-
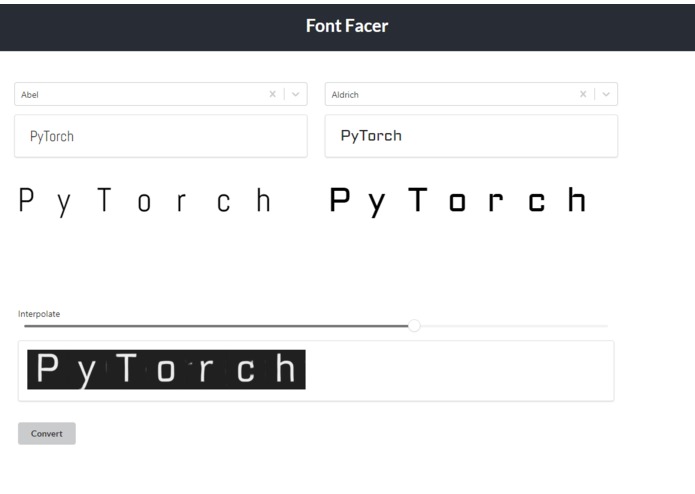
Demo
-

Interpolation: Serif-ness
-

Interpolation: Bold-ness
-

Interpolation between styles
-

Failure of the SVG generator




Motivation
Fonts are crucial in the workflow of typographers and graphic designers to make texts easily legible and aesthetically appealing. However, there are some major challenges to choosing, using, and designing fonts:
- There are millions of fonts available online. Even with font filters, it is often time-consuming to pick the font with the essence that the designer wants to achieve.
- Many popular fonts pose license issues for designers. Often, designers need to spend expensive fees to avoid legal issues.
- If no font with desired style and license is found, typographers need to design their own font. The process of crafting a font can be very time-consuming.
- Current image generation techniques focus on raster images. Generating vector fonts is a relatively under-explored area.
What it does
We aim to provide a toolkit for typographers to get the font right. We try to solve the above four challenges as follows in a "deep learning mindset":
- Hard to find existing fonts: nearest-neighbor retrieval in the latent space! Select two existing fonts, get the embedding of them, and you can retrieve an existing font with the taste of both.
- License issues: generate fonts with trouble-free data! We compiled a dataset of Google Fonts with the SIL Open Font License which "permits the fonts to be used, modified, and distributed freely" with ~2K fonts ~120K characters. We aim to learn a greater font manifold with the "base fonts" free of license issues.
- Font design is time-consuming: have fun searching for new fonts in the latent space! With latent vector arithmetics, you can achieve a style like "get a bold Times font using a normal Times font and the bold-ness of Bold Helvetica without the Helvetica-ness".
- Raster font images are not deployable: generate TTF vector files! With the generated raster image, you can train a model to trace the boundaries and obtain the vector font files (integration to the interface pending).
Font generation is a field with huge potentials. A deployable font generation toolkit can change the entire workflow of a typographer and therefore reshape the design industry.
How we built it
We build all our models in PyTorch.
- Font retrieval model: we used the pre-trained model provided by [FIXME: add link] to retrieve fonts in the Google Fonts dataset.
- Raster font generation: 1) Variational Autoencoder: we implemented our own autoencoder to learn the latent space of different characters and fonts. 2) StarGAN: we modified the code of [FIXME: add link] to manipulate different attributes of a character, such as bold-ness and serif-ness.
- Vector font generation: we tried to reproduce the model proposed by A Learned Representation for Scalable Vector Graphics, implementing it from scratch. We first train a variational autoencoder on raster images and use gated recurrent units and a mixture density network to generate SVG commands and obtain vector font files.
Challenges we ran into
- Attributes of a character can be hard to learn. For example, we tried to learn the serif-ness of a character with StarGAN, but it does not produce comparable results with simple latent space interpolation with VAE.
- The representation of a vector file is vastly different from that of an image. Even if we could get a correct base VAE model to generate raster images, the recurrent units to produce command tokens and numbers are hard to train and we could not get a reasonable result.
- Hooking up the back-end models with the front-end UI needs a lot of communication and engineering.
Accomplishments that we're proud of
- Font retrieval model
- Compiling the Google Fonts dataset
- Interpolation between two fonts
- Manipulating the attributes of a font
- Generating SVG fonts
What we learned
In addition to providing a toolkit, this project provides a method overview for the task of Font Generation. We have a few observations during the development:
- Start from simple fonts. We observe that simple fonts such as sans serif are easier to generate and manipulate than highly stylized ones such as handwriting. However, in the typography market, these simple fonts are on the highest demand. Therefore instead of focusing on generating fonts with crazy styles, we can work on producing production-grade simple fonts that improve readability.
- Data is crucial. A utopian vision is to learn the font manifold and produce open-source industrial-grade fonts to everyone. However, to learn this model, it is always good to get more data, especially for the highly stylized fonts. With more typographers contributing to open-source fonts, we can achieve this goal earlier.
- Vector paths is a visual representation worth looking into. This is not only important for the task for Font Generation, but for a resolution-independent representation for computer vision in general, such as image segmentation, data annotation, and art creation.
What's next for Font Generation
- A better interface and clear functionalities. To make the interface friendly to the general public, we need to restructure the UI and list the functionalities more clearly.
- Get more data. Currently, we have the entire dataset of Google Fonts, but we need to get more data with valid licenses.
- Investigate the representation of vector paths. The existing work uses simple VAE and sequence models to generate characters in a one-pass manner. We have ideas of extending the work to a multi-stage refining process of the paths with a global context, a potential topic that can turn into a research paper.










Log in or sign up for Devpost to join the conversation.