-
-
-

-
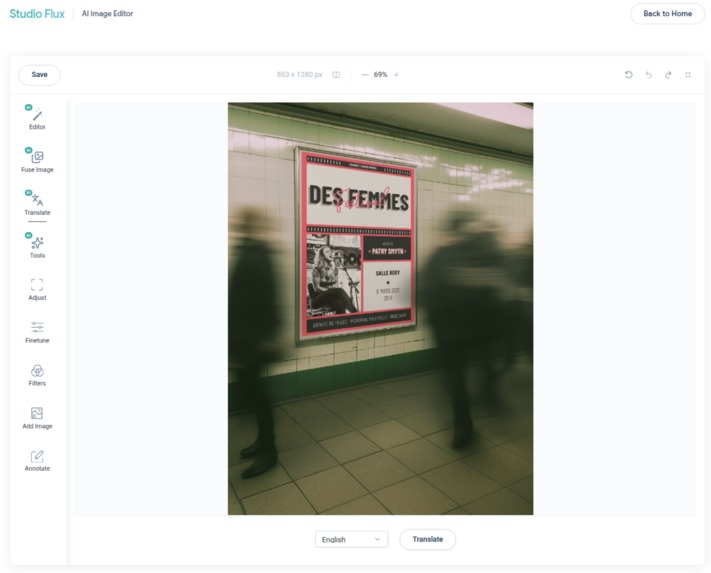
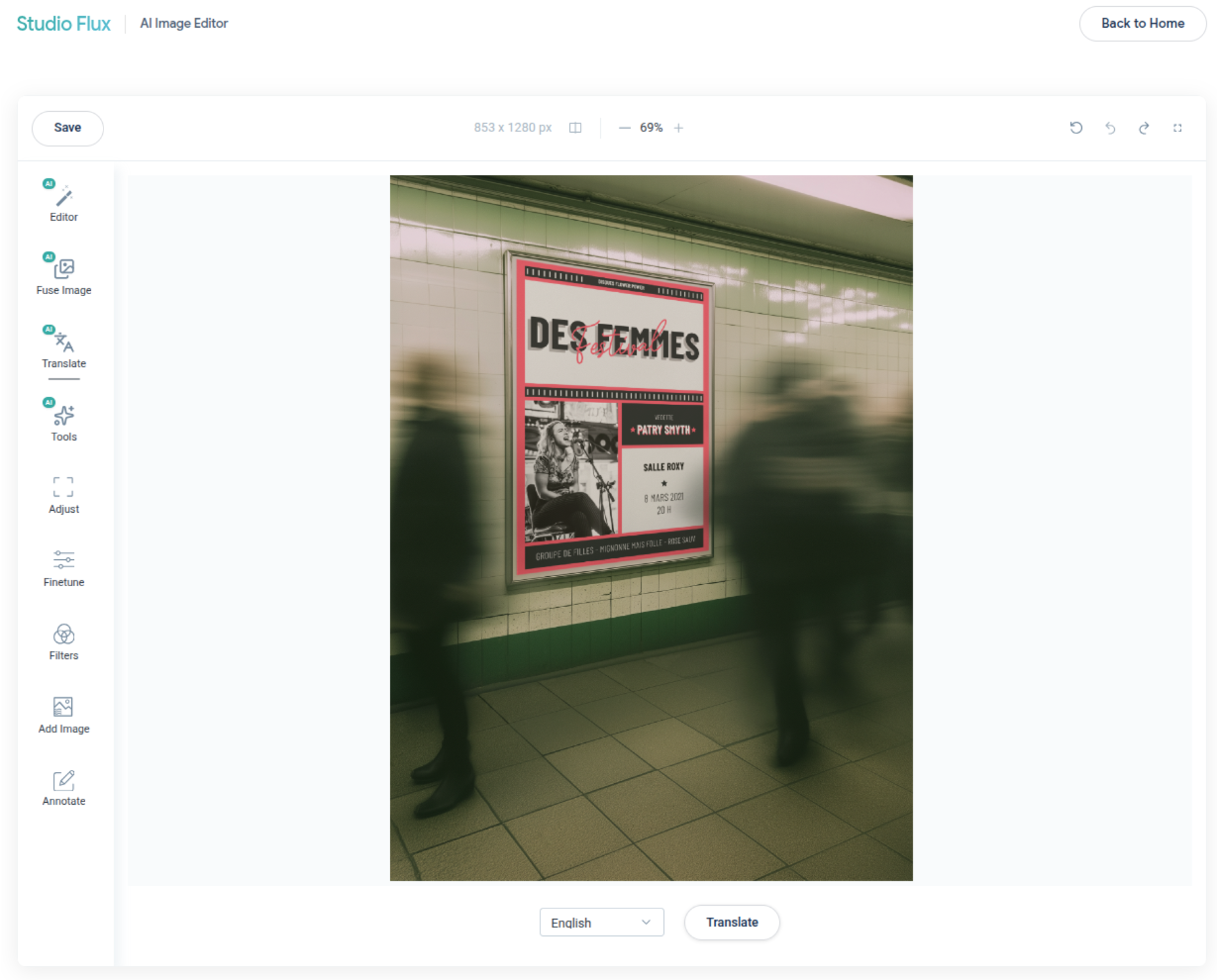
Flux Studio tool translate
-




