-
-
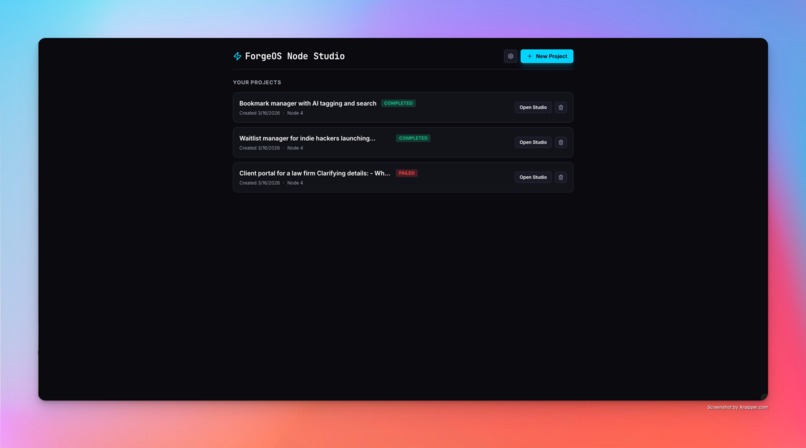
Project list
-
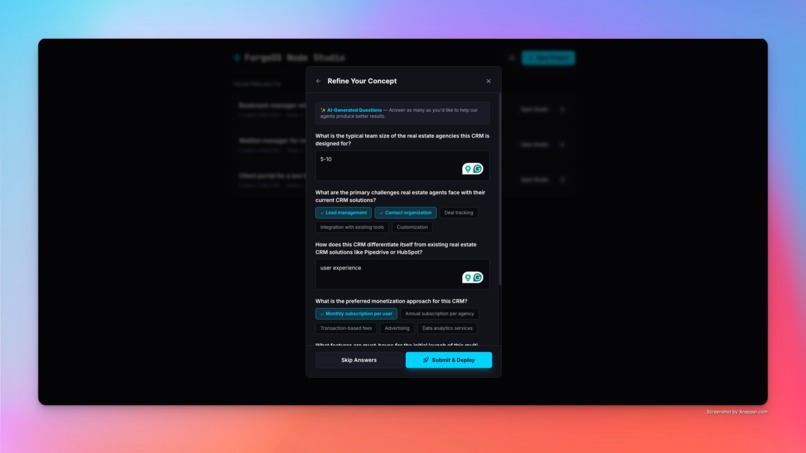
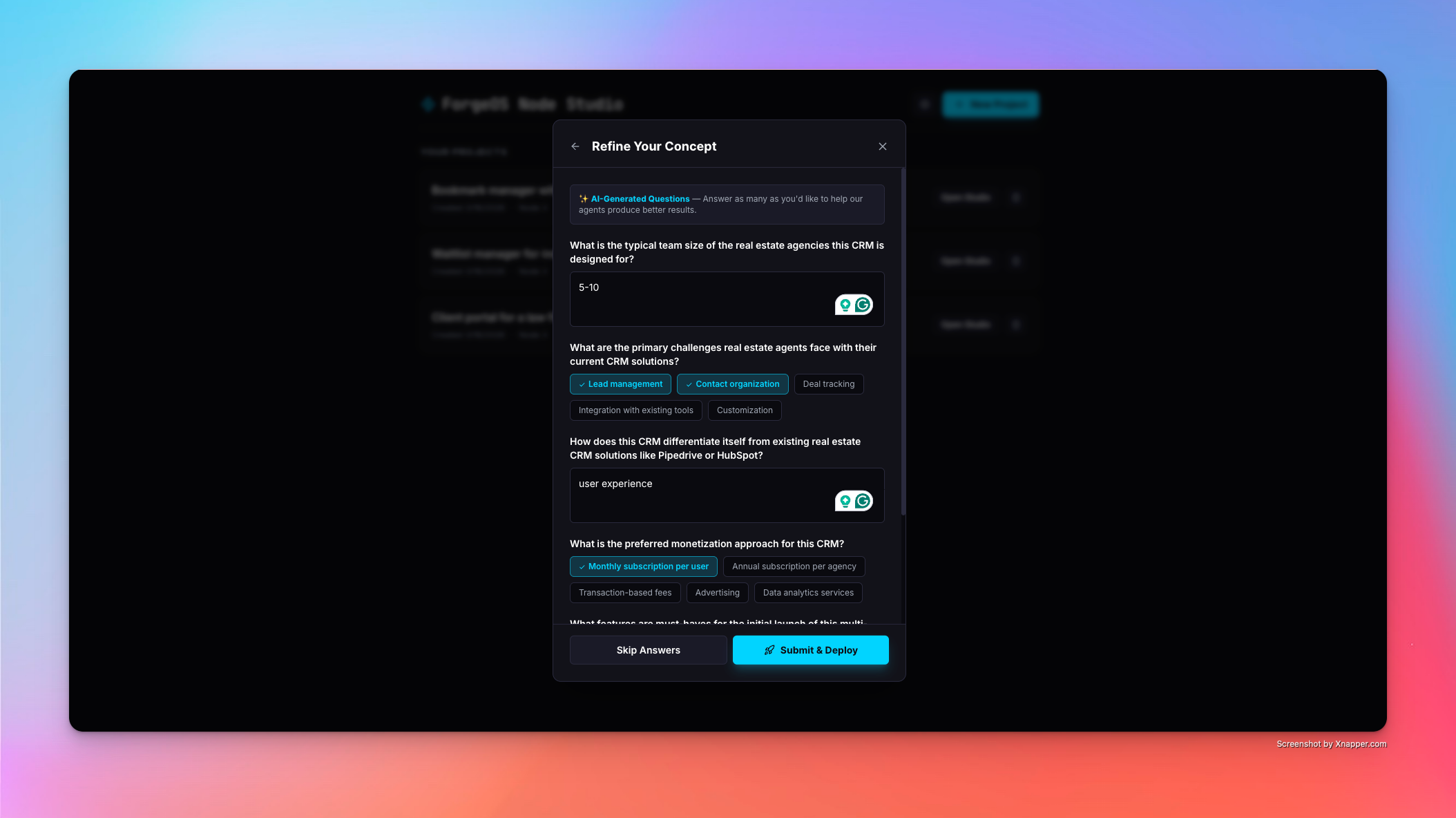
AI Q&A to refine your idea
-
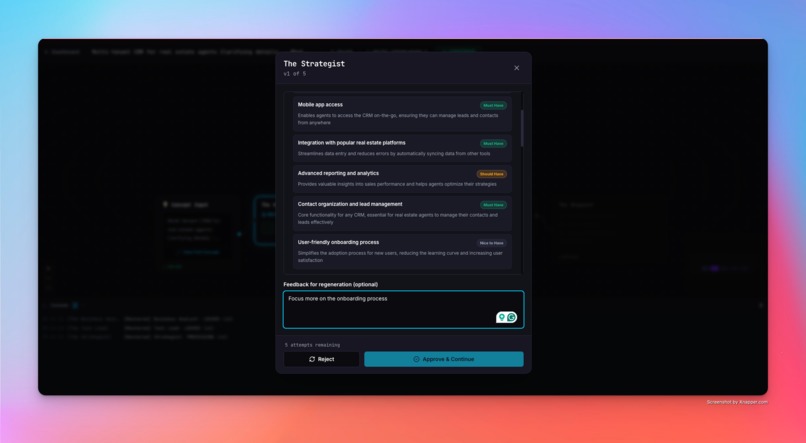
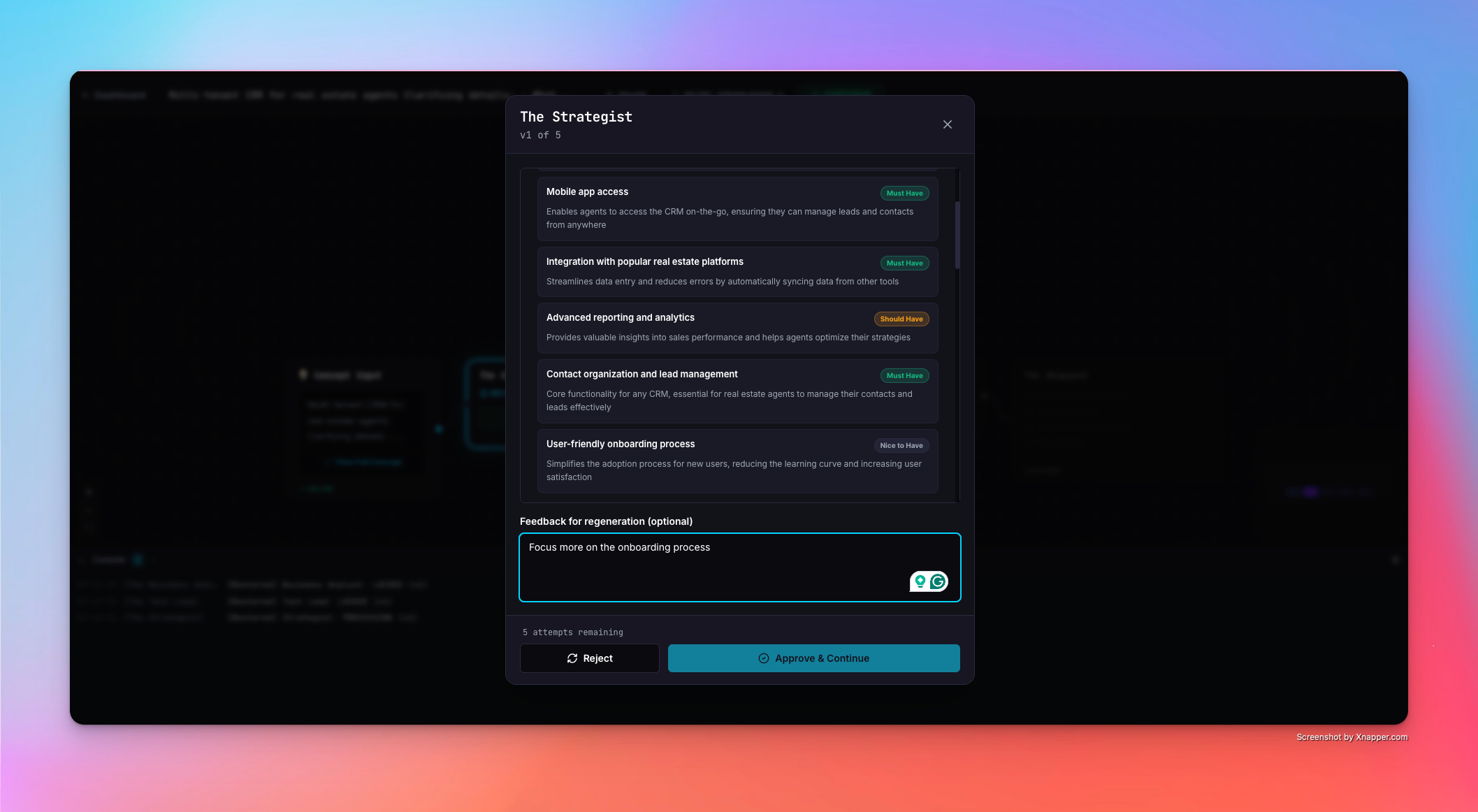
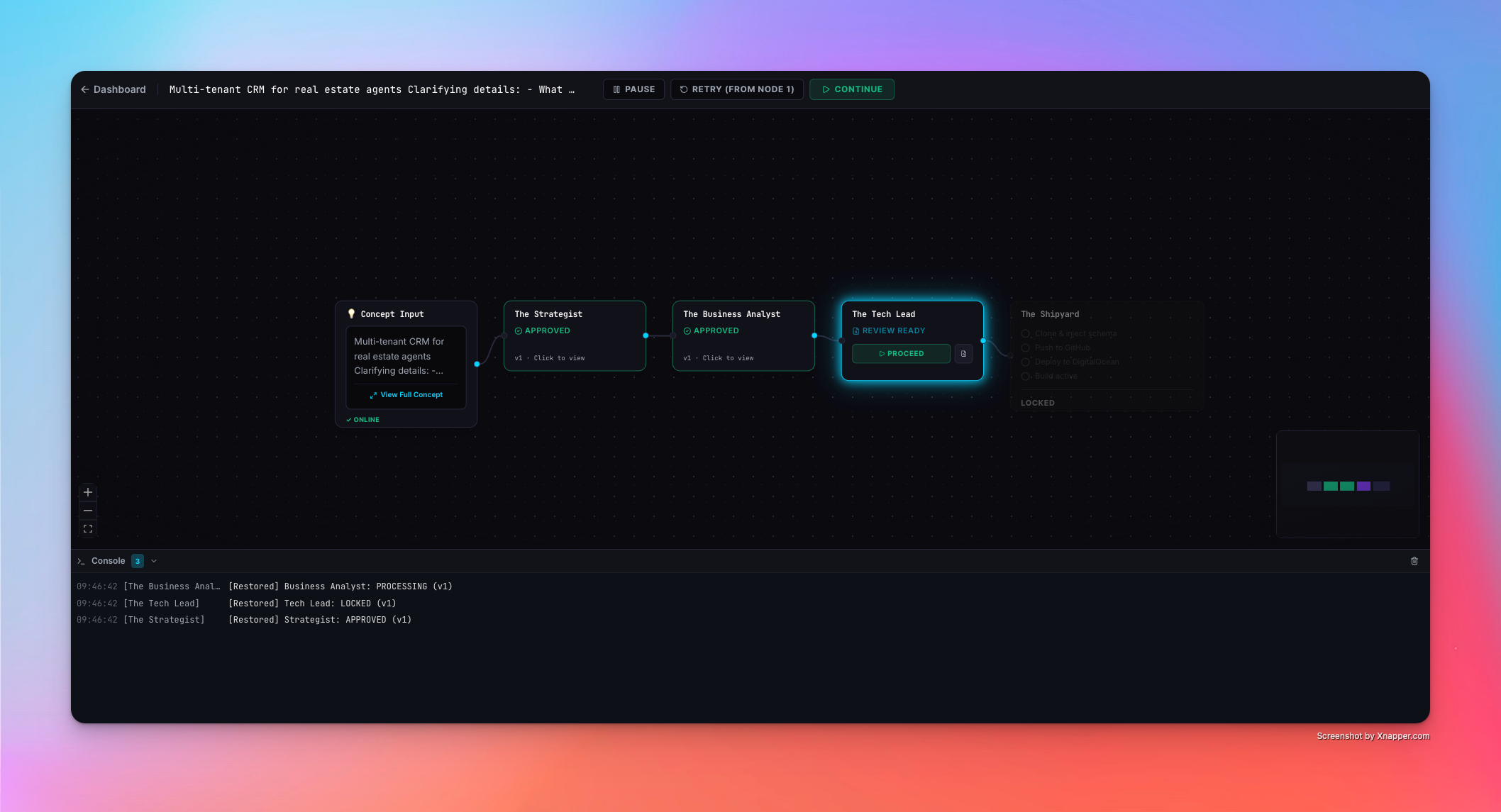
HITL at every step
-
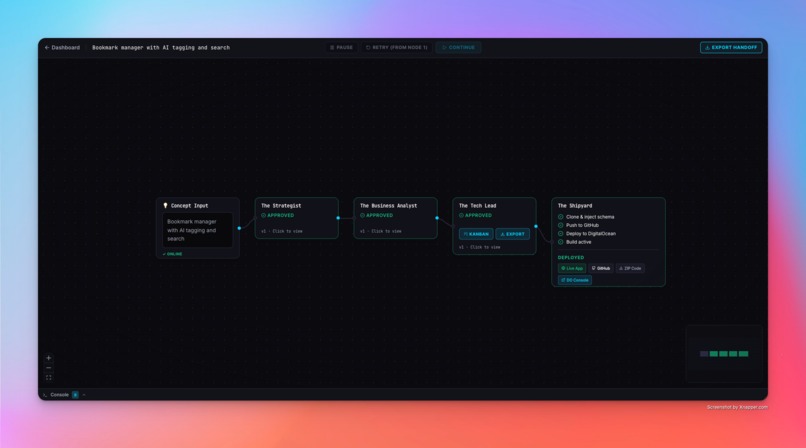
