-
-

When Tama looks at your screen, it's not an animation — it's a real-time request to an LLM analyzing what you're doing.
-

Tama never blocks your workflow — she teleports away the moment your cursor gets close.
-
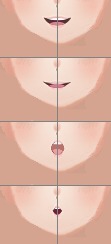
Tama leverages real-time audio chunk from the Google STS model to trigger mouth movements synchronized with the nature of each segment
-

When Gemini triggers it, the 'kill distraction' command is issued, and Tama and her flying object react accordingly! BAM ! back to work !



FocusPals: The Intelligent Productivity Guardian
Inspiration
I've always been a heavy user of Pomodoro apps and site blockers, but like many of us, I'm a victim of my own tendency to get distracted. I realized that traditional site blockers are often ineffective because they're too binary, they can't distinguish context. For instance, is YouTube being used for a work-related tutorial or a procrastination rabbit hole?
I wanted to build an intelligent blocker that understands the why behind the window. Today, only Google's generative technologies provide the reliable and cost-effective infrastructure needed to realize a project like this. I decided to leverage my skills in 3D and animation to create a character that makes staying focused feel personal and engaging.
What it does
FocusPals features a 3D desktop companion named Tama that monitors your activity in real-time.
- Contextual Vision : When Tama looks at your screen, it's not an animation, it's a real-time request to an LLM analyzing what you're doing.
- Behavioral Enforcement : If you stray, Tama's suspicion rises, leading to verbal warnings or a physical "strike" where she closes the distracting tab.
- Smart Pomodoro : Handles sessions with intelligent break suggestions based on your actual focus.
- She can help with any task : Like any LLM, you can talk to her and she'll assist you with anything, except this time, she constantly sees what you're working on.
- Non-Intrusive : Tama never blocks your workflow, she teleports away the moment your cursor gets close.
How I built it
Architecture: Brain — Body — Soul
| Layer | Technology | Role |
|---|---|---|
| Body | Godot 4.4 | Transparent 3D overlay with animations and real-time gaze tracking |
| Brain | Python (async) | A.S.C. (Alignment–Suspicion–Control) behavioral engine |
| Soul | Gemini Live API v1alpha |
Native speech-to-speech and vision capabilities |
The Google Services Powering Tama
FocusPals relies on multiple Google Generative AI and Cloud services working together:
Gemini Live API — Native Speech-to-Speech
Tama's personality isn't scripted text-to-speech : it's native audio generation from the Gemini model. The system prompt acts as "Director's Notes," describing vocal style, pacing, and emotional dynamics. The model then performs them organically: her voice rises when she's teasing, drops with a sigh when she's disappointed, and sharpens when she's angry.
Affective Dialog : enable_affective_dialog=True gives Tama genuine emotional expressiveness. She doesn't just say she's annoyed : you hear it in her tone, her pacing, her sighs.
Proactive Audio : proactive_audio=True allows Tama to speak first. She doesn't wait for you to talk, she reacts to what she sees on your screen, drops sarcastic comments, or cheers you on. Like a real coach sitting next to you.
Session Resumption : When the connection drops (network, API timeout), Tama reconnects seamlessly with session_resumption, preserving the full conversation context. The user never notices, it's a stealth reconnect.
Context Window Compression : Sessions can last hours. sliding_window compression prevents token limits from cutting the conversation short.
Voice Activity Detection (VAD) : Automatic speech detection triggers events in the pipeline. Custom sensitivity tuning prevents false triggers from keyboard sounds while still catching whispered voice commands.
Input/Output Audio Transcription : Real-time bidirectional transcription powers the debug console and activity logging, giving full visibility into what was said and heard.
Gemini Function Calling : 6 Custom Tools
Tama doesn't just talk, she acts on the real world through 6 custom tools:
report_mood: Fires every response to sync her 3D facial expressionsfire_strike: Verbal synchronization ("BAM!" triggers the drone animation to destroy a distraction)close_distracting_tab: OS-level window and tab closure via UIAlook_at_screen: On-demand focused vision (one-shot screenshot to Live API)set_current_task: User declares their goal ("coding", "making music")app_control: Desktop automation: open apps, send shortcuts, type text, control volume, search the web
Gemini 3.1 Flash-Lite : The Separate Eyes AI
Constant screen monitoring can't go through the Live API WebSocket, sending screenshots every 3–12 seconds alongside audio and tool calls would overload the speech-to-speech connection and cause crashes. So a second, dedicated AI (gemini-3.1-flash-lite) handles all visual classification via standard REST API calls, completely isolated from the WebSocket. I call this the Split Brain architecture: the Live API only handles voice, tools, and text, it never receives a single automatic image. Meanwhile, Flash-Lite captures screenshots, classifies them (work / distraction / ambiguous), generates rich descriptions like "YouTube: Python tutorial", auto-infers the user's task after 2 minutes, and produces session summaries at the end.
Flash-Lite's classifications are then injected as compact text hints ([EYES] SANTE A:1.0 — Cursor IDE, Python code) into the voice session. It works like a human: peripheral vision notices "he's on YouTube," and only when Tama needs to actually read what's on screen does she use look_at_screen to send a single one-shot image through the Live API.
Google Cloud Firestore — Analytics & Memory
