-
Deep Learning Final Project Poster
-
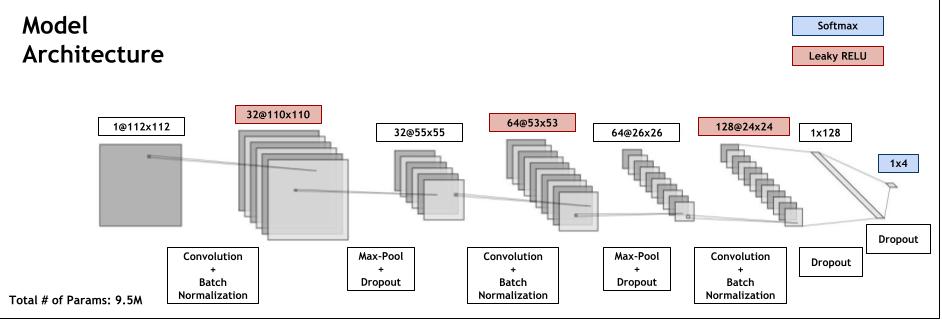
Model Architecture
-
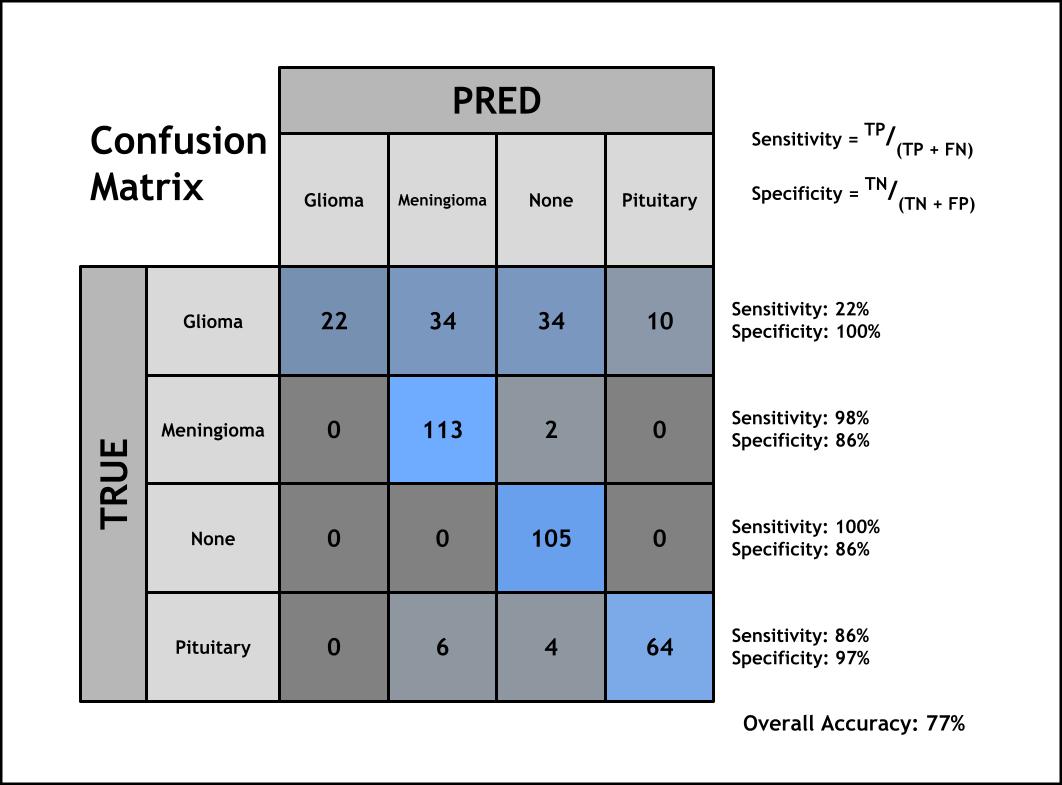
Confusion Matrix for Test Results
Final Writeup/Reflection
Title
What’s in Your Brain?: A CNN Approach to Tumor Detection
Who
Daniel Cho, Kameel Dossal, David Han, Erica Song
Introduction
Convolutional neural networks are a deep learning architecture commonly used for image classification tasks. In the healthcare field, medical professionals use various imaging techniques on the body to properly diagnose patients with diseases. Brain tumors represent one area where machine learning has the potential to help healthcare professionals make more informed decisions, saving time and money. In this project, we implemented a CNN model that classifies brain tumors using MRI images. The categories of tumors were glioma, meningioma, pituitary, and no tumor. We chose to emulate the 2019 paper “Brain Tumor Classification Using Convolutional Neural Network” by Das et al. because we wanted to implement multi-class classification of images. This model also serves an important purpose since the survival rate depends on the type of tumor, and this model can help doctors correctly classify tumors and provide the most fitting treatment to their patients in the early stages of the disease.