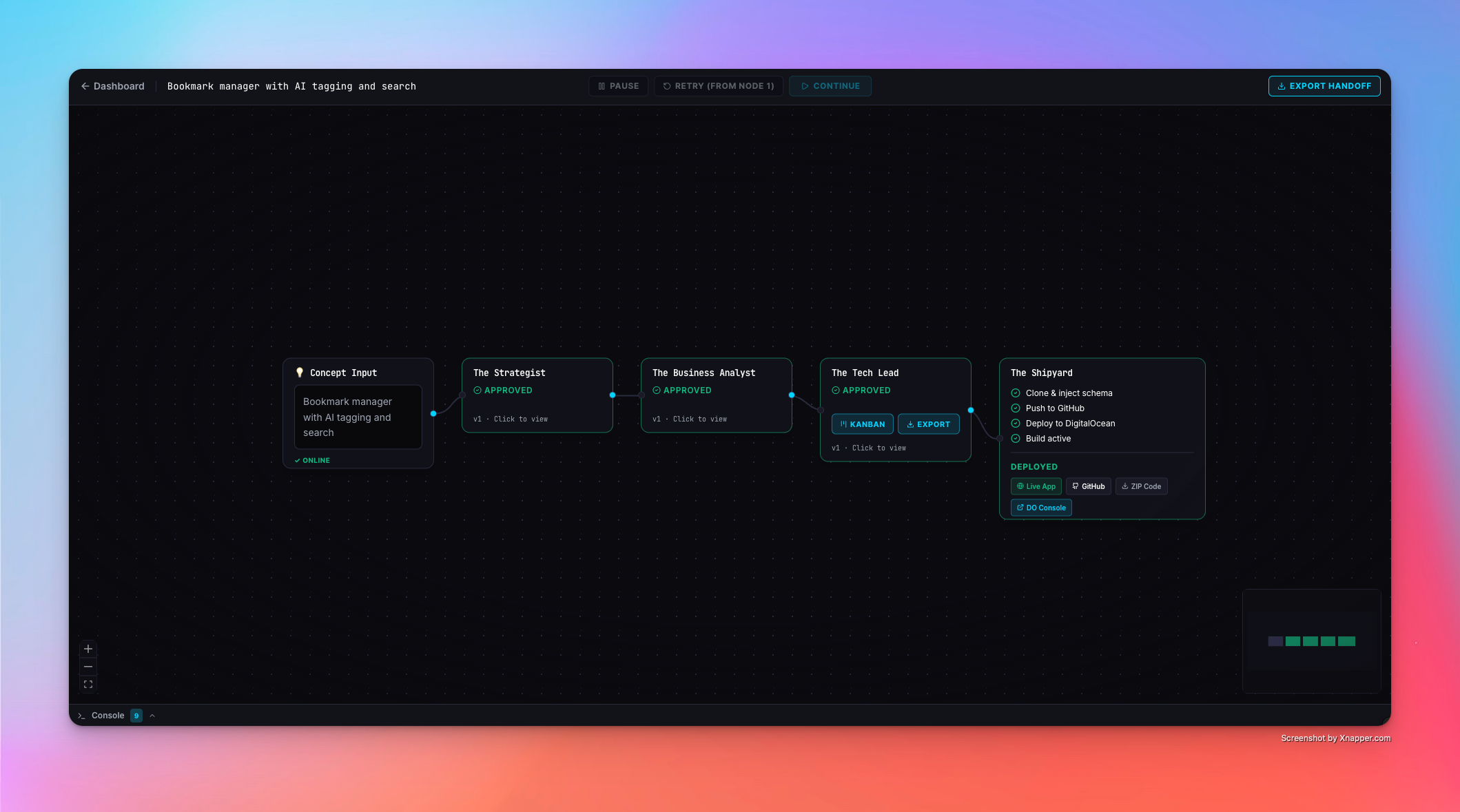
Fully deployed flow
-
Studio with terminal console
-
Deploy the app on DO
-
Handoff markdown file for your AI
Inspiration
Vibe coders move fast. They have great ideas, open Cursor or Claude Code, and start prompting — but skip the planning phase entirely. The result is spaghetti code, no clear