Flux — HackIllinois Submission (Best Web API)
Inspiration
Every AI app that needs current information hits the same wall: LLMs are frozen in time, often trained on old, and outdated data. To give users answers grounded in the live web, you have to wire a search API, fetch and clean pages, rerank by relevance, call an LLM, and extract citations. That’s eight steps, four or more services, and hundreds of lines of glue code before you’ve built the product anyone actually sees. We kept hearing from developers who wanted to ship chatbots, research tools, or internal Q&A, and who were rebuilding this pipeline from scratch every time. We wanted one API that did the hard part so they could focus on the experience. The same way a single, well-designed API can turn a complex domain into a few clear calls, we wanted to turn “grounded, context-aware AI” into something you could integrate in minutes instead of weeks.
What it does
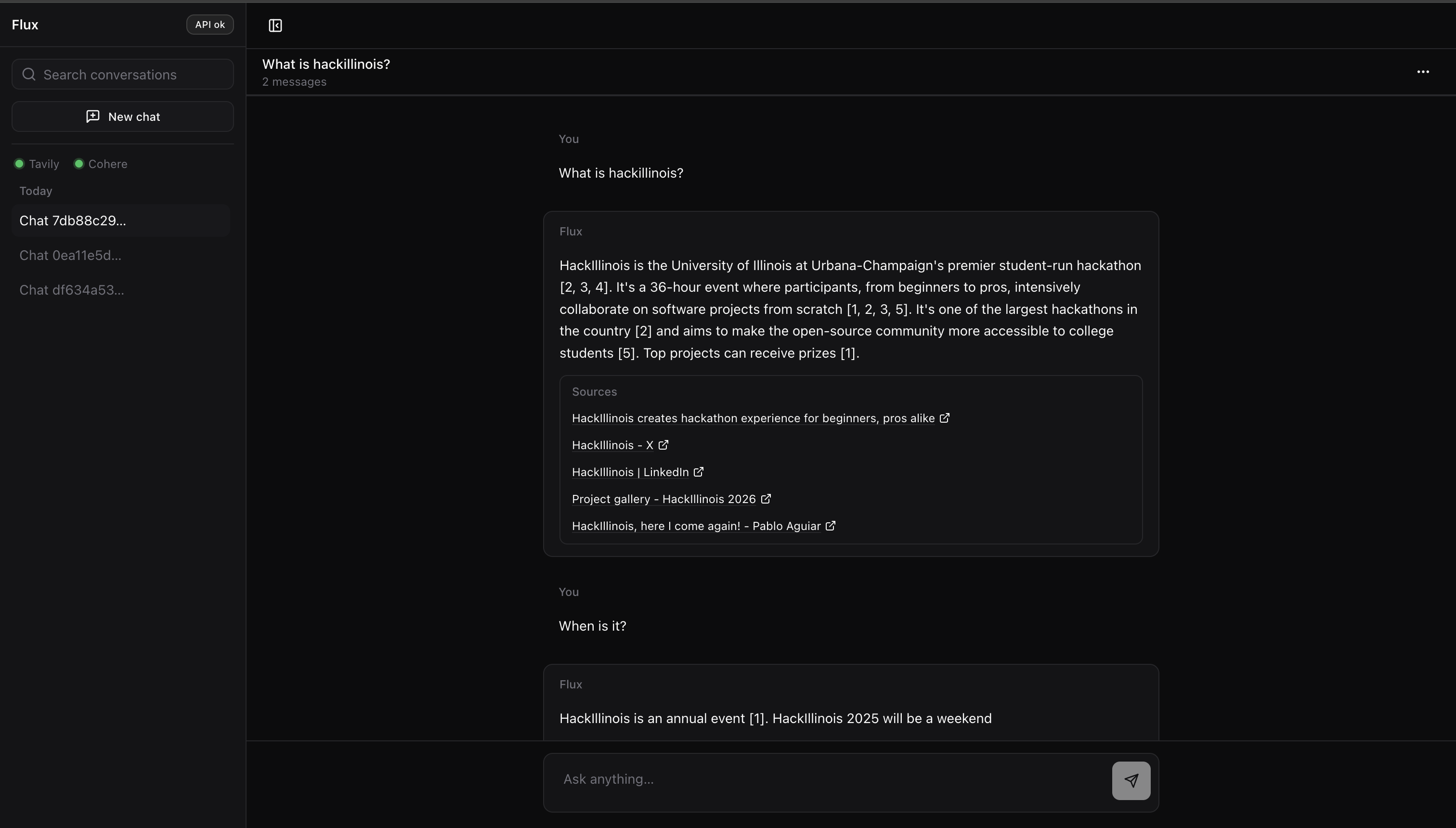
Flux is a REST API that gives your app live web search, cited answers, and stateful conversations in one place.
- GET /search — Send a query; get back live, semantically reranked results (Tavily + Cohere) with scores and ranks. No crawling or embedding code on your side.
- GET /answer — One question in, one cited answer out. We run search, rerank, and synthesis; you get JSON with an answer and a list of sources (title, URL, score).
- GET /contents — Pass up to 10 URLs; get back clean extracted text (and word count) per URL. Handy for “summarize these pages” or custom pipelines.
