-
-
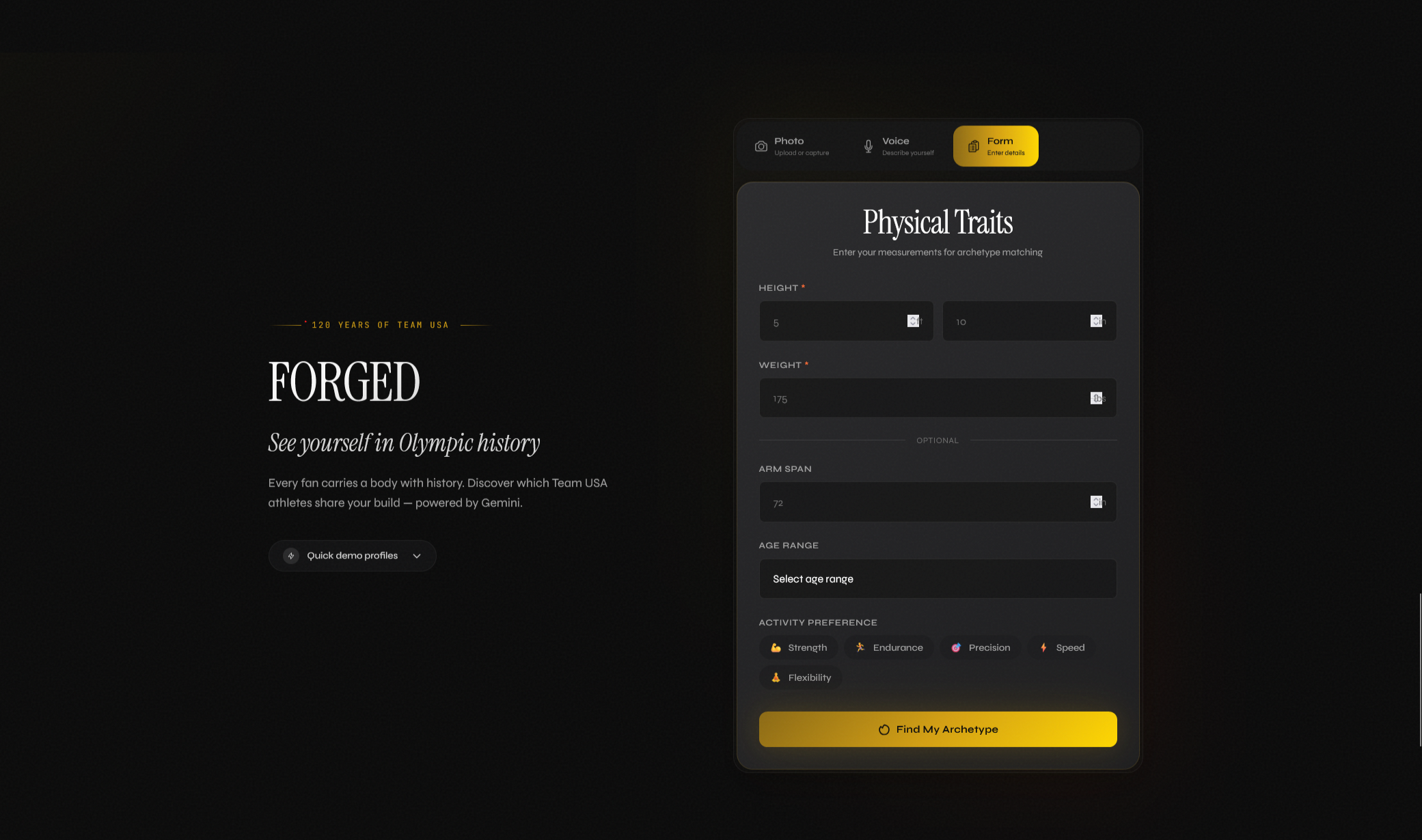
Landing Page submission form
-
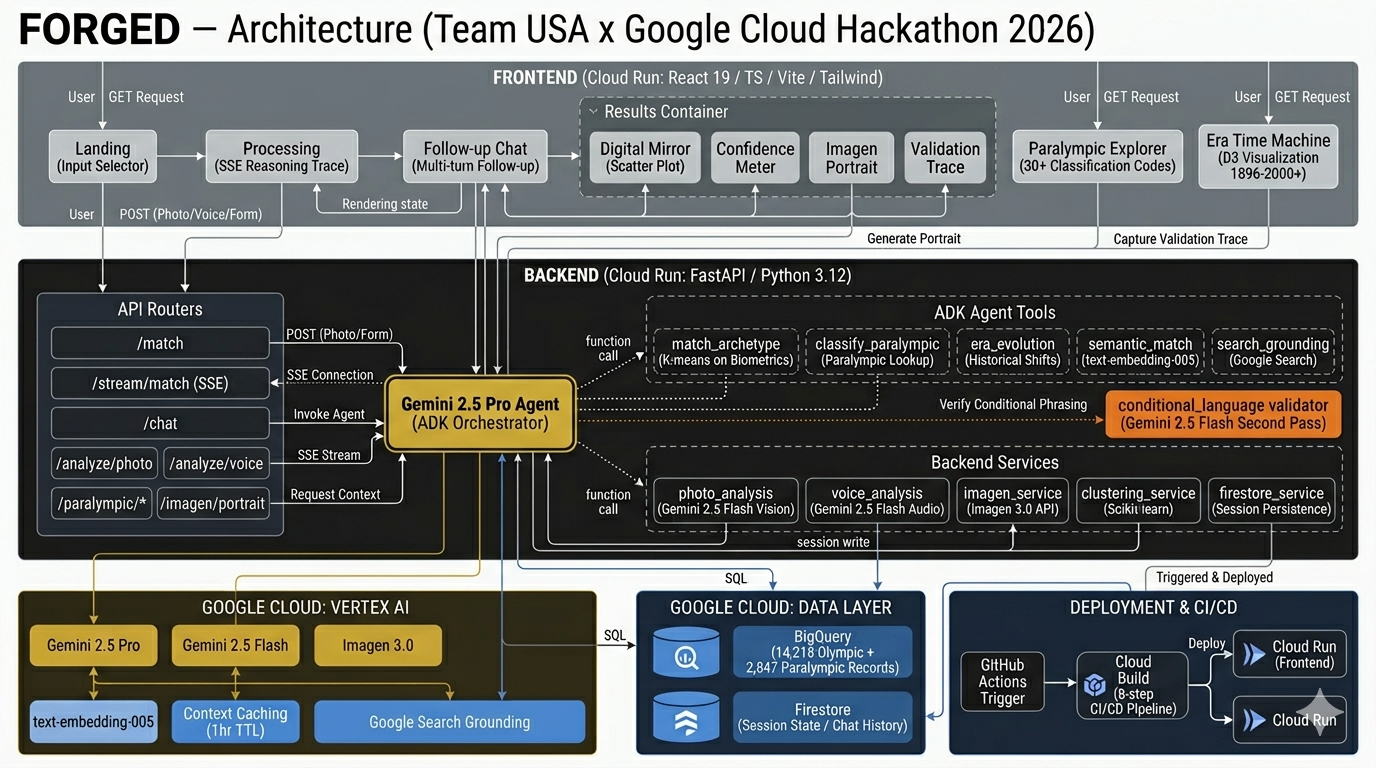
FORGED Architecture Diagram
-
