-
-
Title Page
-
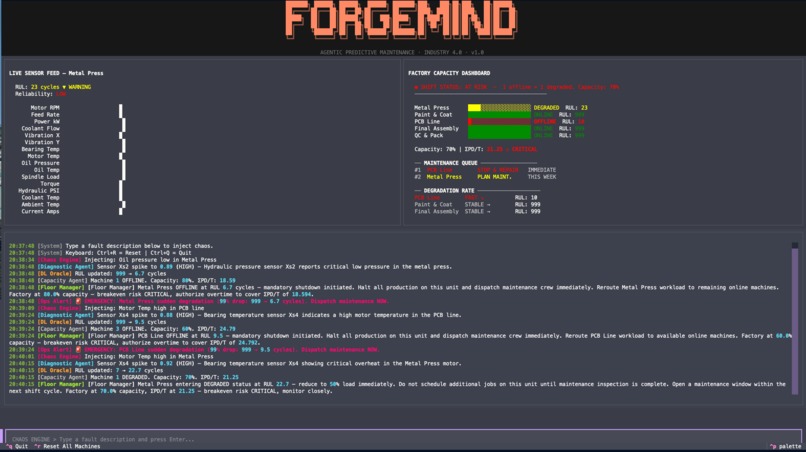
Deteriorating Machines
-
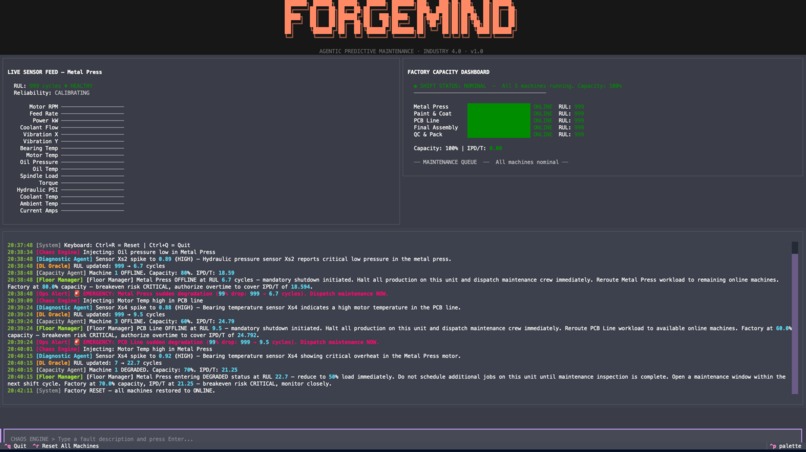
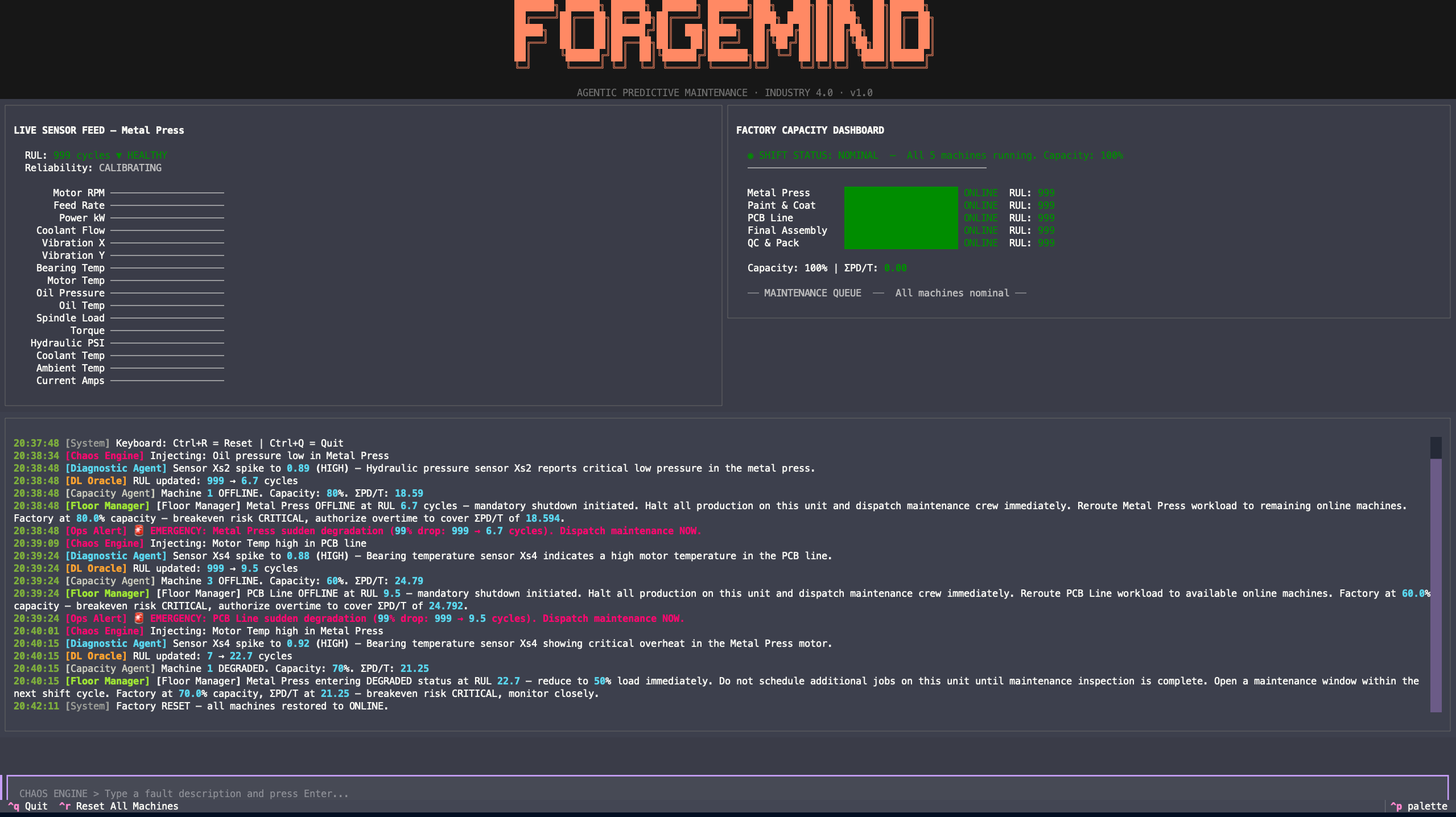
Reset
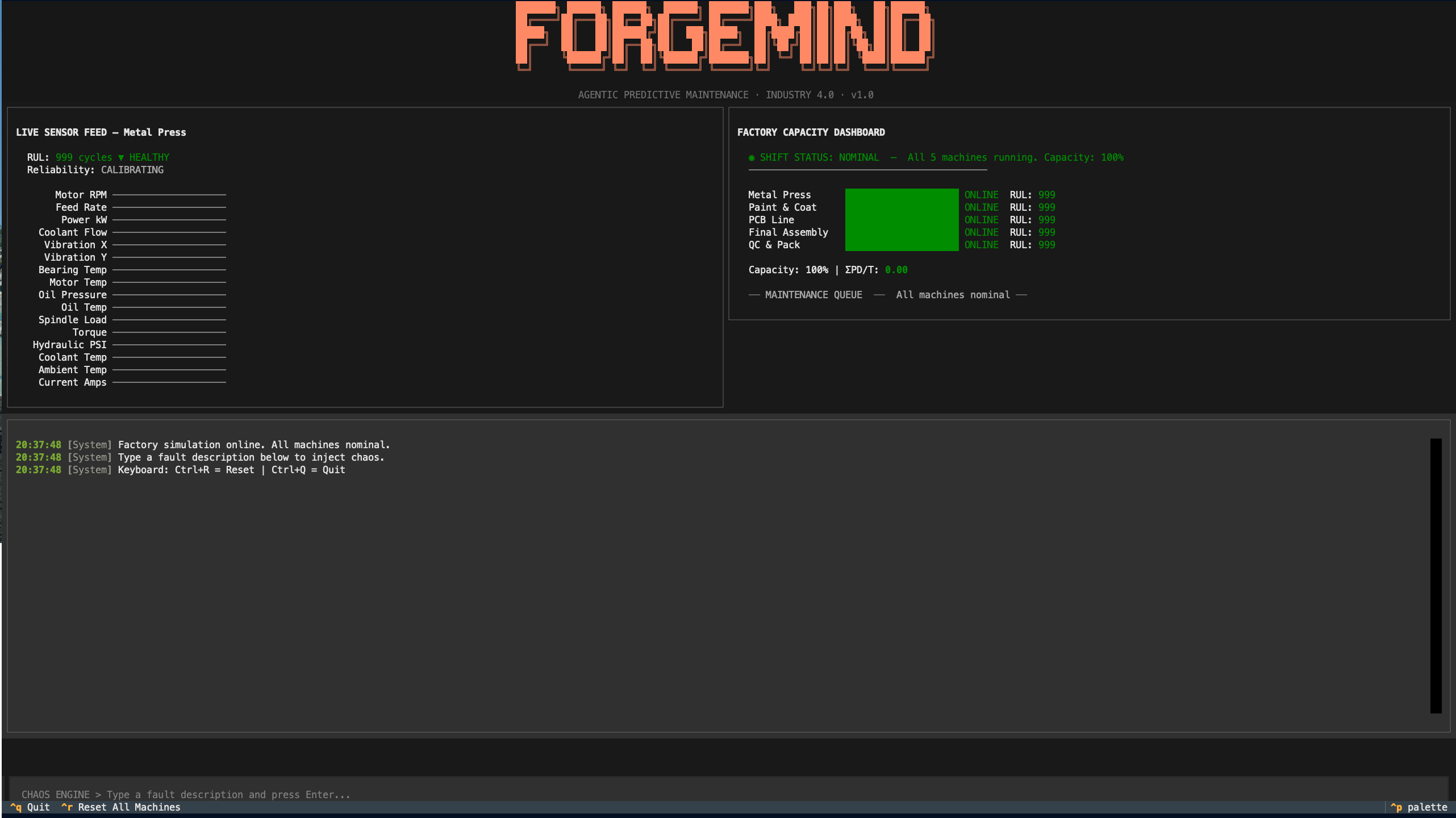
Inspiration
Machines often fail, despite all the data lying around; machines tend to fail, and the entire optimal pipeline stops! Nobody connects sensor readings to decisions fast enough. A vibration spike at 2 AM becomes a three-day production halt by Monday morning. While I was sitting in my Operations class reading a similar case study, I thought of leveraging AI!
