-
-
UN Sustainable Goals
-
Data Analysis
-
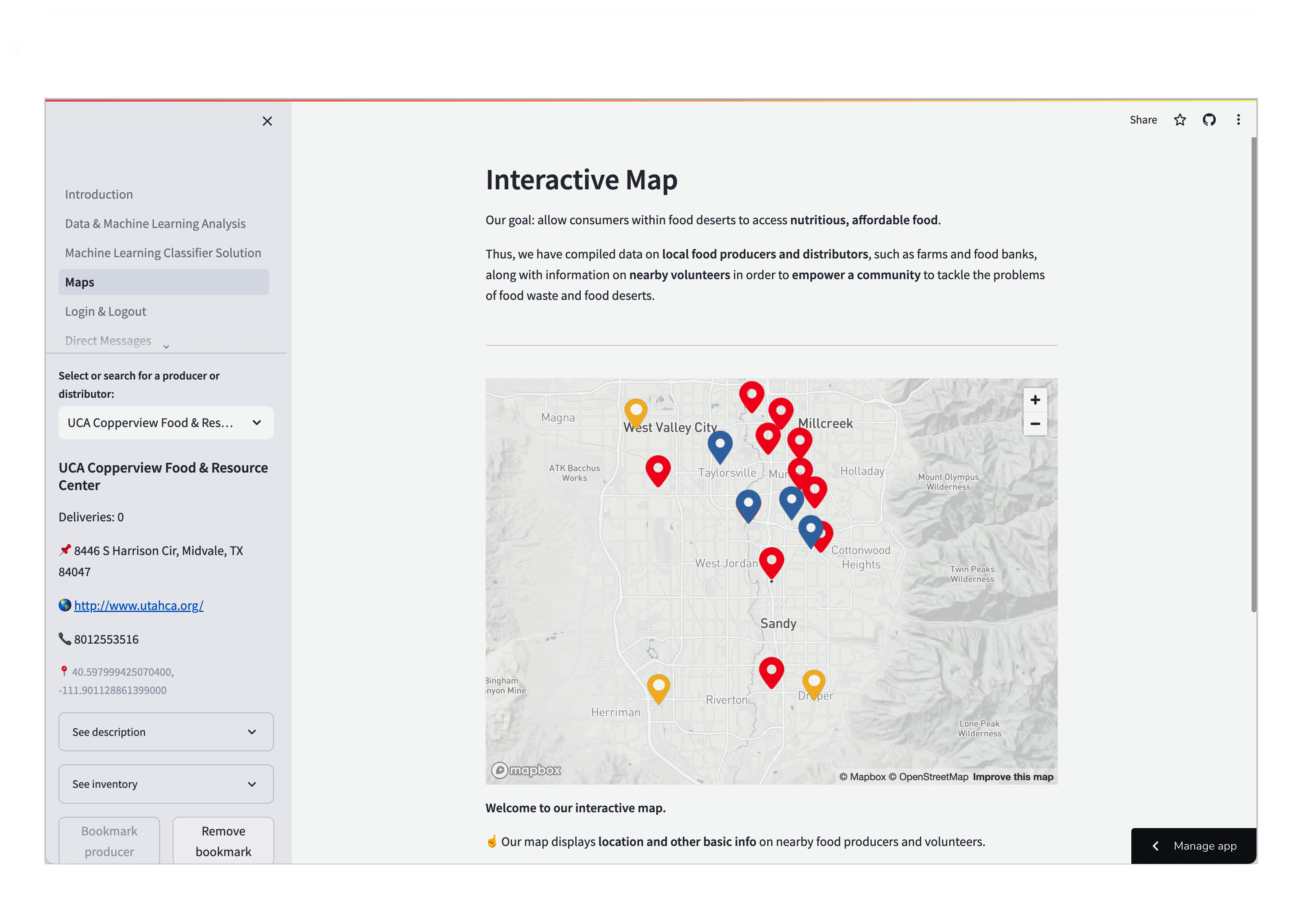
Map
Inspiration 🌟
- Approximately 20 billion tons, 2 billion tons, and 43 billion tons of fresh produce are wasted and thrown away on farms, factories, and stores, respectively due to the fact that they appear ugly yet are perfectly edible. Minimizing this food waste could lead to less food insecurity and mollify the severity of food deserts (entire areas lacking access to fresh produce due to a dearth of local stores).