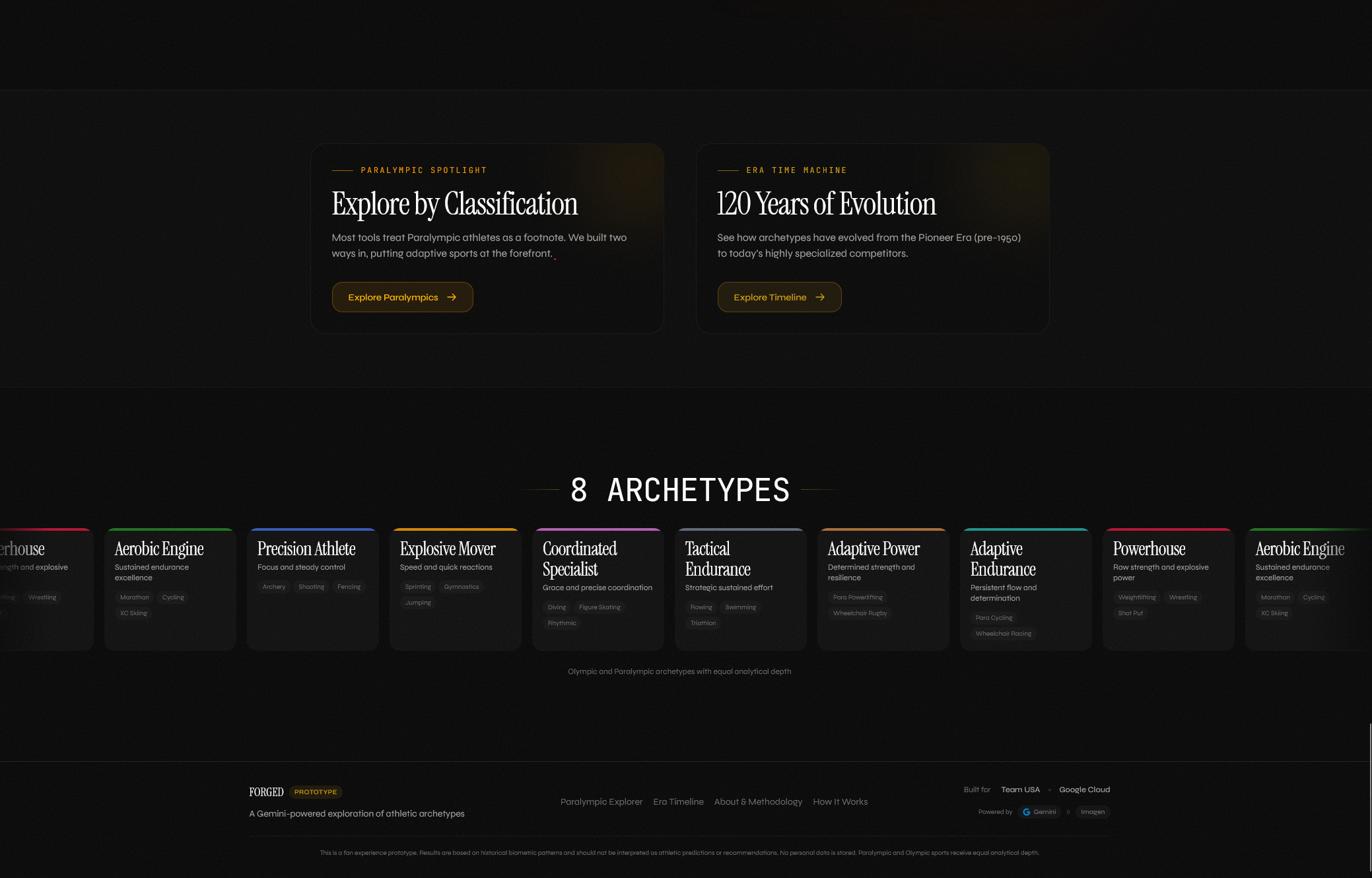
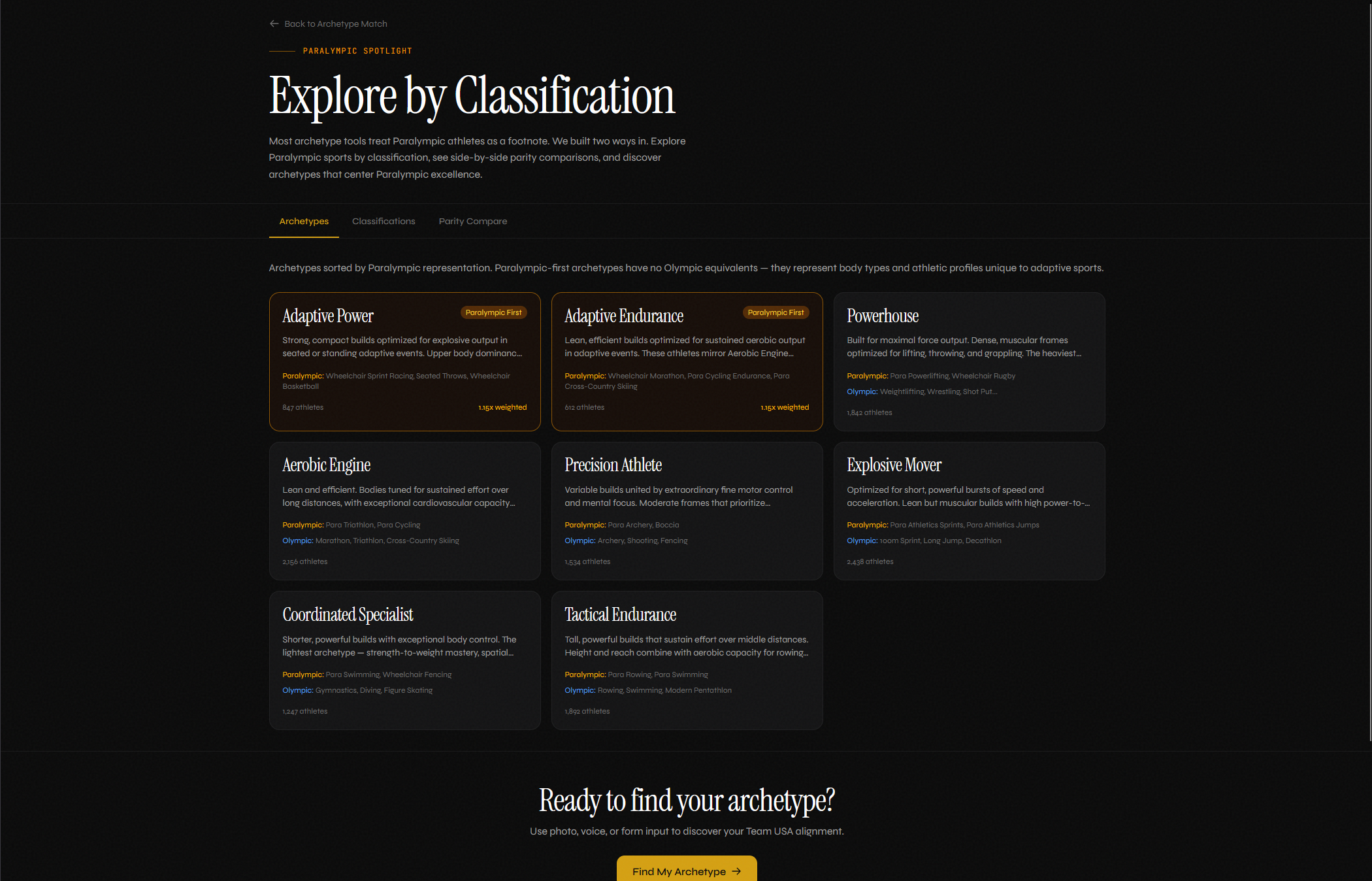
Landing page with all archetypes
-
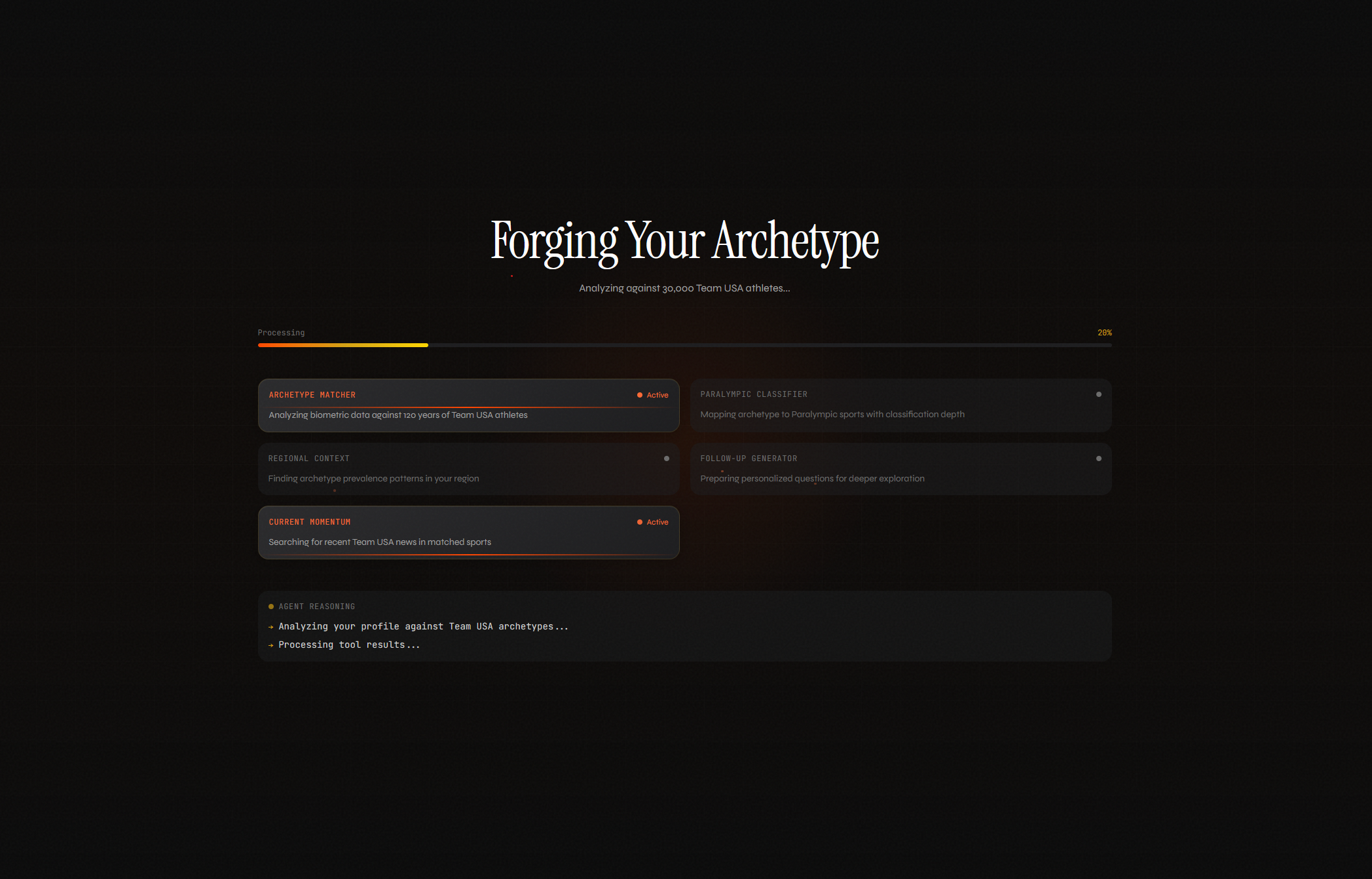
