-
-
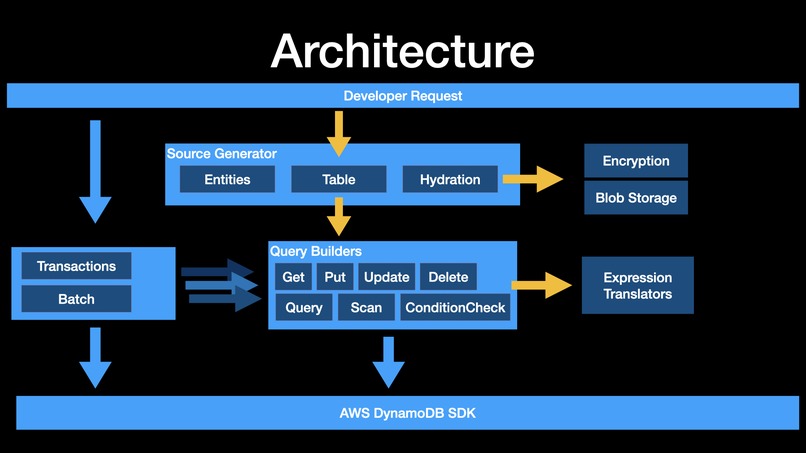
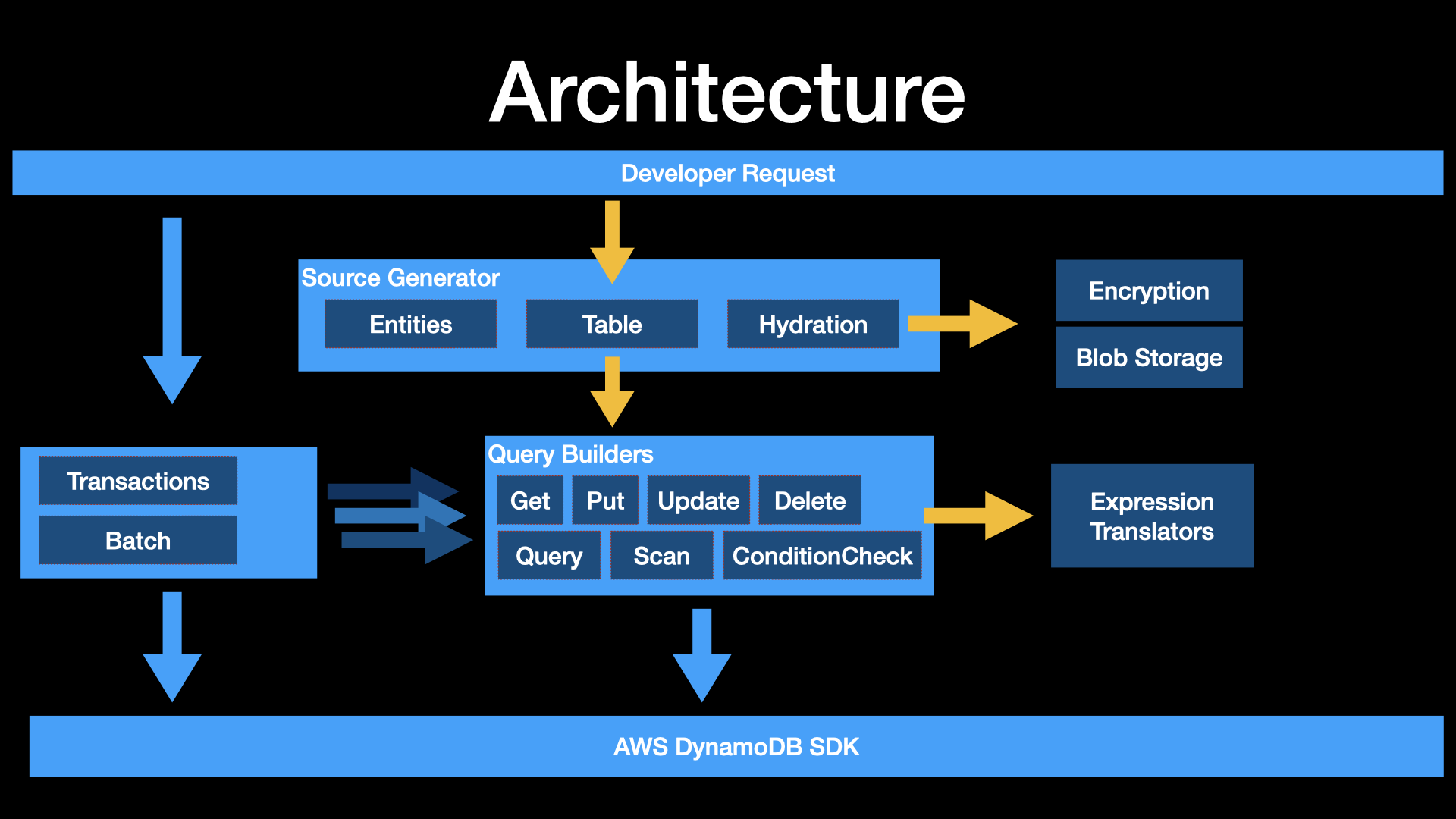
FluentDynamoDB Architecture
-
FluentDynamoDB Documentation Website
This project fits the Frankenstein category because it fuses together multiple complex and normally separate subsystems—source generation, expression parsing, encryption, S3-backed storage, DynamoDB modeling, stream processing, and three different geospatial indexing algorithms—into a unified, coherent ORM. These pieces rarely coexist in a single library, and bringing them together required significant architectural stitching and AI-assisted integration.
