-
-
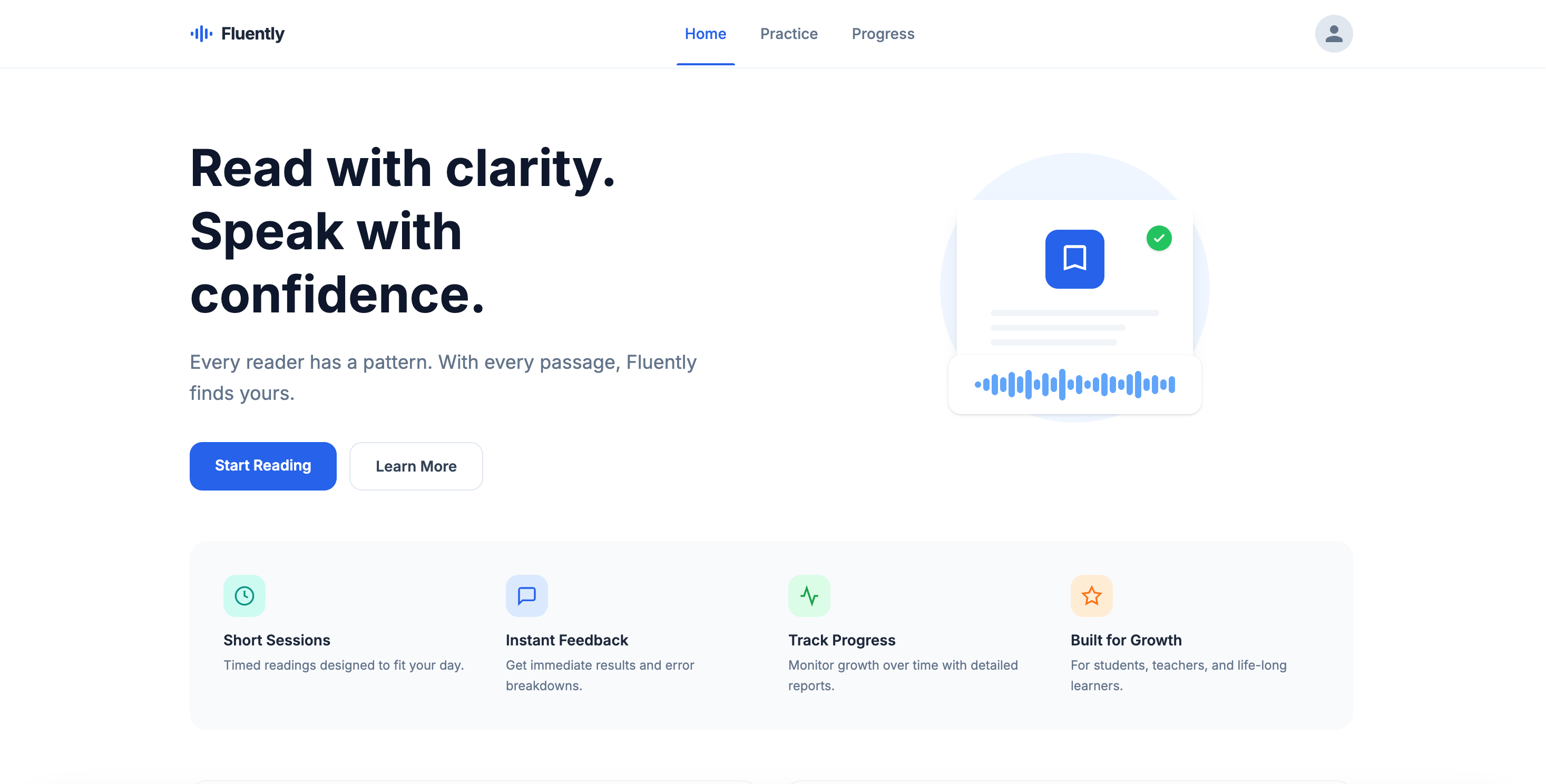
home page
-
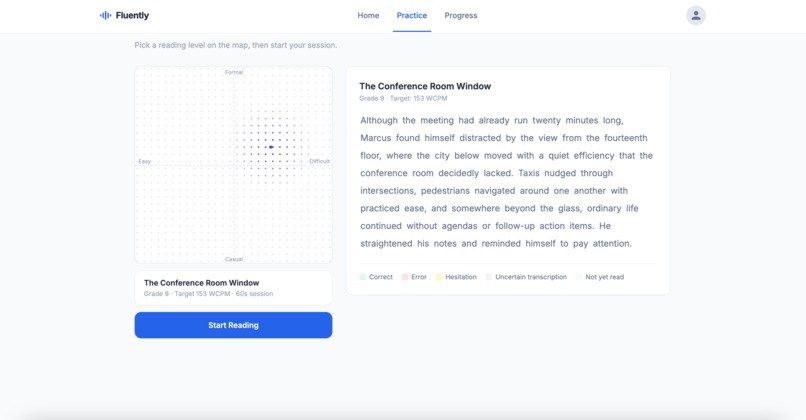
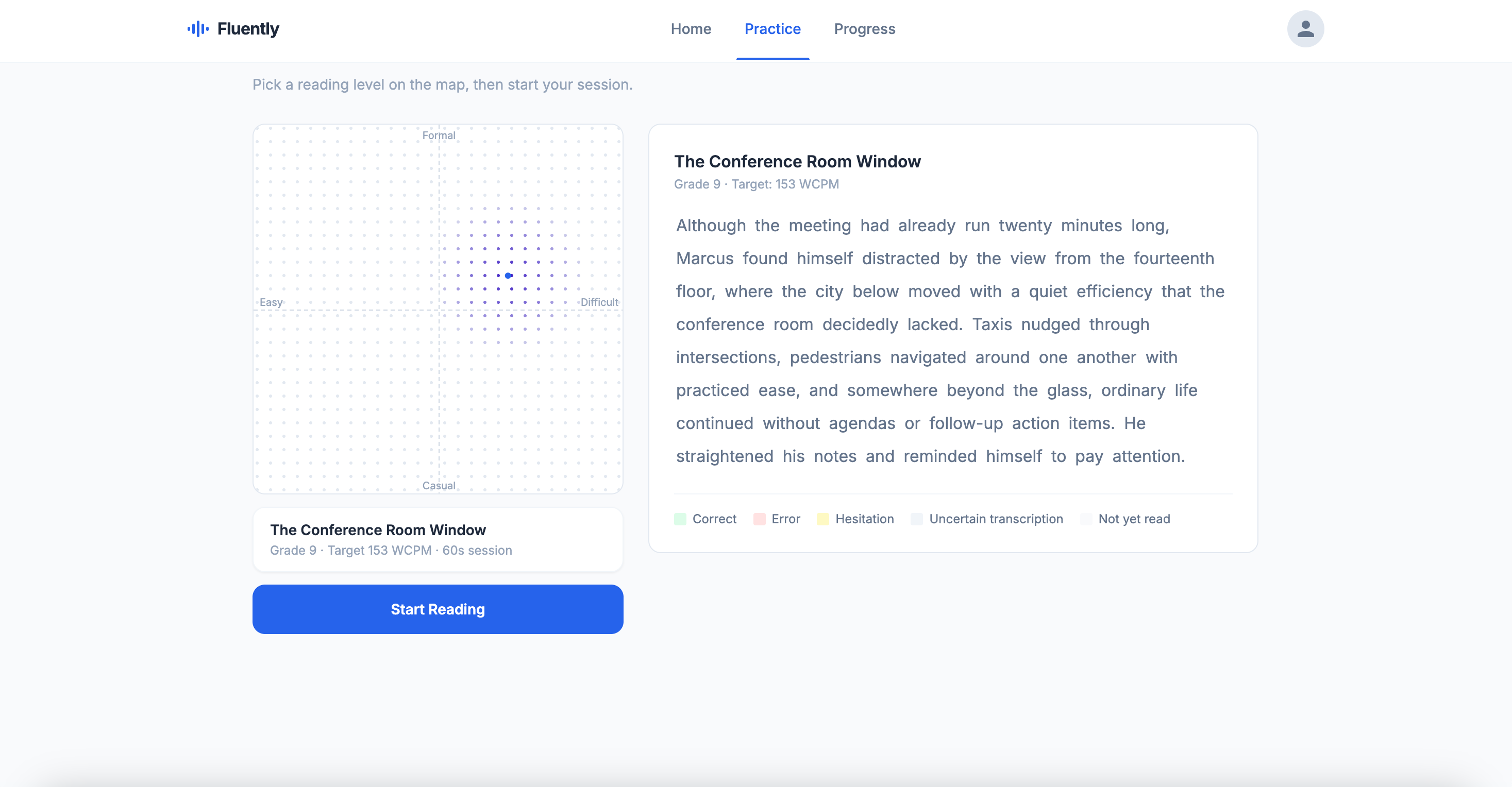
passage selection
-
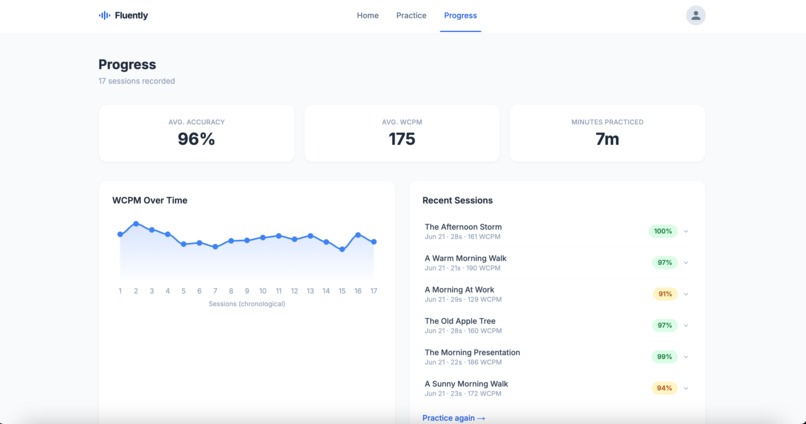
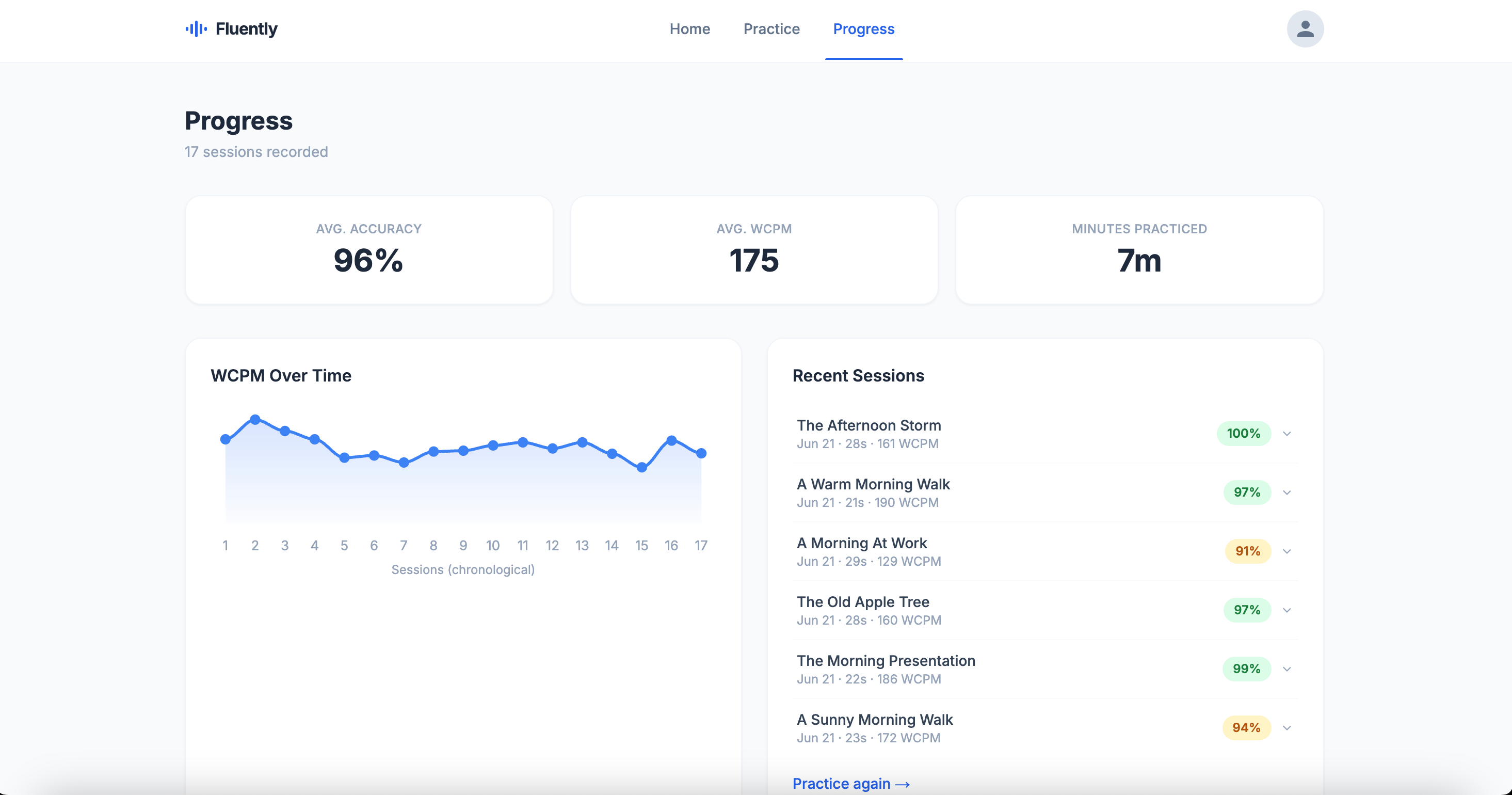
progress page
-
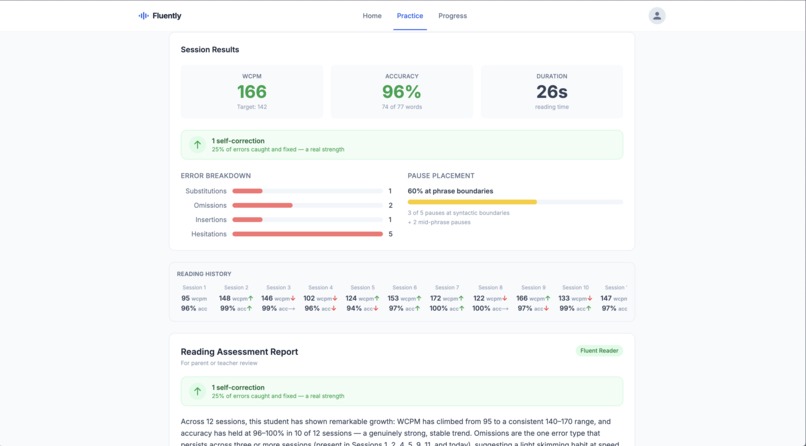