Loading Screen with live AI agent progress
-
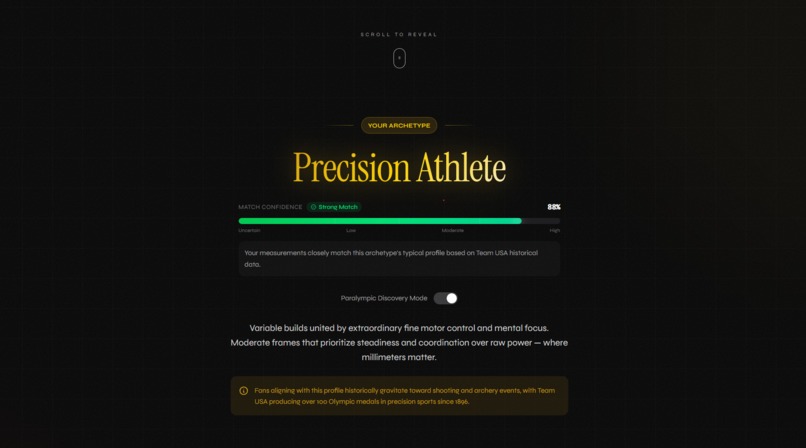
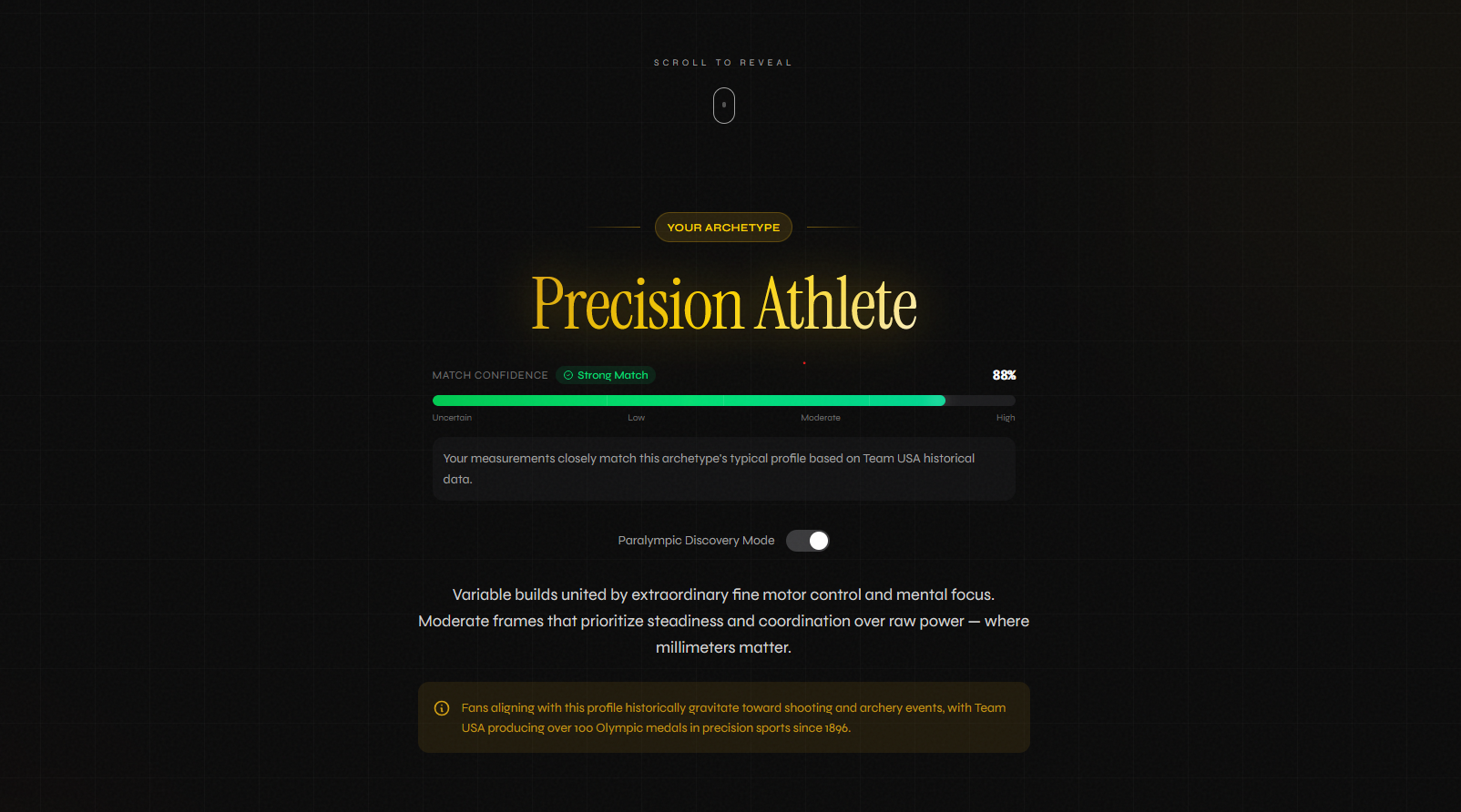
Example Archetype
-

