-
-
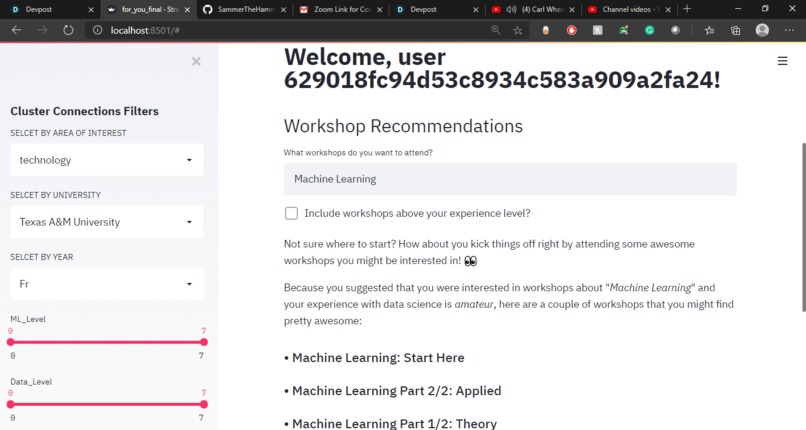
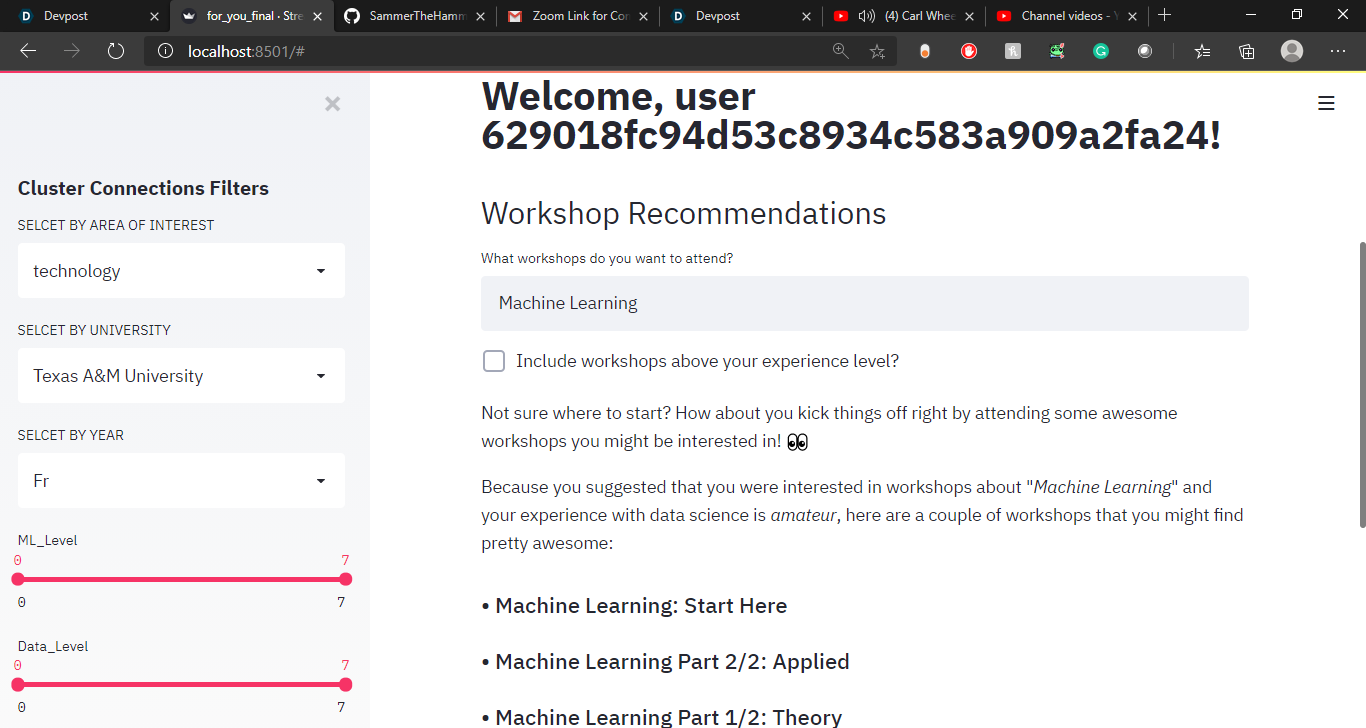
Workshop Recommendation Engine
-
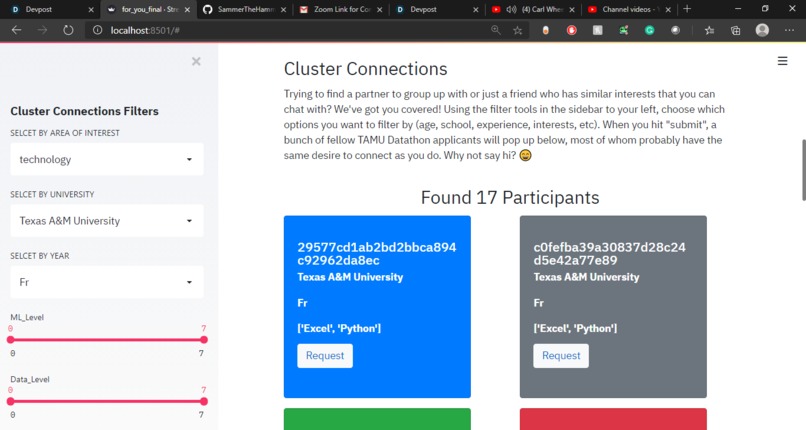
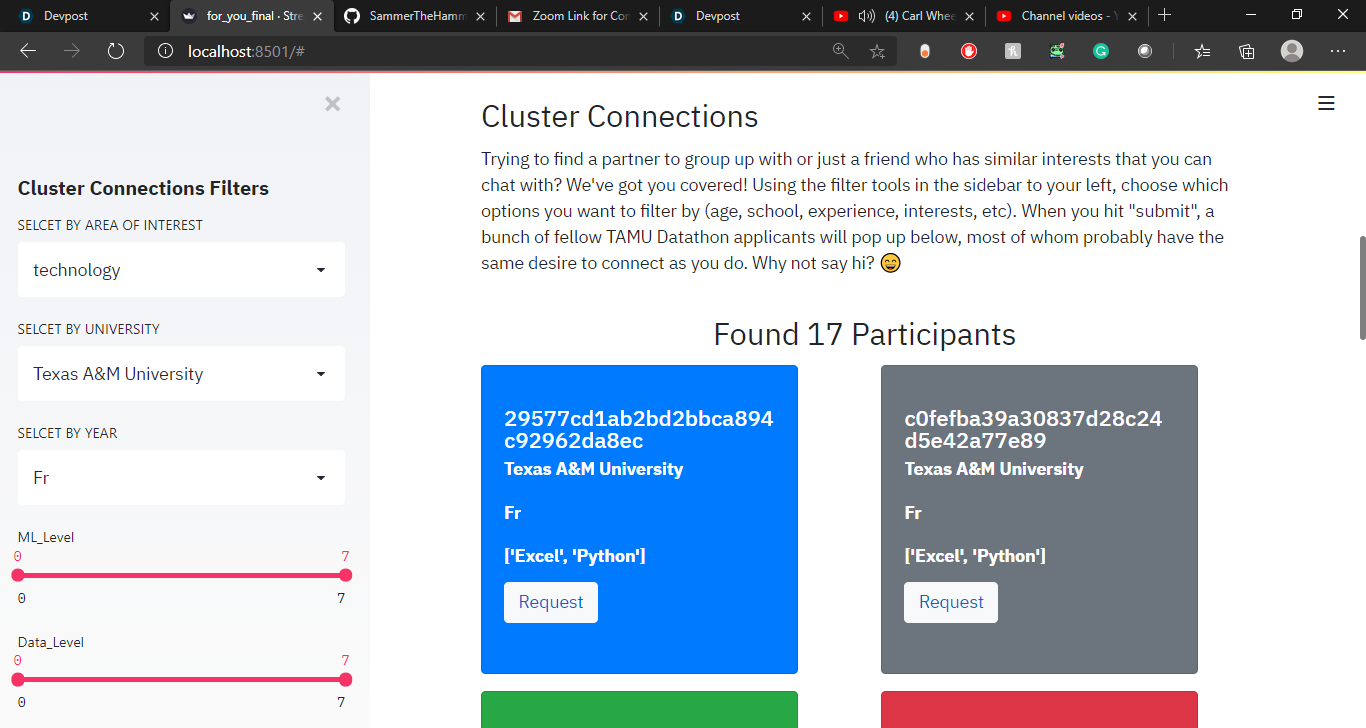
Cluster Connections Engine
Inspiration
We took The TD-for-you Challenge which gives the TAMU-Hackathon-2020 data, where we could play with data and build tools that help the participants in the Hackathon.
What it does
Our project has 2 functionalities, One is giving recommendations for searching teammates who can complement the skills you want for your project, you can filter participants based on their school, year, and area of interest. The model uses WordtoVec for finding semantic similarity between participants Major and the user's Area of interest.
The next functionality is the Workshop Recommendation Engine- Takes data from the workshops database and uses the tags to create and train a very rough NLP model with the queries dataset as input data. Uses the user's queries to predict a track of the workshop and experience in data science to suggest the most appropriate workshops from there.
How we built it
For Team-building we made the data into a presentable and clear form, we took some user inputs and tried to filter participants based on the user's preferences. We calculated each participant's skill levels in various subdomains based on their technology and data science experience. We provided the user to choose if the participants have previous hackathon experience or not. We tried to see in which subdomain user is lacking and gave recommendations based on that too.
To build the workshop recommendation engine, I used pandas for preprocessing with building my own functions to filter the data. I used scikit to train the model based on the queries data (supervised model) and to fit future data, and I finally used Streamlit to develop the front end.
Challenges we ran into
