-
-
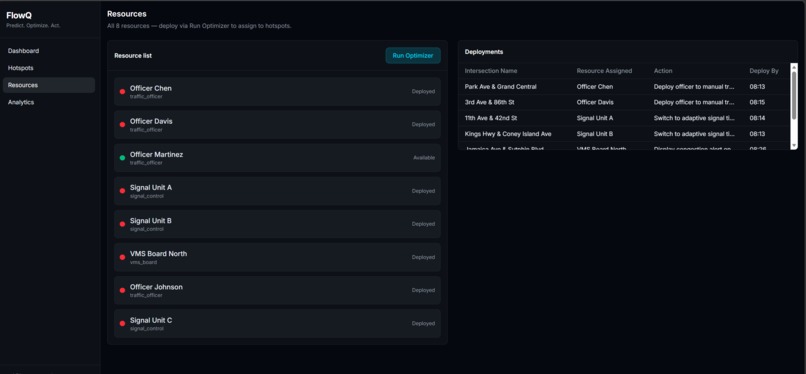
resources
-
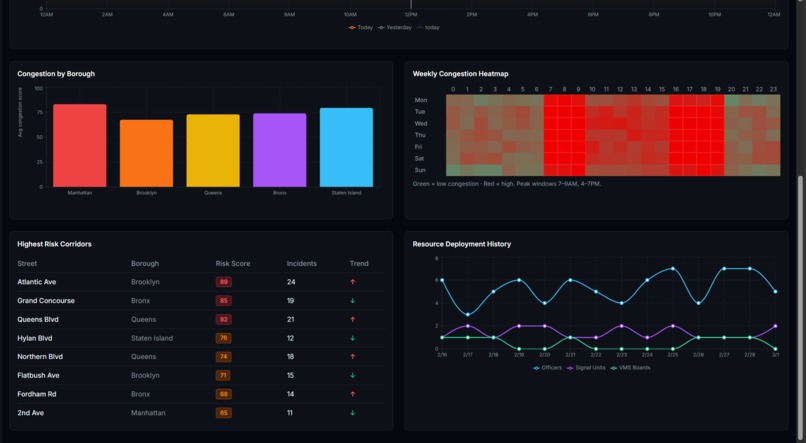
Analysis
-
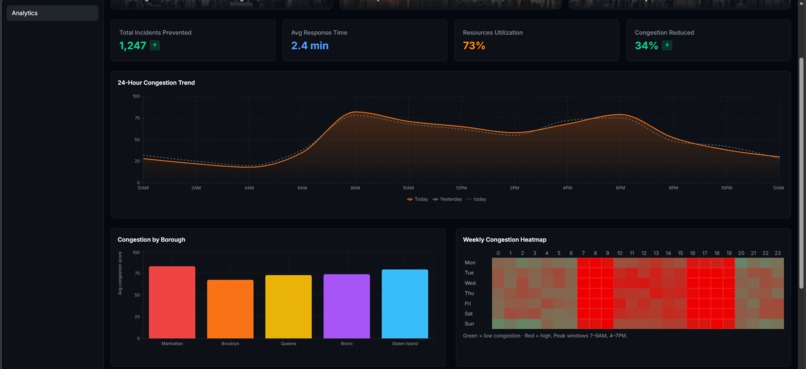
Analysis of traffic data
-
