-
-
Chat interface — describe any browser task in natural language
-
Teach a skill — the agent learns the general pattern, not just one task
-
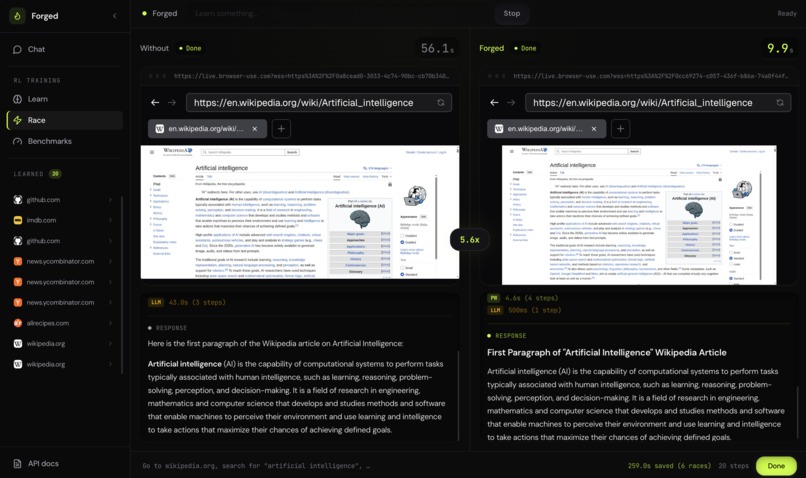
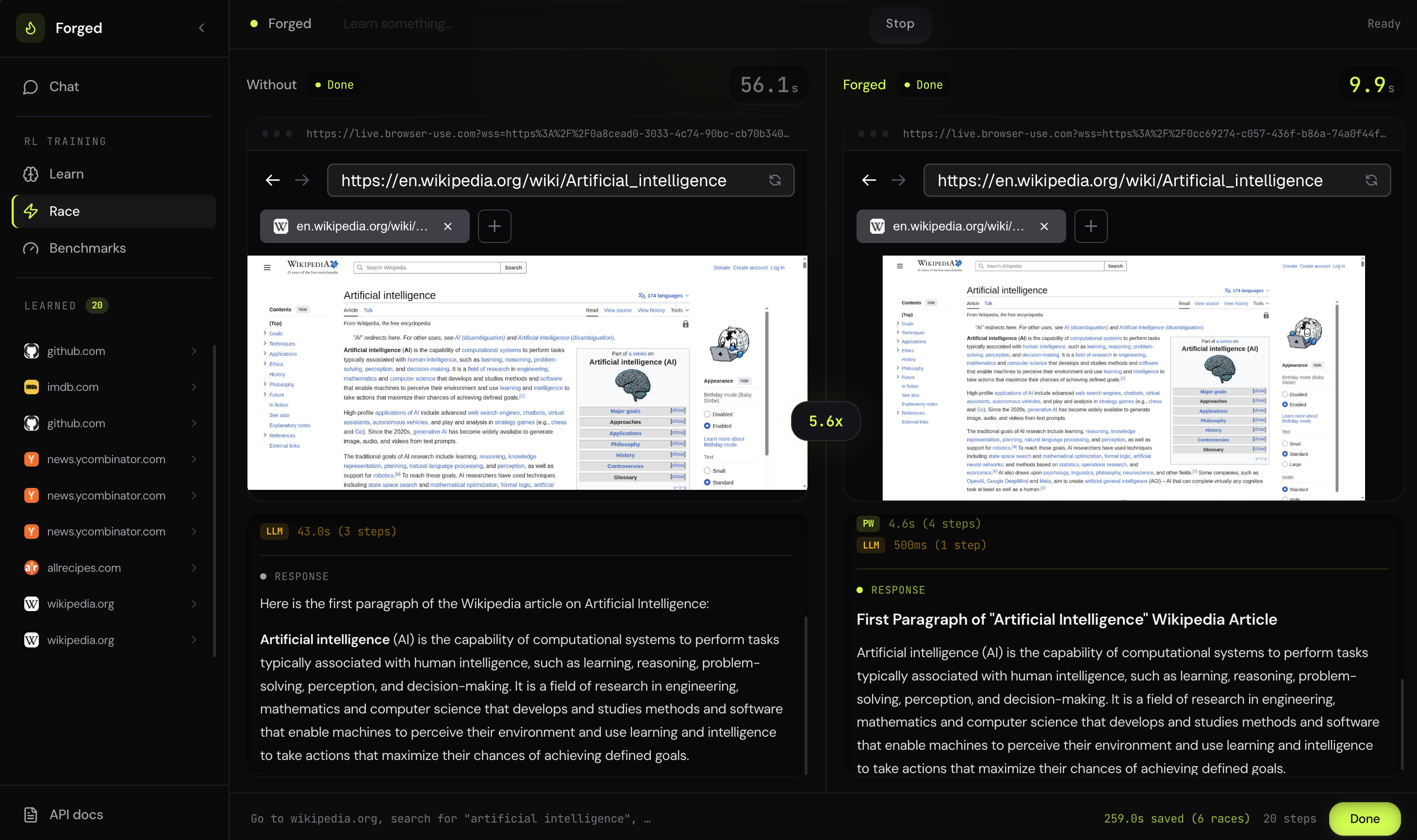
Race view — side by side: vanilla agent (82s) vs. Forged (11s), same result
-

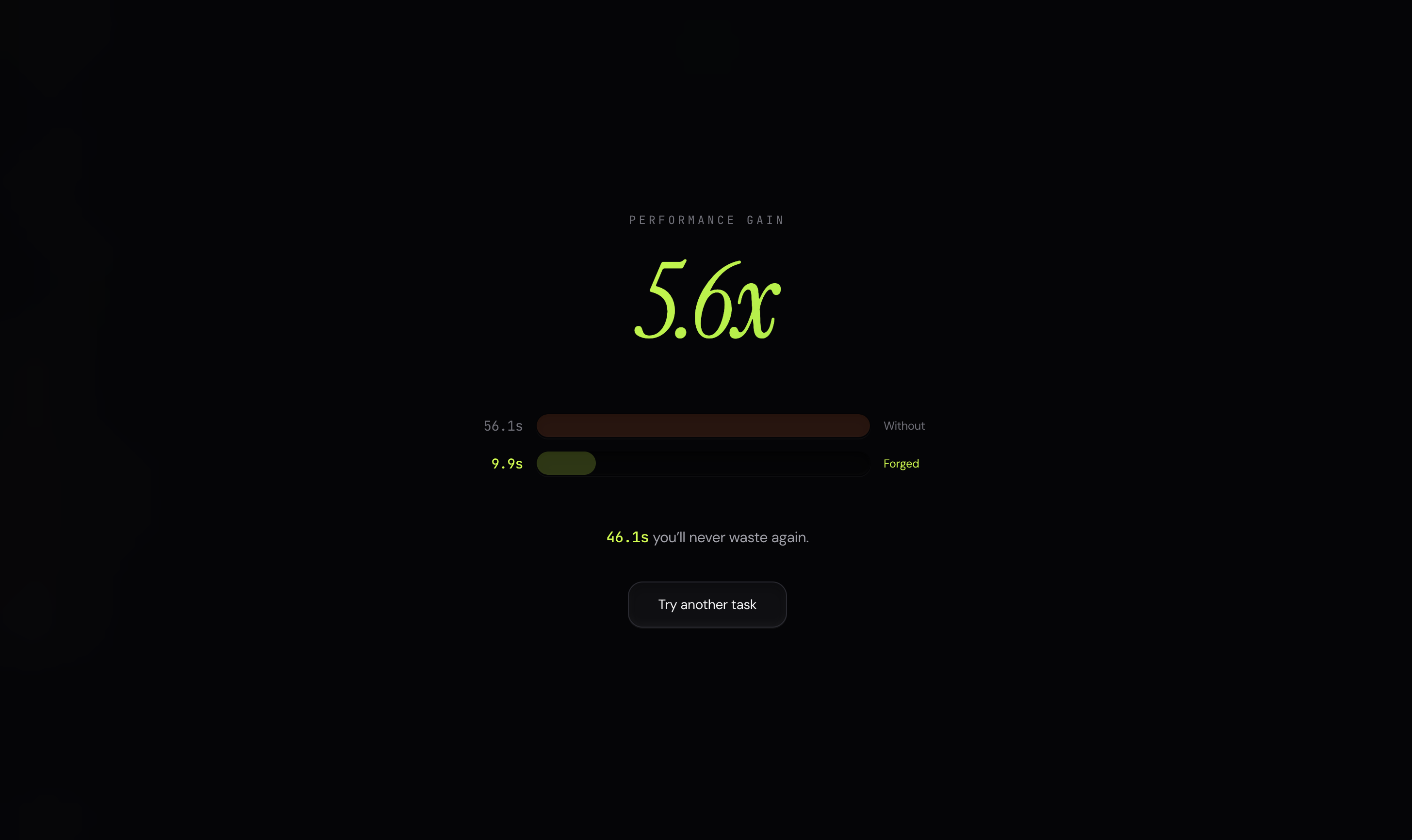
5.6× speedup — Playwright handles deterministic steps, the LLM only thinks when needed
-
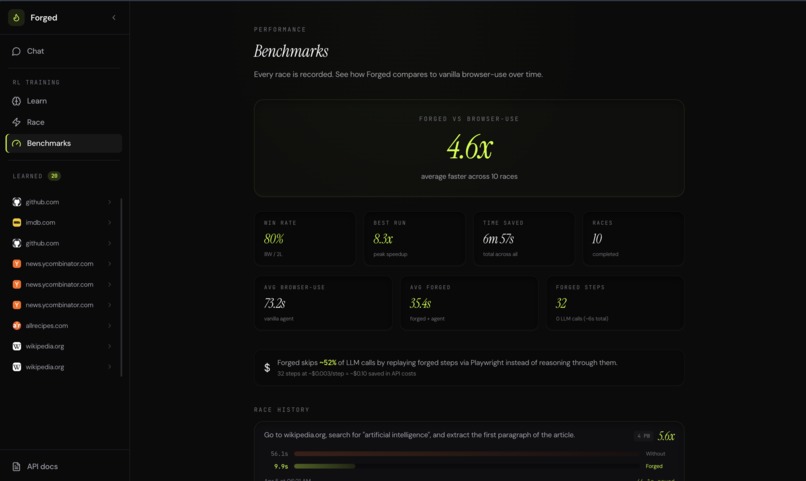
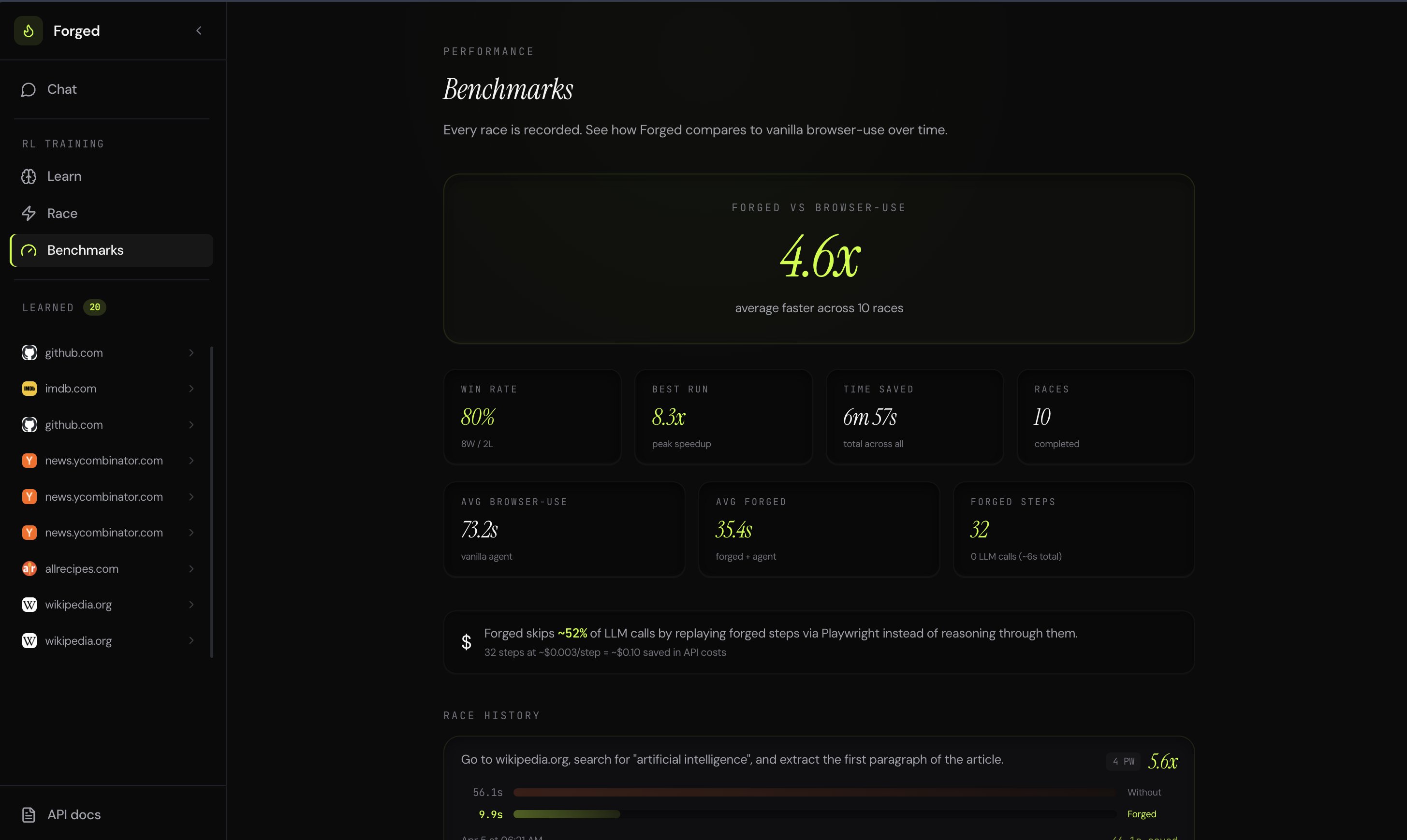
Benchmarks dashboard — track speedups across multiple sites and tasks
Inspiration
A Shahed-136 costs $25k. A Tomahawk costs $2M. Both hit the same target. One doesn't need GPS for every meter of flight. It follows a known path and adjusts only when it has to.
I kept watching Browser Use burn 3 seconds per step on things like "navigate to wikipedia.org." It screenshots the page, sends it to Claude, waits, parses the action. For clicking a search button. Every time. What if the agent only called the LLM when it actually needed to think?
