-
-
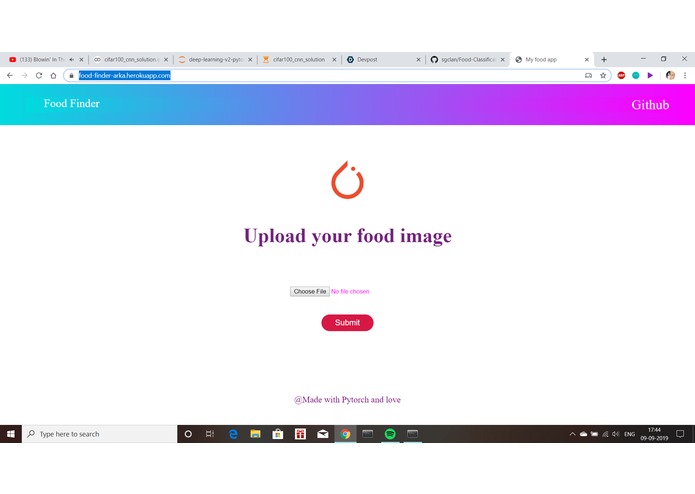
website
-

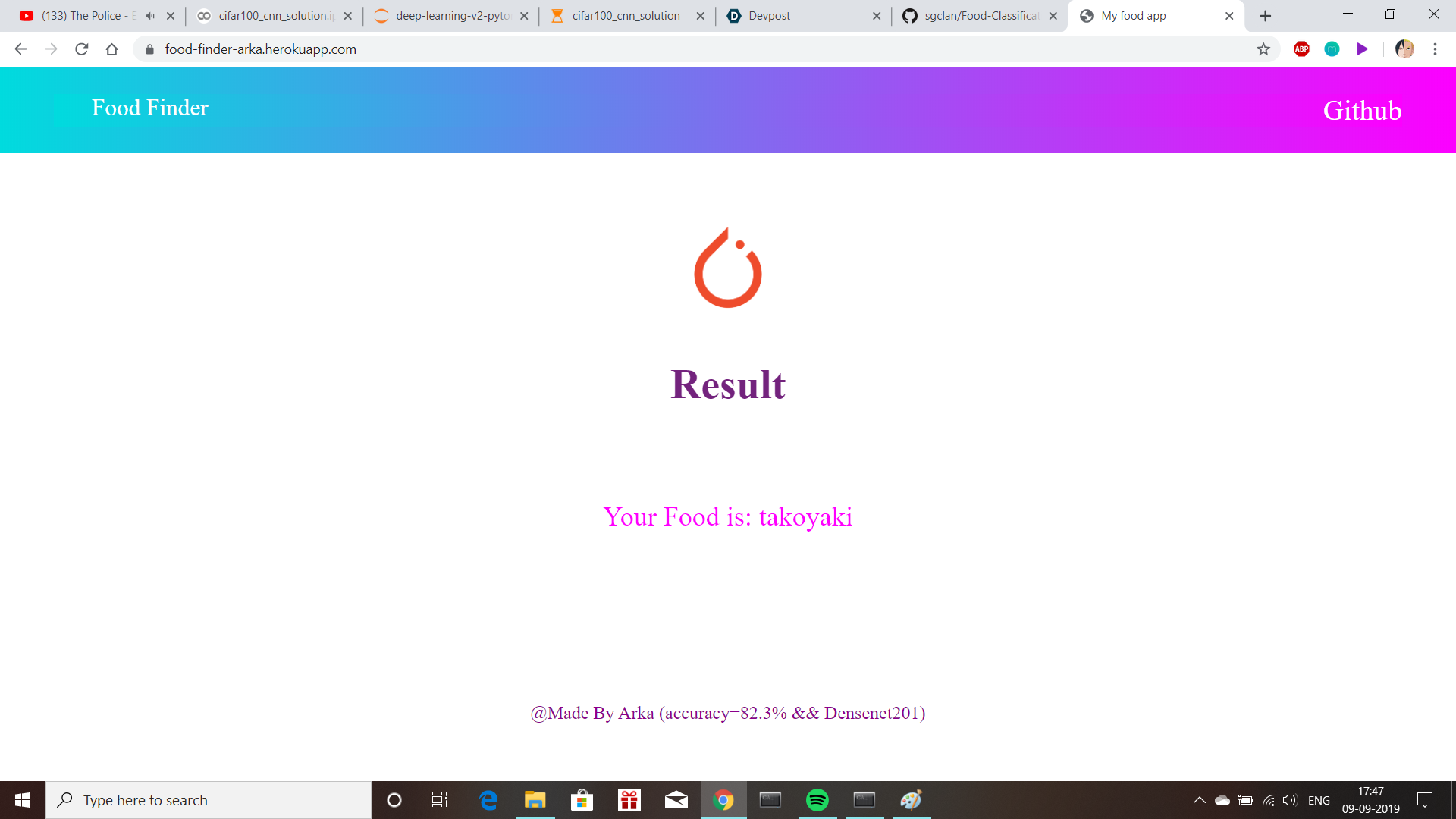
test image of takoyaki
-
