-
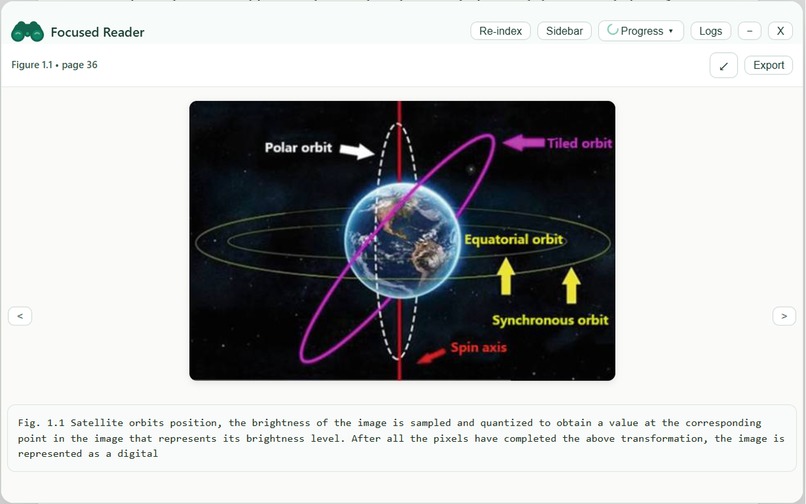
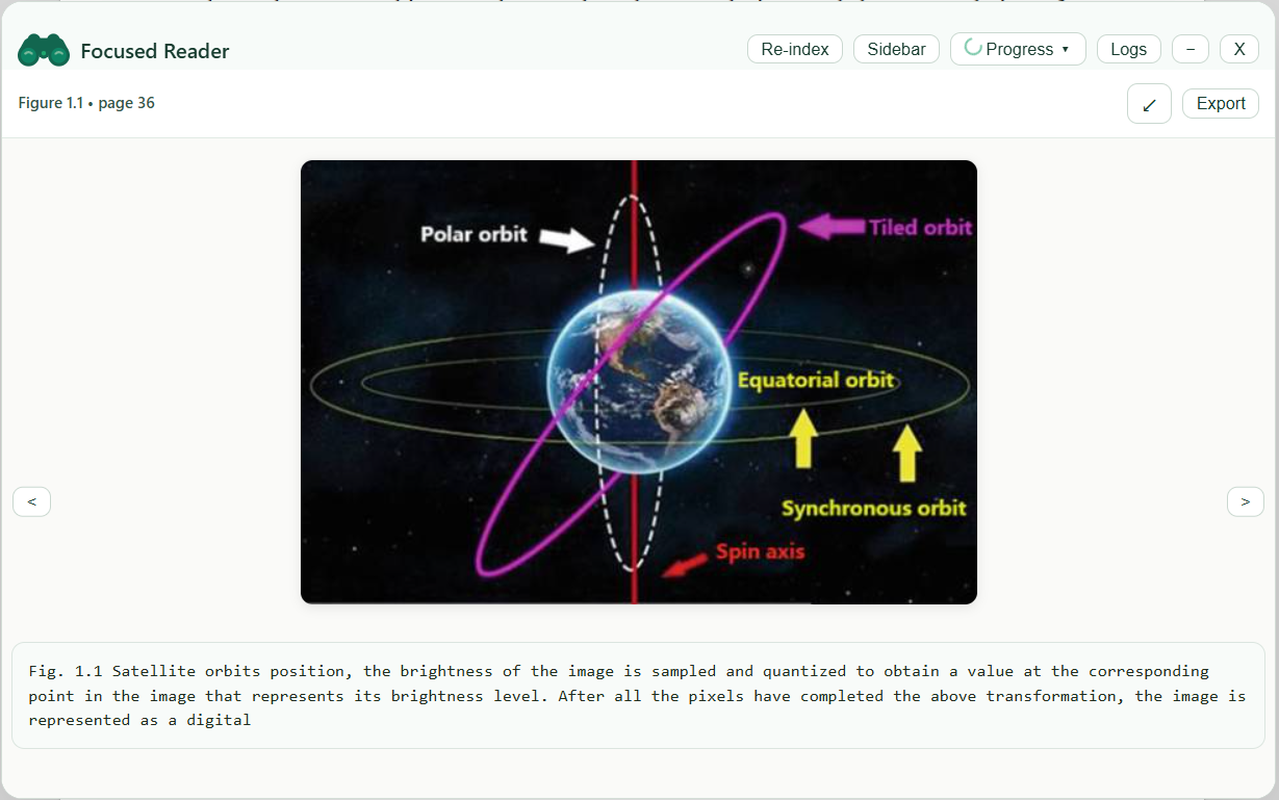
Figure and Caption from the pdf extracted and displayed
-
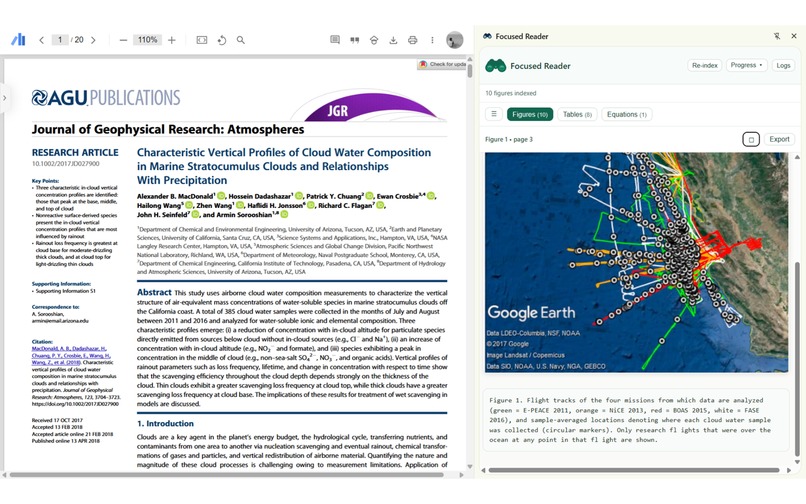
Side bar view of Focused Reader
-