- Conversations — POST /conversations creates a conversation; POST /conversations/{id}/messages with
{"query": "..."}runs context-aware search and returns a cited answer. We use the last few turns to improve retrieval (e.g. “when is it?” after “what is HackIllinois?”). GET /conversations lists them with pagination (page,page_size); **GET /conversations/{id}returns the full thread; **DELETE /conversations/{id}removes one.
Every response is typed JSON. Every error is the same shape: {"error": "<message>", "code": "<CODE>"} with the correct HTTP status (400, 404, 502, etc.), so clients can branch on code or status. You can use cURL, Postman, or any HTTP client; we also ship a demo UI at /demo and interactive docs at /docs (Swagger, try-it-out).
How we built it
- API layer: FastAPI. Routers for health, search, answer, contents, and conversations. Validation at the boundary; no business logic in route handlers. OpenAPI at
/docsand/openapi.json. - Pipeline: Tavily for live search and URL extraction; Cohere Rerank for relevance scoring; a small reranker module that merges Tavily results with Cohere scores and assigns ranks. For answers and conversation messages we use an LLM (e.g. Gemini) with a fixed prompt and source citations.
- Conversation state: In-memory store (single module: create, get, list with pagination, update, delete). We cap total conversations and messages per conversation to avoid unbounded growth. Context for multi-turn is built from the last N queries (and optionally a snippet of the previous answer) and sent to Tavily so follow-ups like “why did it collapse?” retrieve results about the topic already in context.
- Errors: One Pydantic model (
ErrorResponse:error,code). Every failure path returns that shape and the right status. We redact API keys and internal details from messages before returning or logging. - Docs: README with one-line pitch, quick start (clone, env, run, curl), full endpoint table, full error-code table, and a 3-turn conversation example. Hosted Swagger at
/docs; optional Fumadocs site with Scalar API reference for the same spec.
Challenges we ran into
- Context without overloading search: Making “when is it?” work after “what is HackIllinois?” meant feeding Tavily a context-aware query. We had to decide how much history to include and when to append a snippet of the previous answer so vague follow-ups still retrieve the right topic. We added a small context-builder that takes the last few queries and optionally that snippet, and we kept the reranker query as the current query only so relevance scores stay meaningful.
- One contract everywhere: We wanted every error to be the same shape and status so clients could rely on it. That meant auditing every route for validation failures, missing resources, and upstream (Tavily/Cohere/LLM) failures and mapping each to a specific code and HTTP status, and making sure we never leaked secrets or stack traces in responses.
- Graceful degradation: If Cohere fails, we didn’t want the whole search to fail. We return Tavily order with a
reranked: falseflag so the API still works and the client can see that reranking was skipped. Implementing that cleanly required keeping the reranker as a separate step that could be skipped without breaking the response shape. - Docs and DX: We wanted a developer to clone, set env, and hit the API in under five minutes. That meant a strict quick start, a single error table they could scan when something broke, and making sure
/docsand the README matched the actual behavior (e.g. pagination, filtering, error codes).
Accomplishments that we're proud of
- Collapsing the pipeline: What usually takes eight steps and 200+ lines of integration code is one to three HTTP calls. A cited answer is a single GET; a full context-aware conversation is POST to create and POST to add messages. No search, rerank, or LLM code required in the client.
- Predictable surface: One error shape and one set of status codes across all endpoints. Pagination on list conversations; filtering (topic, days) on search and answer. Full CRUD for conversations: create, list, get one, delete. If you create a resource, you can list it and get it by id.
- Context that actually helps: Follow-ups like “why did it collapse?” or “when is it?” use conversation history so retrieval is about the right topic. We’re proud that the state we added is used in a meaningful way, not just for display.
- Documentation a developer can ship from: One README with a clear pitch, a full endpoint table, a full error table, and copy-paste curl examples including a 3-turn conversation. Interactive docs at
/docsso you can try every endpoint without writing code. No SDK required—just HTTP and JSON.
What we learned
- Reranking is a different job than retrieval. Using a dedicated reranker (Cohere) that scores query–document relevance directly gave much better ordering than we could get from a quick embedding similarity. Designing the API so we could degrade (return unreranked with a flag) when that service failed kept the API reliable without hiding the failure.
- Context has to be explicit in the request. To make multi-turn work, we had to encode “what we’re talking about” into the query we send to search (e.g. last N queries + current query, and sometimes a snippet of the last answer). Letting the LLM “remember” wasn’t enough; retrieval had to see that context too.
- A single error contract pays off. Once every path returned
{ error, code }and the right status, debugging and client logic got simpler. We also learned how important it is to redact and sanitize error messages so we never expose keys or internal paths. - Small surface, big leverage. Keeping the API to a few clear operations (search, answer, contents, conversations CRUD) made it easier to document, test, and reason about. We resisted adding options until we were sure they belonged in the core contract.
What's next for Flux
- Persistence: Replace the in-memory store with a database so conversations survive restarts and scale beyond a single process.
- Streaming: Support streaming for answer and conversation-message responses so clients can show tokens as they arrive.
- More controls: Optional parameters for reranking (e.g. top-k), synthesis (e.g. tone or length), and content extraction (e.g. max tokens per URL).
- Observability: Request IDs (we already add them), structured logs, and optional metrics so teams can monitor usage and latency in production.
- Broader docs: Expand the hosted docs site (e.g. Fumadocs + Scalar) with more examples, language-specific snippets, and a short “when something goes wrong” guide that maps codes to fixes.



Log in or sign up for Devpost to join the conversation.