What it does
Forged watches an agent run a task, then Claude Sonnet classifies each step as FIXED (same every run), PARAMETERIZED (same action, different value), or DYNAMIC (needs reasoning). The deterministic steps become a Playwright template. Next run, Playwright replays them via CDP. The LLM only handles the dynamic parts.
Wikipedia search: vanilla agent 82s, Forged 11s. Same answer. 7x faster. Fraction of the tokens.
Templates generalize. Learn "search Wikipedia for AI," it works for "dogs" without relearning. More templates = fewer LLM calls for everyone.
How I built it (solo, ~20 hours)
Python/FastAPI backend, React/Tailwind frontend.
The pipeline: Browser Use agent runs → trace captured → Sonnet classifies steps → template generator extracts the deterministic path with CSS selectors and parameterized values → stored in Supabase with pgvector embeddings → on next similar task, Haiku extracts parameters, Playwright replays known steps, and if all complete I skip the agent entirely and pull the answer from page DOM with a single Haiku call.
Matching uses OpenAI text-embedding-3-large with normalized structural text and domain/action-type boosting.
Built a step filter (Haiku) that decides which template steps apply to task variations, and implemented on_failure strategies (continue, retry, fallback).
MCP & open source
Forged exposes an MCP server. Plug it into Claude Code, Cursor, or any MCP-compatible tool. Your coding agent calls forged_browse to run browser tasks at template speed. Skills learned in one session carry over.
Keeping it fully open source. The template database gets more valuable as people contribute. Every user makes the system faster and cheaper for everyone else.
Challenges
Conservative classification. "Click first search result" was DYNAMIC because content changes. But structurally it's always click .result:first-child. Rewrote the prompt to bias toward FIXED. Speedup: 1.0x → 5.7x.
Embedding mismatch. Templates and queries used different text formats. Similarity was 15–20% too low. Fixed by normalizing both to structural skeletons.
The 35-second wall. After Playwright finished in 5s, the agent spent 35s "reading the page." Added fast extraction: grab innerText, send to Haiku, answer in 1s. Agent skipped.
What I learned
80% of browser agent steps are deterministic. The LLM burns tokens on decisions already made last time. Splitting known path from genuine reasoning is a multiplier on any agent, and it compounds.
What's next
Open source community templates. Self-improving templates that promote DYNAMIC steps to FIXED over time. Deeper MCP integration.
The endgame: browser agents on Playwright rails that only call the LLM when they hit something genuinely new.


Log in or sign up for Devpost to join the conversation.