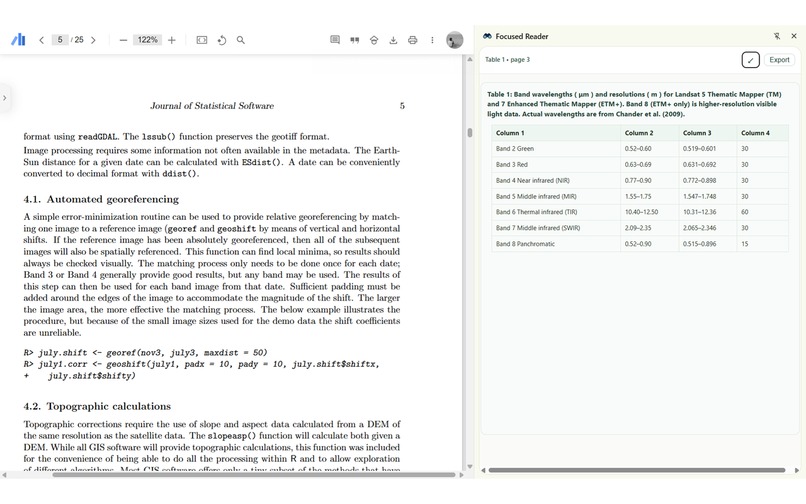
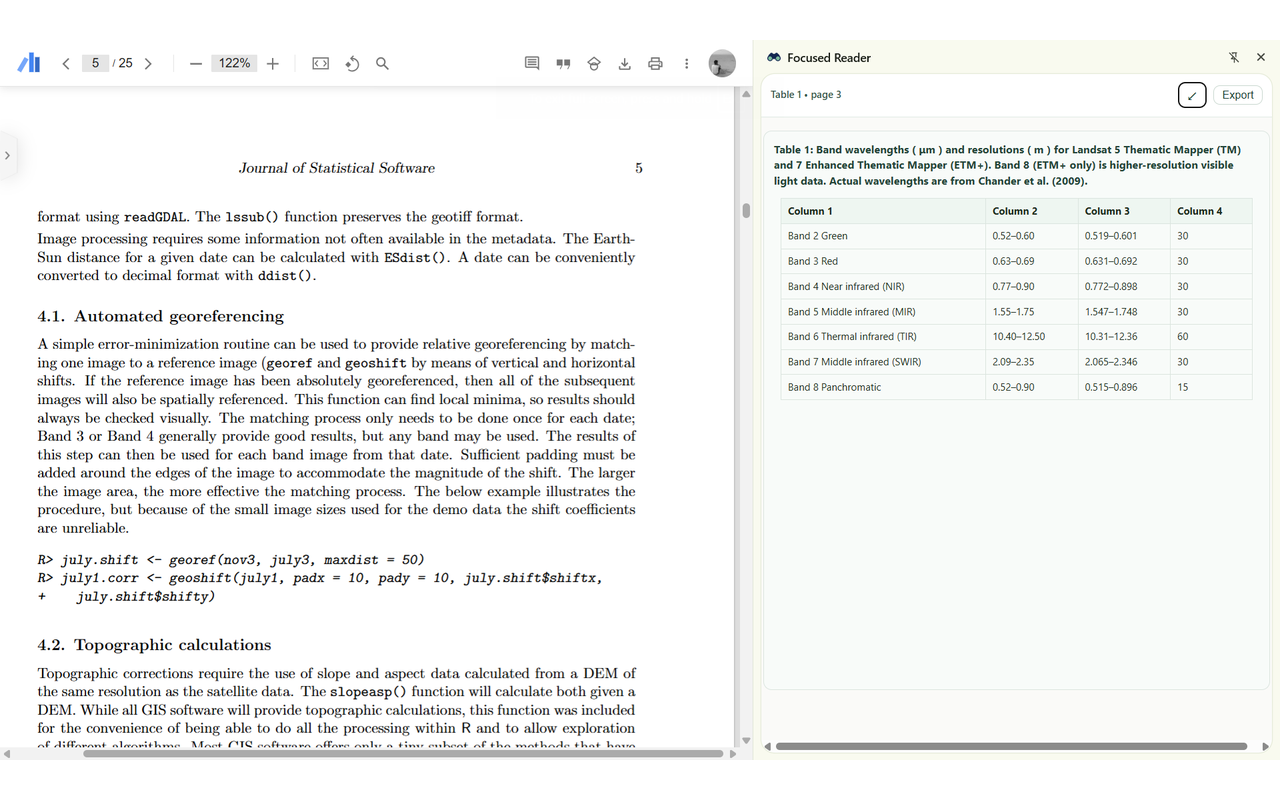
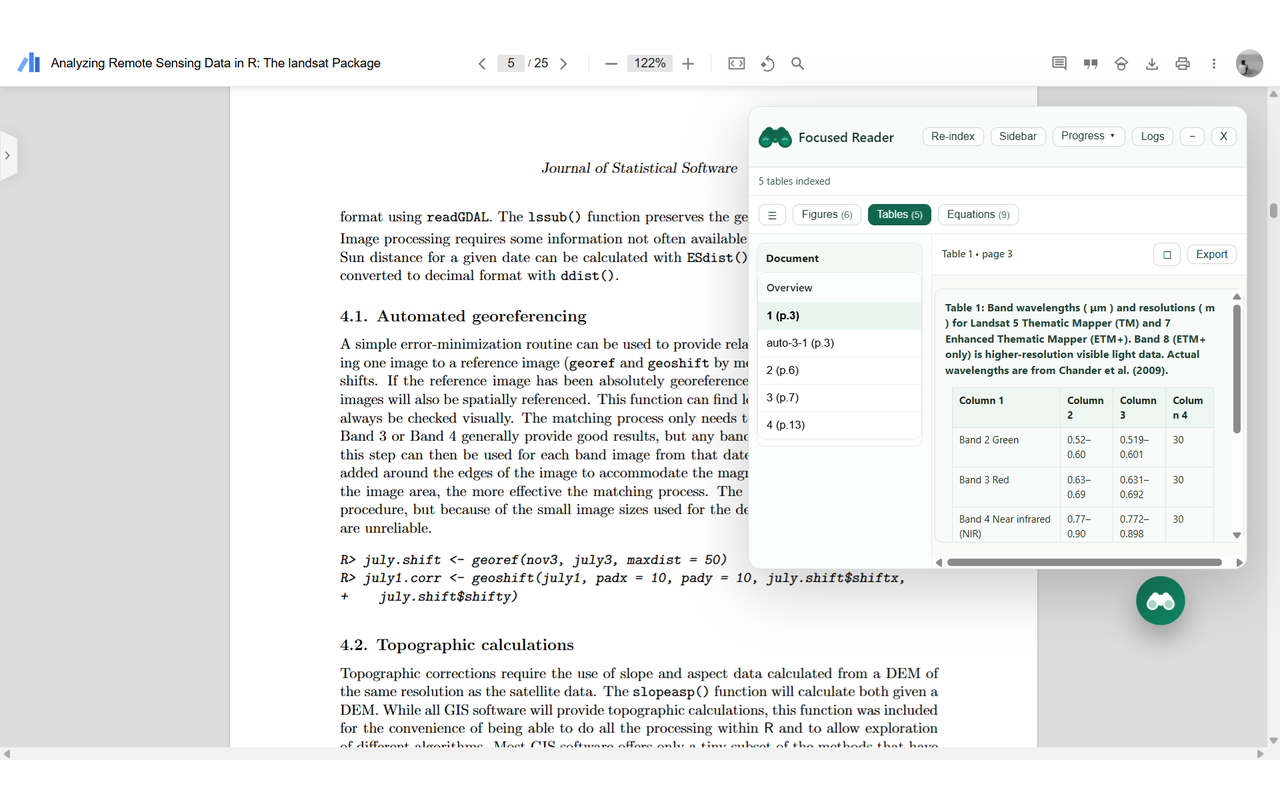
Displaying the table extracted from the PDF in the Sidebar view
-
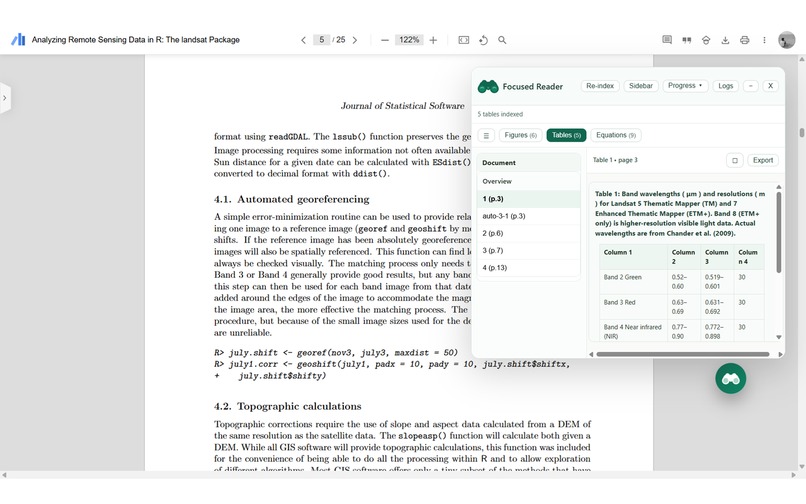