Methodology
We trained our model on the Brain Tumor Classification (MRI) dataset from Kaggle (https://www.kaggle.com/datasets/sartajbhuvaji/brain-tumor-classification-mri). The dataset contains four categories of tumors: glioma, meningioma, pituitary, or no tumor. In total, there are 3,264 grayscale images split into a train set and a test set.
| Train | Test | |
|---|---|---|
| Glioma Tumors | 826 | 100 |
| Meningioma Tumors | 822 | 115 |
| Pituitary Tumors | 827 | 74 |
| No Tumor | 395 | 105 |
Figure 1: Test-train split of the brain tumor dataset.
We preprocessed the images by resizing them to 112x112. We applied a Gaussian filter with kernel size 5x5 and used histogram equalization to enhance contrast. Before feeding them through the model, we also randomly flipped them horizontally and vertically.
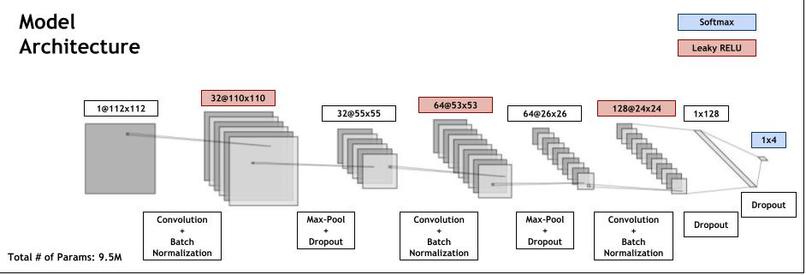
Our model was a CNN with the following tensorflow keras layers: Conv2D (32 filters, kernel size of 3, stride length of 1) BatchNormalization LeakyReLU MaxPool2D (pooling window of 2x2) Dropout (rate of 0.4) Conv2D (64 filters, kernel size of 3, stride length of 1) Batch Normalization LeakyReLU MaxPool2D (pooling window of 2x2) Dropout (rate of 0.5) Conv2D (128 filters, kernel size of 3, stride length of 1) BatchNormalization LeakyReLU Dropout (rate of 0.4) Flatten Dense (output layer size of 128) Dropout (rate of 0.3) Dense (output layer size of 4, or the number of classes) Softmax We used an Adam optimizer with a learning rate of 0.0001 and trained this model for 100 epochs with batch size 128 on the training dataset. The accuracy metric was sparse categorical accuracy and the loss function was sparse categorical cross-entropy.
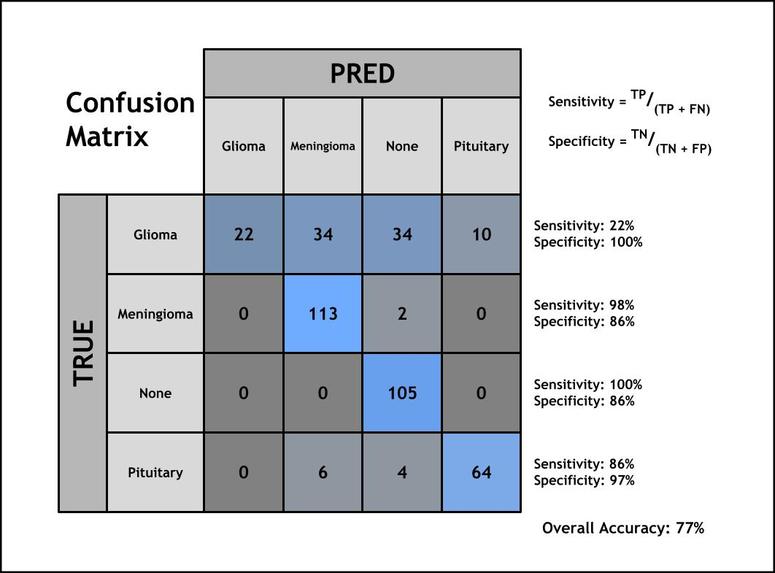
To evaluate our model, we used the test set to calculate the overall accuracy and the sensitivity and specificity values for each category.
Sensitivity measures the model’s ability to correctly identify a specific tumor as that tumor. It is the fraction of true positives among all images in a certain category.
Specificity measures the model’s ability to recognize when an individual does not have a disease. Specificity is given by the true negatives for each tumor type divided by the sum of true negatives and false positives.
Results
Our final test accuracy plateaued at 77%. Our model struggled to classify gliomas the most, only correctly classifying 22% of gliomas. The model was fairly successful at classifying meningiomas (98% sensitivity), no tumors (100% sensitivity), and pituitary tumors (86% sensitivity). This means that our model did not misclassify any tumorless images, and it correctly classified nearly all of the meningiomas.
