-
-
-
-
-
-
-
Request flow
-


Inspiration
Prediction markets like Kalshi turn uncertainty into a price—but the crowd is hard to beat. At Prophet Hacks (UChicago, May 2026), the Forecasting Track challenged us to register a live agent, answer ~200 real-world events over two weeks, and outscore the market on proper scoring rules, not vibes.
We were drawn to a question between ML and judgment: What does it take to beat an efficient crowd when everyone sees the same ticker? Our answer was not one bigger model, but deliberation—independent reasoning, structured debate, and calibration tuned for Brier loss, where overconfidence is punished harshly.
What it does
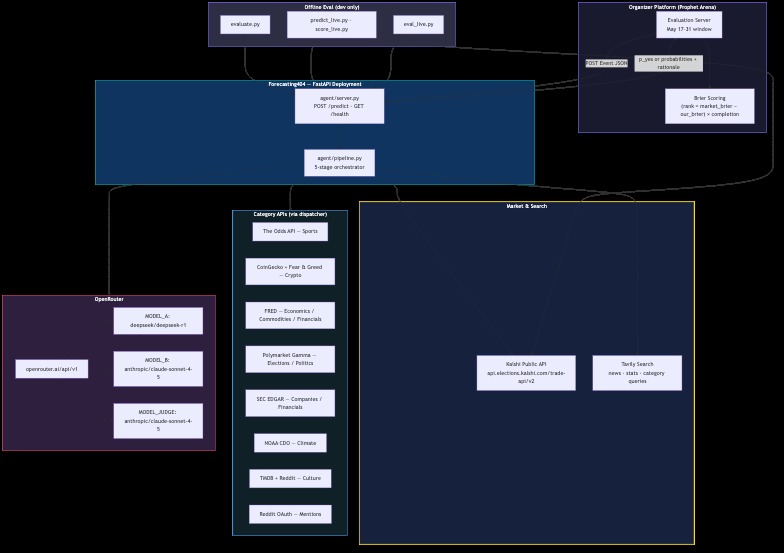
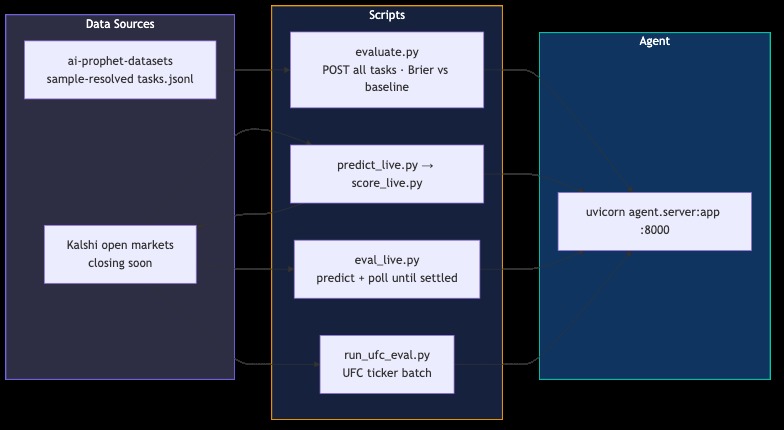
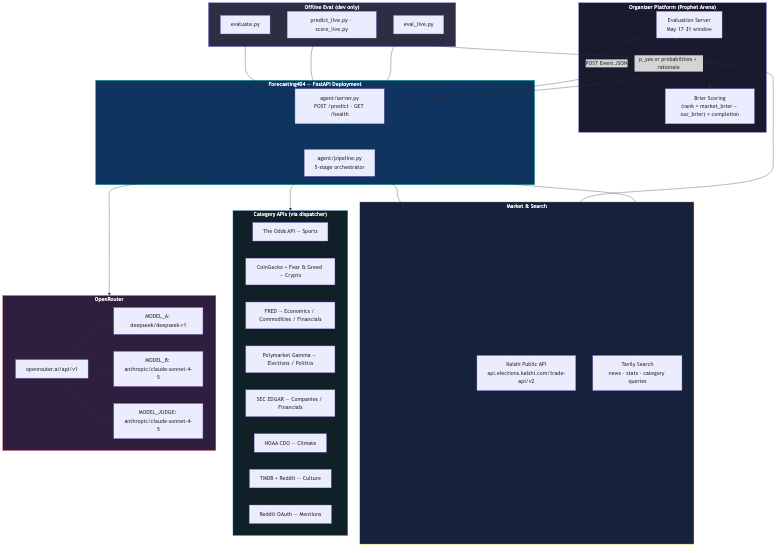
Forecasting404 is a deployed FastAPI forecasting agent. Organizers send a Kalshi-style event to POST /predict; we return calibrated probabilities plus a rationale.
