-
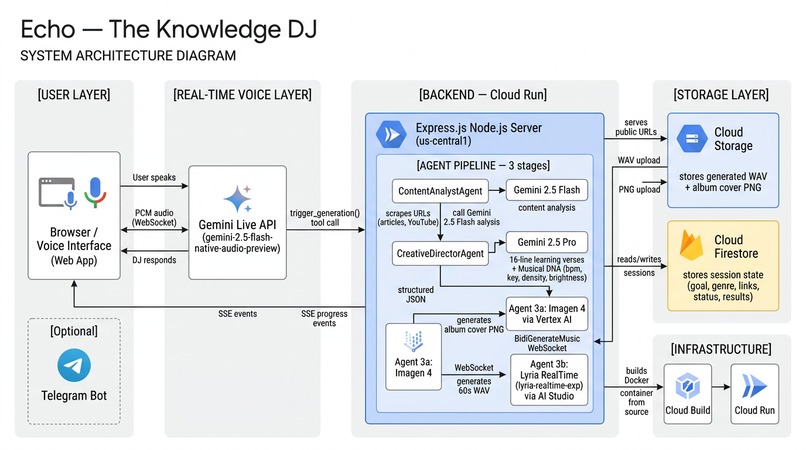
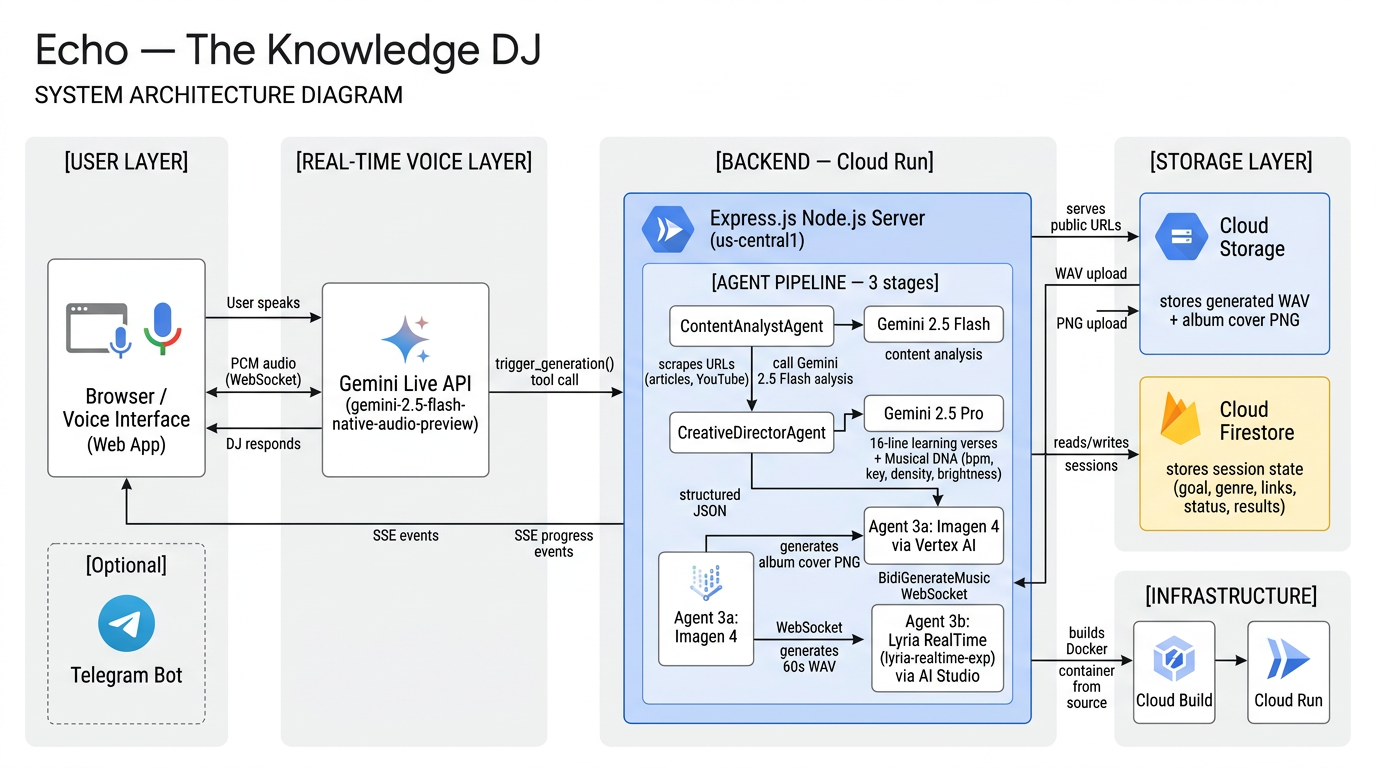