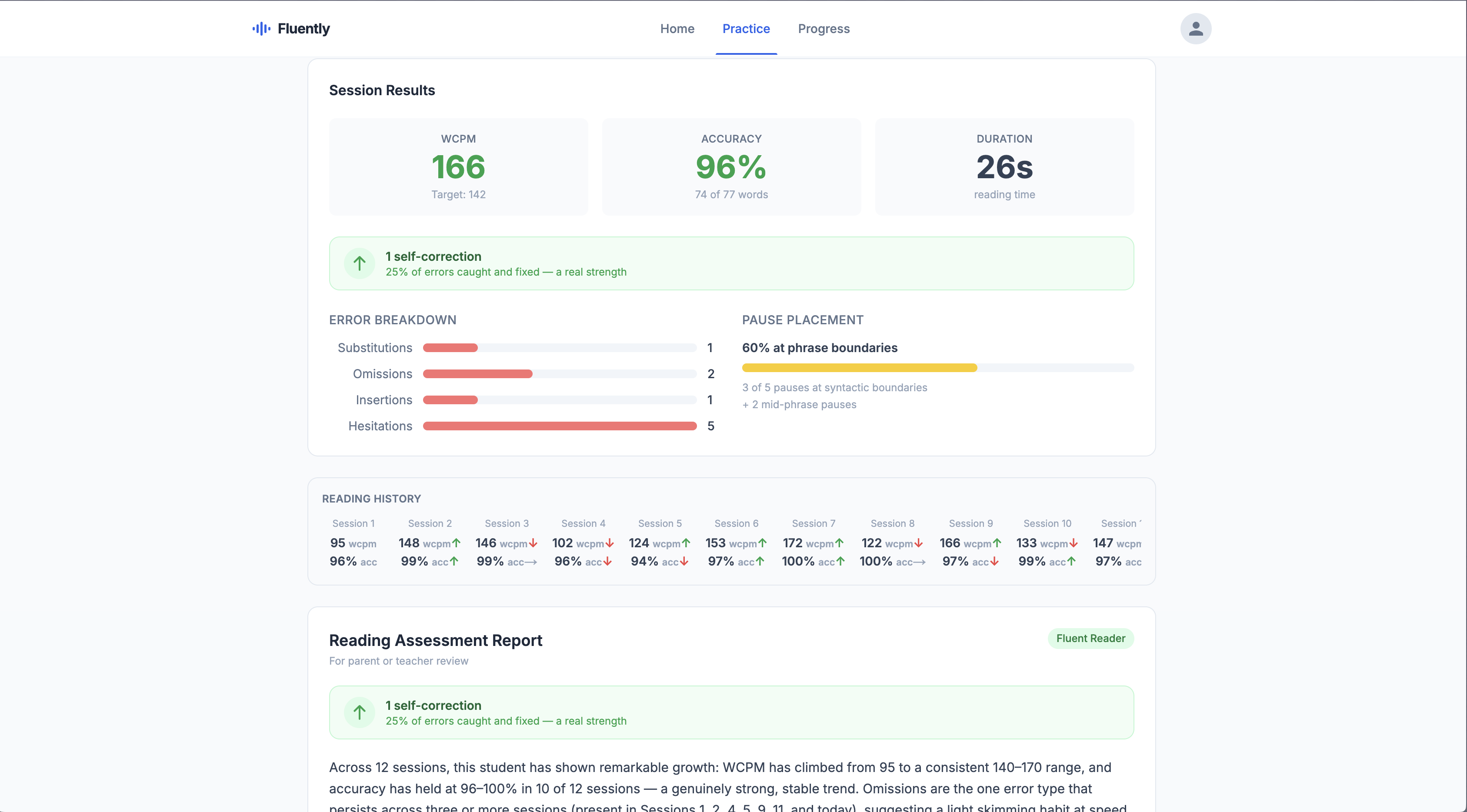
results page
Inspiration
Growing up, we had a family friend on the autism spectrum who struggled with reading and speaking aloud. We watched how much early intervention mattered for kids like him, and how much of that intervention depended on having access to the right specialists at the right time.
That gap stuck with us. When we started building Fluently, we wanted to create something that could do what a speaking specialist does. We aren't aiming to replace the human connection, but instead, make that level of precision accessible to every family, regardless of income or location.
The earlier a reading difficulty is caught and understood, the better the outcome. Fluently is built on that belief.
What it does
Fluently listens to your child read aloud and does what a reading/speaking specialist does, in real time.
A child reads a passage out loud. Every word lights up on screen: green if correct, red if an error, yellow if they hesitated. At the end of 60 seconds, Fluently produces a report that doesn't just count mistakes but explains what they mean. Is this a decoding issue or a phrasing fluency issue? These have different causes and different interventions, and most reading tools can't tell the difference.