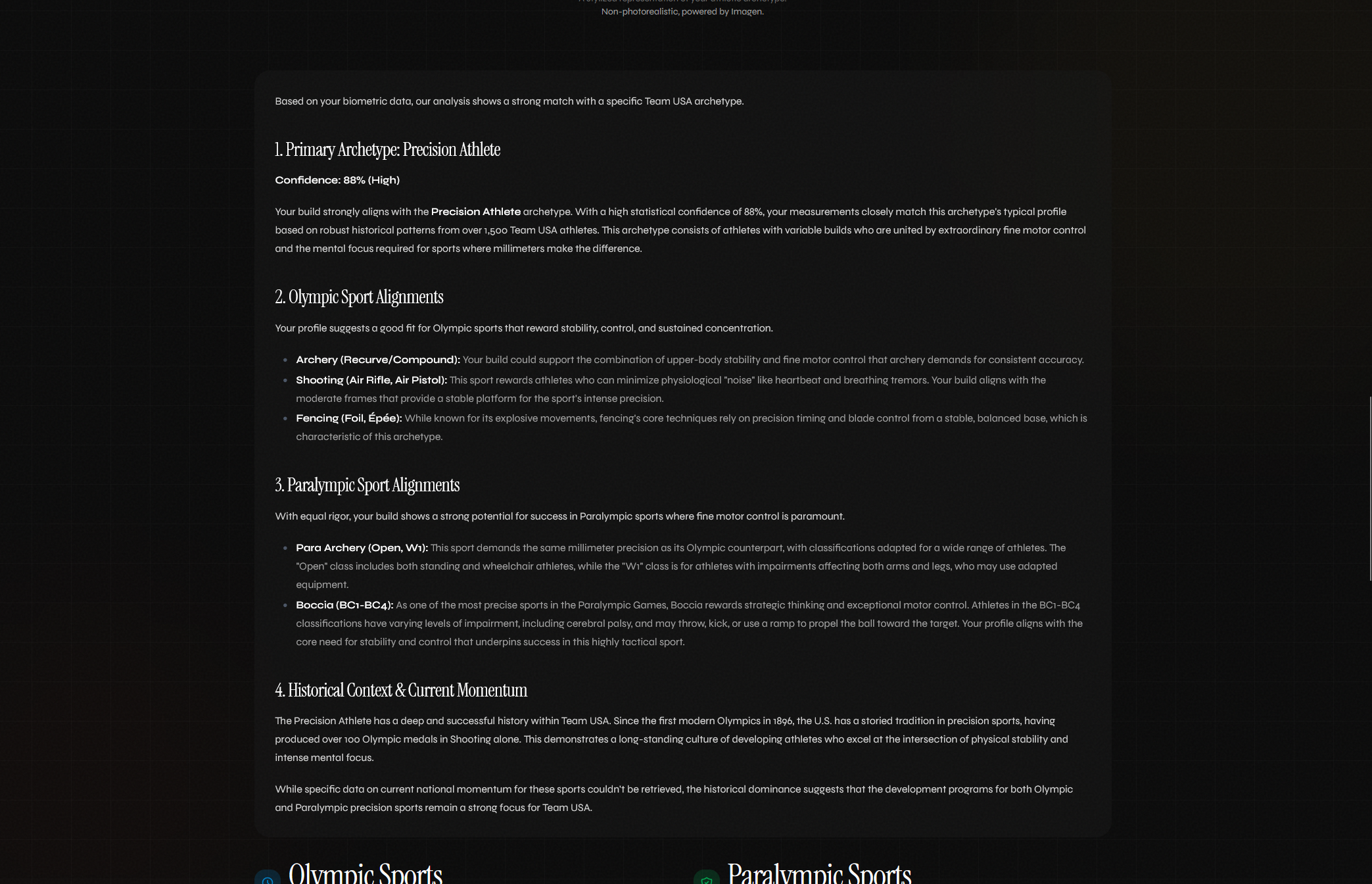
Example Archetype Description
-
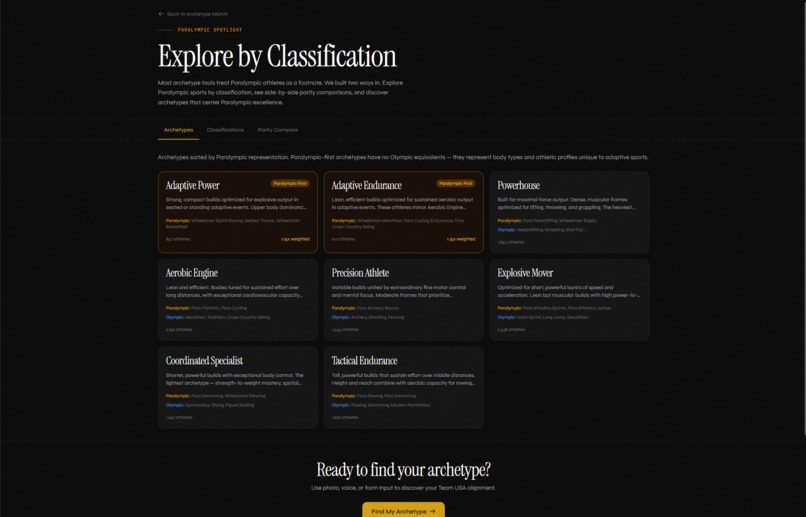
All Classifiers with Paralympic Parity
Inspiration
The brief described Challenge 4 as a "Digital Mirror that helps fans see themselves in the collective journey of Team USA." That framing pulled me in. It also asked for equal analytical depth between Paralympic and Olympic content, and I wanted to design for that from the first commit instead of bolting it on at the end.
