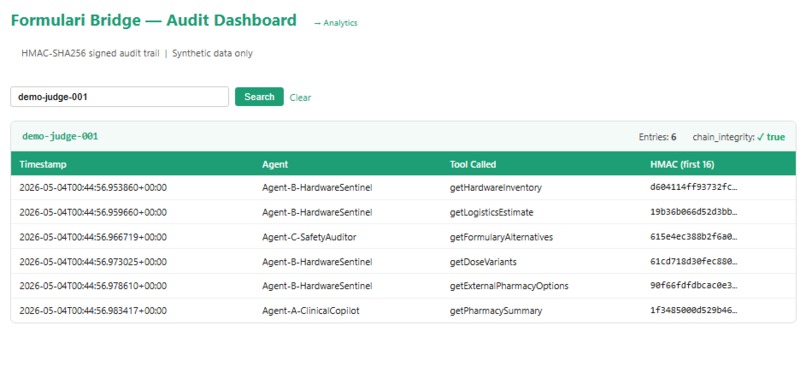
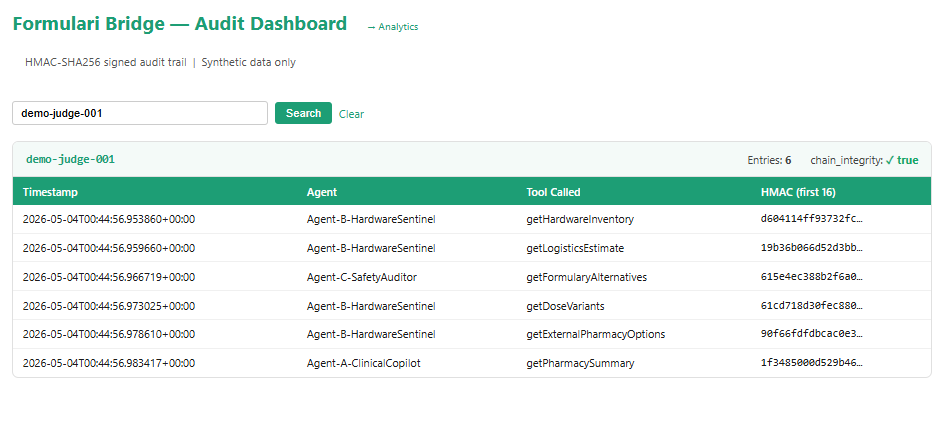
Immutable logging: Every multi-agent interaction is HMAC-SHA256 signed to guarantee data integrity.
-
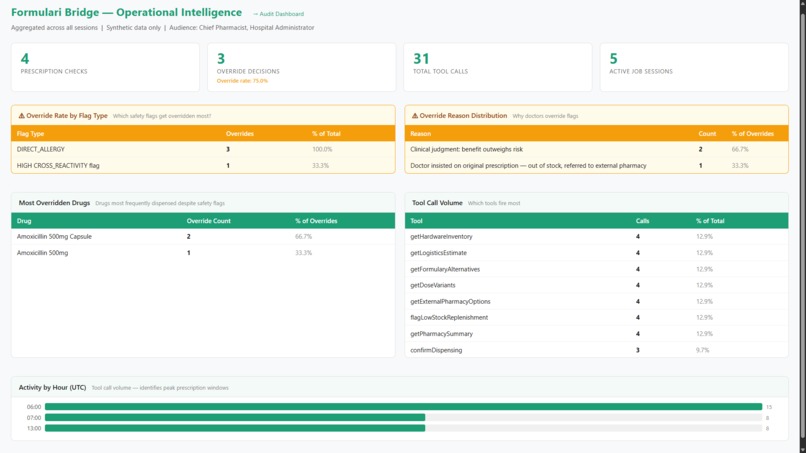
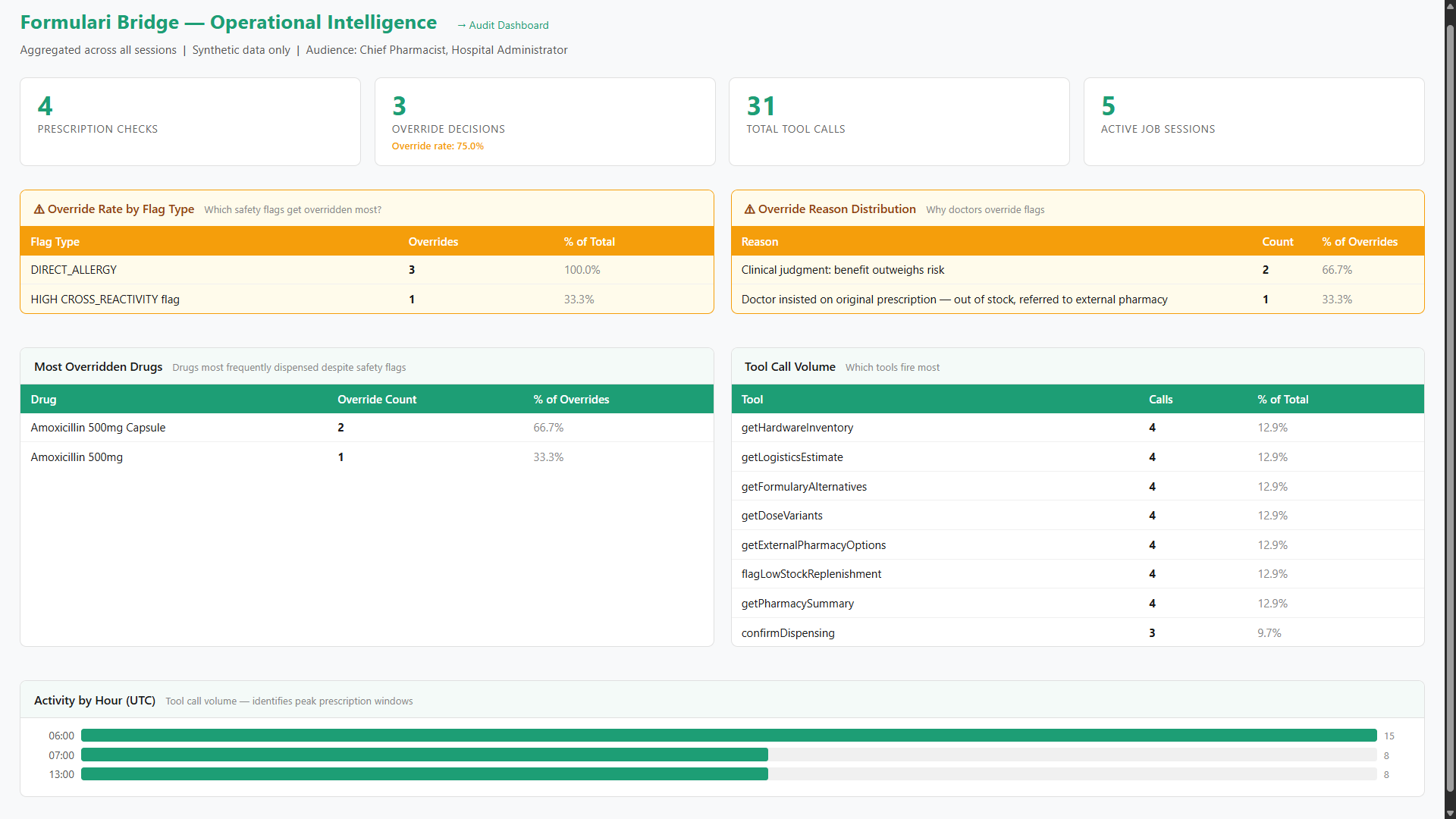
Data-driven oversight: Monitoring override rates, drug trends, and distribution patterns in real-time.
-

Full-stack pharmacy logistics: 11 MCP tools for A2A agents, from inventory to tamper-evident audits.


Formulari Bridge — Devpost Project Story
The problem
When a prescribed drug is out of stock, the current process is a phone call. The pharmacist calls the doctor. The doctor suggests an alternative. The pharmacist checks if it's in stock. If not, they call again. This loop takes 15 to 45 minutes while the patient waits — and it happens dozens of times a day in every outpatient pharmacy.
The waste is not just time. It's cognitive load distributed across two professionals who shouldn't have to coordinate manually. The doctor doesn't know what's on the pharmacy shelf. The pharmacist doesn't have full context on the patient's allergies, renal function, and current medications. So they trade phone calls — each one a partial picture — until they converge on something that works.
Under that time pressure, the wrong substitute gets dispensed. A patient with documented penicillin anaphylaxis receives a cephalosporin. A patient on warfarin gets a macrolide that elevates their INR. These adverse drug events are preventable — but only if the right information reaches the right person at the right moment.
What Formulari Bridge does
Formulari Bridge replaces the phone loop with a one-second workflow.
