Foresight
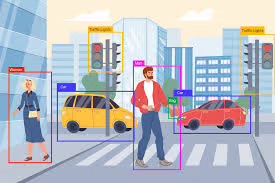
Foresight is an accessibility accelerator that helps visually impaired users by combining ShareGPT4V for visual analysis, Detectron2 for object grounding, and the Gemma model to reduce hallucinations and boost accuracy. By integrating speech-to-text and text-to-speech multimodal interaction, Foresight delivers context-aware assistance and identifies 12% more information than the base model, making AI support more reliable in real-world scenarios. The project was awarded first place at the innovation fair at my undergraduate university.
Key Features
- Image Analysis: Capture photos and ask questions about them
- Multi-modal AI: Uses advanced AI models for accurate scene understanding
- Object Grounding: Highlights objects in images with distinct colors
- Voice Interface: Supports both speech-to-text for queries and text-to-speech for responses
- Dynamic Conversations: Users can ask follow-up questions about captured images
- Reduced Hallucinations: Combines multiple AI models to provide more accurate responses
Technology Stack
- ShareGPT4V for visual analysis
- Detectron2 for object detection and grounding
- Gemma model for response generation
- Speech-to-text and text-to-speech capabilities
- Open-source architecture for customization
Impact
Foresight demonstrates an 11% improvement in image information identification compared to base models, making it a powerful tool for assisting visually impaired individuals in their daily lives.
Future Development
- Performance optimization
- Real-time response capabilities
- Multilingual support
- Enhanced data source integration
Built With
- c
- c++
- cmake
- dart
- html
- kotlin
- objective-c
- swift

Log in or sign up for Devpost to join the conversation.