The agent handles three event shapes:
| Type | Example outcomes | Response |
|---|---|---|
| Binary | Yes / No, team names |
{ "p_yes": 0.67 } |
| Multi-outcome | Many named winners (up to ~30) | { "probabilities": [...] } |
| Numeric range | "49 or below", "50", … |
Same as multi |
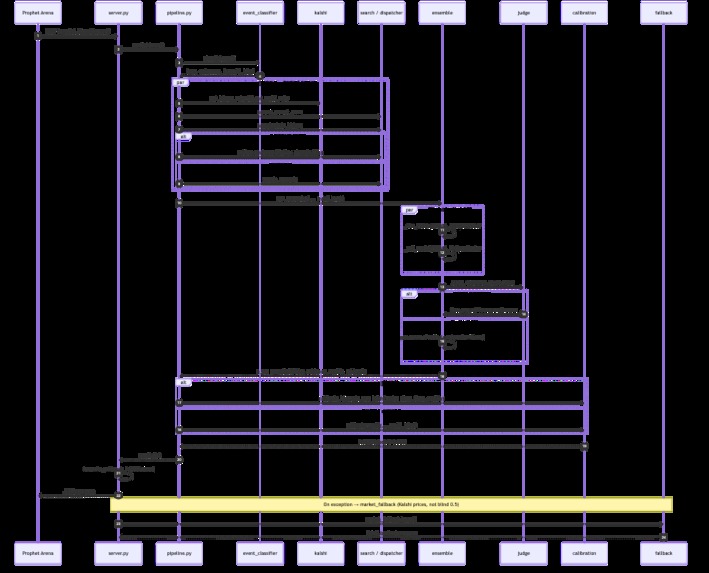
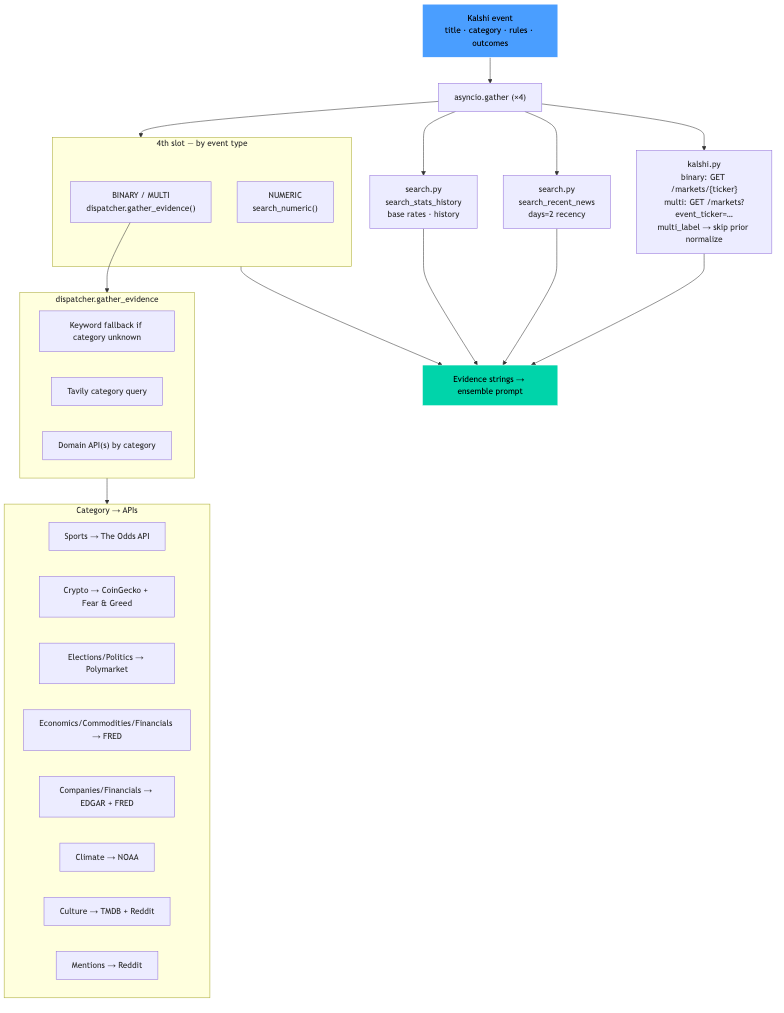
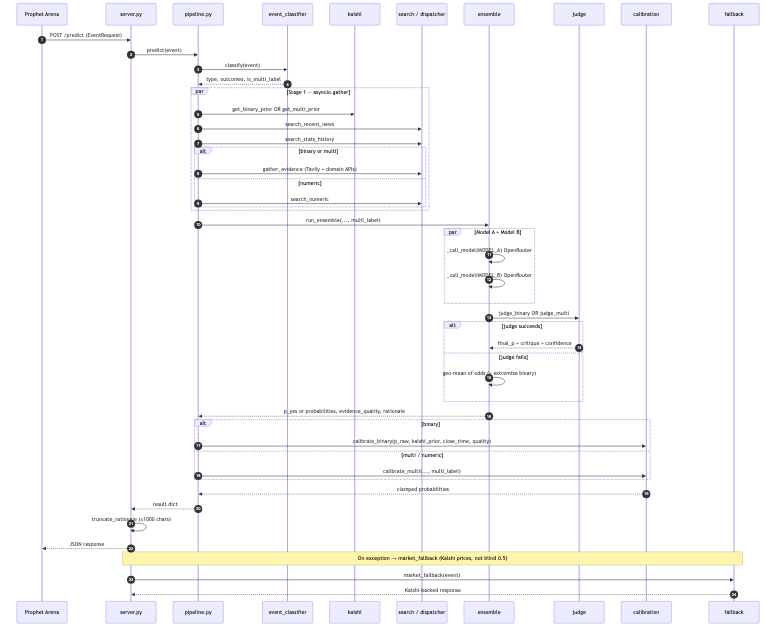
For each event it:
- Classifies the market (binary / multi / numeric, plus winner-take-all vs multi-label).
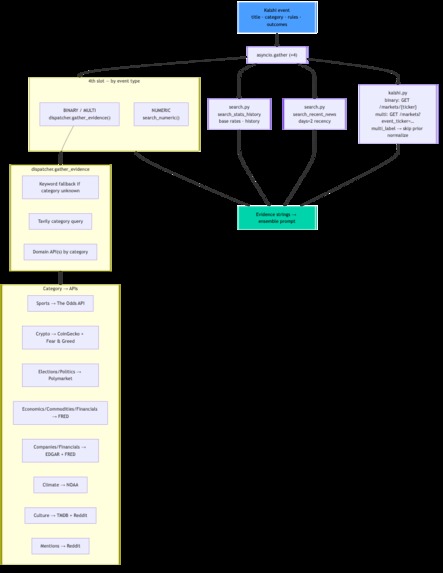
- Gathers evidence in parallel—Kalshi mid prices, Tavily news, and category-specific APIs (sports odds, FRED, Polymarket, SEC EDGAR, NOAA, TMDB, Reddit, crypto feeds, and more).
- Runs two forecasters (DeepSeek R1 + Claude Sonnet) through a shared structured protocol: decompose → argue for/against → estimate.
- Arbitrates with a judge model that audits both traces for anchoring, overconfidence, and correlated errors—not a simple average.
- Calibrates toward the Kalshi prior with time-to-close shrinkage, then clamps to valid ranges.
Ranking score (higher is better):
$$ \text{score} = (\text{market_avg_brier} - \text{our_avg_brier}) \times \text{completion_rate} $$
Per-event Brier loss for a binary forecast:
$$ \text{Brier} = (p - y)^2 $$
where (p) is our probability and (y \in {0,1}) is the realized outcome. Lower is better; a naive (p = 0.5) guess scores about (0.25) on average.
How we built it
We optimized for latency, correct API contracts, and Brier-optimal behavior under a 32-hour hackathon clock.
Stack: Python 3.11+, FastAPI, asyncio, OpenRouter (DeepSeek R1 + Claude Sonnet), Tavily, Kalshi public REST API (no auth), and optional domain APIs that degrade gracefully when keys are missing.
