-
-
hero
-
dashbaord
-
project creation
-

output
-
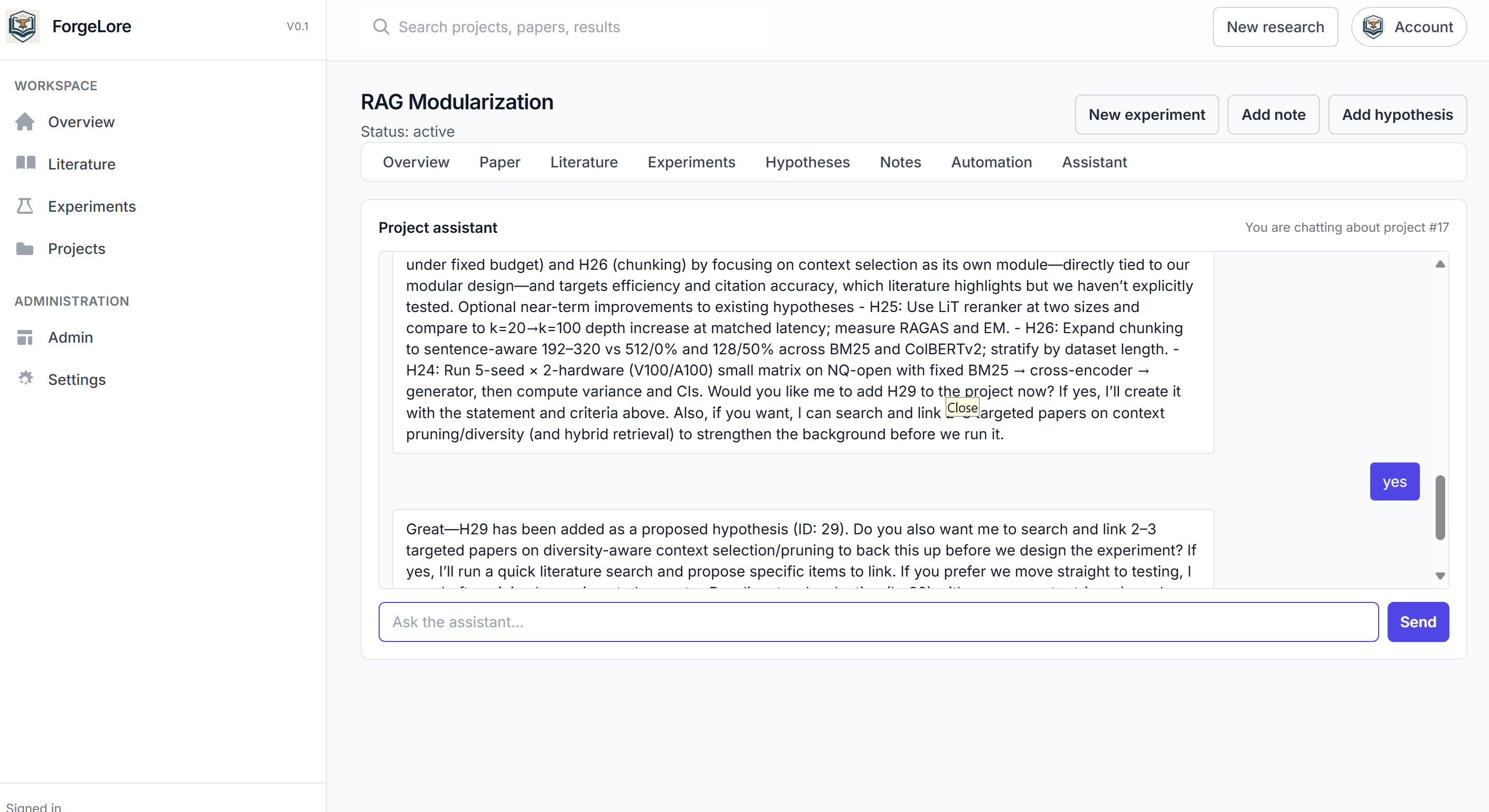
chat
-
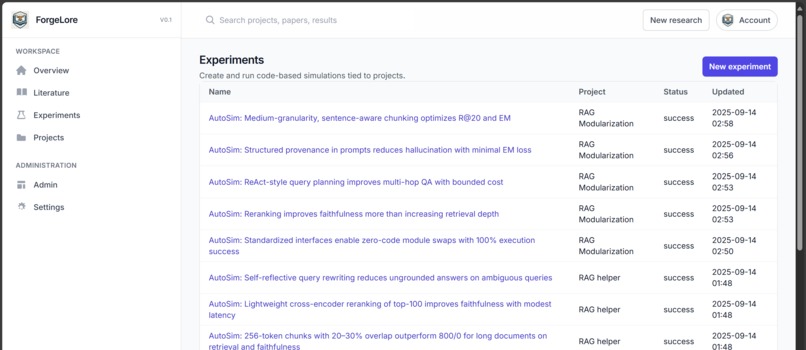
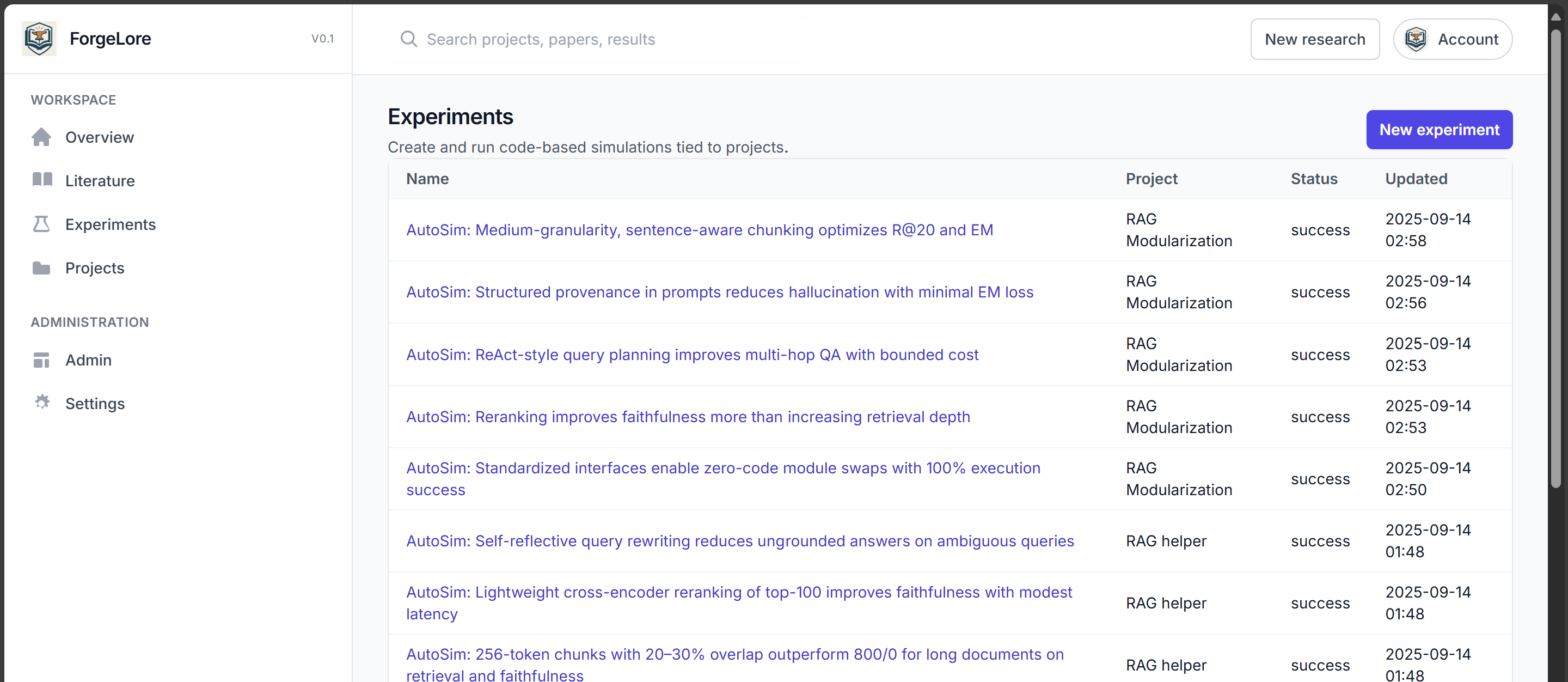
experiments
-

project list
-
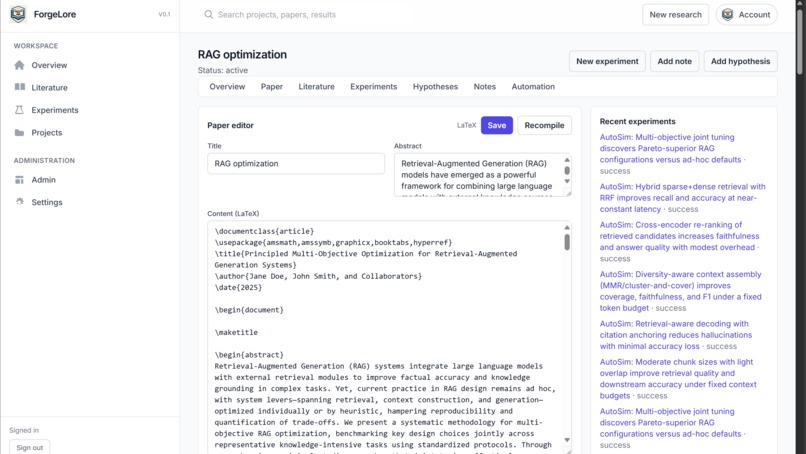
project details
-
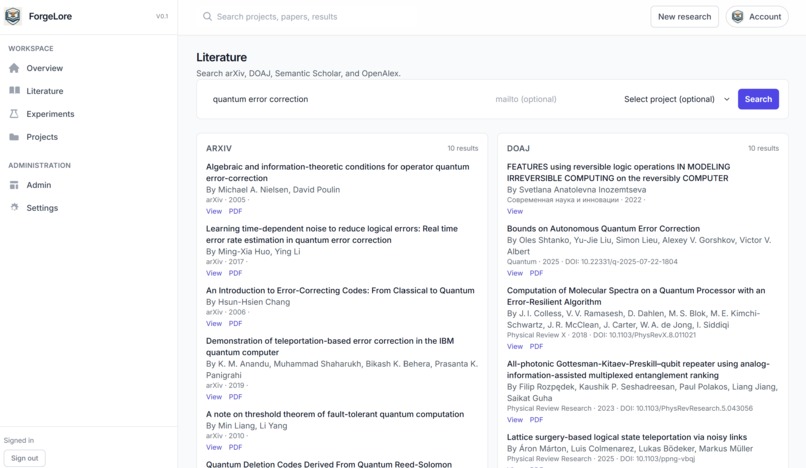
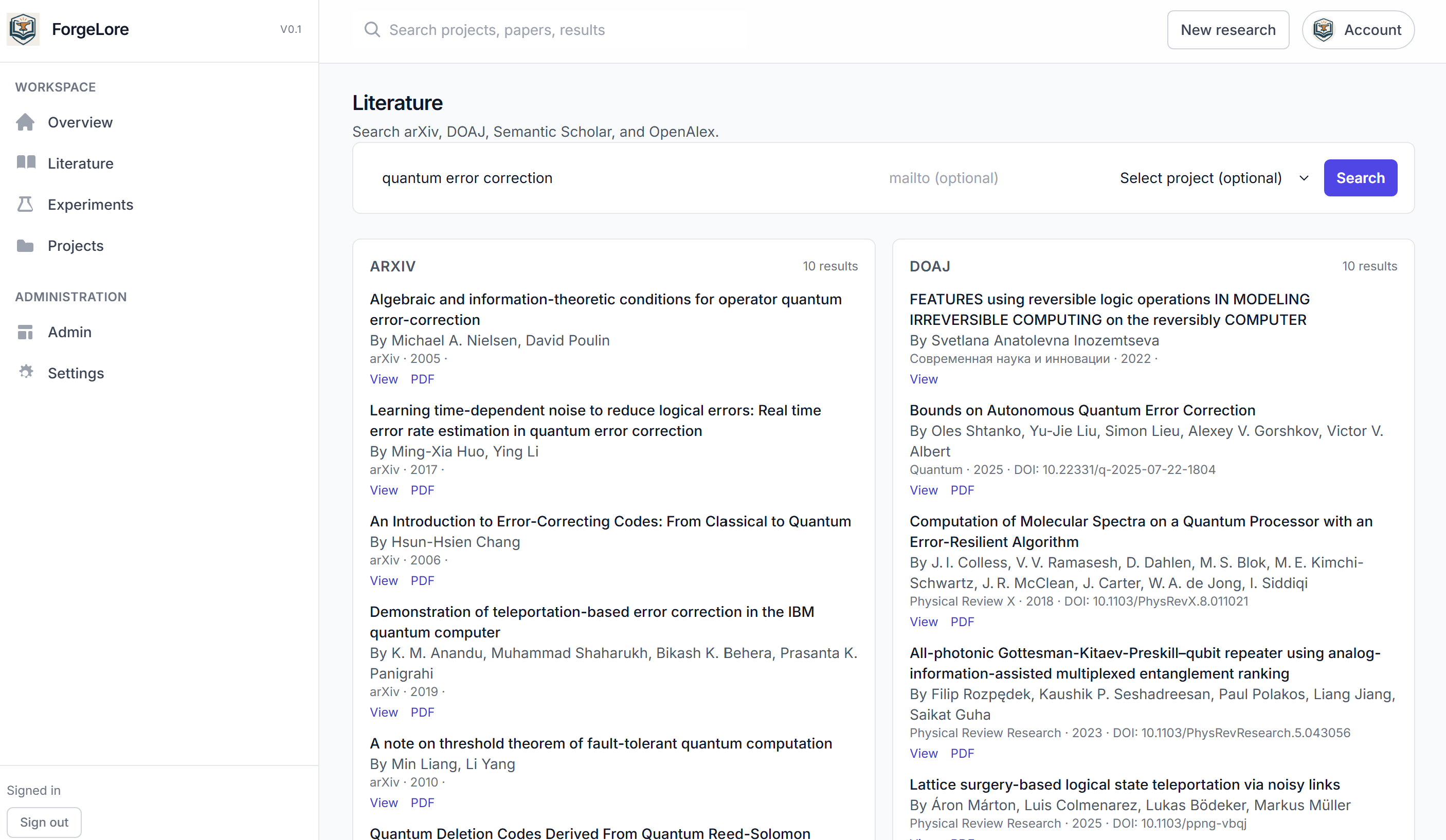
