-
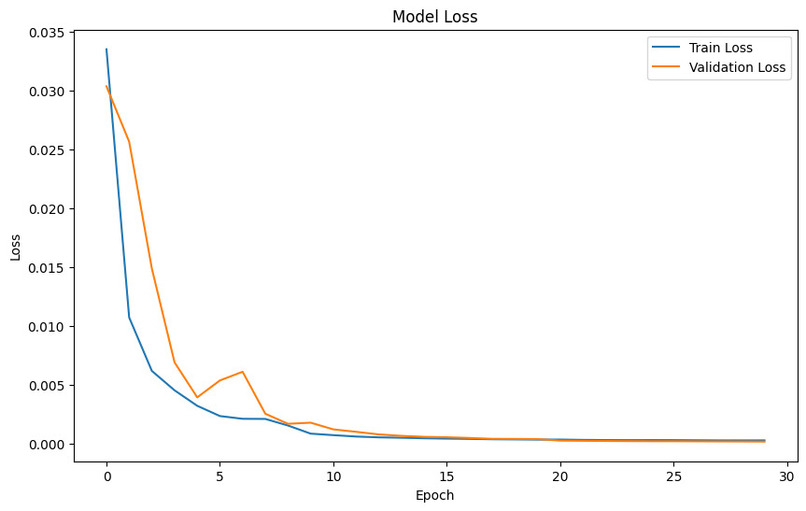
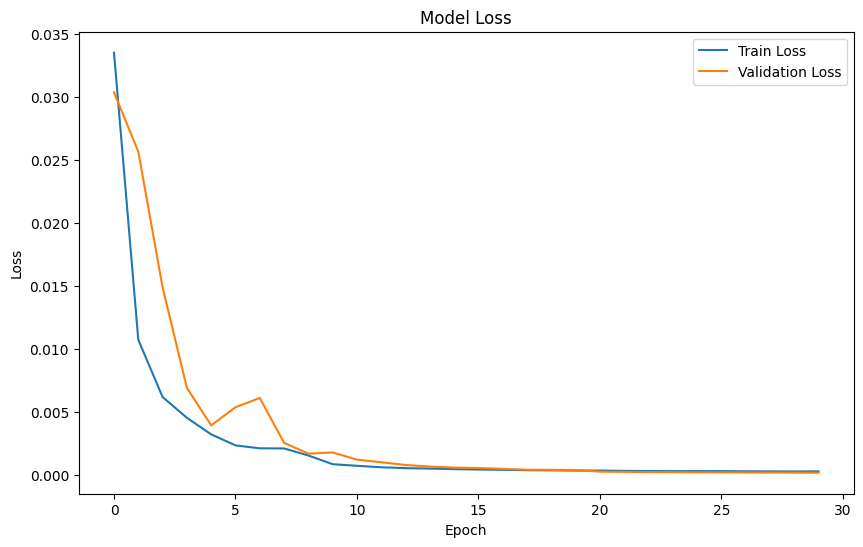
Loss Curves
Inspiration
The inspiration for this project came from reality . Buildings are one of the largest silent contributors to the climate crisis. They consume about a third of the world's energy and are responsible for a similar share of global greenhouse gas emissions. The idea of decarbonization isn't just about switching to renewable energy, it's about using that energy intelligently. Accurate short term load forecasting is the solution. If you can predict how much energy a building will need in the next hour or day, you can optimize heating, cooling, and lighting, better integrate unpredictable renewables like solar, and reduce reliance on fossil fuel power plants. The vision was to create a scalable tool that could bring this predictive power to any building, accelerating our transition to a sustainable future.
What it does
Our system leverages a Bidirectional LSTM model to produce short term forecasts of energy consumption. The model achieves exceptionally low prediction loss (MSE), providing a reliable and precise view of future demand.We can use these results not only for smart energy management but also for Anomaly detection in case of faulty components .
How we built it
The core of our model's architecture is a Bidirectional Long Short-Term Memory (BiLSTM) network. A standard LSTM network processes data chronologically, learning from the past to predict the future. However, a BiLSTM processes the data in two directions: forwards and backwards. This allows it to learn from the full context of a data point, considering both what happened before and what came after.
For any given time step t, the final hidden state ht is a concatenation of the forward hidden state ht and the backward hidden state ht. This can be represented as: $$h_t = [\overrightarrow{h_t} ; \overleftarrow{h_t}]$$
This dual-context approach makes the model incredibly powerful for identifying subtle patterns and anomalies in energy consumption data.
Challenges we ran into
We ran into several challenges . The most obvious one was the lack of compute . As we're students with little to no budget we had to rely on free limits of Colab and Kaggle to train our models. We also faced an issue with high variance where our model was overfitting . Currently we're trying for better models , ideally something based on attention as we feel like it will improve the results even more.
Accomplishments that we're proud of
We achieved an test RMSE of ~0.05 on the "uciml/electric-power-consumption-data-set" and we're very proud of that . We beat the gold medalist on that data set who had a test rmse of around 0.6.
What we learned
We learned a lot about BiLSTM , the underlying concepts and the mathematical intution behind the model.
What's next for Foresight
We're currently trying a lot of different approaches , most of them focused around attention as I think it will improve our model even further.

Log in or sign up for Devpost to join the conversation.