System Architecture
-
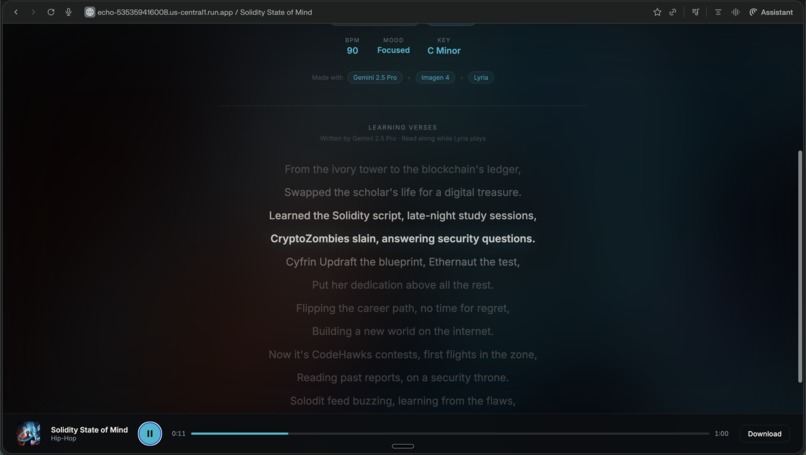
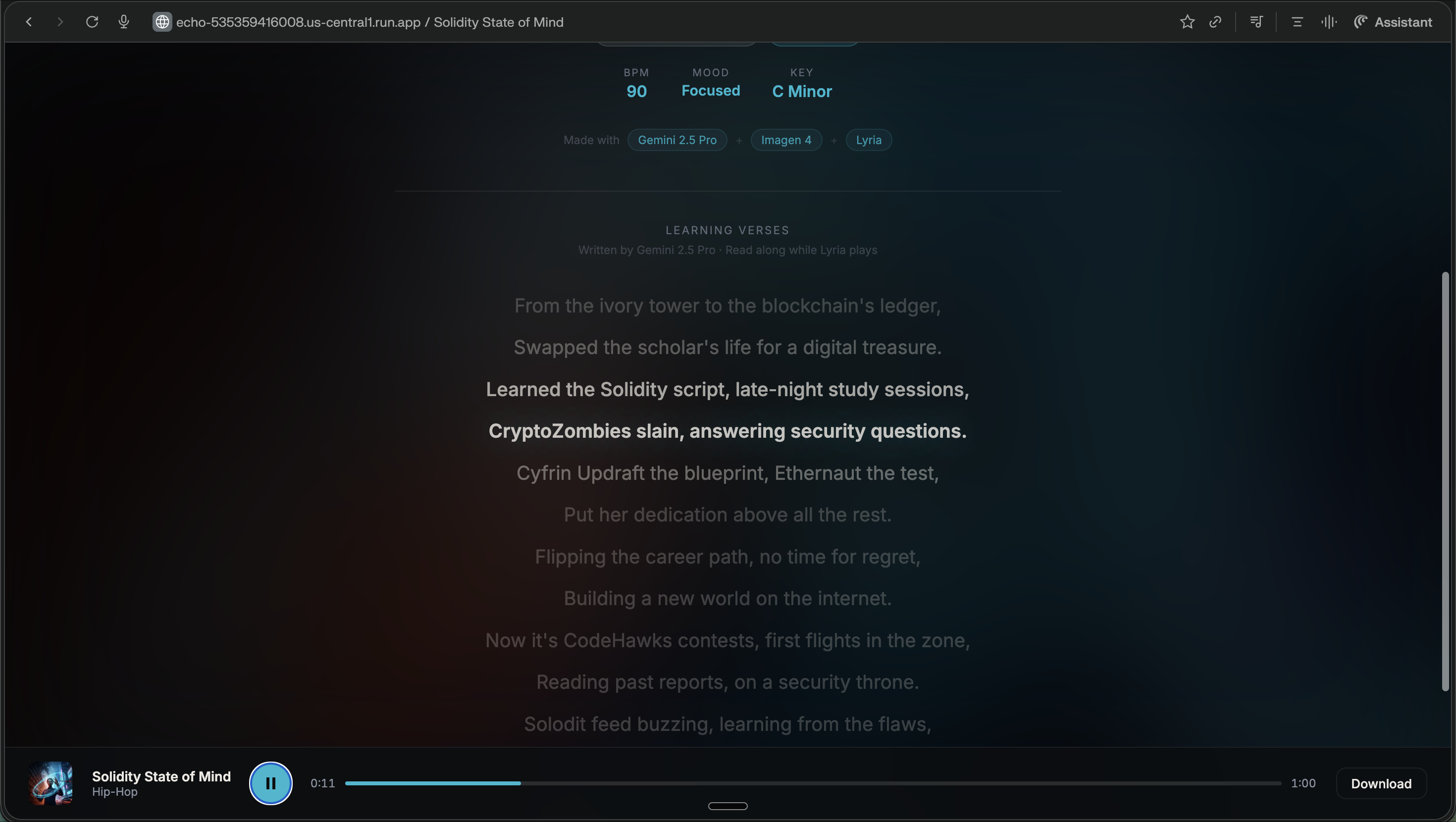