architecture, and a product that drifts from the original vision.
ForgeOS was built to fix that. Before you write a single line of code, you need a market strategy, a product backlog, and a technical spec. We wanted to automate that entire "thinking phase" — and hand developers a structured foundation they can actually build on.
What It Does
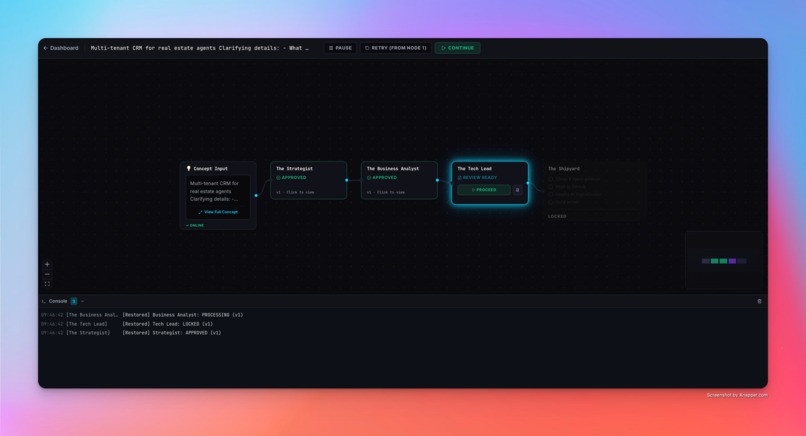
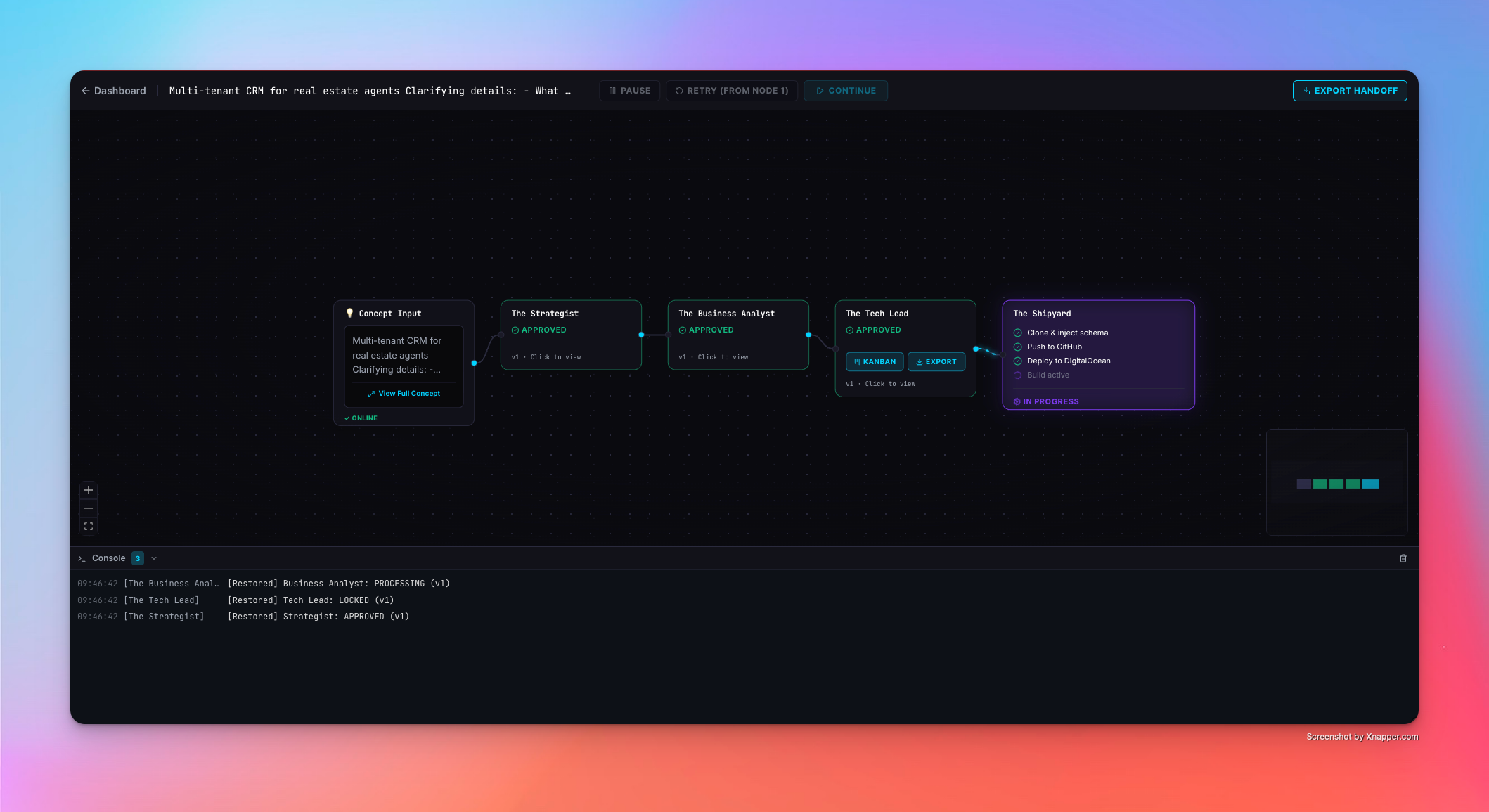
ForgeOS is a multi-agent SaaS incubation platform. You input a raw concept — "a client portal for law firms" — and ForgeOS first asks clarifying questions to sharpen the brief. Once the concept is clear, a pipeline of three specialized AI agents analyzes it end-to-end on a visual node canvas:
- The Strategist — market fit, target audience, MVP features, monetization strategy
- The Business Analyst — user personas, user stories, data entities, integrations
- The Tech Lead — tech stack decisions, Prisma schema delta, API endpoints, environment variables
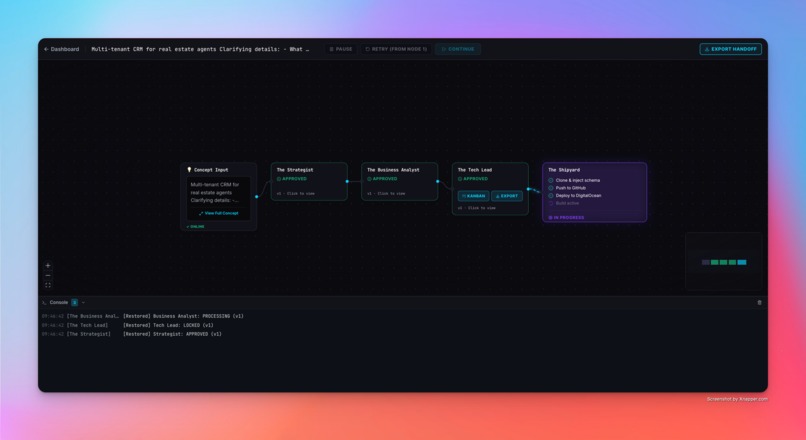
Every agent goes through Human-in-the-Loop review. You read the output, push back with feedback, and the agent regenerates — tracked with a version counter. Once all agents are approved, The Shipyard automatically clones a golden Next.js boilerplate, injects the AI-generated schema, pushes it to a new GitHub repository, and deploys it live on DigitalOcean App Platform.