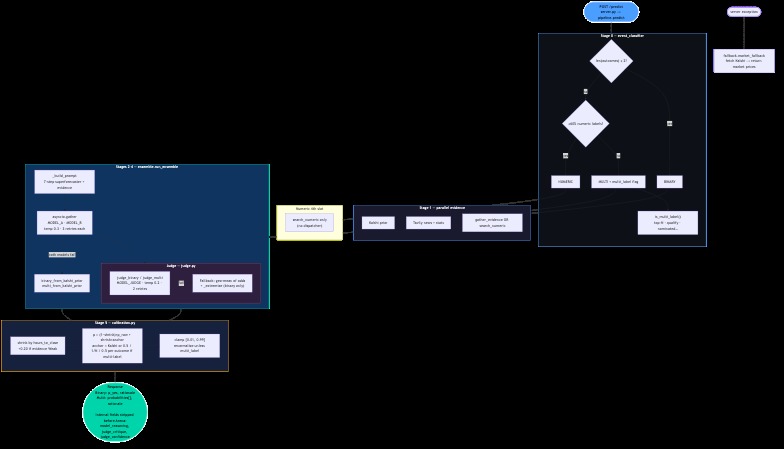
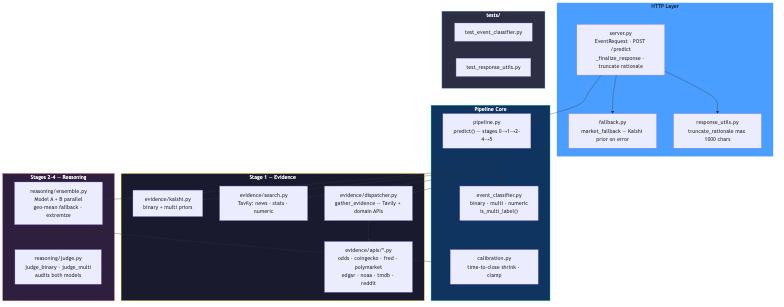
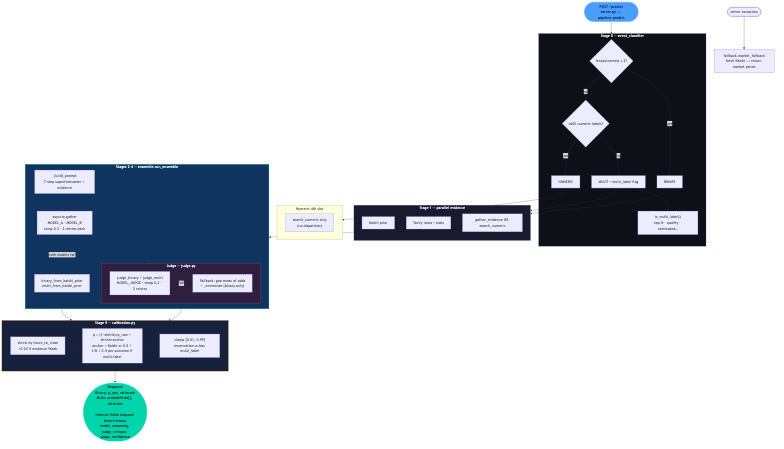
Pipeline:
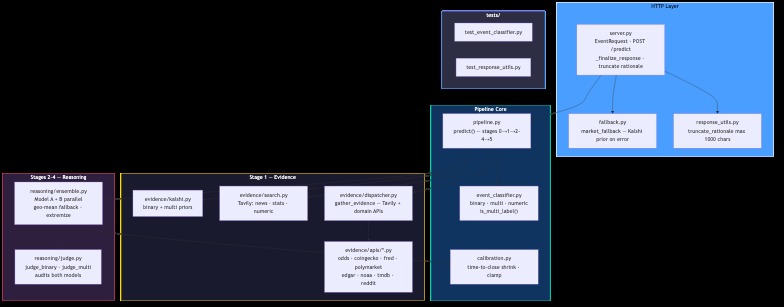
- Stage 0 —
event_classifier.py: Routes binary vs multi vs numeric; detects multi-label markets (e.g. "top 5 finish") where probabilities are independent marginals, not a distribution that must sum to 1. - Stage 1 — evidence:
asyncio.gatherruns Kalshi priors, Tavily (recency + history + category queries), anddispatcher.pyroutes to nine API families by category (with keyword fallback whencategoryis missing). - Stages 2–4 —
ensemble.py+judge.py: Model A and B run in parallel; the judge picks a defensible final (p). Fallback ensemble uses geometric mean of odds:
$$ \text{odds}i = \frac{p_i}{1-p_i}, \quad \tilde{\text{odds}} = \sqrt{\text{odds}_A \cdot \text{odds}_B}, \quad p{\text{ensemble}} = \frac{\tilde{\text{odds}}}{1 + \tilde{\text{odds}}} $$
- Stage 5 —
calibration.py: Shrinks toward the Kalshi anchor, with stronger shrink when time-to-close is large or evidence is weak; clamps to ([0.01, 0.99]) and renormalizes winner-take-all multis.