Song generated, with lyrics vibing
-
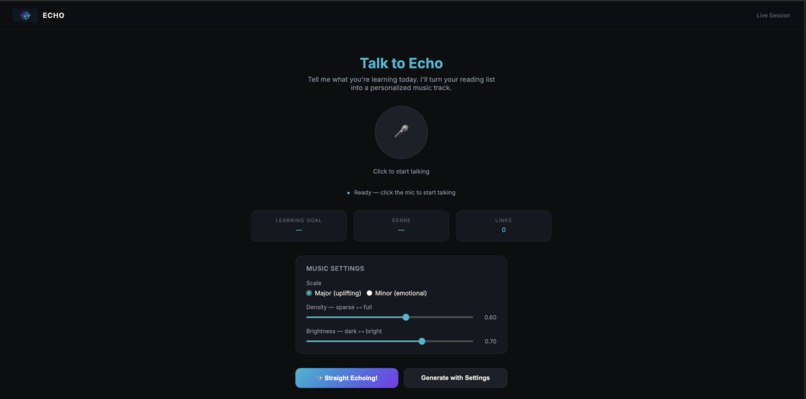
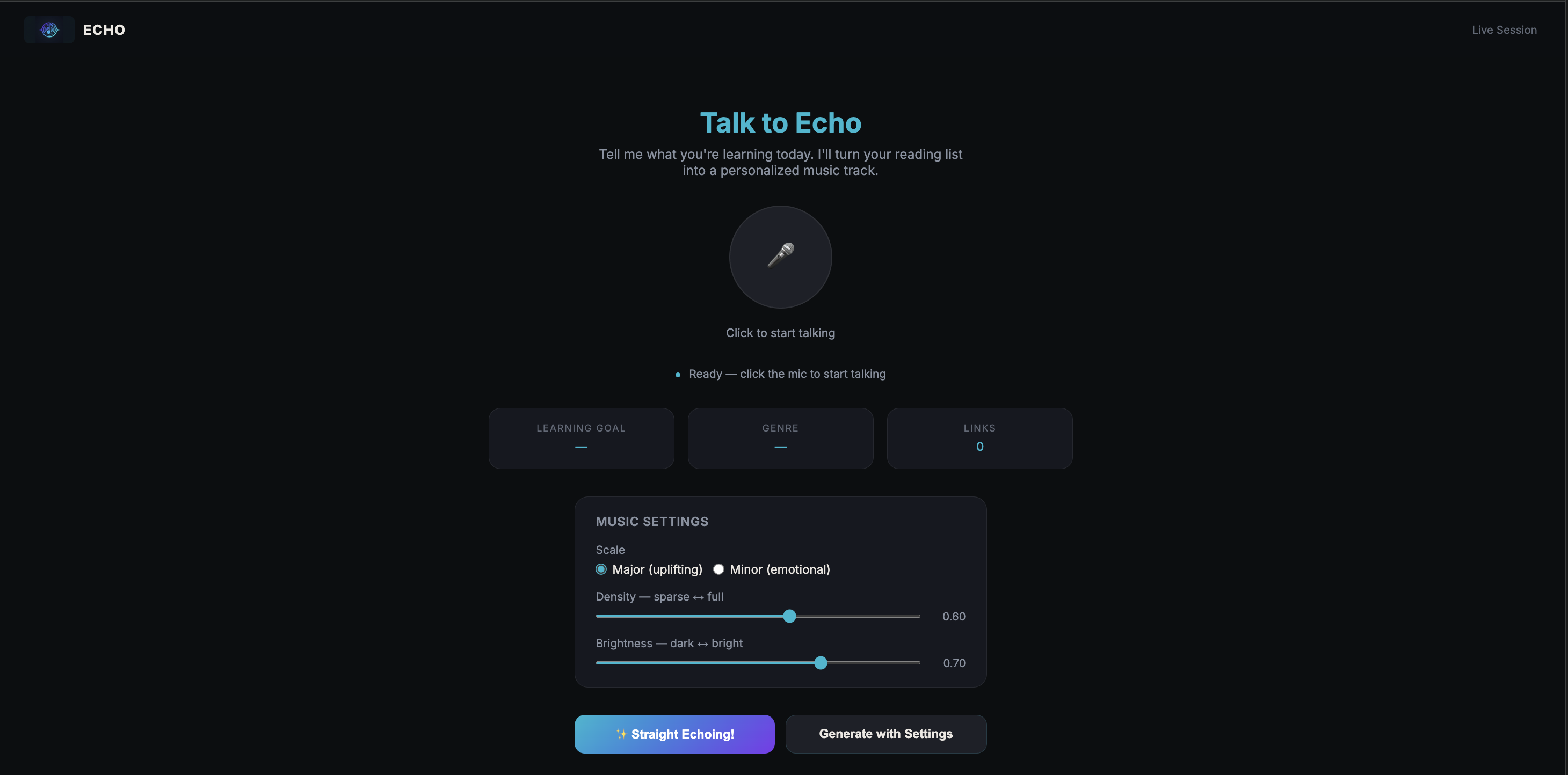
Click the orb and talk to Echo!