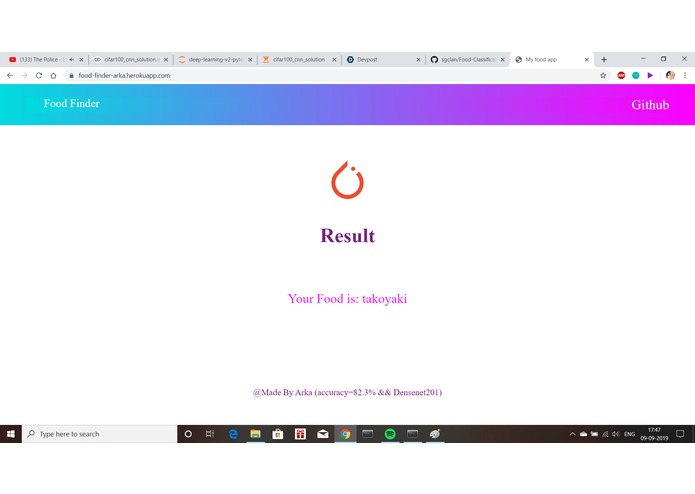
result
-
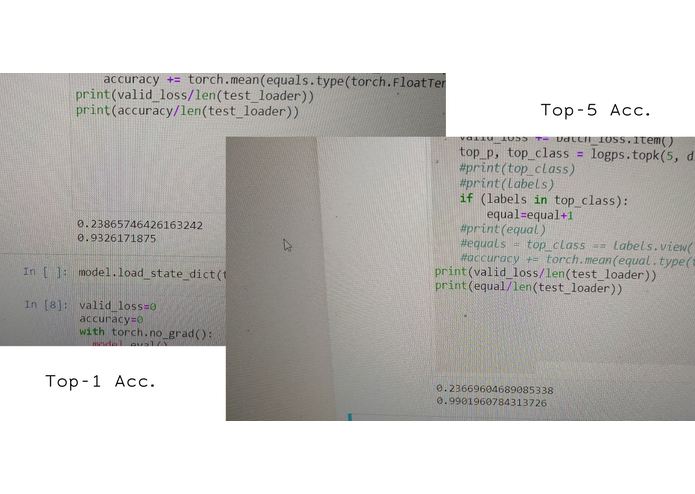
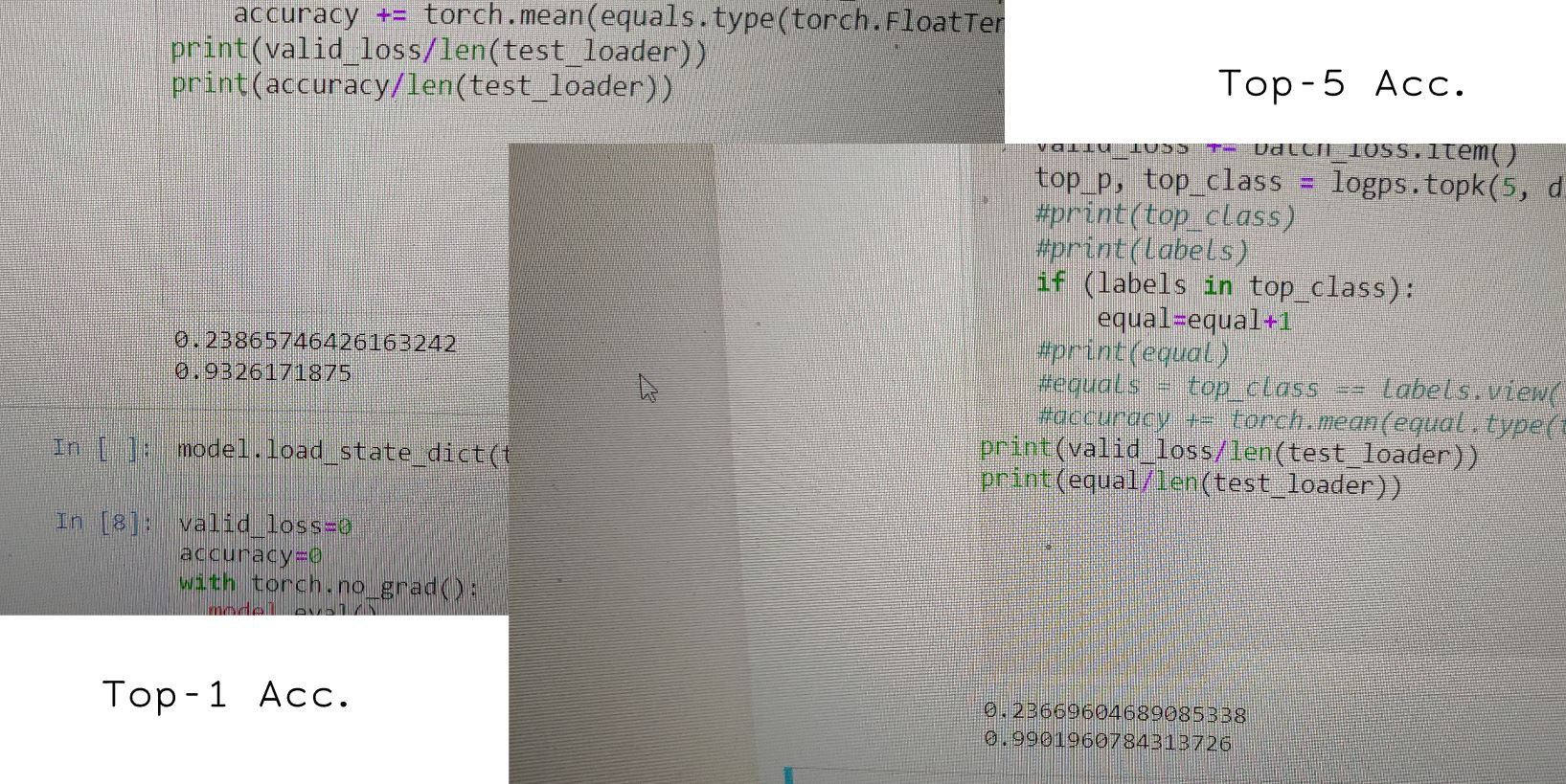
top-1 and top-5 accuracy