Finding similarity between participant major and user's Area of interest is challenging a bit, we used Word2Vec to find similarities, it is not perfect but good enough. Developing UI is a bit confusing at first since we have little experience in the development part.
The time frame did not allow for the best data preprocessing, and because I am still new to model development and machine learning, it took me some time to develop the crude model. The model is a bit inaccurate on some terms, largely due to the relatively small amount of data there was to train it. If I had more time and I knew what I know now after attending the workshops, I would do some scraping of the workshop descriptions to get better tags for the bag of words model.
Accomplishments that we're proud of
All the teammates have average to little experience in UI development and Data Science, at a point, everyone is exhausted but eventually pulled off successfully. We are proud of how the project turned out.
Managed to get an accuracy score of 70-80% fairly consistently on queries dataset. Quite successful when users use it dynamically with the GUI. Very proud of that for my first time using Streamlit and my first time building a professional project using scikit model training.
What we learned
We learned Streamlit and how we could use it to develop quick UI for competitions like this. We also learned a lot about NLP and how to train models to fit natural language.
What's next for for_you
Maybe attend this Hackathon next year and solve some more exciting challenges. Furthermore, give more data to the training set of the NLP model in order to get better predictions and perhaps include an unsupervised model for general queries the user may have, not even necessarily related to the workshops themselves.
Built With
- datascience
- jupyter
- natural-language-processing
- numpy
- pandas
- streamlit


Log in or sign up for Devpost to join the conversation.