Inspiration
Working heavily with DynamoDB in real-world projects, I kept running into the same problems: tedious request construction, error-prone response parsing, large transactional workloads, and the lack of a clean API for advanced features like field-level encryption, geospatial queries, and single-table multi-entity designs. I wanted DynamoDB to feel as ergonomic and productive as a modern ORM, without sacrificing performance or control.
That became the vision for FluentDynamoDb: a fully featured, source-generated ORM designed to make DynamoDB development dramatically easier while still exposing the full power of the native SDK.
What It Does
FluentDynamoDb provides a fluent, strongly typed API for building requests, executing transactions, handling encryption, performing batch operations, and materializing complex entity graphs from a single-table design. The library includes:
- Strongly typed request builders with full IntelliSense
- Single-table multi-entity mapping (e.g., Invoice + Lines + Status in one query)
- Field-level encryption backed by AWS KMS
- Blob offloading to S3
- GeoHash, S2, and H3 support for efficient geospatial queries
- Batch operations and transactional helpers
- Support for consuming DynamoDB Streams
- Full source-generation (no reflection, AoT-friendly)
- Thousands of unit, property-based, and integration tests
The goal is to reduce DynamoDB boilerplate by 20–50× and give developers a more expressive, safer programming model, while keeping the library lightweight and close to the metal.
How I Built It
The project was built almost entirely inside the Kiro IDE using a spec-driven workflow. Across November I created 37+ detailed specs—many thousands of lines long—covering:
- Request/response builders
- Key extraction and partitioning logic
- Encryption/decryption pipelines
- S2/H3 geospatial indexing
- Source-generator structure
- Batch and transaction abstractions
- Documentation and example apps
Kiro handled low-level scaffolding, repetitive patterns, refactors, code cleanup, and complex debugging sessions—especially around geospatial math and source-generation edge cases. I combined this with human oversight, manual steering, and targeted adjustments to ensure correctness and maintainability.
About the Demo Video
Because FluentDynamoDb is such a large, multi-subsystem project, the demo video could only cover a very small portion of the actual features. The library includes hundreds of APIs, deeply integrated subsystems, and a large source-generator architecture that simply can’t be demonstrated meaningfully in a short walkthrough. The video focuses on the core ideas, but the real depth is visible in the repository’s source code, tests, and documentation.
Challenges I Ran Into
- Designing a full ORM without hiding DynamoDB’s flexibility
- Implementing S2/H3 geospatial search with correct cell-covering math
- Keeping everything AoT-safe and reflection-free
- Making encryption, batching, transactions, and streams all play nicely together
- Evolving the API while maintaining a very large test suite
The hardest part was orchestrating so many moving pieces while keeping the public API simple and intuitive—exactly where Kiro’s assistance was most valuable.
What I Learned
This project reinforced how powerful spec-driven development is when paired with intelligent code generation. I learned:
- How to iteratively refine a large architecture using specs
- How to use steering docs to keep Kiro aligned on complex designs
- How much time can be saved when an IDE can reason about patterns at scale
- How to balance ergonomics with the realities of a low-level, performance-sensitive SDK
What’s Next
The roadmap immediately after the hackathon includes:
- Publishing FluentDynamoDb 1.0 as a public NuGet package by 12/31/2025
- Tightening the API surface to reduce manually specified generics
- Redesigning FluentResults integration so it covers the modern API consistently
- Migrating KMS encryption to the newer
AWS.Cryptography.EncryptionSDKpackage and integrating it cleanly into the existing pipelines - Expanding the documentation and tutorials at FluentDynamoDb.dev (currently live with initial content and being filled in)
The long-term goal is to make DynamoDB development dramatically more accessible and productive for .NET teams building on AWS.
Built With
- amazon-web-services
- clearthought
- context7
- csharp
- dotnet8
- dynamodb
- kiro
- kms
- lambda
- s3
- sourcegenerators

Log in or sign up for Devpost to join the conversation.