What it does 🤔
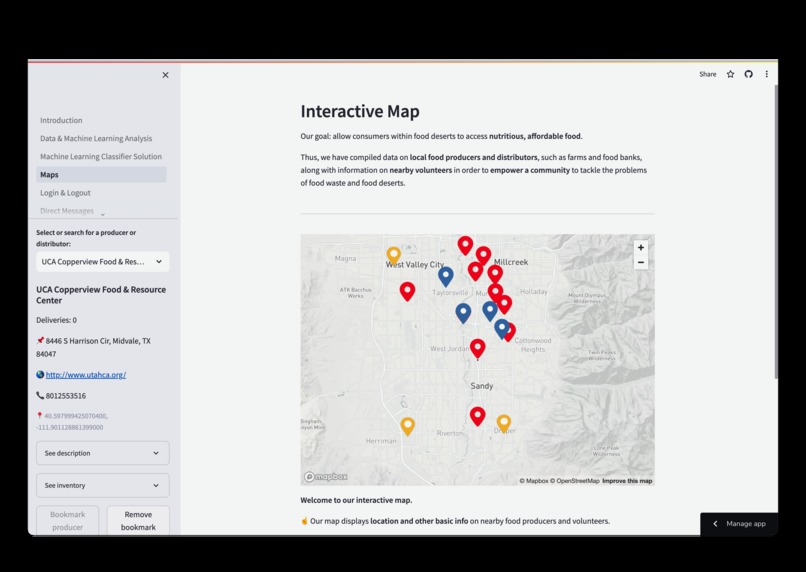
- Our approach is two-pronged. First, a machine learning model will be used to detect produce that is good, ugly (acceptable), or bad using image, color, shape, size, and texture data for individual produce items at producer locations (typically farms). Then, volunteers can see, on this web application, producers' locations and the number of batches of ugly produce that can be picked up and donated (whether it be a farm, factory, or store). The app will also show them nearby food banks delivering to food insecure people and/or those living in food deserts.
Our app 🖥
- Combines front-end elements in the form of the Streamlit web framework, along with back-end elements of Django, SQLite, and firebase that power the application.
- Utilizes PyTorch to collect image data and train a convolutional neural network to produce an accurate food classifier.
How we built it 🌱
- We built our solution by focusing on the product interface first, followed by our data analysis component. We began by first creating a basic Streamlit application with information and started looking into building communication systems and incorporating a powerful backend. Using the Firebase database and the Django framework, we created a reliable messaging system and effectively managed accounts. Along with Streamlit’s support for the pydeck library, we were also able to create an interactive map displaying producer/volunteer locations and information, fetched dynamically from the database.
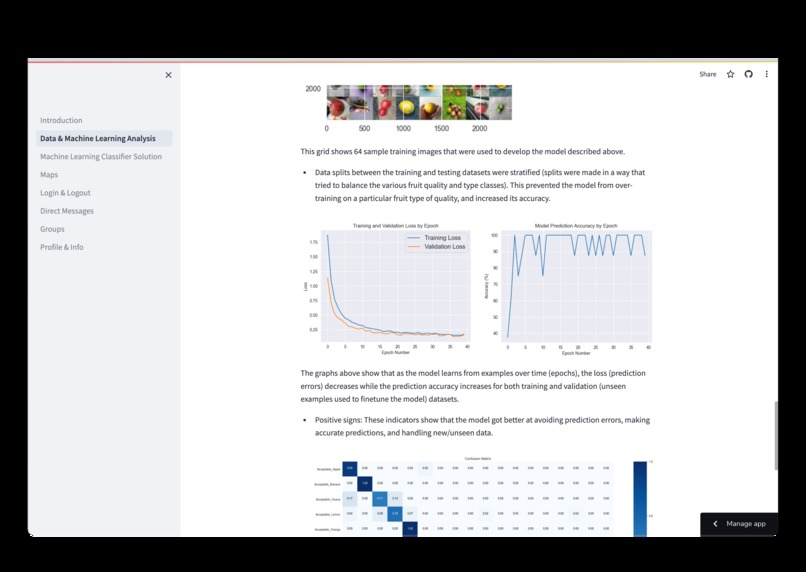
- Work on the machine learning model and the classifier solution also began with the acquisition of simple datasets and training and testing the model on them. Over time (and after doing significant background research) we found a larger dataset which we used to better train our model in predicting the condition of produce. Using Pytorch we were able to train a model that accurately classifies the state of food with 96% accuracy.