Food Classification with DenseNet-161

Recent growth in nutrition related diseases globally have increased awareness in keeping healthy nutritional habits. Healthy diets reduce the risks of reactions to food intolerance, weight problems, malnutrition and some forms of cancer. There are several applications in existance with which we can manually keep track of what we eat and identify food items before consumption. These applications however require that previous experience with the food item for easy identification. An important question however is: what happens if we see a food item for the first time and need to identify it? Automated tools of food identification will be of help in such case. The advent of Convolutional Neural Networks (CNN) and deep learning based architechtures have opened opportunities for the realization of such automatic tools. Indeed, a lot of mileage has already been made in neural networks based image food classification. However, there are still gaps in accuracy of existing methods implemented. In response, we propose a technique based on a pretrained Dense-Net-161, and we enhance class separability using successive augmentation of the data before feeding it to the model. To evaluate our proposed architecture, we have conducted experimental results on a benchmark dataset (Food-101). Our results show better performance with respect to existing approaches. Specifically, we obtained a Top-1 accuracy of 93.27% and Top-5 accuracy around 99.02% on the Food-101 dataset).
| Method | Top - 1 | Top - 5 | Publication |
|---|---|---|---|
| HoG | 8.85 | - | ECCV2014 |
| SURF BoW-1024 | 33.47 | - | ECCV2014 |
| SURF IFV-64 | 44.79 | - | ECCV2014 |
| SURF IFV-64 + Color Bow-64 | 49.40 | - | ECCV2014 |
| IFV | 38.88 | - | ECCV2014 |
| RF | 37.72 | - | ECCV2014 |
| RCF | 28.46 | - | ECCV2014 |
| MLDS | 42.63 | - | ECCV2014 |
| RFDC | 50.76 | - | ECCV2014 |
| SELC | 55.89 | - | CVIU2016 |
| AlexNet-CNN | 56.40 | - | ECCV2014 |
| DCNN-FOOD | 70.41 | - | ICME2015 |
| DeepFood | 77.4 | 93.7 | COST2016 |
| Inception V3 | 88.28 | 96.88 | ECCVW2016 |
| ResNet-200 | 88.38 | 97.85 | CVPR2016 |
| WRN | 88.72 | 97.92 | BMVC2016 |
| ResNext-101 | 85.4 | 96.5 | Proposed |
| WISeR | 90.27 | 98.71 | UNIUD2016 |
| DenseNet - 161 | 93.26 | 99.01 | Proposed |
The Objectives
The first goal is to be **able to automatically classify food item images previously unseen by our model. Beyond this, there are a number of possibilities for looking at what regions/image components are important for making classifications, identify new types of food as combinations of existing tags, build object detectors which can find similar objects in a full scene.
Approach
Dataset
Deep learning-based algorithms require large dataset. Foodspoting's FOOD-101 dataset contains a number of different subsets of the full food-101 data. The idea is to make a more exciting simple training set for image analysis than CIFAR10 or MNIST. For this reason the data includes massively downscaled versions of the images to enable quick tests. The data has been reformatted as HDF5 and specifically Keras HDF5Matrix which allows them to be easily read in. The file names indicate the contents of the file. For example
food_c101_n1000_r384x384x3.h5 means there are 101 categories represented, with n=1000 images, that have a resolution of 384x384x3 (RGB, uint8)
food_test_c101_n1000_r32x32x1.h5 means the data is part of the validation set, has 101 categories represented, with n=1000 images, that have a resolution of 32x32x1 (float32 from -1 to 1)
Model
CNNs increasingly became powerful in large scale image recognition. Alexnet introduced in ILSVRC 2012 had 60 million parameters with 650,000 neurons, consisting of five convolutional layers. Those layers are followed by max pooling, globally connected layers and around 1000 softmax layers. With this inspiration, several other architectures were produced to provide better solution. Few of honourable mentions include ZFNet by Zeiler and Fergus, VGGNet by Simonyan et al., GoogLeNet (Inception-v1) by Szegedy et al and ResNet by He et al.
Dense Convolutional Network (DenseNet) [arixv 1608.0699] is another state-of-the-art CNN architecture inspired by the cascade-correlation learning architecture proposed in NIPS, 1989. The architecture connects each layer to every other layer in a feed-forward fashion. Whereas traditional convolutional networks with L layers have L connections—one between each layer and its subsequent layer—our network has L(L+1) 2 direct connections. For each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers.