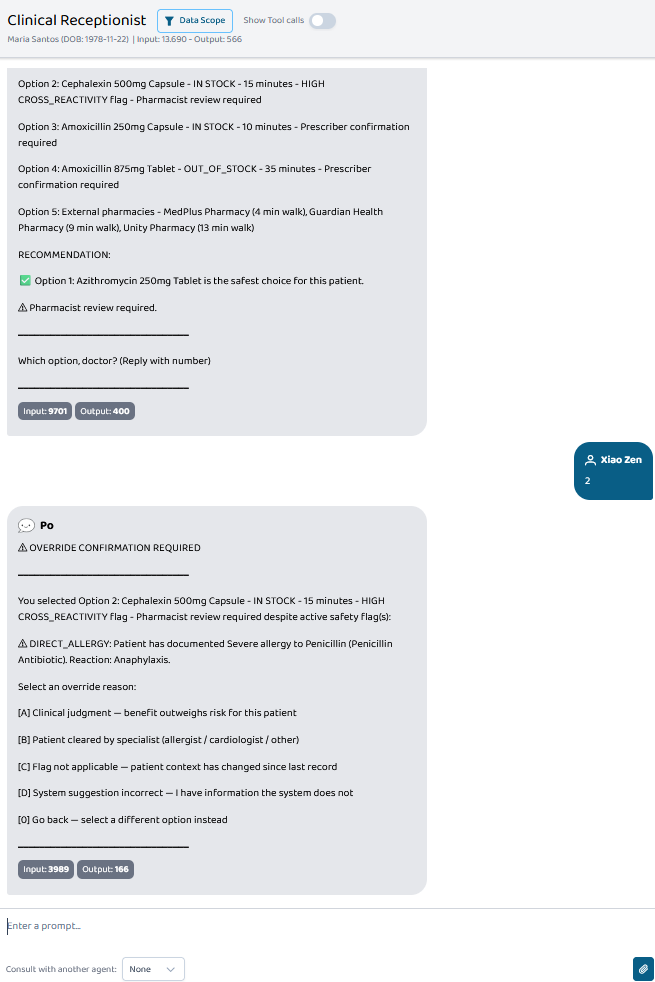
The doctor types a drug name and patient ID. The system simultaneously checks real-time ADC inventory, screens every alternative against the patient's live FHIR record, ranks the options from safest to least safe for this specific patient, and returns a structured menu the doctor can act on immediately.
The doctor picks a number. The pharmacist dispenses it. No phone calls. No waiting. The substitution decision is still made by the doctor — but the legwork, cross-referencing, and safety screening that used to require two people coordinating over the phone is done in parallel by the agent system in under a second.
The output is a decision, not a question.
Why this matters
A traditional formulary system can tell you what's in stock. A traditional CDSS can tell you what's contraindicated. Neither closes the loop. Both still require a human to reconcile inventory with safety, in their head, under time pressure, while the patient waits.
Formulari Bridge closes the loop. The agent system is the third actor in the room — the one that does the cross-referencing so the doctor and pharmacist don't have to.
| Without Formulari Bridge | With Formulari Bridge |
|---|---|
| Pharmacist calls doctor when drug is out of stock | Doctor sees stock status before prescribing |
| Doctor names an alternative blind to patient labs | Patient context is on screen, automatically |
| Pharmacist re-checks stock and safety | Stock + safety pre-screened in parallel |
| 15–45 minutes per substitution | ~1 second per substitution |
| Wrong substitute risk under time pressure | Ranked menu pre-filtered for this patient |
Why this requires Generative AI — not just a rules engine
A rules engine alone can fire flags. What it cannot do — and what makes Formulari Bridge work as a closed loop — is three things only an LLM can:
Patient-specific synthesis in plain English. Translating "CROSS_REACTIVITY flag, severity HIGH" into "this patient's documented penicillin anaphylaxis raises the cephalosporin cross-reaction risk above the baseline 1–2% — pharmacist review required before dispensing" requires understanding patient context, not matching codes. Agent C does this synthesis. It never invents flags — only explains what the rules engine returned.
Free-text clinical intent mapping. When a doctor writes "patient needs antibiotic for UTI, avoid fluoroquinolones due to prior resistance", no rule engine maps that free-text note to a specific drug class. Agent 0 does, using GPT-4o with 25 clinical note training pairs.
Multi-agent A2A orchestration. Four specialised agents — classifier, orchestrator, data sentinel, safety synthesiser — collaborate over a live FHIR record in under a second. That coordination is the A2A protocol doing work no single rule engine or monolithic LLM call replicates.
