
Inspiration
Healthcare systems are never centralised, structured and equally accessible to people in South Asia including India, Pakistan, Bangladesh and nearby countries. Patients need to gather years of diagnostic records from multiple hospitals and laboratories. These reports are present in paper-based or PDF versions that don’t represent consistent statistics of their medical history. Therefore, maintaining accurate healthcare data is not manually possible.
On the other hand, healthcare systems are majorly family-based, which means one individual often has to take care of his/her parents, spouse, children and extended family members. Due to this reason, families face difficulties in tracking the health records of each member over the years. This causes overlooked medical history, negligence of warning signs or growing symptoms, and, in some cases, a mental burden to the responsible person.
There are a lot of health management tools, but they lack full functionality for a multi-patient family. Sometimes, these tools are not designed for low-resource and decentralised healthcare ecosystems.
What it does
Medista is an AI-powered healthcare tool that organises health insights and medical history of patients by extracting information from diagnostic reports and structuring actionable data. Some of the most important features include:
1. Smart Report Ingestion When users upload diagnostic reports in the form of PDF, the vision-language model will read and interpret the information in the reports. The major information that would be translated includes:
- Test Names
- Values/Readings
- Units
- Dates
2. Structured Health Record (FHIR-Ready) It is one of the important features of Medista to accumulate records in standardized format. It converts data which is compatible with FHIR. The FHIR-ready data ensures future clinical integration.
3. Family-Friendly Health Management It is a centralised agent for the entire family, including multiple patient profiles. It features a dedicated dashboard for caretakers, providing a simple interface to track medical records of parents, children and other dependents.
4. AI-Powered Insights
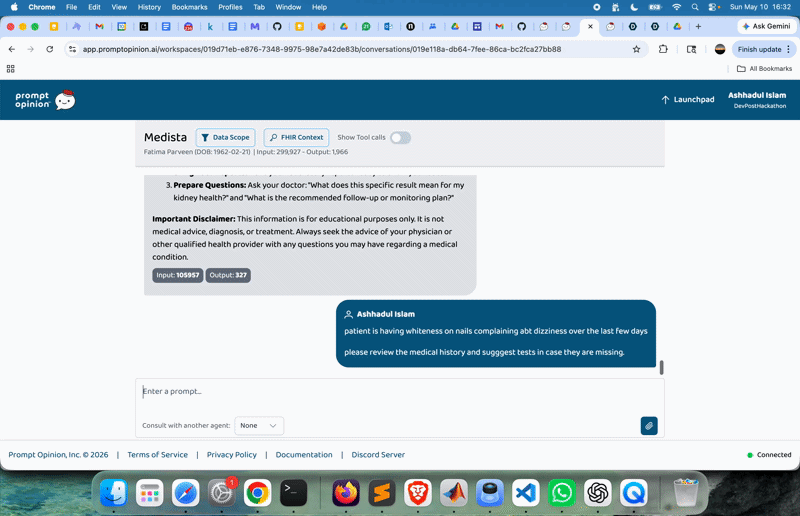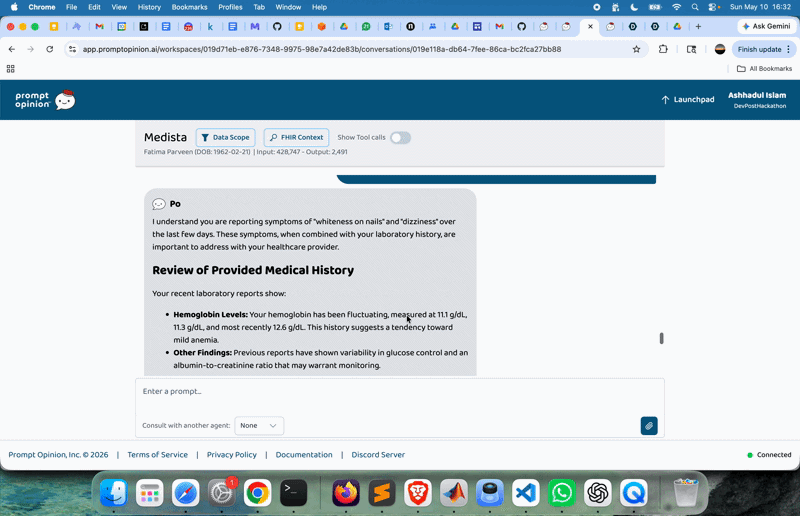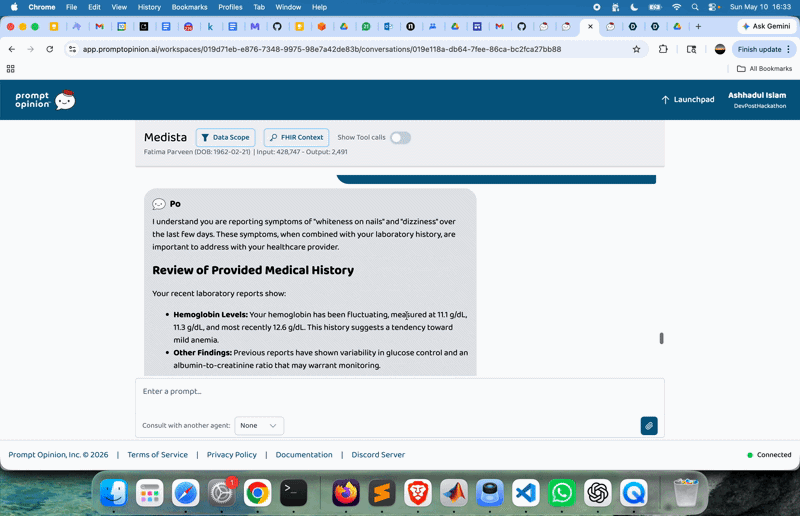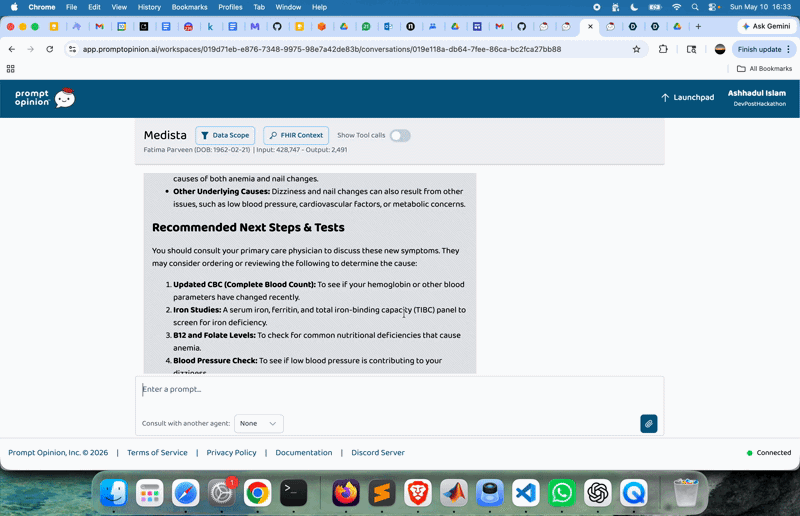