Breaking Language Barriers in Visual Content: A Multi-Modal AI Translation Pipeline
The Problem: Where language meet pixels
Every second, millions of images cross digital borders. A brilliant infographic in Mandarin, a stunning poster in Arabic, critical safety instructions in Portuguese. The visuals travel at light speed, but the meaning? Stuck behind language walls. Traditional OCR chokes on rotated text. Translation APIs strip context. Manual editing takes forever and looks fake. We needed something radically different.
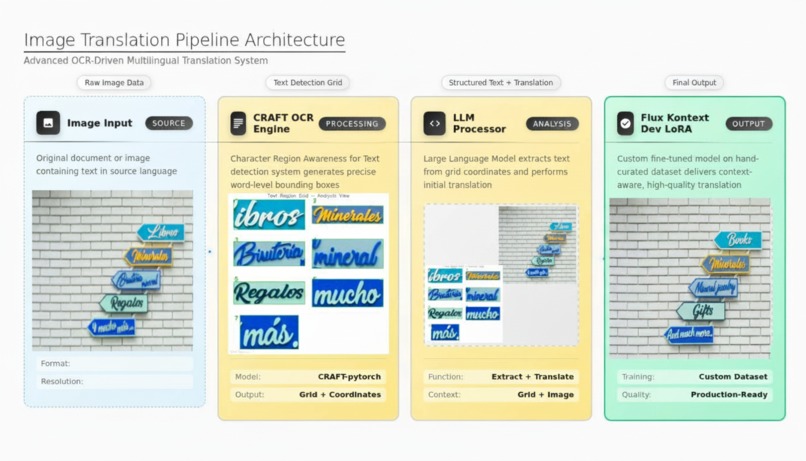
The Solution: Three different architectures Walk Into a single Pipeline... This project orchestrates three distinct AI technologies into a unified translation system that actually gets visual communication.
Stage 1: CRAFT Neural Networks + Smart Geometry CRAFT (Character Region Awareness for Text detection) uses PyTorch to detect text like humans do - understanding character relationships, not just rectangles. But here's the twist: we implemented a Union-Find algorithm for rotated box merging that groups text based on edge-to-edge proximity. The result? Text running diagonally saying "GRAND OPENING MARCH 15TH" stays together as one semantic unit, not 20 broken fragments.
Stage 2: Multimodal LLM Translation Instead of throwing isolated text at a translation API, our system feeds the LLM two images simultaneously:
- A numbered grid showing text positions with the rotated words which Increased accuracy, vision and understanding.
- The original image for full context
- The model sees "SALE 50% OFF" and understands it's a retail banner, not random words. It preserves urgency, hierarchy, and tone. Translation accuracy jumped high upwards compared to text-only approaches.
- The system generates pixel-precise prompts like: Exchange 'OPEN 24 HOURS' with '24 HORAS ABIERTO'.
Stage 3: Flux Kontext Dev with Custom LoRA We fine-tuned Flux Kontext Dev utilizing LoRA technique on a set of hand curated multilingual identical image pairs translated.
Technical Architecture That Actually Works This pipeline creates emergent intelligence. The OCR makes the translation smarter. The translation guides the image generation. The whole becomes greater than the parts. Key innovations:
- Rotation-aware text grouping with O(n α(n)) complexity
- Dual-image LLM prompting for context preservation
- LoRA fine-tuning specifically for multilingual text replacement
- Flask API with base64 streaming for instant response
Why This Matters This isn't just another AI tool. It's infrastructure for global visual communication. By understanding each AI models limitations and unifying the strength of each we achieve a better result.
When every image can speak every language while keeping its soul intact, the entire world becomes more connected.The future of communication it's about ensuring creativity reaching everyone, everywhere, instantly.
And this pipeline makes that future real, today.


Log in or sign up for Devpost to join the conversation.