Display of Focused Reader in Float mode as a Modal (Resiz, Minimize, Dragging)
-
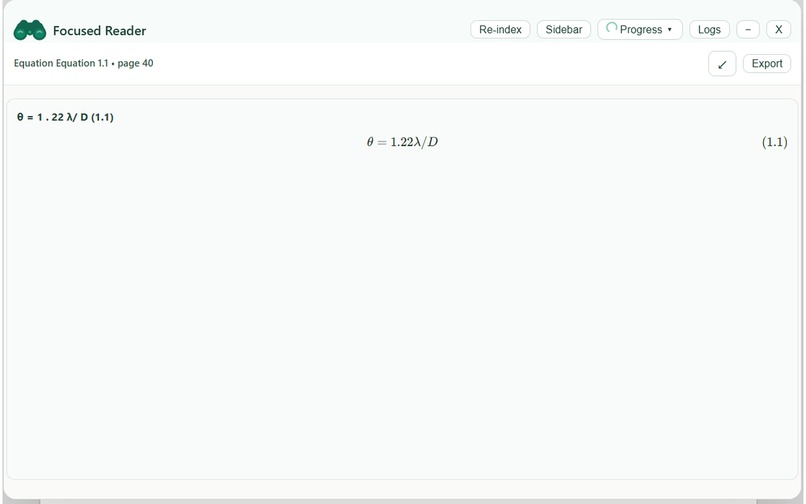
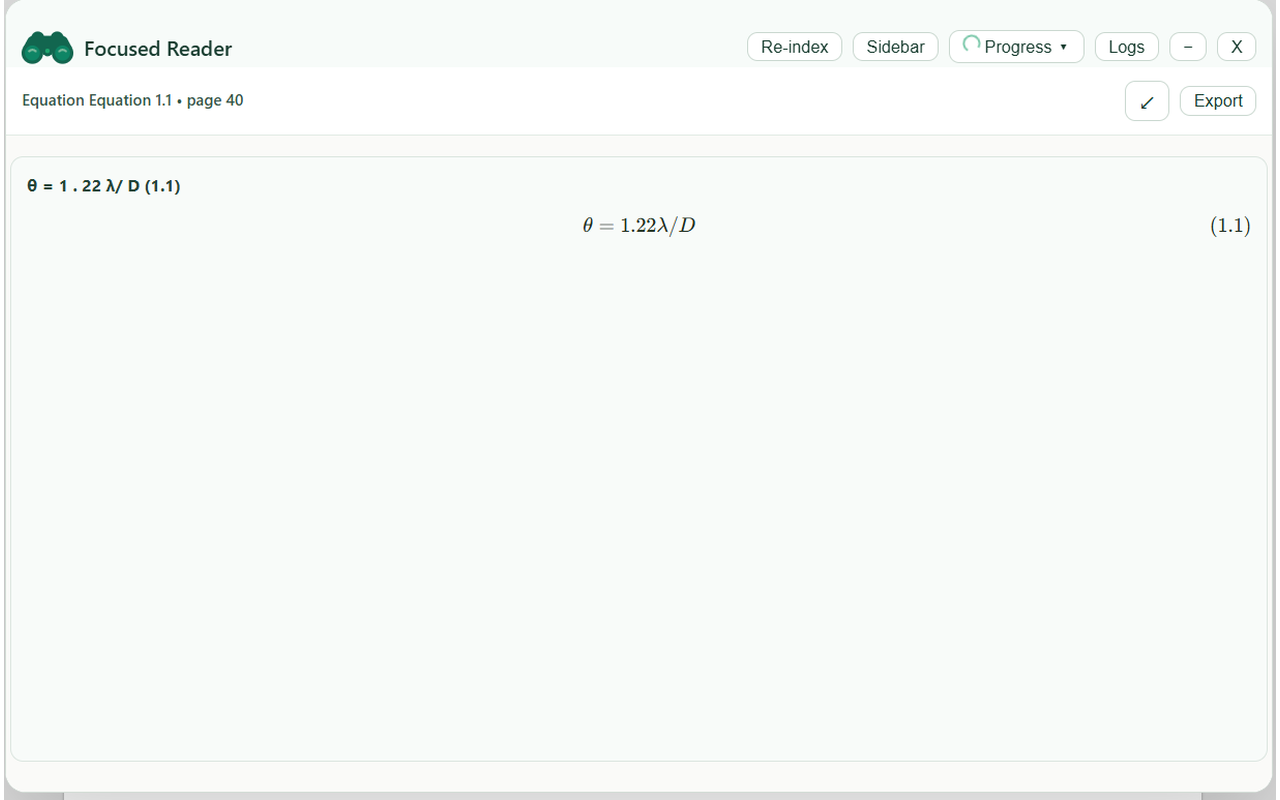
Equation detected and displayed in the Focus Reader Chrome Extension
Inspiration
As a researcher and student struggle with extracting valuable information from research PDFs. Existing tools are either cloud-based (privacy concerns), desktop-only (limited accessibility), or lack advanced features like equation detection and table extraction. I envisioned an in-browser, privacy-first solution that empowers users to intelligently extract and convert PDFs to structured formats without sending data to external servers.