The specificity of gliomas was 100%, all of the tumors labeled as gliomas were actually gliomas, and none of the other tumors were mislabeled as gliomas. Pituitary tumors also had a high specificity of 97%, so the model misidentified a few other tumors as gliomas. The meningioma and no tumor categories both had a lower specificity of 86%, indicating that the model was more likely to misclassify tumors as meningioma and no tumor.
When examining the training process, we noticed that the accuracy stagnated while the loss kept decreasing. Thus, we concluded that our model was overfitting to the training data. We built a second model with two of the three convolutional layers removed and with higher dropout rates, but the test accuracy plateaued at 70%. Because medical diagnoses require high accuracy, we chose the overfitted model as our final model due to its higher accuracy on the test set.
In order to visually see what the model was doing, we also implemented a LIME explainer. This is especially important for healthcare professionals to trust the predictions of the model. Based on the images returned from the LIME explainer, we can see that the model does not perfectly pinpoint the tumor and that the noise in the surrounding areas of the brain can negatively impact the prediction. In some images, regions outside the brain and head also contributed to the prediction, even though they should be irrelevant.
Challenges
A major challenge with the model was that the accuracy of the model when classifying glioma tumors failed to reach our goal of 80% accuracy. The final accuracy for glioma classification on the test set was 22%. Changing the hyperparameters did not yield substantial improvements in classification. We tried several ideas to improve the accuracy of our model, including random top-bottom flipping, random transpositions, batch normalization, and different numbers of convolutional layers. One potential reason for the poor accuracy compared to the original paper is that we used four classifications (glioma, meningioma, no tumor, pituitary tumor) while the authors used three (glioma, meningioma, pituitary tumor). The no-tumor images may contain features that impair the model’s ability to learn the differences between tumors, but further testing is needed to determine this. Additionally, some of the images in the dataset were stretched out of proportion from our preprocessing in order to have all images of uniform size. Removing severely stretched images from the training and test sets could improve the model’s learning.
Reflection
We were satisfied with the fact that our model ran and classified tumors much more accurately than random guesses. Our final accuracy was about 77%. Our base goal was 80% accuracy, which we were close to hitting. Our target goal was 90%, and our stretch goal was 94% accuracy. We realized in the original paper that inspired our model, the authors only had 3 categories of tumors: glioma, meningioma, and pituitary. Since our model classified images into four types of tumors (the aforementioned three categories and a “no tumor” category), this likely contributed to our lower accuracy. Our average precision was only 76.5% across the four categories (22% for glioma, 98% for meningioma, 100% for no tumor, and 86% for pituitary). This was less than the 93% average precision outlined in our stretch goal, but it is a reasonable precision given our model accuracy. Our model did classify tumors in the test set correctly with decent accuracy. However, it was overfitting to the training set; we saw training loss decrease to very small values, while test accuracy plateaued.
In the beginning, our model would always guess the same number for all the images (the class that occurred the most). This led to an accuracy of about 28%. Using SparseCategoricalAccuracy and SparseCategoricalCrossEntropy for our accuracy and loss metrics solved this problem. Later in the process, we ran into overfitting, which caused our accuracy to stagnate at 77%. To reduce overfitting, we randomly flipped images, increased dropout rates, and added batch normalization. While the original paper used the ReLU activation function, we used Leaky ReLU to try and prevent disappearing gradients.
Given more time, we would have tried to find a paper that categorized four types of tumors because the architecture might be very different for this task. We would also complete more thorough preprocessing and remove images that would be distorted by resizing to 112x112. Another strategy is only using training images taken from similar angles (for instance, only picking top views) and then specifying that the model is for use with images from that angle. This might introduce less unnecessary noise into the model.
We could also try taking out gliomas from the training set to see how that might change the training and loss. Some biological aspects of gliomas might be especially difficult for the model to learn. For instance, the glioma images might have a lot of noise that the model tries to learn, causing it to overfit to the training data.
In terms of the model architecture, we would like to experiment with different kernel sizes, activation layers, hidden layer sizes, and even average pooling. Our dense layers did not have an activation function between them, so the model may not have been able to learn nonlinear relationships in the data that well. We could try various activation layers between the dense layers.
Overall, we gained experience fine-tuning a deep learning model to perform well on image processing. We learned new techniques to standardize images by contrast, such as histogram equalization, and we learned more about brain tumors in general. We practiced methods of reducing overfitting and evaluating our model performance, as well as interpreting results in the context of brain tumor classification. Lastly, we learned that the quality of data and the complexity of the task determine the quality of the model. The original paper used a different dataset and only categorized three types of tumors, and their accuracy was much higher than our accuracy, even when we used the same model architecture.
References
https://www.kaggle.com/datasets/sartajbhuvaji/brain-tumor-classification-mri https://ieeexplore.ieee.org/document/8934603
Checkin Document
https://docs.google.com/document/d/1qyXLc_DTyTyBL_fHPOwA1V5ZxiXVfPcQ_-AWyYVtUgk/edit?usp=sharing

Log in or sign up for Devpost to join the conversation.