




Inspiration
We realized that millions of intermediate English learners are stuck in a "passive" loop. They have the vocabulary to pass a test, but they lack the spoken confidence to seize real-world opportunities—like job interviews, presentations, or international travel.
We wanted to build a tool that bridges the gap between knowing English and using it. FluencyPath was born from the idea that learners don't need more grammar drills; they need a safe space to fail and improve. We built this to be a "daily confidence coach" that turns vague ambitions into measurable, spoken progress.
What it does
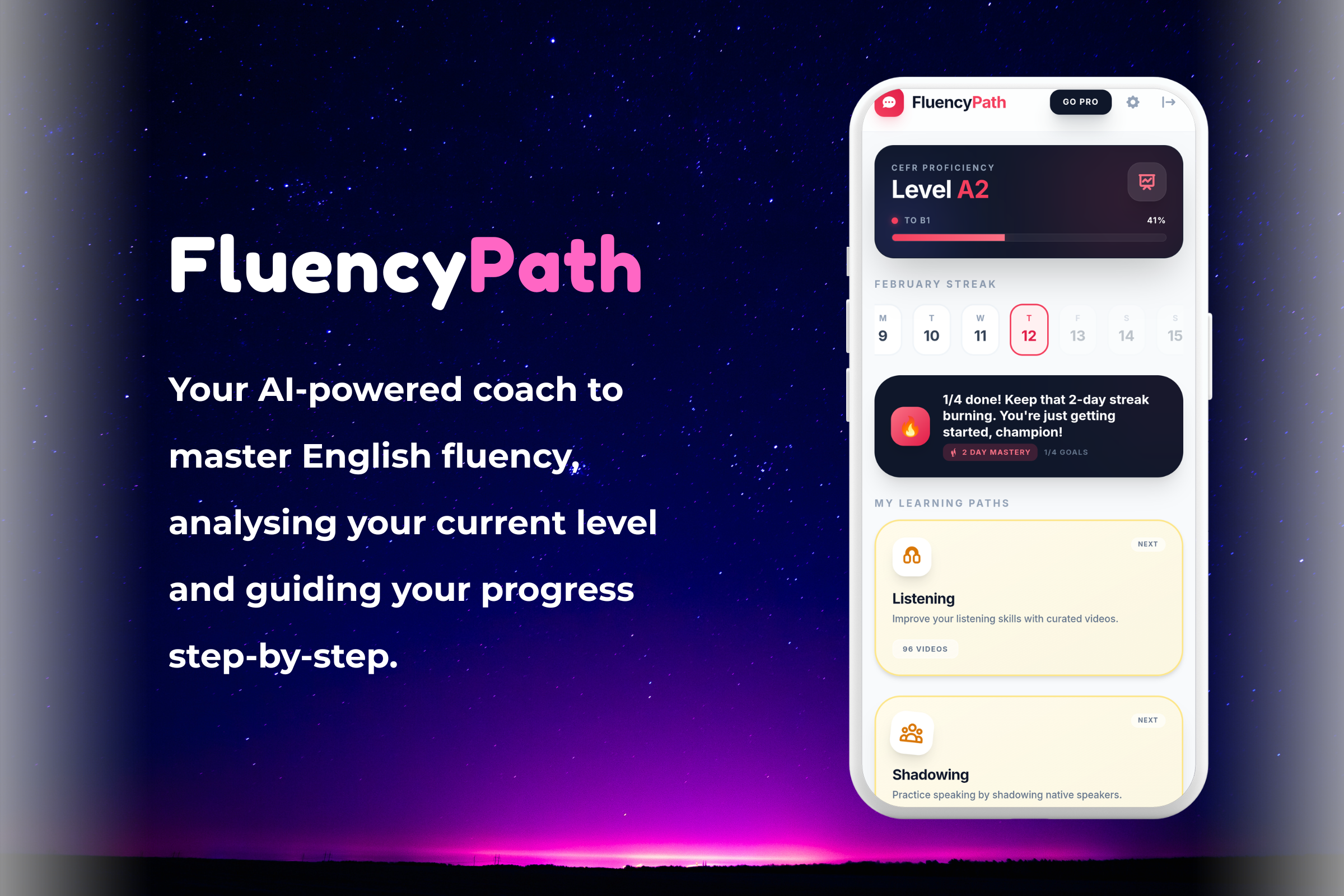
FluencyPath is an AI-powered shadowing platform that transforms passive listening into active speaking. It solves the "Intermediate Plateau" by focusing on delivery and confidence, not just vocabulary.