Strike events, session starts/ends, and productivity pulses are logged to Firestore in a privacy-first, edge-to-cloud architecture. All AI processing stays local; only telemetry reaches the cloud. Writes are fire-and-forget in background threads, cloud sync never blocks the local experience.
The A.S.C. Engine
Alignment: increases if what you do is related to your task (e.g., listening to music when your task is making music = high alignment, Tama stays chill). Suspicion: increases when you do something apparently non-productive. Confidence: decreases when you are constantly distracted, making Tama less forgiving.
$$\Delta S_{increase} = \Delta S_{base} \times (1 + (1 - C))$$
$$\Delta S_{decrease} = \Delta S_{base} \times C$$
Lower confidence makes suspicion rise up to 1.9× faster and decay up to 10× slower.
Context Steering — The Art of Guiding a Live LLM
One of the biggest technical challenges is that Gemini Live API is a continuous live conversation, you can't re-send the system prompt every 10 seconds. Instead, carefully crafted [SYSTEM] text pulses are injected at regular intervals to steer the model organically:
[SYSTEM] 14:32 23/50m(46%) | focus:12m S_trend:↓ active | win:VS Code |
S:1.2 A:1.0 | You're in a good mood. He's working well. You trust him.
[SELF] Reading. [EYES] SANTE A:1.0 — Cursor IDE, Python code visible.
MUZZLED
Each pulse blends situational context (what window, how long, suspicion level), emotional state (mood engine natural language, never raw numbers), identity cues ([SELF] Reading makes Tama aware she's sitting at her wall reading), and a speaking directive (MUZZLED / CURIOUS / ALERT / UNMUZZLED / STRIKE). The model interprets all of this organically, she decides her own tone, intensity, and whether something is worth commenting on. It's not scripted, it's directed.
Additional layers:
- Intelligent muzzling: Tama stays silent during deep work (S < 3.0), only speaks when something is actually wrong.
- Spontaneity windows: When aligned, she still has a 20–30% chance to drop a "tsundere" comment after 10+ minutes of silence, keeping the personality alive.
- Speech gating: Pulses are suppressed while the user is speaking, preventing text context from competing with the audio pipeline.
Challenges I ran into
- WebSocket stability: Sending screenshots through the Gemini Live API WebSocket alongside audio caused server-side 1011 crashes. The Split Brain architecture (dedicated Flash-Lite for vision) solved this entirely.
- Tool call ordering: Gemini may emit
fire_strikebeforeclose_distracting_tabidentifies the target, causing a "Ghost Hand" animation on empty coordinates. Request-flagging ensures animation only starts when the target is confirmed. - Audio corruption: Virtual audio drivers ("Stereo Mix", "Loopback") sent corrupted PCM data. Real-time sanitization (clipping, stuck patterns, fragment detection) was required on every chunk.
- Deferred tool responses: Sending a
tool_responsewhile Gemini is still speaking causes duplicate audio. Responses are buffered and sent only afterturn_complete.
Accomplishments that I'm proud of
- Context-aware blocking : Flash-Lite classifies "YouTube: Python tutorial" = GOOD vs "YouTube: cat memes" = BANNED, genuine situational understanding, not keyword blocking.
- Organic context steering : Millisecond-precise
[SYSTEM]pulse injection blends mood, identity, vision, and behavior into natural language. The LLM is directed, not scripted, and it feels alive. - Real-time lip sync : Spectral analysis (FFT) on Gemini's native audio output classifies each PCM chunk into visemes (REST, OH, AH, EE_TEETH) in under 0.1ms, no ML model, just numpy.
- Long-term memory : Tama remembers your name, your projects, your records across sessions. A calendar heatmap and achievement system give tangible progress feedback.
- Organic emotional system : A mood engine driven by real factors (compliance streaks, time of day, session duration, micro-chaos oscillation), Gemini never sees numbers, only natural language like "You don't trust him, he's been switching back and forth."
What I learned
- How to manage low-latency communication between a game engine and an AI backend via local WebSockets.
- The communication between AI tools and APIs is never perfect; you need to find tricks to make problems invisible, stealth reconnections, session resumption handles, circuit breakers maintain the illusion.
- Techniques for multi-monitor screen capture and real-time image analysis.
- How to use AI for real-time situational classification rather than simple keyword blocking.
- The art of context steering: guiding a live LLM through carefully timed text injections, never overriding it, directing its personality like a film director guides an actor.
What's next for FocusPals
- Distractions aren't confined to your computer, they're mostly on your phone. By leveraging Google Cloud, FocusPals could stay in sync across all your devices, effectively tackling distractions wherever they appear.
- Full Jarvis mode : Tama already has an
app_controltool capable of opening apps, sending shortcuts, typing text, controlling volume, and searching the web. The next step is full desktop automation. A 3D avatar makes AI agent actions visible and readable to the user, instead of a silent process manipulating your OS (which looks like a virus), you see Tama pointing at the window, reaching toward the button. It makes agentic AI transparent and human-friendly. - Expanded personality system with adaptive behavioral profiles.
- Support for team accountability, multiple users with shared focus sessions.
- FocusPal*s* is plural, Tama has a very sarcastic personality that might not suit everyone. Pals with various personalities (gentle, strict, playful) would let users pick their ideal coach.


Log in or sign up for Devpost to join the conversation.