We don't just want to create a RUL calculator, cause thats very common! We saw a lot of projects and demos, in every predictive-maintenance demo: a beautiful deep-learning model that outputs a single number and then... nothing. No translation. No action. No context.
We wanted to build the thing that comes after the ML model. The part where a messy human fault description ("bearing overheating on Machine 3") gets turned into a grounded, machine-readable diagnosis, run through a real trained CNN-LSTM, converted into capacity impact, and surfaced on a live factory floor dashboard; all in under a few seconds. That's ForgeMind.
What it does
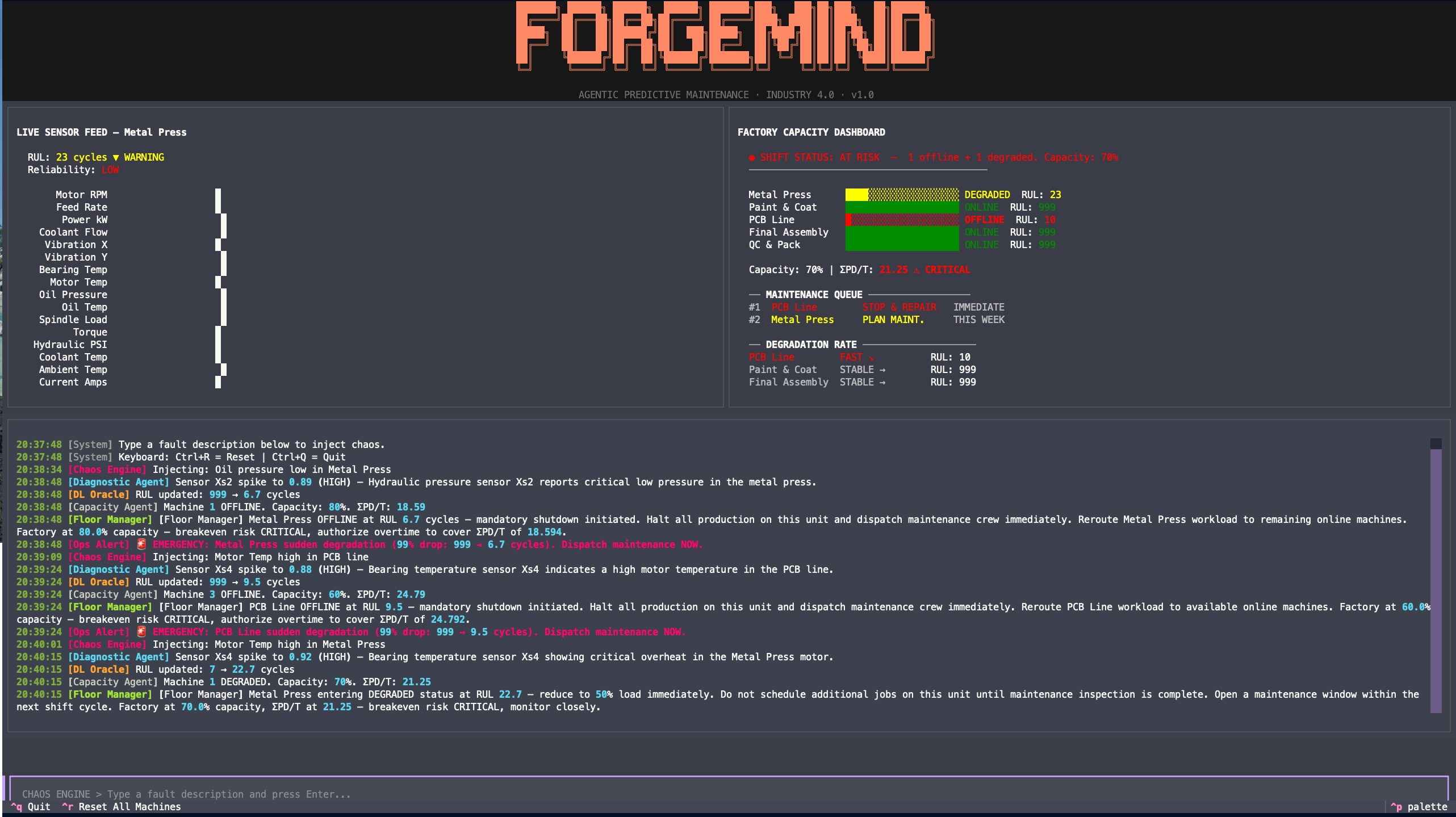
ForgeMind is an end-to-end predictive maintenance decision system. You type a fault description in natural language; it gives you back a full operational response.