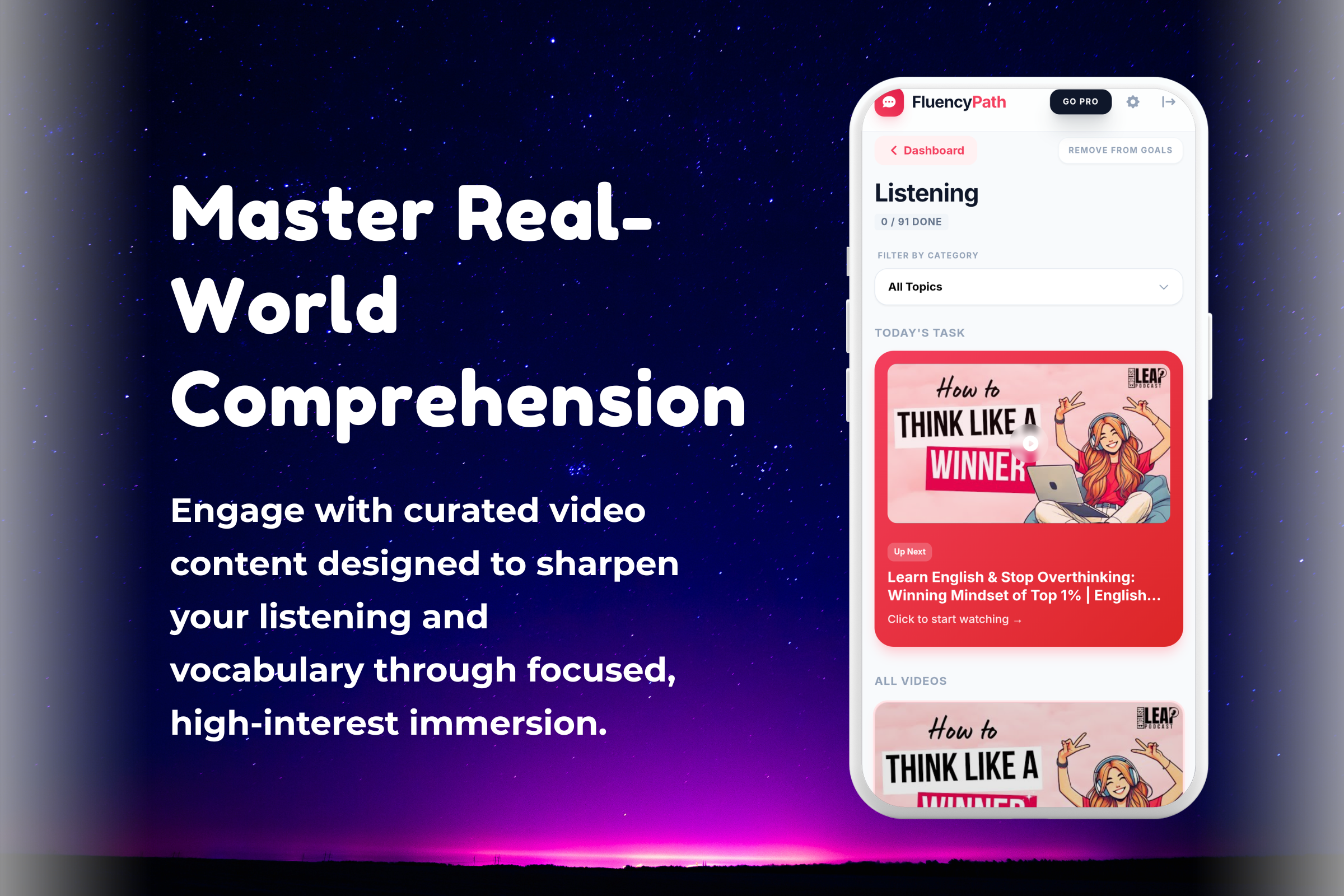
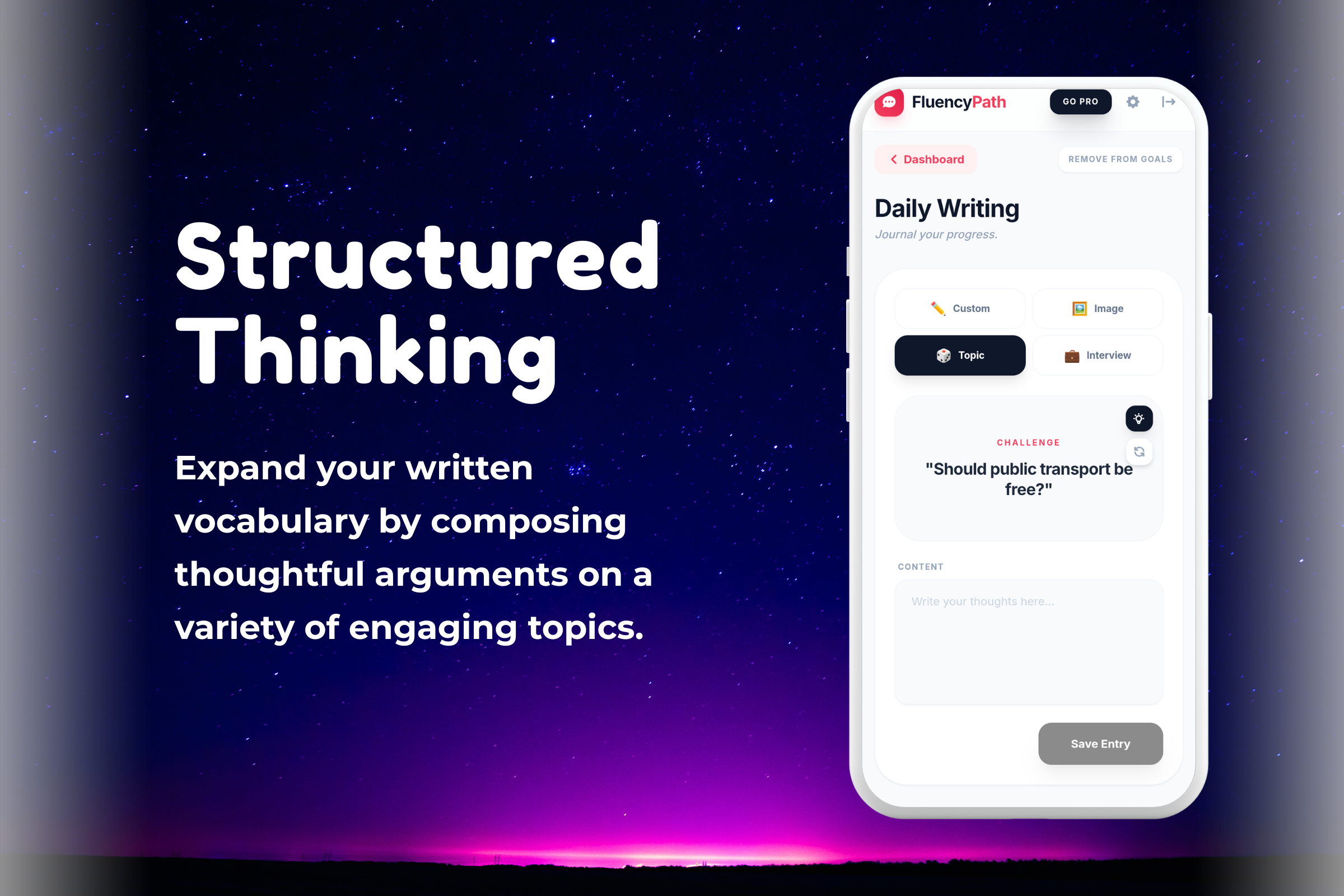
- Active Shadowing: Users listen to native-level clips (interviews, business pitches, casual chats) and record themselves mimicking the speaker.