-
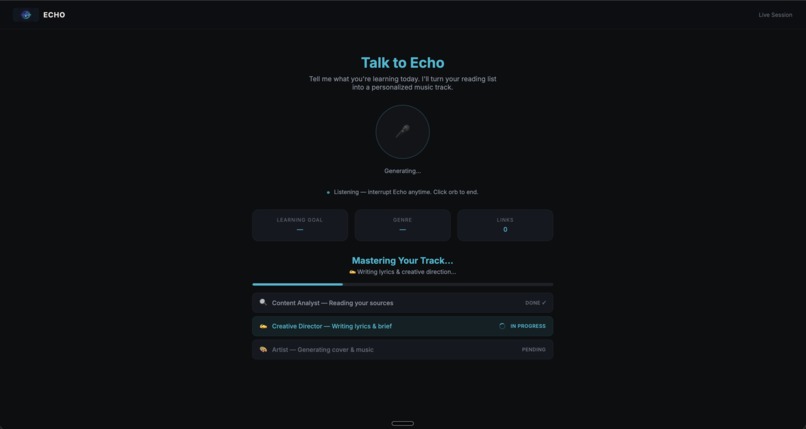
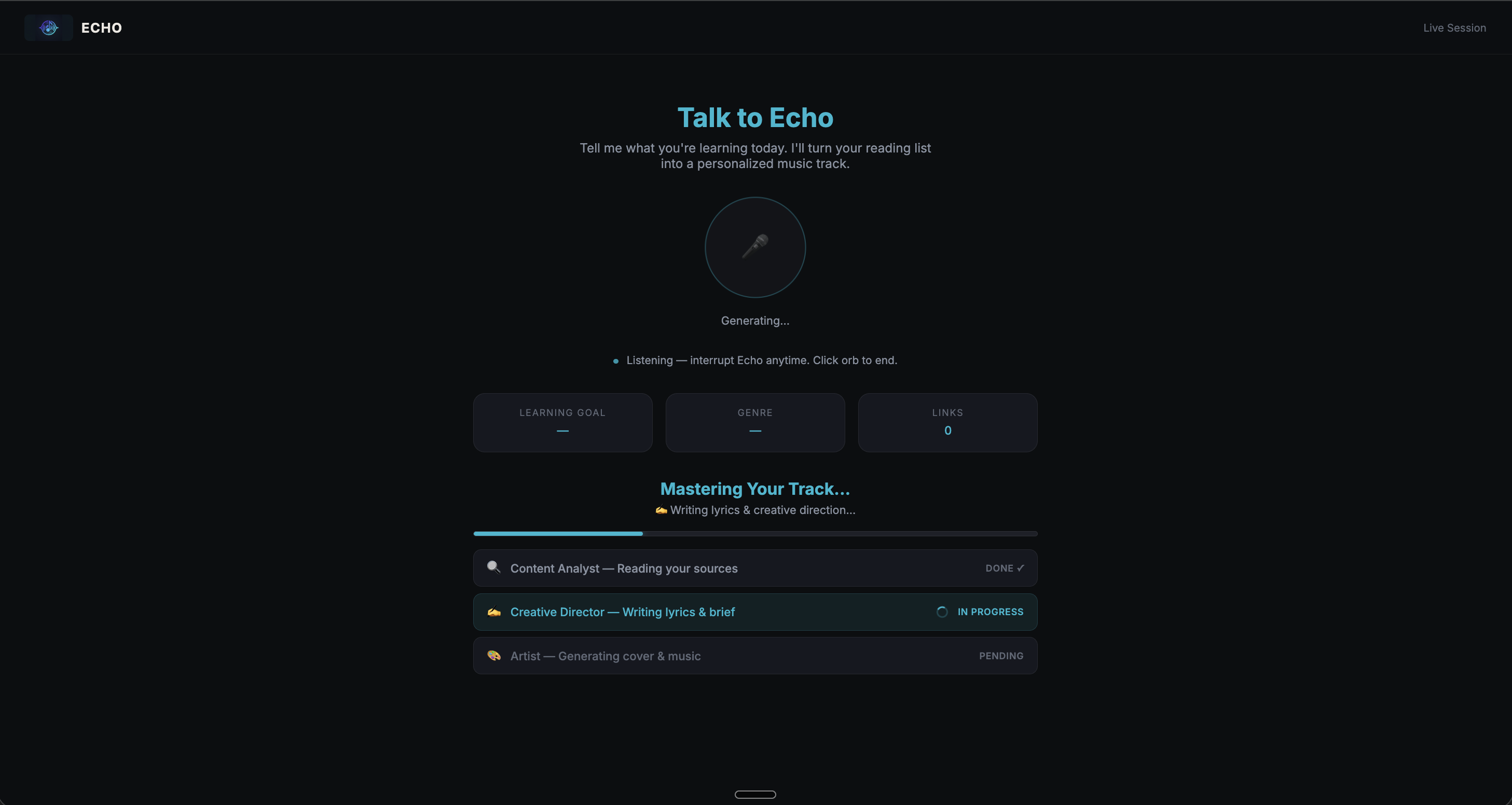
Music generating in progress....
