
Problem
In education, certain groups of students can slip:
○ Low Income: 44% of high-achieving lower-income students fall out of the top reading achievement quartile between 1st and 5th grade
○ Neurodivergent: 32% of students with ADHD drop out of high school, and 33% of students with ADHD receive no school-based interventions at all
○ Mental Health: Only 25% of children with mental health challenges receive the required support; Only 34% of schools provided outreach mental health screenings for all students
What it does
Our tool helps educators identify when students are losing attention in real time by monitoring facial information (gaze, posture, facial movements, etc.) to detect student attention, engagement, and mood.
By surfacing patterns associated with stress, fatigue, social withdrawal, or ADHD-related symptoms, the system enables earlier intervention and more personalized support for students who might otherwise fall through the cracks. This is especially impactful in under-resourced communities, where students often have less access to individualized academic attention, mental health support, and learning disability screening.
How we built it
At its core, the system is a real-time computer-vision pipeline that converts a raw webcam feed into a high-dimensional behavioral signal stream — and from that stream, into a quantitative attention and ADHD-indicator profile. The browser captures frames, JPEG-encodes them, and pushes them over a single bidirectional WebSocket to a FastAPI server. Each frame round-trips through the analysis pipeline and returns a structured JSON metrics packet at near-camera framerate, while a parallel control channel handles start / stop session commands and final report delivery. We deliberately chose a binary-frames-out / JSON-metrics-back protocol over WebRTC so the server has direct access to pixel data for inference without negotiating media pipelines, while still hitting interactive latency.
The vision core is built around Google's MediaPipe Tasks API running two models concurrently on every frame: a 478-point face landmarker (with iris refinement) and a two-handed hand landmarker, both in VIDEO running mode so they exploit temporal tracking instead of re-detecting from scratch each frame. We extract a 6-point sparse correspondence (nose, chin, eye corners, mouth corners) and solve a full 3D head-pose estimation via OpenCV's iterative solvePnP against a canonical 3D face model — recovering yaw, pitch, and roll in degrees from the rotation matrix decomposition. Eye openness is computed as a 6-point Eye Aspect Ratio (EAR) averaged across both eyes, smoothed with an exponential moving average (α=0.25) so that individual blinks don't pollute the attention signal. Mouth opening uses an analogous Mouth Aspect Ratio (MAR) to detect sustained yawning (>0.45 for >2 seconds). Gaze direction is recovered from iris-landmark displacement: we take the iris center, normalize it against the eye's horizontal/vertical bounding box, and rescale by ~3.5× since the iris physically only travels ≈28% of eye width. The result is a continuous (gaze_x, gaze_y) ∈ [-1, 1] vector representing where on the screen the user is actually looking.
Because every face shape and webcam framing is different, the detector runs an 8-second adaptive calibration at session start: it collects yaw/pitch/gaze/EAR samples while the user sits naturally, then takes the median across all samples (robust to outliers) to build a per-user CalibrationProfile. Every downstream metric is then computed as a delta against this baseline, so a user who naturally tilts their head 10° still gets correctly classified as focused. The attention score itself is a weighted multi-signal composite clamped to [0, 100]: head-pose deviation contributes a soft penalty above ±20° yaw / ±25° pitch, EAR contributes a continuous penalty up to 40 points, gaze direction cancels up to 60% of the head-pose penalty when the iris is on-screen (so glancing down at notes doesn't tank the score), small head-velocity readings earn a stability bonus, and sustained yawning subtracts a fixed penalty. Discrete state classification (focused, taking_notes, looking_away, drowsy, uncertain, not_in_frame) is computed independently — taking_notes, for example, requires a downward pitch + downward gaze + low head velocity simultaneously, which lets us distinguish a student reading their textbook from one staring out the window.
Emotion recognition runs in a separate daemon thread to avoid blocking the frame loop. Every 15th frame is pushed into a single-slot queue (we always discard stale frames in favor of the freshest one) where a DeepFace worker runs a 7-class facial-expression CNN (happy / neutral / surprise / sad / fear / angry / disgust) and writes results back through a mutex-protected slot. The main loop reads the most recent mood snapshot non-blockingly, so a slow inference on one frame never stalls real-time feedback. We also implemented graceful tracking-loss handling: if face detection drops out for under 1.25 seconds, we hold the last good attention score and emit uncertain rather than collapsing to zero, which prevents flicker when the user briefly looks down or blinks aggressively. Each frame's output also carries a confidence score (0–1) and quality flags (calibrating_baseline, gaze_unavailable, tracking_jump, etc.) so the UI and downstream analytics can weight or discard noisy samples.