- AI Confidence Feedback: Our Gemini-powered engine analyzes the user's audio for intonation, speed, and clarity, providing instant feedback on how "natural" they sound compared to the native speaker.
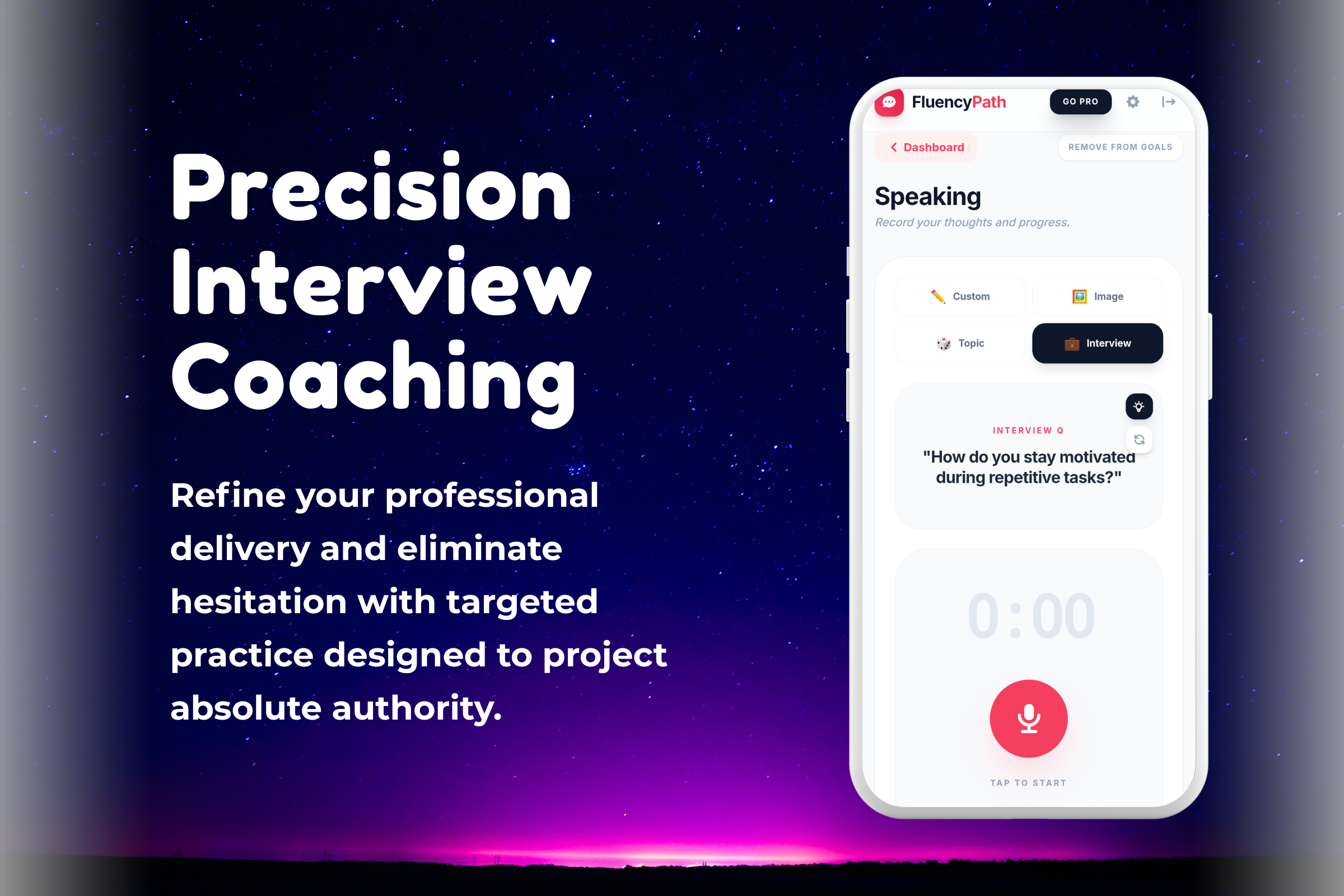
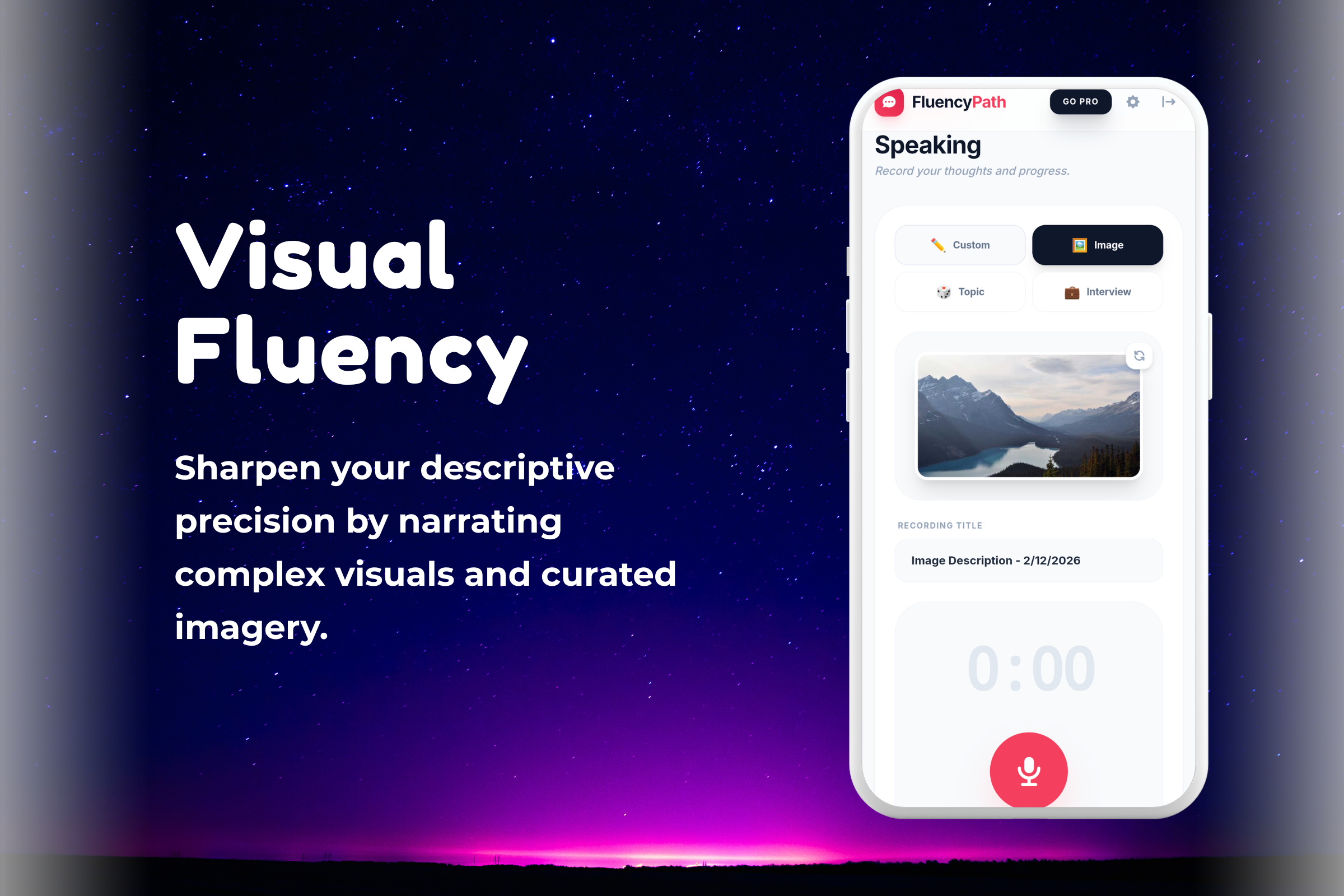