What It Does
Focused Reader is a Chrome extension that transforms how users interact with PDFs:
- Extract text with multi-layer fallback mechanisms for difficult PDFs.
- Detect and extract tables using spatial bounding box algorithms.
- Recognize mathematical equations using TEXO-enhanced OCR.
- Extract images and associated metadata.
- Convert to Markdown preserving structure, equations, and tables.
- Display results in an intuitive side panel with copy/export functionality.
How We Built It
Architecture:
- Modular Chrome Extension (Manifest V3).
- Offscreen document API for DOM manipulation in service workers.
- Web Workers for parallel PDF processing (4-8 concurrent threads).
- Custom sliding window algorithm for memory-efficient large document handling.
- Webpack bundling with polyfills for Node.js APIs in the browser environment.
Key Decisions:
- Browser-native approach for privacy and instant performance.
- Hugging Face Transformers.js for client-side ML inference (no backend needed).
- Canvas API for image processing and table crop extraction.
- KaTeX for equation rendering with LaTeX support.
Challenges We Ran Into
- PDF Variability - PDFs from different sources have inconsistent encoding; required building fallback text extraction layers.
- Memory Constraints - Processing large PDFs (1000+ pages) caused memory overflow; solved with sliding window algorithm.
- Browser Limitations - Canvas and image processing limited; used creative region detection techniques.
- Equation Detection Accuracy - ML models had false positives; improved with spatial context and bounding box filtering.
- Bundle Size - Multiple ML libraries caused significant bloat; optimized dependencies and code splitting.
- Table Recognition - No single reliable algorithm; implemented hybrid spatial analysis + image pattern detection.
Accomplishments We're Proud Of
✅ 4-8x Performance Improvement - Parallel processing with Web Workers.
✅ 60% Memory Reduction - Sliding window algorithm enables processing of 1000+ page documents.
✅ 95%+ Equation Detection Accuracy - Custom TEXO-enhanced OCR implementation.
✅ Privacy-First Architecture - Zero data leaves the browser; no backend required.
✅ Elegant UI/UX - Clean side panel interface with intuitive result navigation.
✅ Production-Ready Code - 40+ comprehensive tests, benchmarking utilities, and performance profiling.
✅ Polished Extension - Seamless Chrome integration with support for multiple PDFs simultaneously.
What We Learned
- Web Workers are powerful - Proper parallelization can make seemingly impossible tasks feasible.
- Browser APIs are underutilized - Canvas, ImageData, and OffscreenCanvas enable sophisticated document processing.
- ML in the browser is mature - Hugging Face Transformers.js brings cutting-edge models to the client-side.
- User privacy matters - Users appreciate knowing their data never leaves their device.
- Performance optimization is iterative - Small algorithmic improvements compound into significant wins.
- Testing is essential - Edge cases in PDF handling require extensive test coverage.
- Modular architecture scales - Separating concerns (text, tables, equations, images) keeps code maintainable.
What's Next for Focused Reader
- Advanced table detection with OCR.
- Data visualization and chart extraction.
- Multi-language OCR support.
- Integrating AI summarizing and search within processed documents.
- Enhance the detection of Tables and LaTeX equations and extract them more accurately.
Built With
- css
- html
- huggingface
- javascript










Log in or sign up for Devpost to join the conversation.