The rules engine fires the flags. The LLM closes the loop. Neither works without the other.
Agent architecture
Agent 0 — Clinical Classifier reads the doctor's free-text clinical note and maps it to a drug class. Grounded on 25 GPT-4o generated training pairs. Only fires when the doctor writes a note instead of naming a drug directly.
Agent A — Clinical Receptionist extracts the drug name, orchestrates the full workflow, and is the doctor-facing entry point. Presents results and waits for explicit confirmation before any dispensing proceeds.
Agent B — Hardware Sentinel calls runFullPharmacyCheck_mcp — a single tool executing the complete 7-step workflow in parallel: inventory, logistics, formulary alternatives with contraindication flags, dose variants, external pharmacy options, replenishment alert, and HMAC audit trail. Response time: ~629ms.
Agent C — Clinical Synthesiser produces a patient-specific safety ranking in plain English. Explains flags — never invents them. No MCP tools — reasoning only.
FHIR R4 integration
We self-host a FHIR R4 compliant server serving synthetic patient bundles. Patient context propagates through the agent chain via the Prompt Opinion SHARP extension — patient ID and FHIR token injected at session start, flowing through every tool call without re-authentication.
Endpoints served: /fhir/metadata (CapabilityStatement), /fhir/Patient/{id} (full Bundle with AllergyIntolerance, Observation, and MedicationStatement resources). All data carries the FHIR R4 SUBSETTED security tag marking it as synthetic.
How it stays deployable in a real hospital
The time-savings story is the value proposition. The trust architecture is what makes the system shippable past a CISO. We built both, and they are complementary — not competing.
Rules engine for safety-critical logic. All 9 contraindication flags come from hardcoded rules, not LLM inference. A compliance officer can read the rules and verify them line by line. The LLM never generates a clinical flag from its training knowledge — it only explains what the rules engine already determined.
Doctor always confirms. No auto-approval anywhere in the system. Final decision authority stays with the prescriber. The agent system surfaces a ranked menu — the doctor picks.
HMAC-SHA256 signed audit trail. Every tool call across the entire agent chain is signed. The chain_integrity: true flag means no entry has been tampered with since it was written. This is the forensic layer that makes the system auditable for regulatory review.
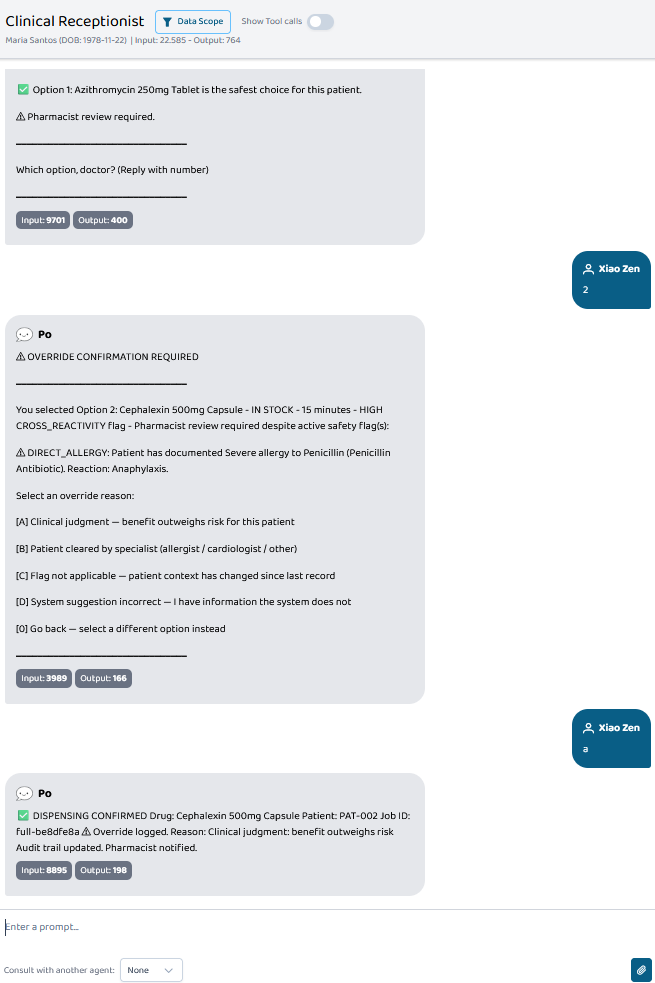
Override flow for compliance. When a doctor sees a flagged option and chooses to dispense it anyway, the system blocks auto-proceed and requires a stated reason. That's a hospital deployment requirement — not the main feature. But it produces a useful side effect: aggregated override patterns become operational intelligence for the Chief Pharmacist via the /analytics dashboard, showing which flag types are routinely overridden and why.