It provides long-term health tracking statistics showing trends in patients’ physiology. What makes this feature more useful is timely updates and risk alerts for abnormal values. The agentic AI understands natural language, so the user can ask questions in simple human language. For example:
“Is my mother’s glucose improving?”
“Show haemoglobin trend over 6 months”
| Feature | Description |
|---|---|
| AI-Powered Report Ingestion | Gemini 2.5 Flash Lite extracts test names, values, units, dates, and patient details from inconsistent real-world PDFs and images, regardless of format or layout. |
| Dedicated Healthcare MCP Layer | Extends Prompt Opinion’s MCP architecture with a specialized layer for medical report ingestion, AI extraction, and longitudinal health tracking. |
| FHIR Data Normalization | Raw extracted data is normalized into a FHIR-compatible format, ensuring consistency regardless of report source or layout. |
| Longitudinal Health Tracking | Stores and queries medical data across multiple reports over time, enabling historical health monitoring. |
| Natural Language Health Queries | Users can ask questions like “Is my mother’s glucose improving?” and receive structured answers with full chronological context preserved. |
| Cost-Efficient Query Architecture | Patient data is served through deterministic PostgreSQL queries via Supabase, eliminating repeated LLM processing and significantly reducing inference costs. |
| Multi-Patient Family Management | Caretakers can manage health records for multiple family members — parents, children, and dependents — from a single workspace. |
| Abnormal Value Detection | Automatically identifies and flags out-of-range test results across reports to surface early warning signals. |
| Interactive Health Progression Dashboard | Visual trend charts allow caretakers to track specific health parameters over time, across reports and patients. |
How we built it
Architecture
Medista is built as an A2A healthcare agent on top of PromptOpinion’s MCP framework, with an added Medista layer for report ingestion, medical data extraction, structured storage and longitudinal health tracking.