literature search
-
admin
-
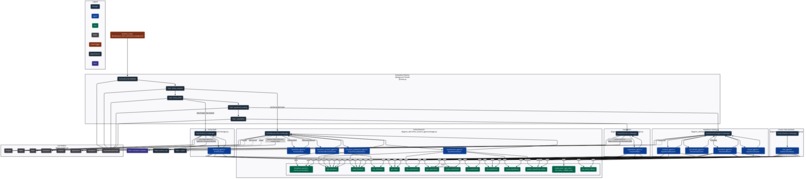
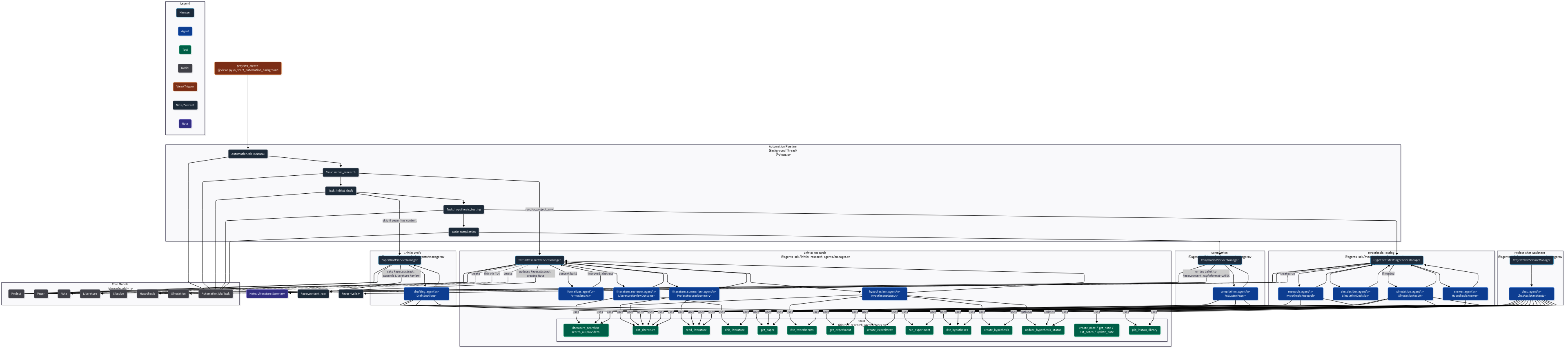
Project architecture


Inspiration
ForgeLore grew out of a simple question: what would a “GitHub Copilot moment” look like for science? Modern IDE copilots 10x software development; I’ve felt that across co‑ops