What it does
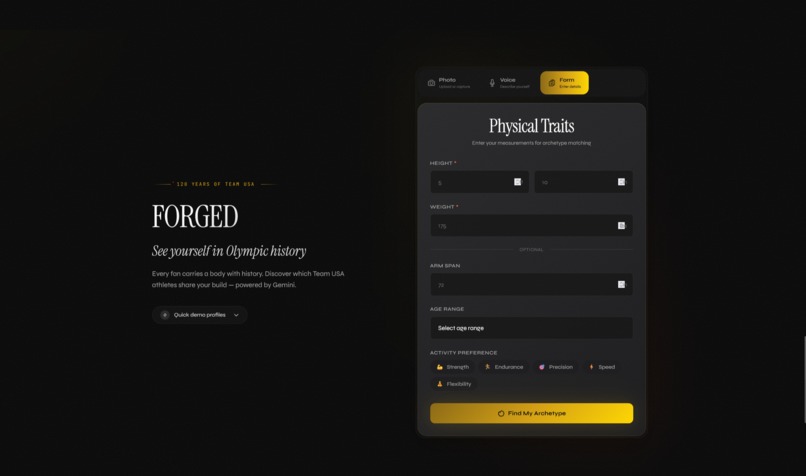
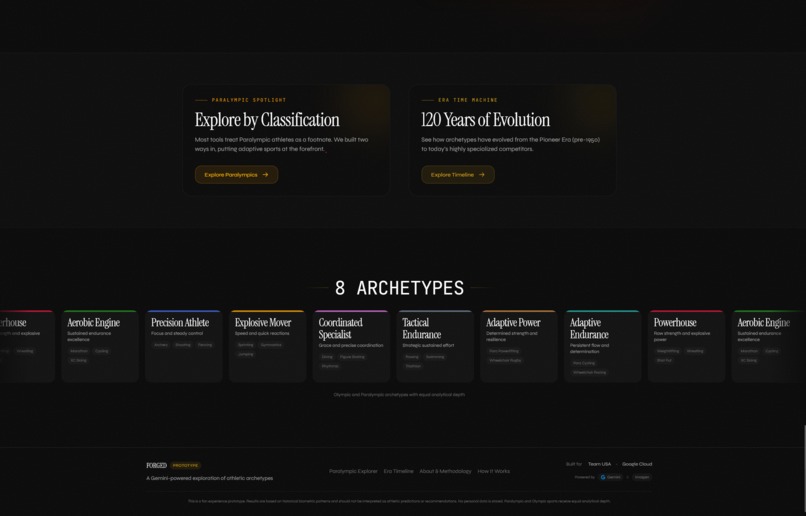
FORGED matches users to one of 8 Team USA athlete archetypes built from 120 years of historical biometric data. You give it a photo, a 30-second voice description, or a few stats. It returns a primary archetype with a confidence score, two secondary matches, an Imagen-generated stylized portrait, conditional sport recommendations using "could align with" phrasing, and a live trace of Gemini's reasoning as it works.
Two of the 8 archetypes are Paralympic-first: Adaptive Power and Adaptive Endurance. Their centroids come from Paralympic sport requirements directly, not from Olympic profiles with modifications. A Paralympic Spotlight surfaces 30+ classification codes with eligibility explanations. Discovery Mode lets users browse Paralympic sports ahead of Olympic ones. An Era Time Machine visualizes how each archetype's body type shifted across four historical eras from 1896 to today.
How I built it
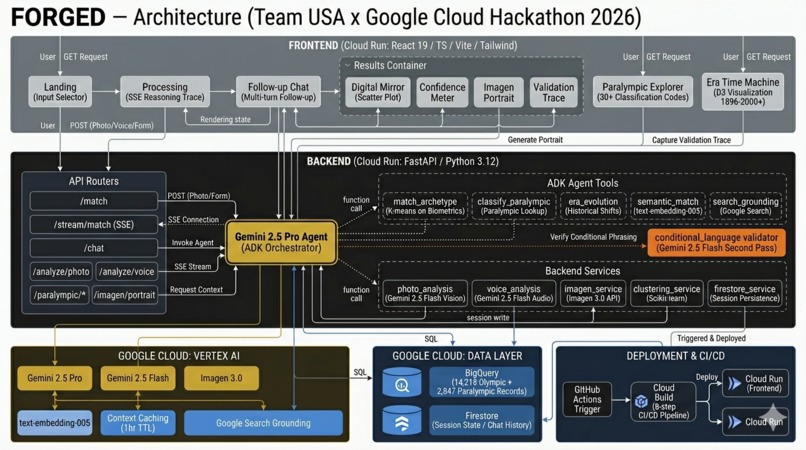
The backend is FastAPI on Python 3.12. The frontend is React 19 + TypeScript + Vite. Both deploy to Cloud Run through a Cloud Build pipeline. The agent runs on Gemini 2.5 Pro with five tools: match_archetype, classify_paralympic, era_evolution, semantic_match, and search_grounding. BigQuery holds the athlete data (14,218 Olympic and 2,847 Paralympic records). Firestore stores session state for follow-up conversations.