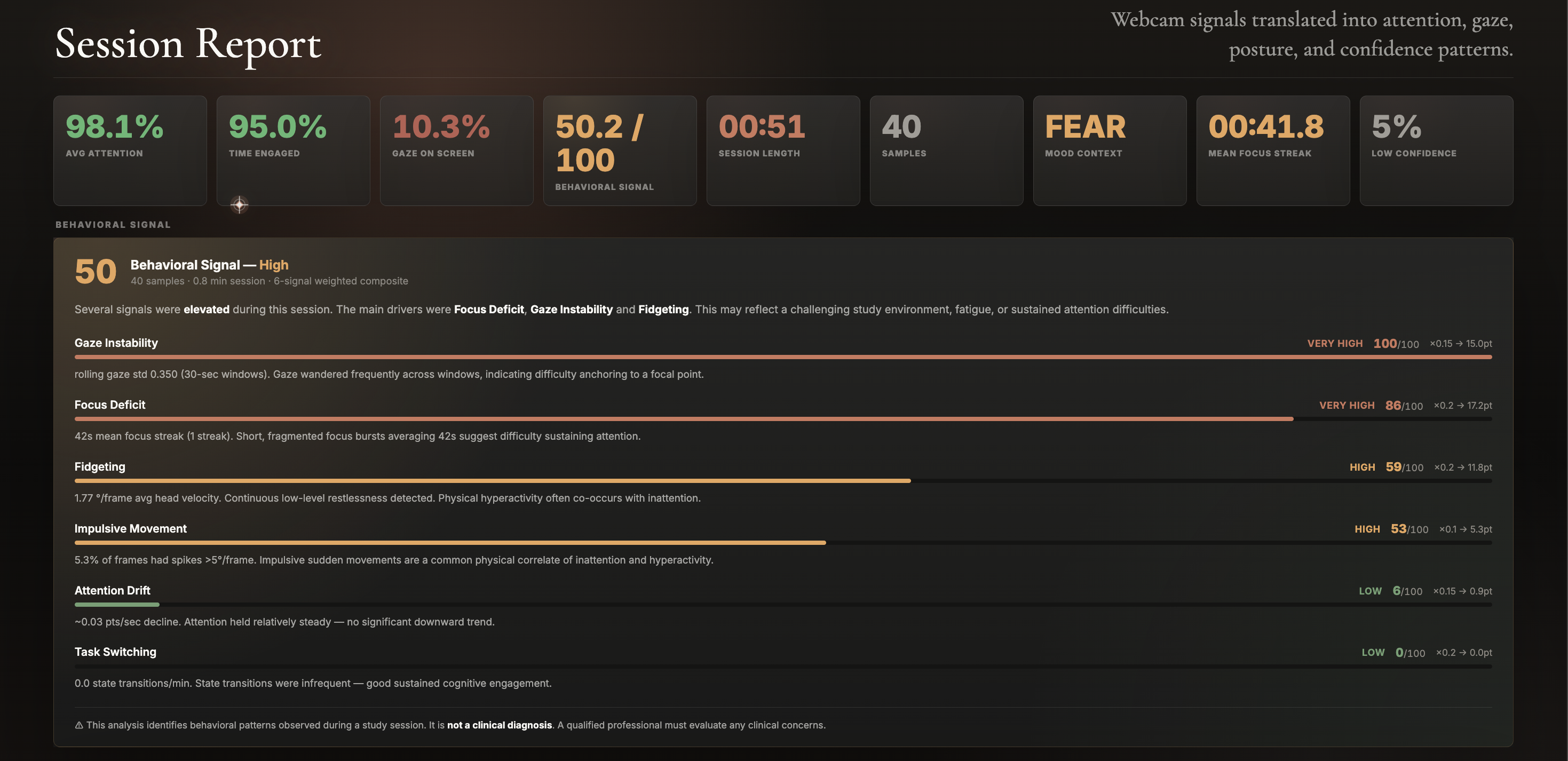
A SessionTracker accumulates one timestamped sample per second across the entire session, recording attention, state, mood, gaze, and head velocity, plus an event log of every state transition. When the user clicks Stop, the server runs the ADHD behavioral analysis module over the full sample stream, filtering to high-confidence engaged samples and computing six independent signals: attention drift (linear-regression slope of attention score over time), fidgeting (mean head velocity), gaze instability (mean of standard deviations of gaze position over rolling 30-second windows), task switching (state-change frequency per minute), focus deficit (inverse of mean continuous "engaged" streak duration — derived from a streak-detection algorithm that segments the timeline into focused intervals), and impulsive movement (fraction of samples exceeding a head-velocity spike threshold). Each signal is independently saturated to [0, 100], then combined into a composite risk score using empirically-chosen weights (focus deficit and task switching dominate at 0.20 each). The whole report — full statistical breakdown plus Plotly chart specs serialized as JSON — is shipped back over the same WebSocket and rendered client-side without a page reload.
Architecturally, the stack runs as two cooperating servers in development: FastAPI + Uvicorn on port 8000 hosts the WebSocket pipeline, MediaPipe models, and DeepFace worker, while Vite on 5173 serves the React 19 frontend with hot-module reload and proxies /ws traffic transparently to the backend. This split lets us iterate on UI shaders, custom WebGL cursors, and animated reveal logic at sub-second refresh while the heavier ML models stay warm in a long-lived Python process. The result is a system that takes ~30ms per frame end-to-end on an Apple M3 (XNNPACK-delegated TensorFlow Lite for the landmarkers, Metal-backed GL context for MediaPipe's internal compute graph), produces a dense behavioral fingerprint at 1Hz sampling, and delivers a full session report in under a second after stop — all from a single laptop webcam, with no proprietary hardware or cloud inference in the loop.
Built With
- claude

Log in or sign up for Devpost to join the conversation.