What Inspired Echo
I spend a lot of time reading — articles, research papers, YouTube deep-dives, Twitter threads. And I've always felt there's a disconnect between consuming information and internalizing it. You read something brilliant, close the tab, and two days later it's gone.
Music is different. A song you heard once in 2015 can trigger an entire emotional memory. The rhythm makes it stick.
So the question that started Echo was: what if the content you consumed became a song about what you learned?
Not a random song. A personalized one — with a genre that matches your mood, an AI-generated album cover that reflects the content's themes, and verses written specifically from your learning goals. Something that encodes your knowledge into a format your brain actually remembers.
That's Echo: The Knowledge DJ.
How I Built It
The Architecture
Echo is structured as a 3-agent DAG pipeline inspired by Google's Agent Development Kit (ADK) patterns. Each agent is independently isolated and communicates through structured outputs:
Voice / Web Form
│
▼
Gemini Live API ──── real-time bidirectional audio
↳ trigger_generation() tool call
│
▼
Agent 1: ContentAnalystAgent
└─ Scrapes URLs → Gemini 2.5 Flash → key themes + insights
│
▼
Agent 2: CreativeDirectorAgent
└─ Gemini 2.5 Pro → 16-line learning verses + Musical DNA
│
┌┴────────────────┐
▼ ▼
Agent 3a: Imagen 4 Agent 3b: Lyria RealTime
└─ Album cover └─ 60s instrumental track
(parallel) (BidiGenerateMusic WebSocket)
└──────────────────┘
│
▼
Cloud Storage → Result Page (SSE progress)
The voice interface uses Gemini Live (gemini-2.5-flash-native-audio-preview) — a real-time bidirectional audio stream. Echo carries a natural voice conversation to collect three things: learning goal, music genre, and URLs. When it has all three, it calls a trigger_generation() function tool, which fires the pipeline. This is the core Live Agent pattern: the conversation is the agent, and the tool call is the handoff.
The Musical DNA System
The Creative Director agent outputs a structured "Musical DNA" object that drives Lyria:
$$\text{Musical DNA} = {bpm, \; mood, \; key, \; density \in [0,1], \; brightness \in [0,1]}$$
Lyria is steered with these precise parameters — not just a genre label. A jazz track about neural networks might get bpm=92, key="A Minor", density=0.6, brightness=0.4 — fundamentally different from a lo-fi track about the same topic.
The WAV Pipeline
Lyria streams raw PCM over a WebSocket. Building the WAV manually gave full control:
- Sample rate: $48{,}000$ Hz
- Channels: 2 (stereo)
- Bit depth: 16-bit signed PCM
- Target: $48000 \times 2 \times 2 \times 60 = 11{,}520{,}000$ bytes (~11 MB for 60 seconds)
Chunks accumulate until the byte threshold is hit, then a 44-byte RIFF header is prepended and the buffer is uploaded to Cloud Storage.