Multimodal input uses Gemini 2.0 Flash for photo analysis and voice transcription. Imagen 3.0 generates the archetype portraits with non-photorealistic prompts that avoid IOC IP. A separate Flash pass validates every output for conditional phrasing, and the validation trace is exposed to users in an expandable panel showing flagged terms, modifications, and latency.
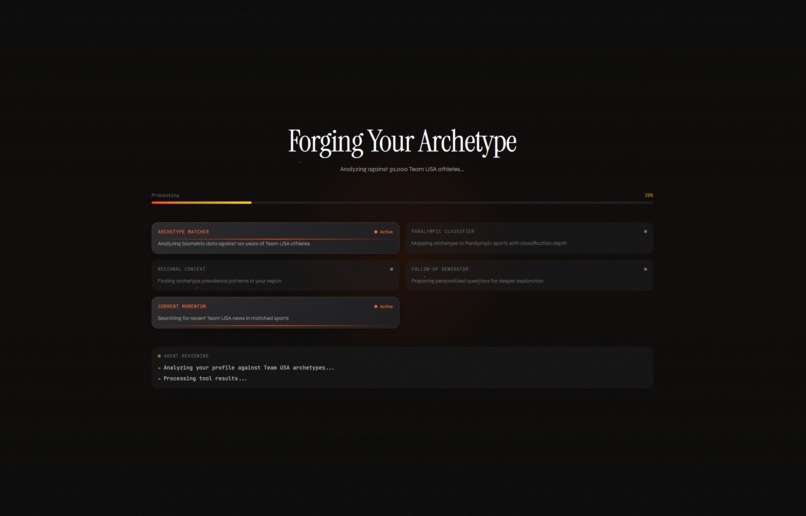
The matching pipeline runs two signals in parallel. K-means clustering on biometric centroids gives a quantitative match. Semantic embeddings (text-embedding-005) on the user's self-description give a qualitative match. When the signals agree, confidence increases. When they diverge, the UI surfaces both and invites exploration. Server-Sent Events stream the full reasoning trace to the frontend, so users see actual tool execution rather than a loading spinner.
Context caching keeps the 120-year corpus warm in Vertex AI with a 1-hour TTL, which dropped repeated-session token costs by roughly 90%. CI runs ruff, mypy, pytest, and Vitest through GitHub Actions, with dedicated tests for banned phrases and NIL references that block any commit reintroducing them.
Challenges I ran into
Compliance. Early archetype descriptions cited Frank Shorter, Jesse Owens, and Simone Biles to make the writing feel concrete. That violated NIL rules. The first Imagen prompts referenced Olympic rings and torches, which is IOC IP. I had to strip both systematically, replace them with aggregate historical descriptions and abstract athletic imagery, and add CI tests to keep them out.
Paralympic parity. It sounds like a checkbox until you build it. Treating the two programs as peers meant designing Paralympic-first archetypes from the data rather than from Olympic templates. It meant sample-weighting the dataset so a century of Olympic data didn't statistically dominate. It meant writing 30+ classification explainers at the same depth as Olympic sport pages.
Production sharp edges. CORS broke between the two Cloud Run services on first deploy. The ConfidenceMeter component collapsed to 4 pixels inside a text-center parent and needed explicit display: block and width: 100%. Imagen calls failed silently in production until I added traceback logging and a Skip button. The conditional-language validator added ~800ms per request, which context caching mostly clawed back.
Accomplishments I'm proud of
The validation trace turns compliance into a visible feature. Users can expand a panel and watch Gemini audit its own output: original phrasing, flagged terms, applied modifications, latency, all timestamped.
The Paralympic-first archetypes are structural peers in the architecture. Two of eight, with their own centroids, sample weighting, and dedicated UI surfaces.
The dual-signal matcher catches cases that single-method clustering misses. When K-means and embedding similarity disagree, that disagreement becomes useful information for the user rather than a hidden weakness.
What I learned
Compliance is a design constraint that shapes the product. The validator stopped feeling like a chore the moment its output became a feature.
Streaming the reasoning trace builds more trust than a polished result with a hidden middle. Both users and judges want to see the agent think.
Paralympic parity is dramatically cheaper to design in from the start than to retrofit. The architecture has to support it at the data layer, not just the UI.
Vibe coding with Gemini works best when the agent has a small set of well-scoped tools to compose, rather than one giant prompt to interpret.
What's next for FORGED
- Touch handlers for the D3 visualizations on mobile
- An era-evolution forecast pointed at LA28 sports
- Exposing the validation trace as a standalone API so other Gemini apps can reuse the compliance pattern
- Expanded archetype set with regional clustering tied to hometown data
Built With
- apache-2.0
- bigquery
- cloud-build
- cloud-run
- d3.js
- docker
- fastapi
- firestore
- framer-motion
- gemini
- gemini-2.5-flash
- gemini-2.5-pro
- github-actions
- google-adk
- google-cloud
- imagen
- python
- react
- server-sent-events
- tailwindcss
- text-embedding-005
- typescript
- vertex-ai
- vite

Log in or sign up for Devpost to join the conversation.