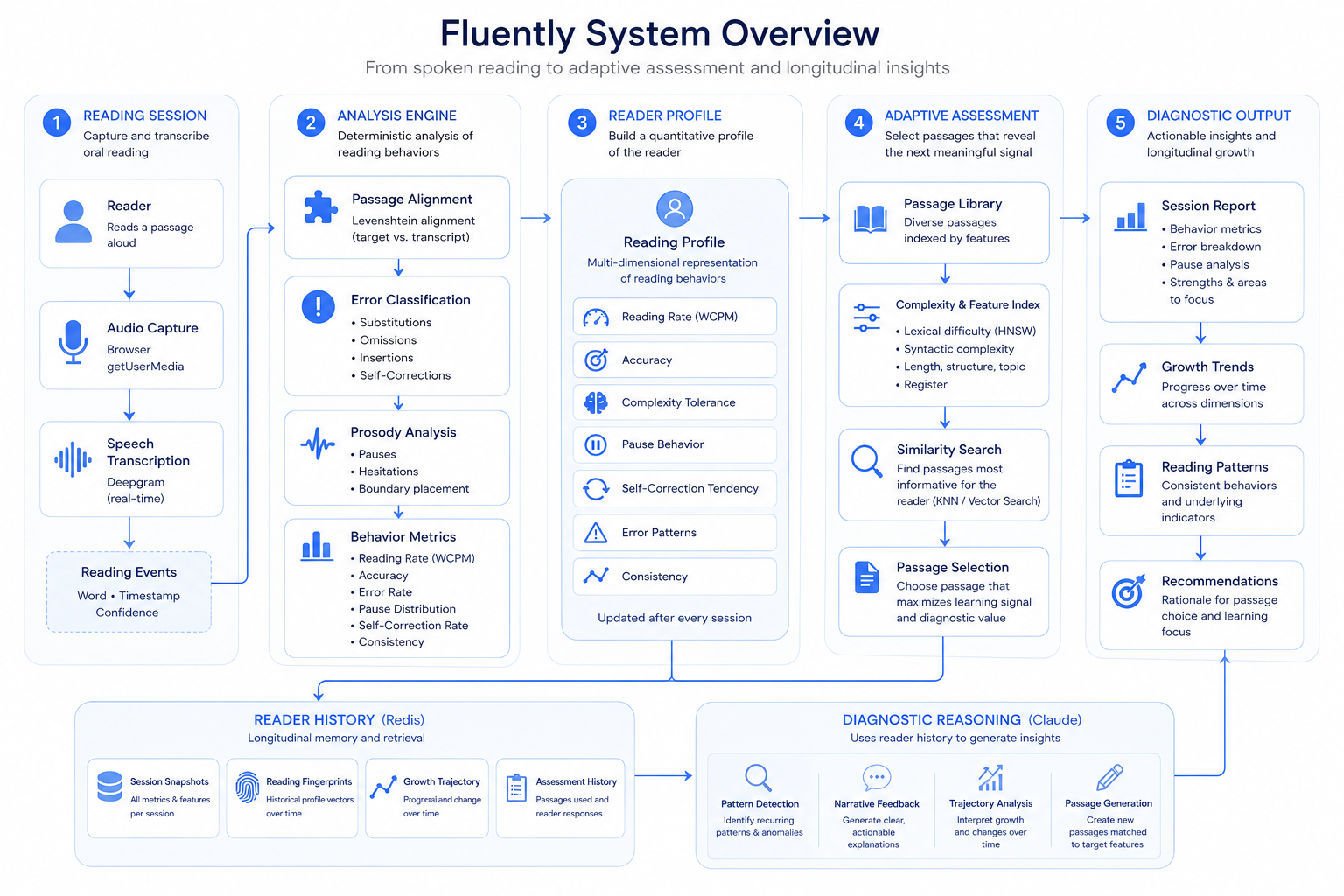
A 2D PassageMap lets you navigate material by complexity and register, with Claude generating fresh passages on demand. After each session, Redis vector search finds the optimal next passage based on where errors were concentrated, moving the reader harder in exactly the right dimension.
Over multiple sessions, Fluently builds a longitudinal model of the reader's error patterns, shifting from a snapshot of today to a genuine reading profile that gets sharper every session.
How we built it
Part 1: Deterministic pipeline
The scoring engine is fully deterministic and AI-free. Deepgram Nova-3 streams word objects with start, duration, and confidence fields. A custom Levenshtein alignment function matches the transcript against the expected passage word-by-word, classifying each word as correct, substitution, omission, insertion, hesitation (\(> 500\text{ms}\) pause), or acoustically uncertain (confidence \(< 0.75\), excluded from all error metrics to avoid penalizing accent variation). A separate metrics pass computes WCPM benchmarked against DIBELS 8th Edition grade-level thresholds (Grade 2: \(\geq 125\), Grade 4: \(\geq 141\), Grade 6: \(\geq 135\), accuracy threshold \(\geq 96\%\)), pause placement using compromise.js to identify syntactic boundaries in the target text, and self-correction rate as its own positive signal separate from the error taxonomy.