Challenges I Faced
1. Lyria's Undocumented WebSocket Protocol
This was the hardest technical challenge. Lyria RealTime (lyria-realtime-exp) is experimental and the documentation is sparse. Through trial and error I discovered:
- The
setupmessage must include themodelfield — omitting it causes a silent connection rejection - Prompts aren't sent as plain text — they go inside
{ clientContent: { weightedPrompts: [{ text, weight }] } } - Music configuration is a separate message:
{ musicGenerationConfig: { bpm, scale, density, brightness } } - Audio arrives as base64-encoded PCM in
serverContent.audioChunks[].data - Lyria generates instrumental music only — it doesn't sing text. This required a significant product pivot: instead of "AI karaoke", Echo frames the AI-written verses as learning companions to read while listening.
2. Gemini Live Timing & Tool Call Reliability
The voice session needed to avoid calling trigger_generation() prematurely — if Gemini started the pipeline before the user gave all three inputs, the generation would fail silently. The solution was a strict system prompt with explicit step gates (STEP 1 → 2 → 3 → 4 → 5) and a rule that the tool can only be called after a user confirmation. This made the conversation reliably collect all three required inputs before firing.
3. SSE + Long-Running Background Tasks
Generation takes 60–90 seconds. The browser needs to show real-time progress without polling. The solution: fire the pipeline as a background async task (fire-and-forget), use an in-memory EventEmitter as a pub/sub bus, and stream events to the browser via Server-Sent Events. Late-joining clients (e.g., page refresh during generation) replay the last known state from a pipelineState Map.
4. WebSocket Audio Buffering (Gemini Live ↔ Browser)
Gemini Live sends audio back as base64-encoded 24kHz PCM. The browser needs to play it in real time via the Web Audio API. The challenge was handling variable-size chunks, resampling from 24kHz to the browser's AudioContext sample rate, and avoiding dropouts. The AudioWorklet approach with a ring buffer resolved the latency and dropout issues
What I Learned
Lyria's true interface is Musical DNA, not text. The genre prompt matters less than the precise BPM, scale, density, and brightness values. This shifted how the Creative Director agent works — its most important output isn't the verses, it's the musical parameters.
Gemini Live's tool calling is surprisingly robust. The model naturally handles multi-turn conversations where users give partial information ("just jazz" → "what about jazz hip-hop?") and still correctly extracts structured data before calling the tool.
SSE is underused for long AI tasks. Compared to WebSockets, SSE is trivially simple to implement and perfectly suited for one-way progress streaming. The EventEmitter + SSE pattern is now something I'll reach for any time I have a background job that needs UI progress.
Product framing matters as much as the tech. The biggest lesson wasn't technical — it was learning that "AI writes song lyrics + instrumental music" is confusing when the music is instrumental. Reframing as "learning verses + musical companion" made the product story coherent and honest.
What's Next for Echo?
Full MV Generation (Pending Lyria vocal support)
Once Lyria supports lyrics + music together, Echo will generate complete music videos rendered with Google's Veo 3 — not just audio, but a visual learning experience where knowledge becomes something you can watch. The AI-written verses, album art, and music would be composed into a synchronized MV.
Current blocker: Lyria generates instrumental music only and doesn't support vocal tracks yet. Veo 3 was evaluated for video generation but integration was not completed in this MVP.
Zero-Input Goal Detection
Instead of asking users to type their learning goal, Echo would auto-detect it by connecting to the tools they already use:
- Notion API → read notes, pages, and tasks
- GitHub API → analyze repos, recent commits, and open issues
- Google APIs → scrape calendar, docs, or other workspace context
Echo would infer the user's learning goals from their existing data — eliminating manual input entirely and making onboarding frictionless.
Both features are scoped for post-MVP iterations. The current version establishes the core voice → analysis → music pipeline.
Built With
- axios
- cheerio
- css3
- express.js
- firestore
- genai
- google-auth
- google-cloud
- html
- javascript
- node.js
- telegraf
- ws
- youtube-transcript

Log in or sign up for Devpost to join the conversation.