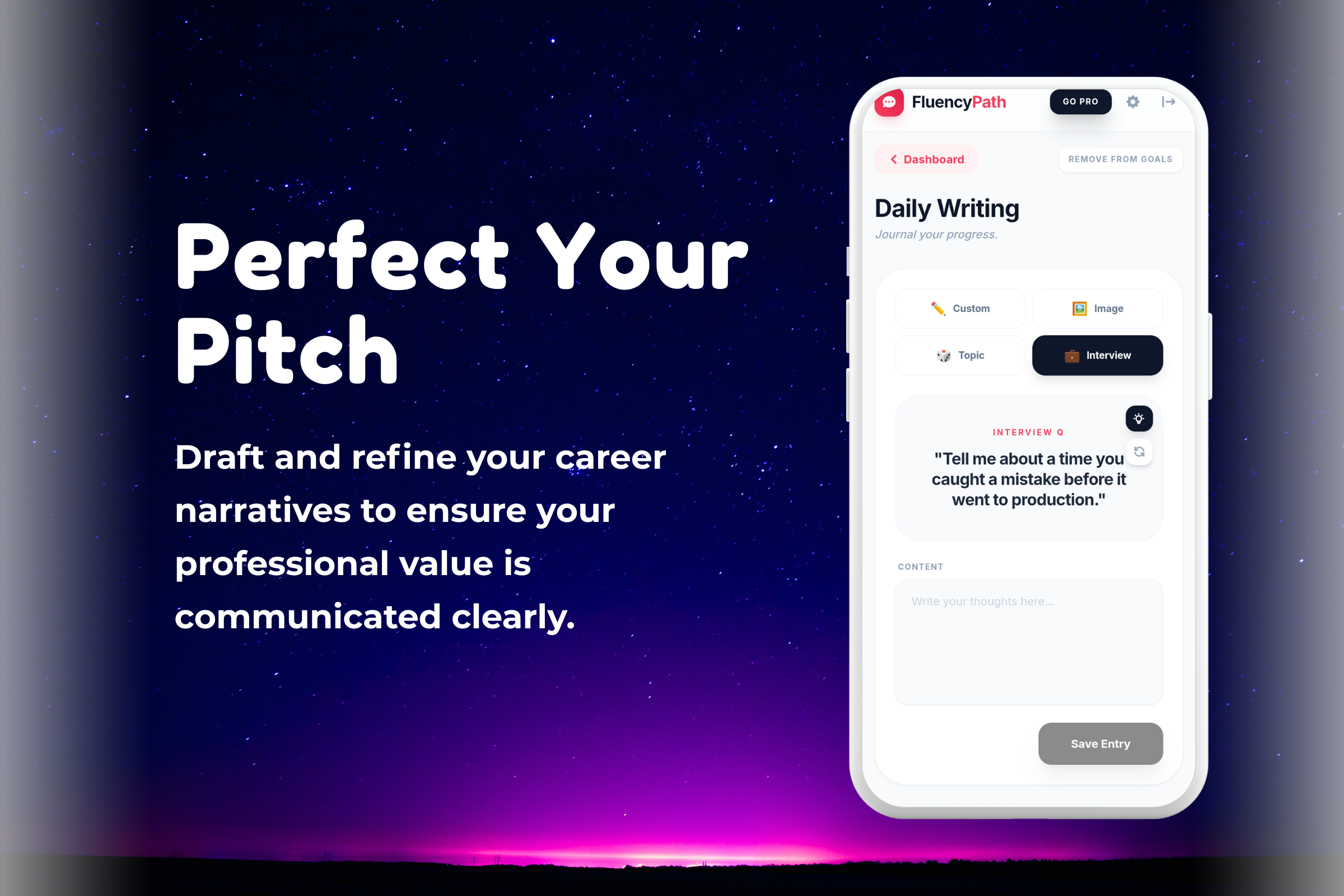
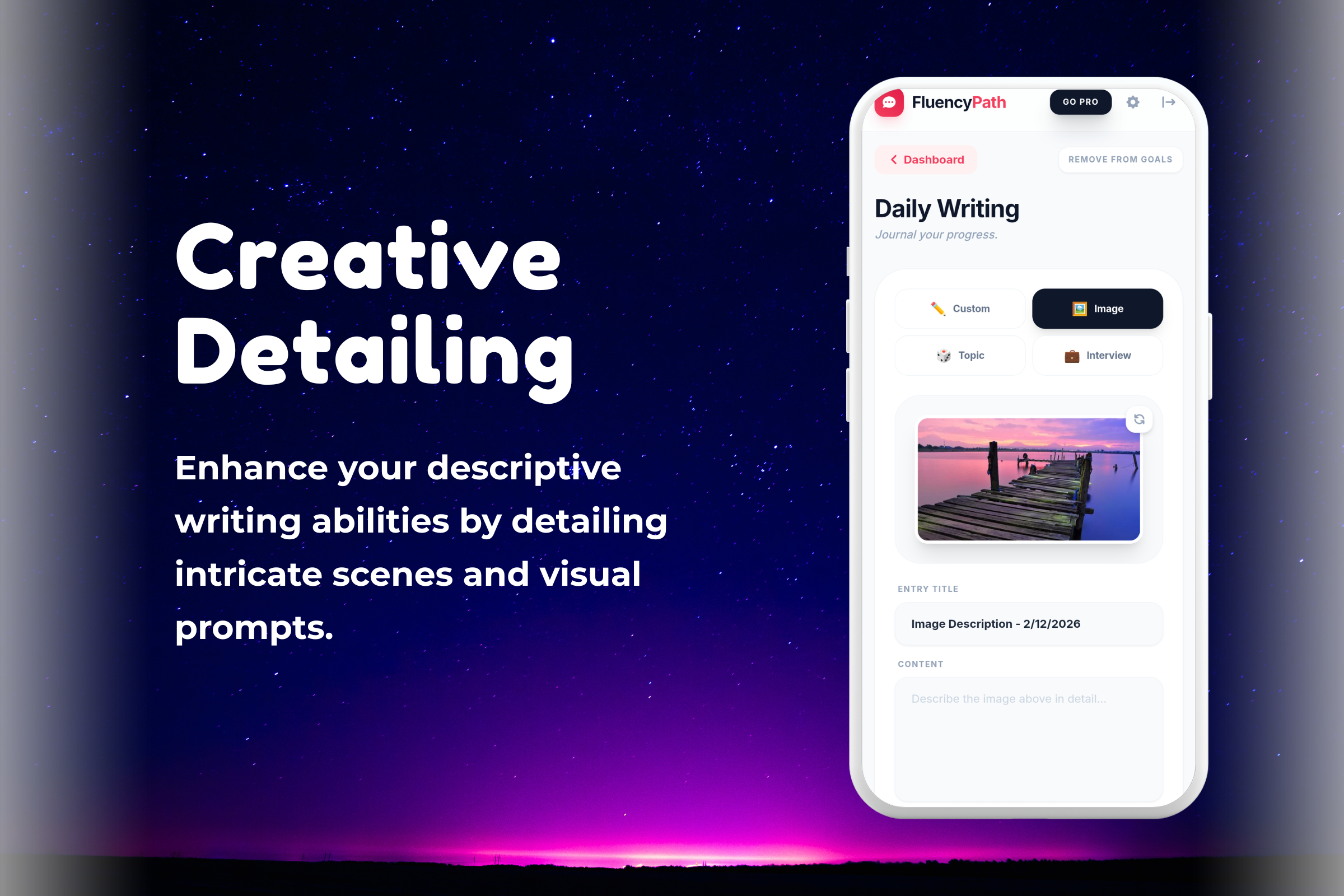
- Real-World Scenarios: Instead of abstract sentences, users practice high-stakes scenarios: "Answering 'Tell me about yourself'," "Ordering coffee in a busy cafe," or "Leading a Zoom meeting."
