-
-

About FocusBeats AI
-
Home Page
-
Before Processing
-
During Processing
-
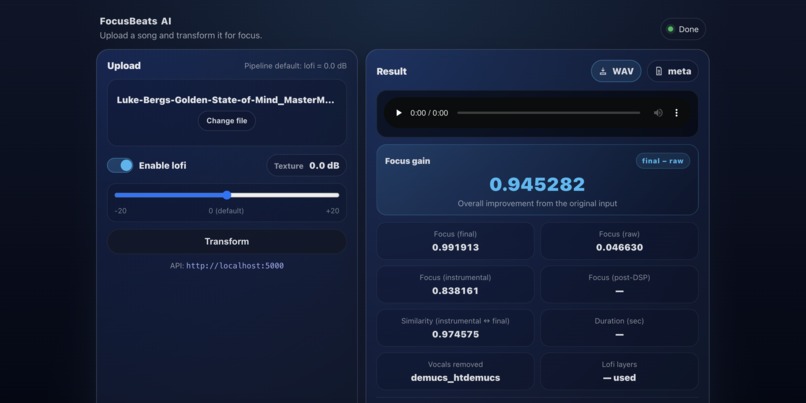
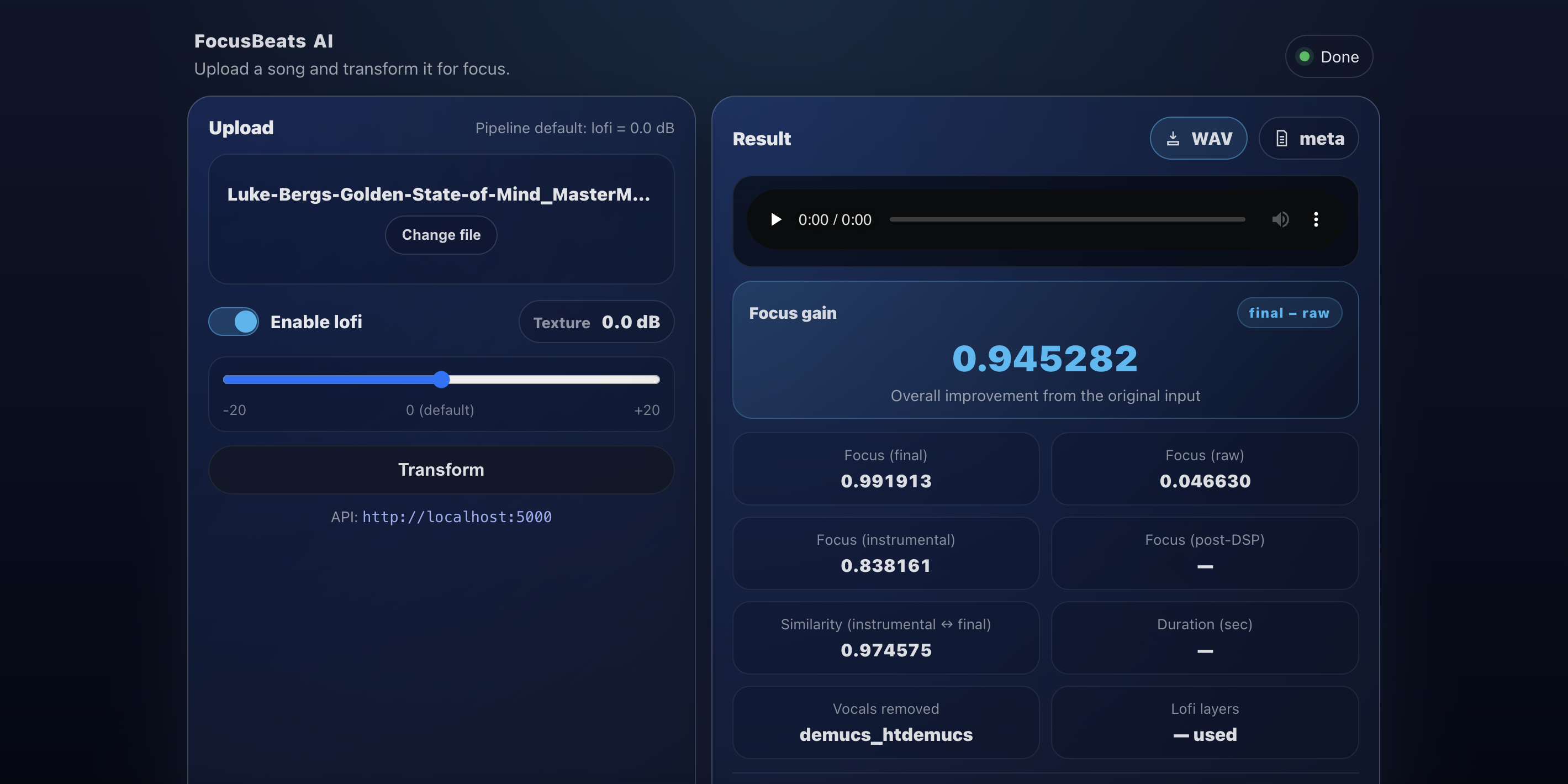
Transformed Version
-
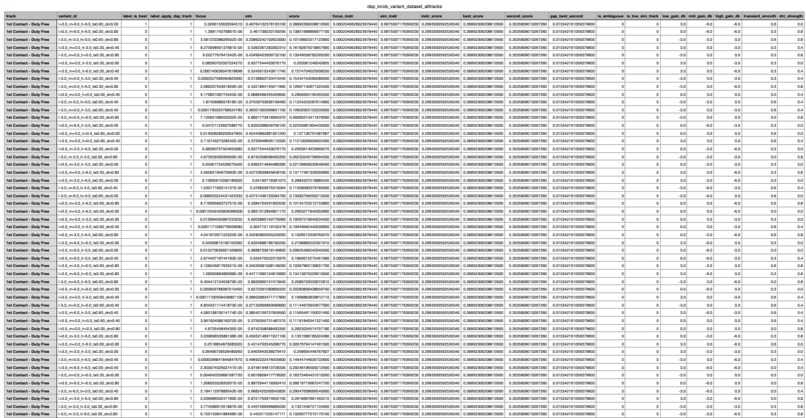
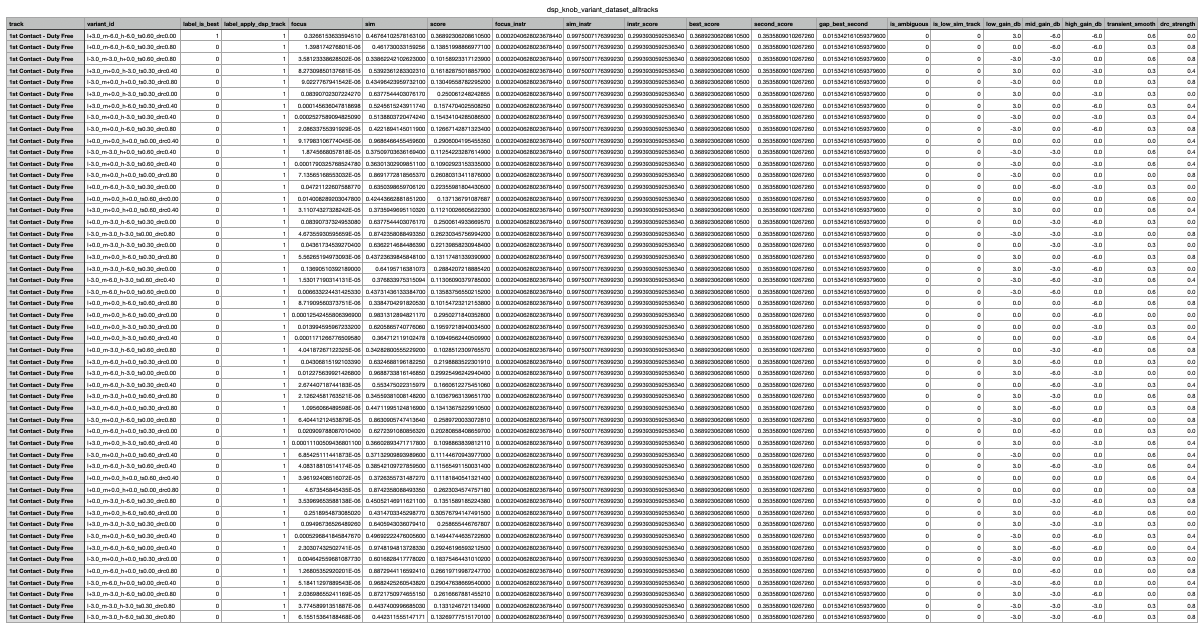
Dataset used to Train XGBoost Controller

Inspiration
Many individuals listen to music while they work. However, they choose to work with music that they are familiar with as prior research has shown that familiar music can reduce mind wandering and can feel easier to process. General background music has been shown to be highly dependent on the user, meaning the same piece of background music can help one person and hurt another. Therefore, I listen to my favorite playlists because I need familiar music, and general background music simply does not work for me. Yet, these pieces of music are not built for focus, and can interfere with cognitive performance. Thus, I decided to create FocusBeats AI, a completely novel application that allows users to enter any of their favorite songs and get a focus-optimized version that helps them concentrate.