Challenges we ran into 🚧
- Meeting Deadlines: The first primary challenge that we had to face was that of meeting the two-week deadline in which we had to develop our product within.
- Maintaining Quality: In addition to this challenge of meeting deadlines, we also faced the challenge of ensuring that quality remained high throughout the entire project. For our complete application, we had to take various factors into consideration, such as performance, security, and usability.
- Novel Learning: Another significant challenge that we had to face was that we had to learn the ins and outs of many of the libraries and frameworks that we decided to use. We often found ourselves paging through documentation, testing sample code, and debugging errors online as we explored these new territories.
- Dataset: Another challenge involved finding a dataset to train the machine learning model. Many datasets were limited to only fresh or rotten fruit and lacked images that can help classify food that was not visually appealing, but still edible. Fortunately, after a prolonged search, we were able to find this data for 6 different types of fruit.
Accomplishments that we're proud of 🙌
- One great source of pride for us is the fact that we can declare ourselves to be full-stack developers! Our project took elements from multiple subfields of computer science, and combined them all into one, functioning web application. These included a dual-natured front-end and back-end system, two databases allowing for user authentication and messaging, as well as a machine-learning classification model.
- Another achievement we are proud of was that we had to remain consistent in a 2-week-long hackathon project. We never lost sight of the final product and remained ambitious while keeping the project deadlines in mind.
What we learned 📖
- First, we learned how to handle and work with back-end systems, such as with the Django framework and SQLite database. The nature of our project forced us to learn the properties of relational database systems and had us explore its management through Django’s system of models, migrations, URLs, and more. Additionally, the backend introduced us to many important concepts, such as security and password hashing.