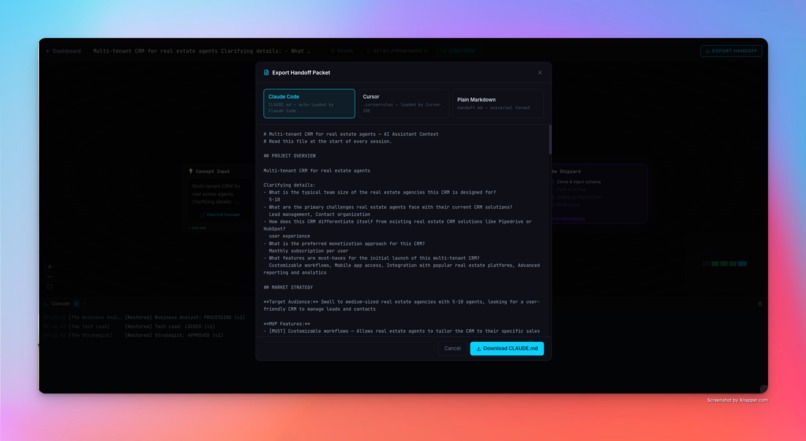
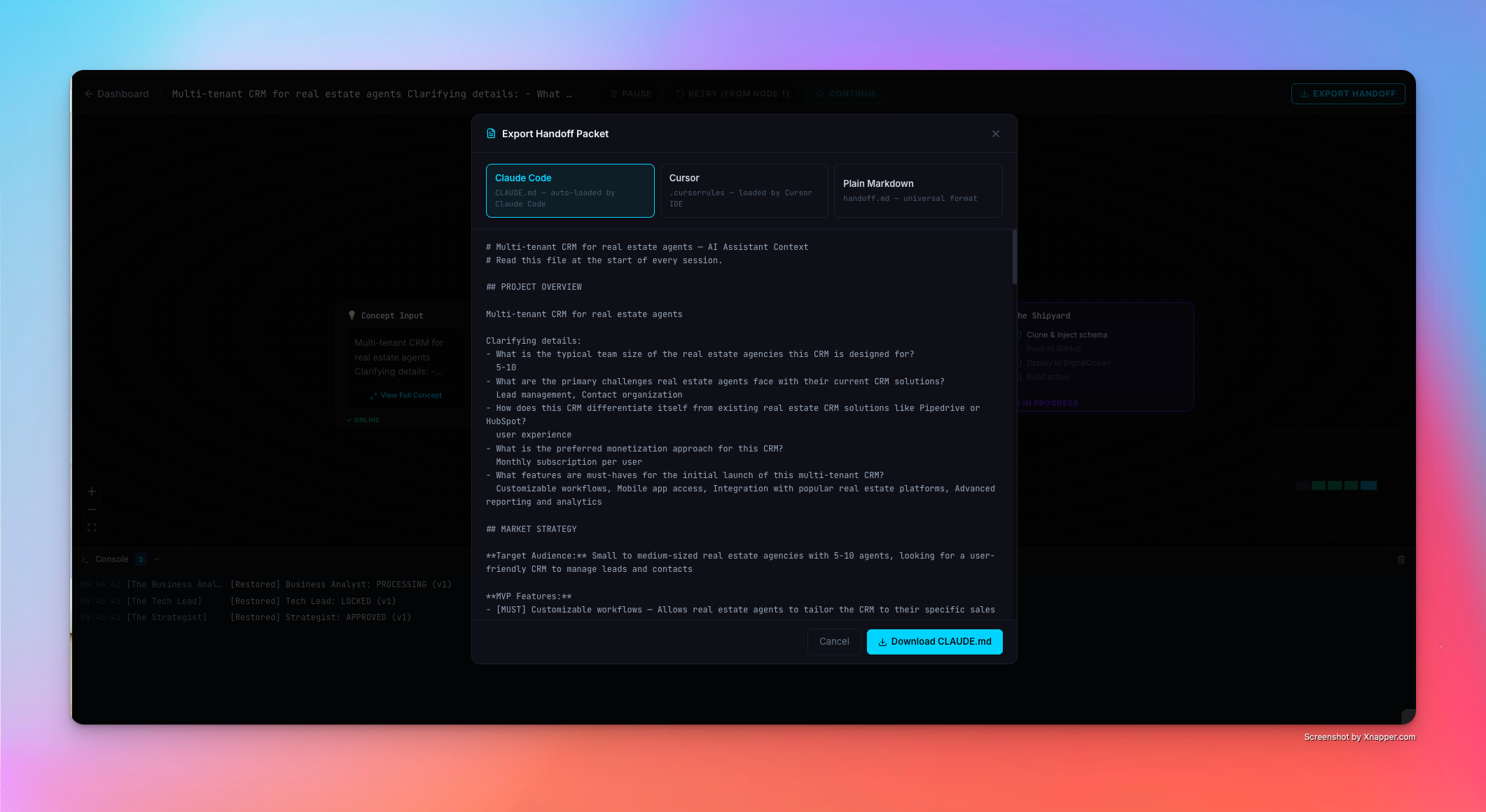
The final output is a real, running application — not a mockup. Plus a one-click export of a CLAUDE.md, .cursorrules, or plain Markdown handoff document so your AI coding tool can continue building immediately.
How We Built It
ForgeOS is a pnpm monorepo with two main services:
Backend (Express + TypeScript): Agent pipeline orchestrated with BullMQ, real-time updates streamed over Server-Sent Events, Prisma ORM with PostgreSQL. Each agent calls Llama 3.1 8B via DigitalOcean Gradient serverless inference. RAG context is powered by DigitalOcean Gradient Knowledge Base — past project summaries are stored and retrieved to give agents relevant prior experience before they respond.
Frontend (React + TypeScript): Built with Vite, @xyflow/react for the node canvas, Zustand for pipeline state, and Framer Motion for animations. The dark industrial canvas with live node animations and HITL review drawers is fully reactive via SSE.
Infrastructure: DigitalOcean App Platform hosts both the API and static frontend. Managed PostgreSQL for persistent storage, Managed Valkey for BullMQ queues and pub/sub.
Challenges We Ran Into
Getting Llama 3.1 to reliably output valid structured JSON was the biggest challenge. We ended up combining strict JSON fence stripping, retry logic with up to 3 attempts per agent, and explicit JSON-only instructions in every system prompt.
Orchestrating the Shipyard required careful idempotency — cloning a boilerplate, injecting a Prisma schema delta, pushing to GitHub, and polling DigitalOcean App Platform for build status all needed to be safely retryable on partial failures.