What it does
FocusBeats AI takes any user-uploaded song and transforms it into a focus-friendly version. However, it also ensures that the identity (rhythm and melody) of the song stay consistent. The app first removes vocals using Demucs, an AI music separation tool. From the instrumental, the app computes numeric features and a 1024-D YAMNet embedding. Then, the app applies a small selection of Digital Signal Processing (DSP) knobs. The app then optionally adds lo-fi elements from a custom lo-fi library.
How I built it
A model was first created in order to estimate the focusability of a given song. First, a custom dataset consisting of 114 general tracks and 122 study-oriented tracks was created. All tracks were then standardized into 2-minute WAVs with loudness normalization. Then, two methods were used to extract the features of each track that the model would then be trained on. The first method extracted handcrafted features including tempo/onsets, RMS energy, spectral measures, MFCC stats. The second method extracted 1024-D YAMNet embeddings for each tract. Next, three focus models were trained. Model #1 was a logistic regression on the handcrafted features. Model #2 was a multi-layer perceptron trained on handcrafted features. Model #3 was also a multi-layer perceptron trained on YAMNet embeddings. Model #3 was the model used to rate focusability throughout the rest of the project. Then, Demucs was used to transform all 114 general tracks into instrumental versions. Once completed, a grid of digital signal processing knob combinations was applied to each instrumental track (EQ (low/mid/high), transient smoothing, and compression). For every variant, focusability was computed using model #3 and similarity using cosine similarity between YAMNet embeddings. Next, I needed to build a clean and labeled training data for the XGBoost ranking model. Once the dataset was built, I trained an XGBoost ranker to predict which knob setting should rank the highest. The ranker used the track's features, embeddings, and the knob values. Finally, I then prepared 18 lo-fi textures and applied trimming and loudness normalization. I then mixed two random layers into each of the 114 general tracks and evaluated the final transformed version to the instrumental version of the song (before DSP knob and lo-fi application).
Challenges I ran into
When building this project, I ran into multiple challenges. I had to ensure that the full pipeline was fair and reproducible. This was because of different audio formats and so I had to standardize heavily. Furthermore, I realized that no pre-built dataset that consisted of both general and study oriented tracks existed. So, I had to build my own custom dataset which took many hours. Although the focusability models performed well, the XGBoost ranking model often underperformed. This required me to adjust the dataset multiple times.
Accomplishments that I am proud of
The final focusability model (model #3) achieved 94.4% test accuracy and 0.988 ROC-AUC. The DSP controller had a top-1 hit rate of 78.3% and a top-3 hit rate of 95.7%. In the end, all 114 general tracks were evaluated. 83.3% of the tracks increased in focusability compared to the INSTRUMENTAL baseline. This signifies the strength of the DSP knob and lo-fi application. Furthermore, the mean cosine similarity was 0.9824, and median cosine similarity was 0.9869 compared to the INSTRUMENTAL version. This illustrates how the waveforms did not drastically change, and that the song retained its identity.
What I learned
I learned that audio ML is extremely sensitive to preprocessing, so standardization is crucial. I also learned about how tools such as YAMNet are important, and that not every part of the project must be created independently. I also learned how an XGBoost controller works, and why it was the correct choice over another ML architecture.
What's next for FocusBeats AI
The next important step is human study. This will be used to validate the results of the pipeline and ensure that the transformed version truly does increase focusability while keeping the identity of the original track. I also want to increase personalization by having FocusBeats AI learn the user’s settings so the DSP knobs and the lo-fi layers adapt to each user. I also want to release FocusBeats AI on the web so users have access to this application.

Log in or sign up for Devpost to join the conversation.