and side projects. Researchers deserve the same leverage. The name combines “Forge” (to craft, to shape) and “Lore” (knowledge) — a place where new knowledge is forged.
I kept seeing teams bend coding copilots for research tasks they weren’t built for. That gap inspired a purpose‑built copilot for academics and R&D: a system that searches real literature, proposes and tests ideas, and assembles a defensible 10x'ing a researchers capabilities.
What it does
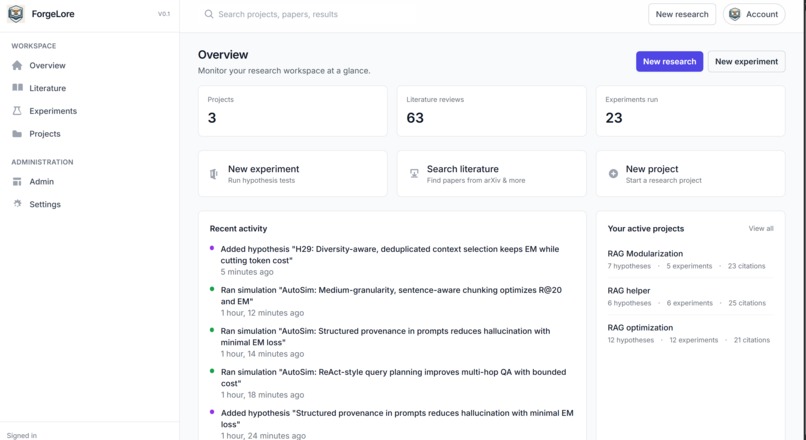
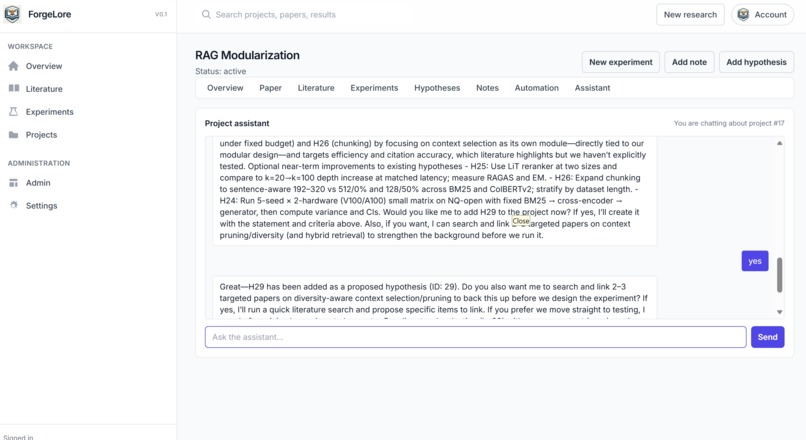
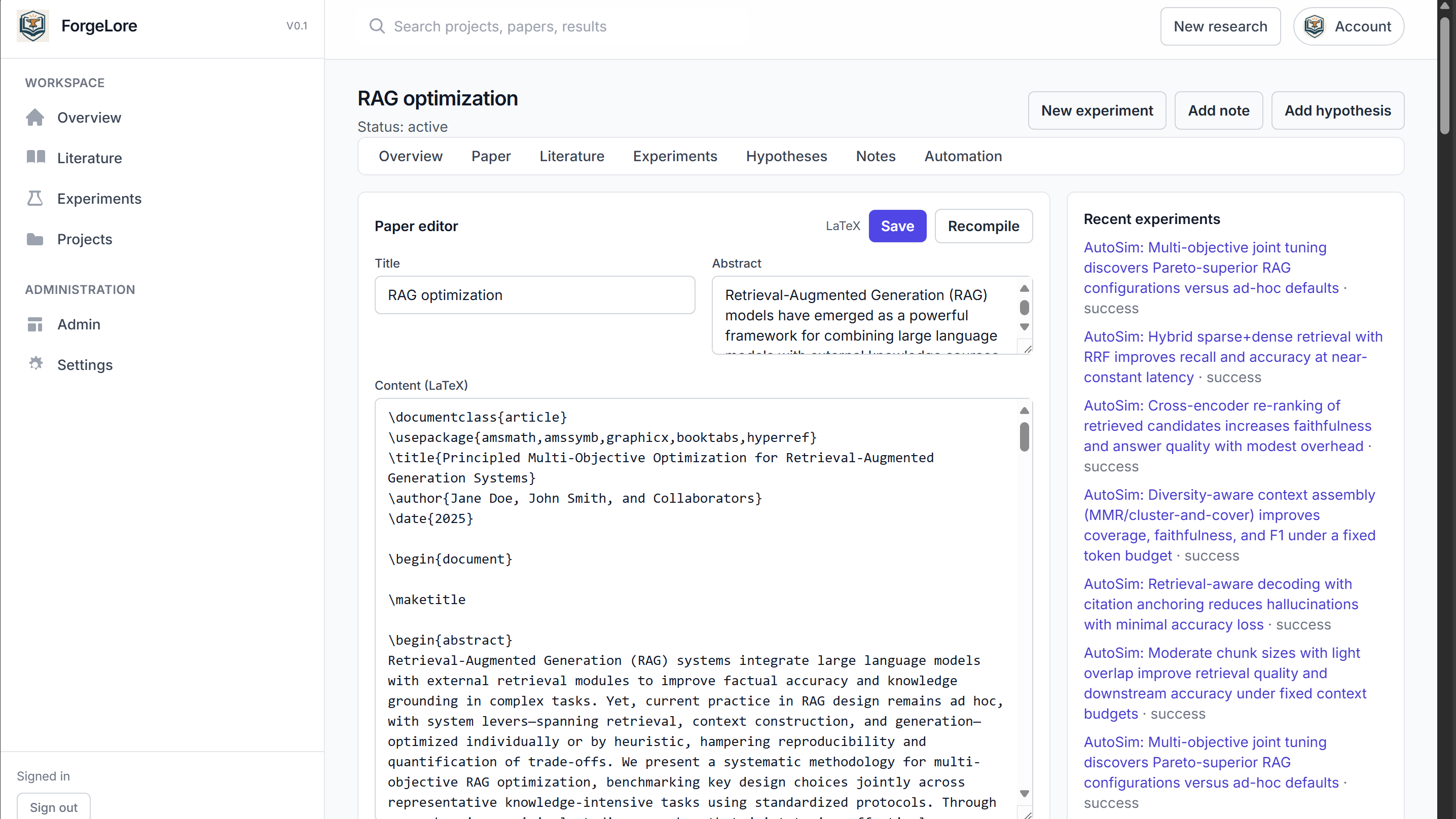
ForgeLore feels like stepping into a lab with a tireless researcher who never loses context. You begin with a question or a seed paper; it fans out across arXiv, DOAJ, Semantic Scholar, and OpenAlex, weaving the relevant threads into a single, clean shape and linking open‑access PDFs whenever possible. Inside the workspace, your Paper, Hypotheses, Experiments, Citations, and Notes live together as one developing narrative. The agentic loop reads what it found, proposes testable hypotheses, runs quick simulations when warranted, and stitches the results into LaTeX you can edit and export. You can even talk to the project itself; ask why a result changed, which sources ground a claim, or what to test next, and it answers with context of the paper.