The pipeline:
- Input Guard filters noise and validates input.
- Diagnostic Agent (Gemini) translates the fault text into a structured sensor-anomaly tensor: raw text →
(50, 18)array of realistic sensor values. - DL Engine runs that tensor through a trained CNN-LSTM to predict Remaining Useful Life.
- Capacity Agent (Gemini) reasons over the predicted RUL and current factory state to compute system-level capacity impact.
- Ops Analytics detects RUL cliffs, sensor saturation, and degradation trends; schedules predictive maintenance.
- Floor Manager (Gemini) generates a human-readable decision for the operator.
- Terminal Dashboard (Textual UI) displays everything live across 4 panes: sensor feed, capacity dashboard, agent comms log, and a chaos engine for injecting faults.
The core design principle: LLMs handle interpretation and communication; the CNN-LSTM handles prediction; rules handle safety-critical logic. No component does something it shouldn't.
How we built it
- Deep Learning: CNN + LSTM hybrid trained on NASA's N-CMAPSS turbofan degradation dataset. CNN layers capture local degradation patterns across 18 sensor channels; LSTM layers model long-term temporal dependencies over a 50-timestep sliding window. Trained with NASA's asymmetric scoring function so the model is penalized more for late failure predictions than early ones; which matches real-world maintenance cost.
- Agent Layer: Three Gemini-powered agents using structured output schemas via Pydantic. Each agent has its own API key, its own prompt contract, and its own fallback path if the API fails.
- Factory State: A single source of truth object that every component reads from and writes to; no duplicated state across UI, agents, and ML.
- Terminal UI: Textual + Rich for a real-time four-pane dashboard with live sparklines, color-coded machine health, and non-blocking async workers so heavy ML runs don't freeze the UI.
- Offline resilience: A fallback cache for Gemini responses means the demo keeps running even if the API rate-limits or the WiFi dies at the venue.
Challenges we ran into
- Agent contracts are brittle. Getting Gemini to consistently return a valid
(50, 18)sensor-spike specification took several iterations of prompt engineering, Pydantic validation, and a retry-with-fallback layer. One malformed JSON from an LLM can crash a whole system if you don't plan for it. - Keeping the terminal UI responsive. Running PyTorch inference + three Gemini calls on the main thread froze Textual. Had to move every heavy operation into
@work(thread=True)workers and usecall_from_threadfor state updates.
What we learned
- Grounding matters more than fluency. An LLM that hallucinates a sensor value wrecks the whole pipeline. Structured output + Pydantic validation + a real ML model for the numeric prediction made the system trustworthy in a way that pure-LLM "agent" demos never feel.
- The scaler is part of the model. We almost shipped a version where the weights lived in one folder and the scaler lived somewhere else. If they drift apart, inference silently lies. Treating
best_model.ptandscaler.pklas a single atomic artifact saved us. - Fallbacks aren't optional for live demos. Every external call (Gemini, API keys, etc.) needs a degraded-but-alive path. Our demo runs with or without working API keys.
- Terminal UIs are underrated. Textual gave us a genuinely impressive-looking dashboard in a fraction of the time a web app would have taken.
What's next for ForgeMind
- Multi-model ensemble - swap in a Transformer-based RUL predictor and let a meta-agent reconcile disagreements.
- Closed-loop scheduling - wire the Ops Analytics maintenance queue into an actual CMMS (computerized maintenance management system) so recommendations become work orders automatically.
- Explainability layer - show operators why a RUL dropped, not just that it did. SHAP values per sensor channel, surfaced in a fifth terminal pane.

Log in or sign up for Devpost to join the conversation.