- The "Action Loop": We use a streak and reward system to encourage daily "micro-actions," helping users build the muscle memory required for fluent speech.
How we built it
We engineered FluencyPath to be fast, responsive, and distraction-free.
- Frontend: Built with React and Tailwind CSS for a clean, focus-driven interface that works seamlessly on mobile and desktop.
- Backend: A Node.js server handles secure API requests and user data management.
- AI Engine: We integrated the Google Gemini API (multimodal) to act as the core "coach." It processes user audio and text inputs to provide nuanced, CEFR-aligned feedback that goes beyond simple spell-checking.
- Data & Visualization: User progress and recordings are stored in Google Firestore. We built custom data visualization components to render "Confidence Charts," giving users a tangible view of their improvement over time.
Challenges we ran into
Quantifying "Confidence" with AI: The biggest technical hurdle was defining what "fluency" actually looks like in data. It’s easy to check if a word is correct, but harder to check if it was said confidently. We had to iteratively fine-tune our Gemini prompts to analyze prosody (rhythm and stress) and pacing, ensuring the feedback felt helpful and human, not robotic or overly critical.
Audio recording is not working right now. Due to the limitation of time, I focused on other parts.
Accomplishments that we're proud of
- The Feedback Loop: We successfully created a system where a user can record, get feedback, and retry in under 30 seconds—creating a tight, addictive learning loop.
- Visualizing the Invisible: We built a "Confidence Score" metric that gives users a concrete number to aim for, gamifying the otherwise subjective process of language learning.
- Real-Time Processing: Achieving low-latency feedback so the conversation feels fluid, maintaining the user's momentum.
What we learned
- Action > Theory: We learned that users improve faster when they are forced to speak immediately, rather than watching a tutorial first.
- The "Safe Space" Factor: Users are willing to make mistakes with an AI that they would be too embarrassed to make with a human tutor. This "judgment-free zone" is our key value proposition.
- Prompt Engineering is Key: The personality of the AI coach matters. Tweaking the prompt to be "encouraging but firm" drastically changed user engagement.
What's next for FluencyPath
- Live AI Roleplay: Moving from asynchronous recordings to real-time, voice-to-voice conversations with an AI interviewer.
- Community Challenges: Introducing "Cohort Mode" where groups of friends can compete on "Speaking Streaks" together.
- Video Analysis: Using multimodal AI to analyze non-verbal cues (eye contact, posture) during mock interview sessions.
Built With
- android-(java/kotlin)
- capacitor
- express.js
- firebase-firestore
- google-gemini-ai-api
- ios-(swift)
- json-server
- node.js
- react
- revenuecat-api
- tailwind-css
- typescript
- vercel
- vite
- youtube-iframe-api

Log in or sign up for Devpost to join the conversation.