Workflow
Upload Report → AI Extraction → FHIR Structuring → Database → AI Agent → Insights
When users upload medical reports (PDFs or images), a vision-language model (Gemini 2.5 Flash Lite) extracts relevant medical information such as test names, values, units, timestamps and patient details. Since diagnostic reports vary drastically across hospitals and laboratories, we built a normalization layer to standardize test names and outputs into a consistent schema for reliable querying and trend analysis.
The extracted information is stored in a FHIR-compatible structure, allowing Medista to maintain patient context, timestamps, observations and diagnostic history in a standardized healthcare format. Data is securely stored and reconciled into structured records that support future interoperability with clinical systems.
For conversational interaction, we integrated PromptOpinion’s MCP tool architecture. Instead of repeatedly parsing reports, MCP tools fetch already-structured patient data from the database and return clean JSON summaries to the LLM, making interactions faster, cheaper and more reliable.
We also use a healthcare-focused instruction layer that guides the conversational agent to automatically retrieve relevant patient summaries, preserve patient context and answer medical-history questions naturally.
Models Used
- Gemini 2.5 Flash Lite → medical report extraction from PDFs/images
- Gemini 3.1 Flash Lite Preview → conversational health assistant inside PromptOpinion
- Supabase + PostgreSQL → structured FHIR-compatible medical record storage
Challenges we ran into
One of our earliest challenges was deciding where medical report ingestion should happen. We initially experimented with integrating uploads directly into PromptOpinion, but quickly realized that separating report extraction from conversational interaction made the system more modular, scalable and reliable.
Another major challenge was entity reconciliation. Diagnostic reports vary drastically across hospitals and labs — the same patient could appear as “Mrs. Fatima Parveen” in one report and “Fatima Parveen” in another, while the same medical test could be labeled differently across providers (“FBS”, “Glucose Fasting”, “Blood Sugar”). The harder problem wasn’t model non-determinism, but building a robust normalization layer to standardize patient identities and medical entities.
To address this, we built a lightweight human-in-the-loop reconciliation layer for resolving patient names and canonical test mappings whenever ambiguity appears.
Accomplishments that we're proud of
Database reconciliation
Example of patient name reconciliation. Similar interface exists for test name recon.
Example of test name reconciliation. m.c.h.c is reconciled with mchc. The test report is also made available through a hyperlink as a ground truth
Patient Discovery: Finding hidden signals in patients
Some Samples
Discovering and suggesting diagnostic tests that are absent in the reports
What we learned
Healthcare data is messy by default
The biggest challenge was not OCR or LLM extraction — it was reconciling inconsistent patient names, test labels and report formats across hospitals and laboratories.Structured data beats repeated LLM calls
Converting extracted reports into a normalized, FHIR-compatible schema made querying faster, cheaper and more reliable than re-processing documents every time.AI works best with human oversight in healthcare
Fully automated extraction is powerful, but lightweight human-in-the-loop reconciliation significantly improves trust, accuracy and long-term usability.
What's next for Medista
Over the next six months, we aim to transition from early validation to a functional, user-tested product with initial market traction. We will begin by validating the problem through structured interviews with 50–100 users across India, Pakistan, and Bangladesh, refining our core features based on real user needs. In parallel, we will develop our MVP by stabilizing the AI pipeline for report extraction, building the health dashboard, and ensuring secure, FHIR-aligned data storage. We will then launch a closed beta with early users, focusing on families managing multiple health records, to test usability, accuracy, and overall product value. Based on feedback, we will iterate on model performance, enhance caretaker workflows, and introduce doctor-facing summaries. In the final phase, we will expand to 50–200 users through targeted communities, identify early adopters, and explore partnerships with clinics and diagnostic labs. We will also begin defining our monetization strategy and prepare for a public launch and early-stage fundraising.
Built With
- amazon-web-services
- mcp
- nosql
- promptopinion
- python

Log in or sign up for Devpost to join the conversation.