- Working with database (firebase)
- With this backend knowledge, we then had to go on a journey as we explored the Streamlit frontend framework. It was during this section of the project that we had to shift our mindset from managing data to displaying data. This included design elements, formatting, and writing text with brevity.
- Turning to machine learning, we learned how to use various neural network components to build our own image classifier in Pytorch (with the model architecture shown in the deployed solution on the machine learning analysis page), which allowed us to make a solution for food producers to evaluate the quality of their produce accurately
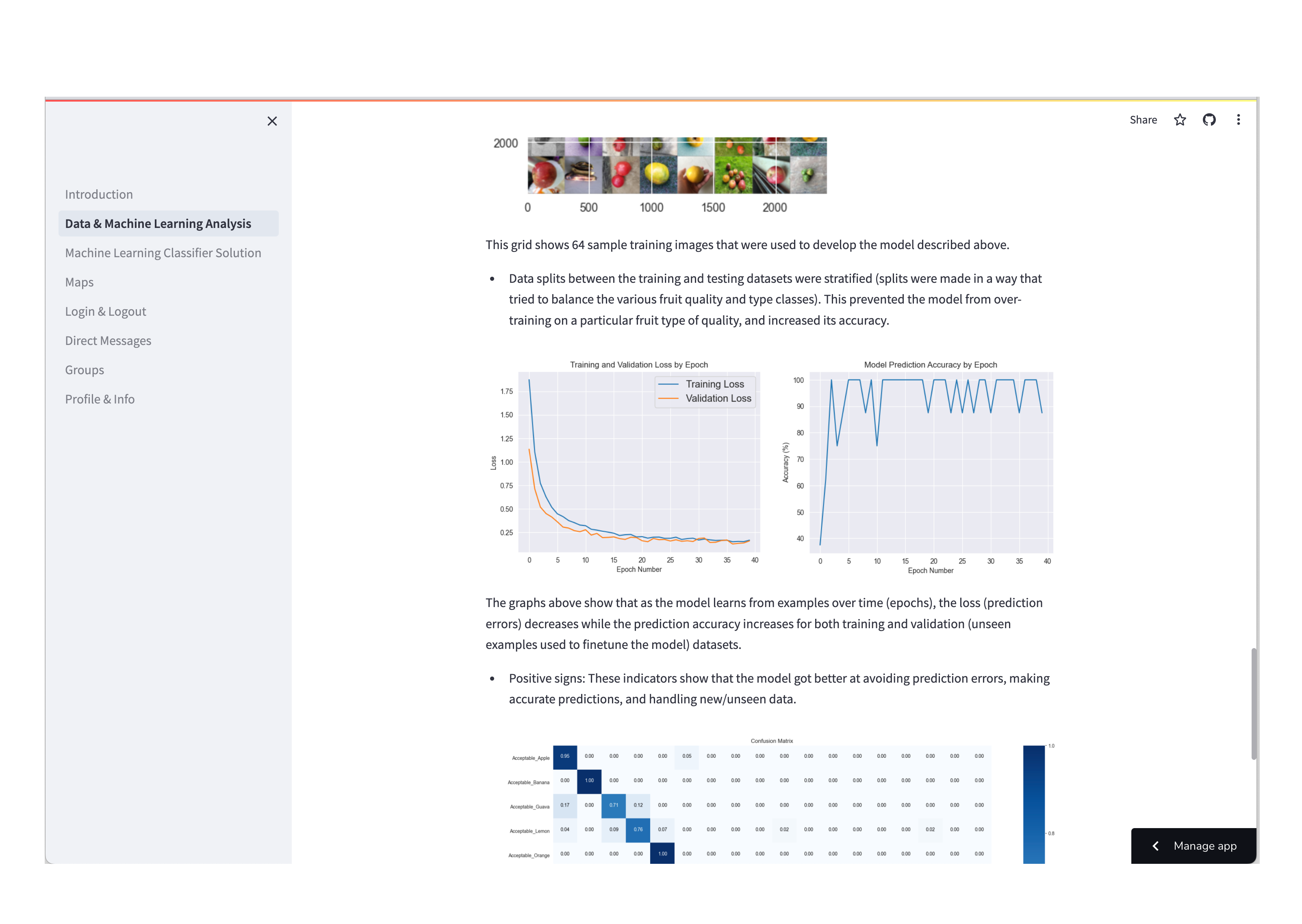
- We learned how to use a stratified selection of training, validation, and test data to deal with the overrepresentation of certain types of produce/fruit in the data
- Finally, we learned how to evaluate the performance of a neural network using confusion matrices (with this graph shown on the machine learning analysis page)
What's next for Food Finder 🔮
- Improve the scope and range of our database to include information across the state of Utah, then the United States, and then the entire world
- Improve the reliability of our direct/group messaging systems
- Upgrade our database from SQLite to MYSQL or PostgreSQL to better handle multiple users and grant different levels of permissions to users based on their account type (producer or volunteer)
- Investigate other hosting methods to give us greater control over the appearance of the frontend of the application
- Develop a mobile application and/or optimize the current web application to work on mobile devices (such as adding features to call producers directly from the webpage/mobile app)
- Change Neural Network architecture to improve produce classification accuracy (from its current ~96% to, ideally, ~99.5%), ensuring the reliability of predictions if a producer were to upload images of their produce for classification
- Get data for more types of produce, other than the current 6 (apples, bananas, guavas, lemons, oranges, and pomegranates





Log in or sign up for Devpost to join the conversation.