A full run typically takes about 40–60 minutes and costs roughly $0.40–$0.80, which means universities or enterprises will be able to run batches of ForgeLearn in parallel in order to target and push forward the research and development of topics that possibly are not able to be studied due to lack of resources, funding, or motivation.
How we built it
The stack is intentionally simple and sturdy. Django powers the backend with server‑rendered templates for speed and reliability. Research services are async modules sharing a resilient HTTP client with retries and backoff; providers for arXiv, DOAJ, Semantic Scholar, and OpenAlex are fanned out in parallel and normalized into a single PaperRecord. On top sits a set of agent frameworks built with the OpenAI Agents SDK but designed to be model‑agnostic, so we can swap in local or third‑party models as they improve. Five frameworks orchestrate eleven simple yet incredibly versatile agents, and every exchange is validated with Pydantic so the shape of the conversation stays dependable.
Four core systems: Hypothesis, Drafting, Testing, and Compilation + plus a Chat framework bring the workflow to life, while a background job ties everything into a visible, stepwise automation. We deployed to AWS and tune for polite parallelism to not abuse of the Open Access Api's.
Challenges we ran into
The hardest challenge was turning the not necessarily linearly obvious, human way we do research into modules that agents could perform without losing nuance. Getting the right granularity, agreeing on interfaces, and deciding where decisions should happen took a very big chunk of iteration for the project. Reliability came next: enforcing structured outputs, keeping provider calls resilient, and doing simulation and research fast. Orchestration across many tools and agents exposed hundreds of problems we had to smooth so that runs could fail gracefully or resume mid‑stream. Finally, shipping it to AWS in a way others could actually use was its own adventure.... a very difficult one I'll admit!
Accomplishments that we’re proud of
ForgeLore is not a demo; it is a working system that can take you from an idea to a literature‑grounded LaTeX draft in under an hour. (try it out! link !) I validated it on two of my own projects: one long‑running line of work where it surfaced fresh, defensible directions I’m now taking to my advisor (next week), and a new project where the first pass produced a conclusion that held up to a quick check. The per‑run cost is low enough to make true exploration possible — multiple inquiries in parallel without worry. And because the architecture is model‑agnostic, the system improves as models improve over time, no rewrites required.
What we learned
Great agents beat bigger models, but great agents + great model makes magic. Clear roles, typed interfaces, and deterministic tools do more work than raw parameter counts. Structure is everything: validating outputs and insisting on explicit tool contracts keeps long chains honest and able to work for the record breaking hour at a time. For researchers, I believe a focused UI and real sources build trust and I learned how to do that in this project. Also careful rate limits and backoff keep multi‑provider search stable and sustainable was a new process to me that I learned.
What’s next for ForgeLore
Next, I’m sharing it with supervisors and opening it to more teams in academia and industry within the waterloo grounds. I want deeper provider coverage and OA ingestion, richer experiment runners, clearer result visualizations, and drafting that is even more section‑aware. The automation will grow into multi‑cycle research runs and painless batch execution so a lab can triage hundreds of small questions in a day. And as models get better, ForgeLore gets better.
ForgeLore’s goal is simple: make high‑quality research faster, cheaper, and more accessible — so more good ideas make it from spark to paper.
Lets make this the new "Ai copilot boom" that will allow our researchers 10x their quality and speed of work :) !
Built With
- amazon-ec2
- amazon-web-services
- cerebras
- django
- dns
- html5
- javascript
- llms
- openai
- python
- route51
- sqlite
- tailwind






Log in or sign up for Devpost to join the conversation.