No raw PHI to the LLM. Patient context propagates via SHARP extension hashes, not raw record content passed to the model.
Demo scenarios
PAT-002 — Penicillin anaphylaxis, in one second
Amoxicillin 500mg prescribed for Maria Santos, documented penicillin anaphylaxis. The system flags Amoxicillin as CRITICAL (direct allergy, out of stock), flags Cephalexin as HIGH risk (cross-reactivity), and surfaces Azithromycin as RECOMMENDED. Total time from prescription to ranked menu on doctor's screen: ~1 second.
In the old workflow, this scenario takes a phone call to the doctor, who has to remember the cross-reactivity rate for cephalosporins in penicillin-anaphylactic patients, then think of an alternative, then wait for the pharmacist to check stock again. Here, it's already done.
PAT-005 — Polypharmacy complexity caught in parallel
Azithromycin 250mg for David Mensah, 81. CKD Stage 4, QTc 462ms, on Warfarin and Amiodarone. Two simultaneous flags fire: QT_PROLONGATION (triple additive risk — drug + prolonged QTc + amiodarone) and DRUG_INTERACTION (CYP3A4 inhibition elevates warfarin levels). Doxycycline surfaces as the safe alternative.
This is the case that traditional workflows fail. Two independent risks, both real, both requiring patient-specific lab values to identify. A pharmacist on the phone catches one of them maybe. The system catches both, in parallel, in under a second.
Try it yourself
| Patient | Condition | Prescribe this | What happens |
|---|---|---|---|
| PAT-001 | Healthy | Amoxicillin | Clean fast path, no flags |
| PAT-002 | Penicillin anaphylaxis | Amoxicillin | CRITICAL allergy + HIGH cross-reactivity |
| PAT-003 | CKD Stage 3 + Warfarin | Azithromycin | DRUG_INTERACTION flag |
| PAT-004 | Penicillin allergy + CKD | Ibuprofen | Two flags simultaneously |
| PAT-005 | Polypharmacy + QT risk | Azithromycin | QT_PROLONGATION + DRUG_INTERACTION |
For PAT-002: after seeing results, select Option 2 (Cephalexin — flagged) to trigger the override flow. This demonstrates the compliance layer required for hospital deployment.
Live endpoints
- Health check
- Audit dashboard — HMAC-signed tamper-evident trail
- Analytics dashboard — override rates, flag patterns, activity by hour
- API docs — all 11 MCP tools with live testing
- GitHub
- Demo Video
What we learned
The hardest problem in clinical AI is not clinical intelligence — it is closing the loop. Doctors and pharmacists already know enough to make safe substitution decisions. What they don't have is the time, the shared context, and the cross-referencing in one place.
We built the closer. The rules engine handles safety-critical logic — auditable, deterministic, the kind of thing a compliance officer can sign off on. The LLM handles synthesis and orchestration — the part that turns raw data into a ready-to-act decision in plain English. Together they replace a 45-minute phone loop with a one-second workflow.
The integration work was the real challenge. FastMCP SSE transport compatibility with Prompt Opinion's A2A protocol required significant debugging. The SHARP FHIR context extension required patching FastMCP's create_initialization_options method to inject the correct capability key. LLM agents in A2A chains are inconsistent about multi-step tool orchestration — we solved this by consolidating the 7-tool workflow into a single runFullPharmacyCheck endpoint that the agent calls once. And the most useful debugging lesson: check the model before debugging infrastructure. What appeared to be SSE transport failures were resolved immediately by switching to Gemini Flash.
What's next
Near-term: Multi-drug prescription handling and patient refusal workflows — both partially scoped and ready to build.
Data expansion: Synthea-generated training data for the Clinical Classifier, expanding beyond the current 25 clinical note examples.
Long-term: On-premise clinical LLM per hospital region. Patient data never leaves institutional infrastructure. Federated model training shares only model weights across regional networks, not patient data. HIPAA-compliant by design. This addresses the single biggest barrier to hospital AI adoption: data sovereignty.
Citation
Watanabe JH, McInnis T, Hirsch JD. Cost of Prescription Drug–Related Morbidity and Mortality. Annals of Pharmacotherapy. 2018;52(9):829-837. doi:10.1177/1060028018765159. PMID: 29577766.

Log in or sign up for Devpost to join the conversation.