Part 2: AI layer
Claude receives a structured JSON object (never raw audio or transcript) and returns a plain-language report calibrated to the reader's DIBELS tier (intensive: at risk, strategic: some risk, core: on track), the passage's register (informal passages don't penalize contractions or casual phrasing), and any persisting error patterns across prior sessions. The prompt runs in one of three modes: snapshot (first session), comparison (second session), or pattern-recognition (third session onward), each with distinct framing language. In pattern-recognition mode, Claude receives a full markdown table of historical metrics and is explicitly instructed to re-read every number from the table rather than recall from context. This eliminated hallucinated historical values during testing.
Part 3: Redis AI integration
Every session stores a 5-dimensional skill vector
$$\mathbf{v} = [\text{complexityHandling},\ \text{registerHandling},\ \text{wcpmPercentile},\ \text{pausePlacementScore},\ \text{selfCorrectionRate}]$$
and full error metrics in Redis. After each session, computeNextTarget() identifies the weakest map-axis dimension (complexity or register only, since non-map dimensions like WCPM are addressed through Claude's exercise recommendations rather than passage movement) and computes the optimal next position in the 2D skill space. The target only escalates on an advance recommendation. On retry, the position stays fixed so the reader consolidates at the same level rather than compounding difficulty. A KNN search (FT.SEARCH) finds the nearest existing passage. If no close match exists within distance \(0.1\), Claude auto-generates a fresh passage at the exact target coordinates and stores it in Redis, growing the library organically with every session. The full reader history is fetched from Redis before every Claude call, enabling longitudinal pattern recognition across sessions.
Part 4: PassageMap
Instead of a grade picker, a draggable 2D SVG canvas lets users place a pin anywhere across the full K–adult complexity and casual–formal register space. Each pin placement calls Claude to generate a fresh ~70-word passage at those exact coordinates. After a session, a dashed blue arrow on the map shows where the recommendation moves the reader next, visually grounding the concept of "harder in the right dimension" in something a parent or child can immediately understand.
Challenges we ran into
Accent fairness A child who pronounces "th" as "d" should not have that counted as an error. We implemented confidence score filtering and switched to accent-agnostic English recognition, then found and fixed a subtle bug where uncertain words were excluded from error counts but still dragging down the accuracy denominator silently, penalizing the reader anyway through a different metric.
Longitudinal prompt hallucination In early testing, Claude would misstate historical WCPM values when given prior session data as prose. Switching to a structured markdown table with an explicit instruction to re-read every number from the table rather than recall from context eliminated the issue entirely.
Redis vector search projection When running KNN search against our passage index, the query was returning passage identifiers and titles as literal undefined strings. The issue was a subtle mismatch between which fields Redis indexes for search and which fields it actually returns in query results.
Accomplishments that we're proud of
- A fully deterministic scoring pipeline where Claude interprets but never detects
- Accent fairness built into the confidence filtering layer so no child is penalized for how they speak
- Redis powering genuine vector search across a 2D pedagogical skill space, not just caching
- Longitudinal error tracking that shifts Claude's diagnostic language after three sessions
What we learned
The most powerful thing you can do with an LLM is constrain what it has to guess. Every time we moved a computation out of Claude and into a deterministic function, the output got more reliable and the AI layer got more useful. Real equity has to be designed into the architecture, not added as an afterthought. Accent fairness required deliberate decisions at the data layer, not just the UI. And longitudinal context changes everything: a system that remembers is fundamentally different from one that scores.
What's next for Fluently
- Expanding to ESL adult learners with register-specific passage sets calibrated to workplace and academic English
- Support for speech therapy use cases including fluency disorders, apraxia, and progressive speech conditions like Huntington's disease, where tracking subtle degradation in prosody and phrasing over time could serve as an early clinical signal
- Difficulty regression on retry: backing off in the weak dimension before re-attempting, which is what reading specialists actually do
Built With
- anthropic
- compromise.js
- deepgram
- next.js
- redis
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.