-
-
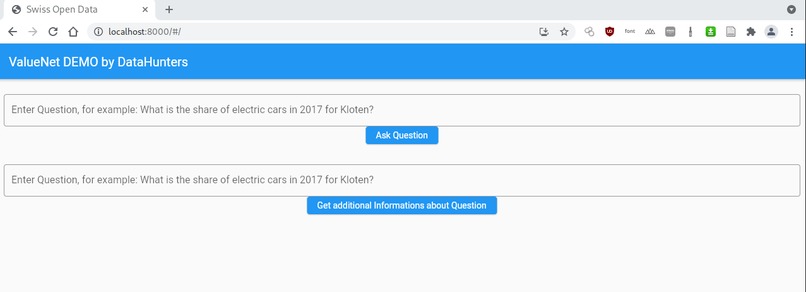
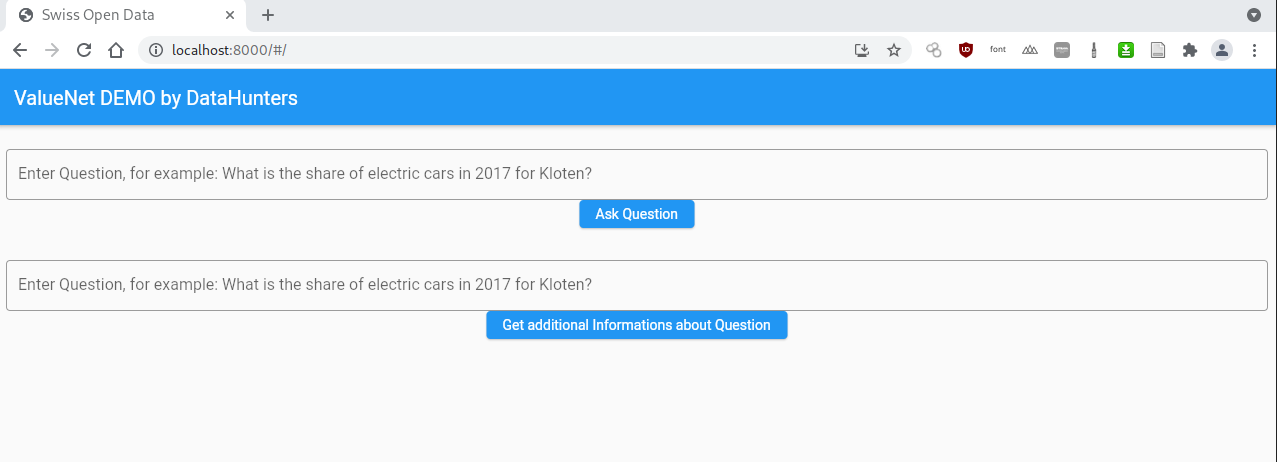
Interface of our prototype
Inspiration
In the current day and age, nothing spreads faster than a wrong (or even purposefully fake) statistic on social media. Most of the time, the data to verify or disprove some claims is readily available, but the amount of effort and technical knowledge required to do this can be overwhelming. Even when the technical expertise is there, finding the correct dataset can be challenging. The Open Data platform opendata.swiss currently features 6'264 datasets, each with different formats and amounts of completeness.
Our solution
Using the ValueNet natural language to SQL model allows us to match complex questions in natural language to a corresponding query which can be applied to a database. Voice recognition powered by Google Assistant allows us also to interpret vocal questions into text queries which then can be used by the ValueNet model. We experimented with suggestion broader queries related to the question posed by an user to try and provide context to the data. For example, if an user asks about the share of electric vehicles in a certain commune in a certain year, we also list this datapoint for different years, providing an user with more references the single answer can be compared against.
You'll find our code here
Technologies Used
INODE/ ZHAW ValueNet
The ValueNet natural language to SQL machine learning model allows us to translate queries and questions like a human asks them into a format databases can work on. This is is the basis which allows us to enable people without any knowledge of databases or programming to access the data they are interested in or rely on.
PostgreSQL
DB instance was deployed on the Azure Cloud Access for the Backend and supportive scripts for data conversion
Flutter
- Support for Android, iOS and Web
- Integration with Google Assistant for people with visual disabilities
Flask
Plumbs Frontend + Backends together
Infrastructure
- Docker
- Github
- Visual Studio Code
Challenges we faced
Since none of us really had any experience with the provided environment (especially ValueNet) and only had a small time frame, we faced several challenges. We would like to mention the biggest ones here.
Overwhelming amounts of heterogeneous data
opendata.swiss consists of a huge collection of heterogeneous data. There are csv, xlsx, pdf and json files for example which made it rather hard to create a generic way of either visualizing or exporting the data into a generally usable format, in our case into SQL to be put into a DB.
Obtaining a cloud GPU on a short notice
First, we tried to deploy ValueNet on Azure. This, simply because azure offered a container environment with GPU support, which is needed by ValueNet. In the ValueNet GitHub repository, there is a docker-compose file which will set up directly all needed components:
- PostgresDB with the sample datasets provided by FOITT for Hack Zürich
- Adminer
- ValueNet with a pretrained model for the Hack Zürich dataset
Thus, the idea was to use docker-compose directly in the Azure cloud. This was not directly possible due to the fact that there is no (compatible) option in docker-compose to request gpus resources. Therefore, the ValueNet would not have GPU access and thus will not work. We translated the docker-compose file into a Azure CLI compatible yaml file which should (in theory) set up the similar environment as docker-compose would had. Afterwards, we recognized that on Azure we only have access NVIDIA Tesla K80 GPUs which were not supported anymore by the used nvidia-pytorch docker image used by ValueNet. We could have downgraded the version but since the last supported version was more than two years old, we decided against this because the we would surely run into conflicts.
As a next provider IBM cloud came into our mind. There, the upgrade from the free to the pay-as-you-go account failed (for several team members) and thus, we could not collect our free 200$ credits which we would needed in order to create a VM with GPU capabilities.
Deploying on AWS was not usable as well because they do not offer free tier instances with GPU support.
At Google Cloud we also had no luck since there, we could redeem our free credits but the quotas did not allow us to run any instance with GPU support.
With help from the FOITT team, we tried Google Colab. In the end we brought ValueNet up (at least according to the output from the notebook). But testing was rather impossible since Google Colab instances are running behind a NAT. After several ours of debugging and hacking a way around the NAT (Reverse socket via ngrok etc. etc.), we gave up trying deploying our own ValueNet instance.
Organizing a hybrid remote team
Only one member of our team was on-site the rest of us were sitting at home. We organized ourselves in a way that we used Slack but as well were connected via a separate voice call (almost the whole week-end). Of course for the person on-site, the team work experience was quite the same as if he would simply be at home too. One of the main problem is clearly that you cannot simply go to a teammates desk and either show or ask him something but in the end, we have to say that the team worked very well even if we were not sitting in the same room.
Built With
- azure
- dart
- flask
- flutter
- google-colab
- postgresql
- python
- valuenet






Log in or sign up for Devpost to join the conversation.