Reliability: fallback.py returns Kalshi prices (or neutral priors) on internal errors so we keep completion rate high—a direct multiplier on the leaderboard formula.
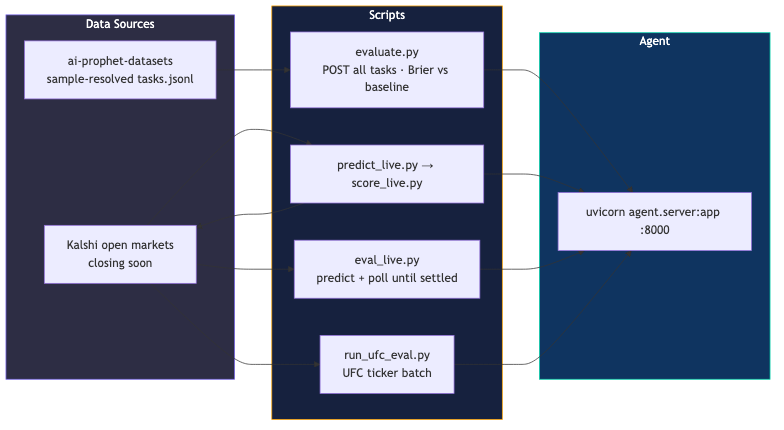
Local eval: Scripts like evaluate.py and eval_live.py score predictions against resolved markets before the official window.
Challenges we ran into
Beating a strong prior. Kalshi prices are our baseline and our anchor. Moving away without evidence hurts Brier; staying glued to the market never beats it. Time-to-close shrinkage was our compromise: trust research more near resolution, lean on the crowd when the event is far out.
Three response shapes, one server. Binary p_yes, multi-outcome distributions, and numeric buckets each have different JSON contracts. Probabilities must sum to 1 (winner-take-all); each probability must stay in ([0.01, 0.99]).
Multi-label vs winner-take-all. Treating "top 5" markets like a single winner and renormalizing destroyed marginal probabilities. We added rule-pattern detection and threaded is_multi_label through priors, prompts, judge, and calibration.
Latency vs depth. Three LLM calls plus many API fetches per event is expensive. We parallelized evidence gathering and dual models, and merged reasoning into one structured call per model.
Correlated model errors. Two strong models can share the same blind spot. The judge catches agreement without justification—consensus that is really duplicated bias.
API reality. Kalshi tickers, string dollar fields, missing categories, and rate limits forced defensive parsing and graceful empty evidence strings rather than hard failures.
Accomplishments that we're proud of
- A production-ready
POST /predictagent with health checks, structured fallbacks, and unit tests on classification and response utilities. - A deliberative architecture (dual forecasters + judge) aimed at the competition metric, not generic chat.
- Category-aware evidence fusion across nine API families, always backed by Tavily, with keyword routing when metadata is thin.
- Correct handling of binary, multi-outcome, numeric, and multi-label markets in one pipeline.
- Brier-first calibration—shrink toward market priors, extremize when models agree, clamp to valid probability bands.
- Shipping end-to-end in a 32-hour hackathon window while leaving room for two weeks of live evaluation.
What we learned
- Scoring rules shape architecture. Brier score rewards calibration and punishes 0.99 on uncertain events; that pushed us toward shrinkage and ([0.01, 0.99]) clamps instead of flashy extreme calls.
- Ensembles need diversity, not just voting. Geometric mean of odds beats arithmetic averaging when combining correlated estimates—but a judge is still needed when both models err the same way.
- The market is data. Kalshi mid is the best single prior we have. The win condition is conditional edge: better evidence and reasoning when it matters.
- Contracts matter as much as models. Event classification, multi-label detection, and response normalization were as important as prompt engineering.
- Parallel I/O is free performance.
asyncio.gatherfor evidence and dual models was the difference between timeout and a completed prediction during eval bursts.
What's next for Forecasting404
- Live leaderboard feedback: Track per-category Brier vs market during the May 17–31 eval window and tune shrinkage weights.
- Faster paths for easy events: Skip the judge when A/B agree within (\epsilon) and evidence quality is high.
- Resolution-aware prompting: Few-shot examples per category from our resolved eval set.
- Richer sports and elections tooling: Deeper injury/lineup pipelines and polling aggregation.
- Offline calibration layer: Platt scaling or isotonic regression on held-out resolved events.
- Observability: Structured traces per stage for post-mortems when we beat—or lose to—the crowd.

Log in or sign up for Devpost to join the conversation.