SSE connection management across BullMQ workers, Redis pub/sub, and multiple concurrent pipelines also required significant care to avoid memory leaks and stale connections.
Accomplishments That We're Proud Of
The Human-in-the-Loop flow feels genuinely useful — not just a demo gimmick. The version counter, rejection feedback loop, and agent regeneration cycle make it feel like a real collaborative workflow between the developer and the AI agents.
The Shipyard producing a live, deployed URL from a raw concept in under 3 minutes is the moment that makes it click.
Using DigitalOcean Gradient Knowledge Base for RAG — instead of managing embeddings and pgvector manually — dramatically simplified the backend while making agent output noticeably more grounded and realistic.
What We Learned
Prompt engineering for structured JSON output at scale is harder than it looks. RAG context dramatically improves agent quality — agents that know about past similar projects produce much more realistic recommendations. And DigitalOcean's managed infrastructure stack made the deployment story surprisingly simple to wire together end-to-end.
What's Next for ForgeOS
- Dynamic agent spawning — the Strategist decides which specialist agents are needed based on the concept type
- AI Founding Team framing — expanding beyond 3 agents to include CMO, CFO, and domain specialists
- Iterate Mode — instead of a new deployment, the Shipyard opens a branch and PR on the existing repo for continuous improvement
- Agent confidence scores — visual indicators showing how certain each agent is about its output, surfaced directly on the canvas nodes






Log in or sign up for Devpost to join the conversation.