Why Densenet?
The advantages of Densenet include its ability to alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters.

Image Preprocessing
Pytorch provides the API for loading and preprocessing raw images from the user. However, the dataset and the images in the raw state as obtained aren't suitable for further processing. Consequently, successive transformations are used to preprocess the training dataset. In our implemetation, these transformations include: Random rotation ,Random resized crop, Random horizontal flip, Imagenet policy and at the end Normalization.
These preprocessing transforms are used to mitigate the disparities in image properties due to different image backgrounds; to help the model learn faster; and to improve the output accuracy.
Our transforms for both the training and test data are defined as follows:
train_transforms = transforms.Compose([transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),ImageNetPolicy(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
test_transforms = transforms.Compose([transforms.Resize(255),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
An illustration is attached in this repository to depict the outcome of the transforms.


Methodology
We utilized a system having the following configuration to run the whole program:
| Vendor | Asus (RoG) |
|---|---|
| Processor | Core I7 |
| Ram | 8 Gb |
| GPU | Nvidia GTX - 1050ti |
The machine spent 4-5 days to process the complicated network structure and complete the learning task. We implemented our image classsification pipeline using the latest edition of PyTorch (as at 19/08/2019). We applied the transfer learning method to our model which by using the pretrained Densenet-161 model in the following steps:
- At first, with a pretrrained DenseNet-161 model, we loaded a checkpoint. The checkpoints file contains all the tensors after months of training with the ImageNet dataset.
- Secondly, we redefined the classifier part of the model (i.e
model.Classifier()) to fit our number of outputs classes (101) as derived from our inout data classes. Side note: ImageNet trained networks have 1001 output classes by default. Below is a sample code snippet for the classifier block (i.emodel.Classifier()) we implemented. You can observe the number of classes have been modified to fit with the food-101 dataset classes (i.e 101).classifier = nn.Sequential(OrderedDict([ ('fc1', nn.Linear(1024, 500)), ('relu', nn.ReLU()), ('fc2', nn.Linear(500, 101)), ('output', nn.LogSoftmax(dim=1)) ]))
To evaluvate our model, we split the dataset into training, test and validation in a ratio 8:1:1 i.e the 80% of the whole dataset was used for training and the rest equally split into test and validation. We obtained the model training and test error.
To improve our model classification accuracy and reduce the derived error values, we fine tuned the network parameters using Adam optimizer as defined below. This optimizer requires that we set the learning rate and learning rate decay parameters. To achieve the minimum loss, we have spent several days tweaking these paramters to find a sweet spot (Patience is always needed in deep learning based applications, and our case was not an exception). Other tunings we performed include the use of dropouts are used to prevent overfitting.
Here is a code snippet showing the specific betas for our Adam optimizer:
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001, betas=[0.9, 0.999])```
Result
Here is an illustration depicting the progress due to heavy augmentation and overall accuracy achieved from the model.


Future work
This work continues, and we intend to implement the following in the coming weeks/months:
- Mobile application for automatic food identification.
- Inclusion of more food classes in the model classification capability. This will be done by collecting and annotating more data in varying food categories across different parts of the world. Our team is composed of people from different countries and continents, thus we intend to leverage our diversity in achieving this goal.





Log in or sign up for Devpost to join the conversation.