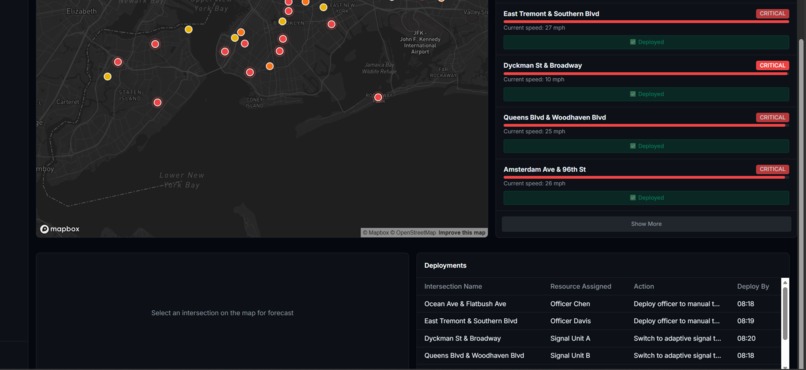
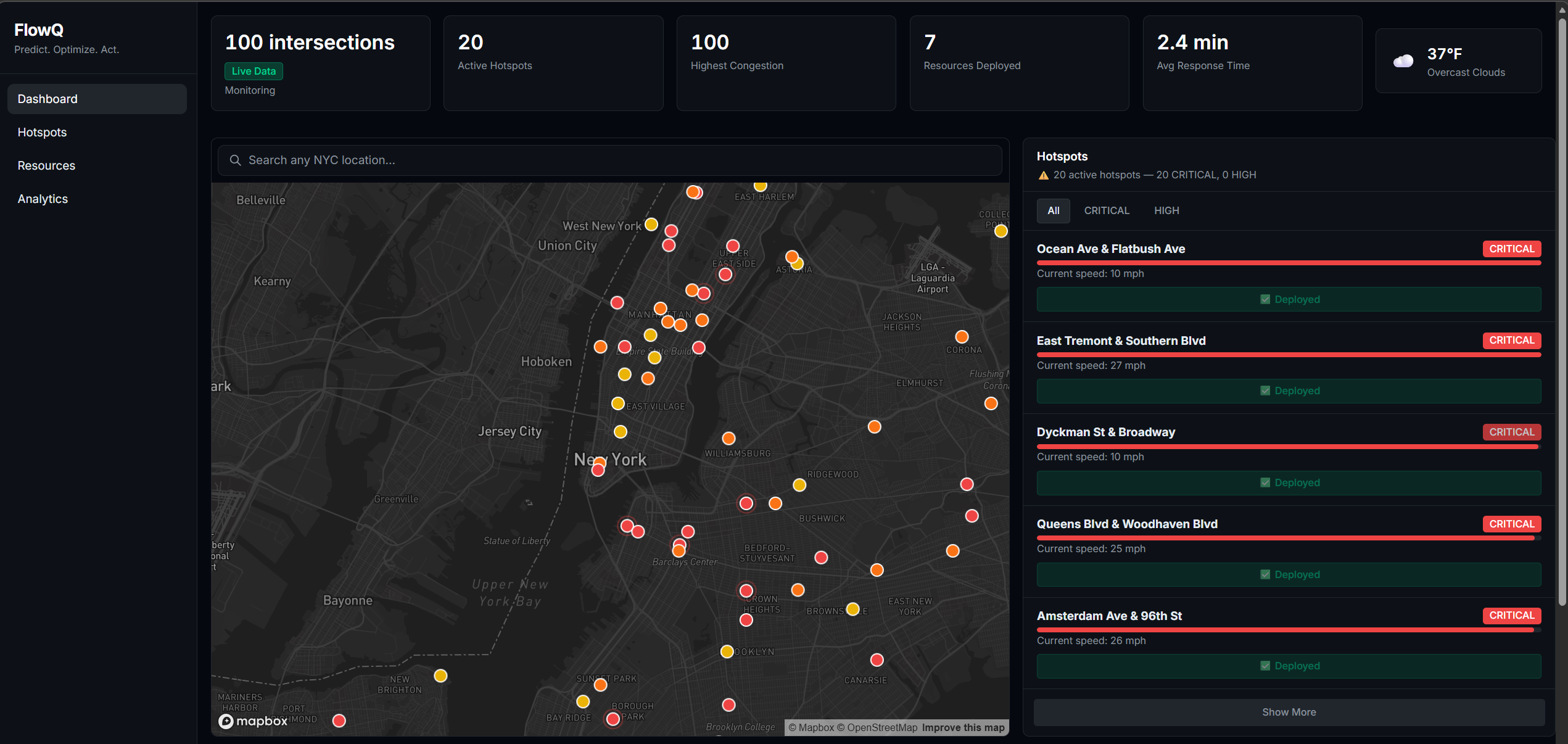
Dashbaord
-
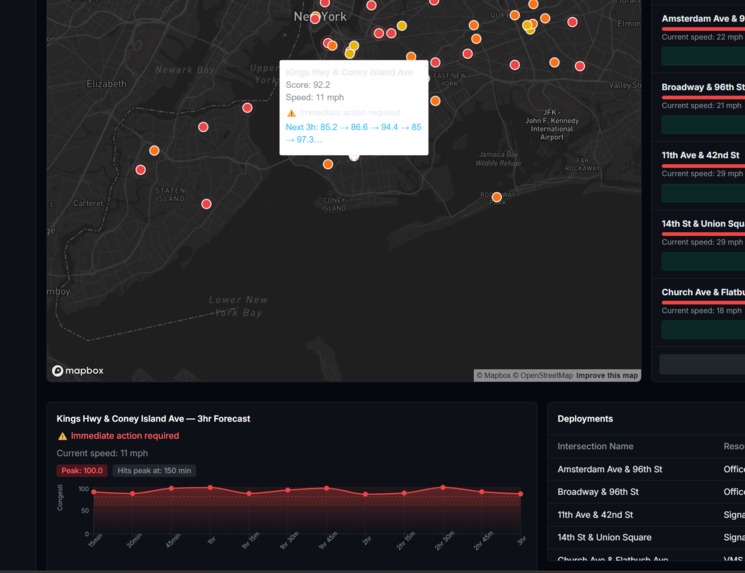
DashBaord with prediction
-
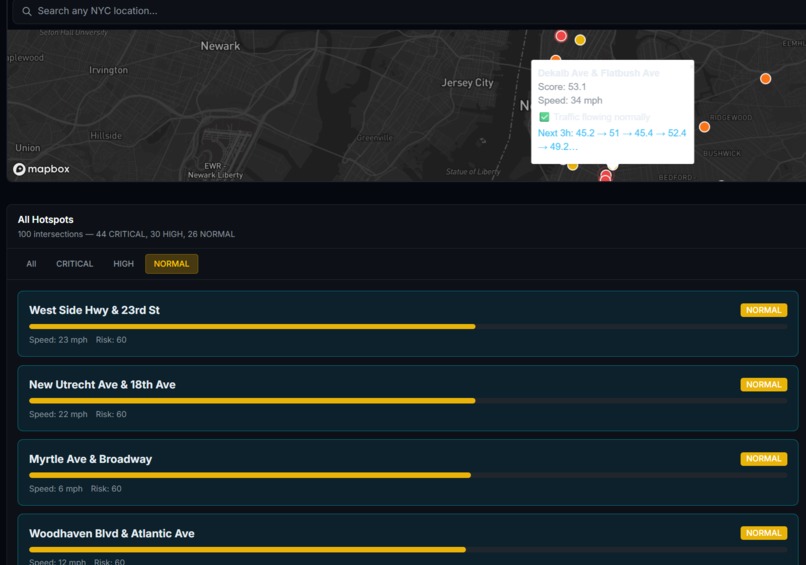
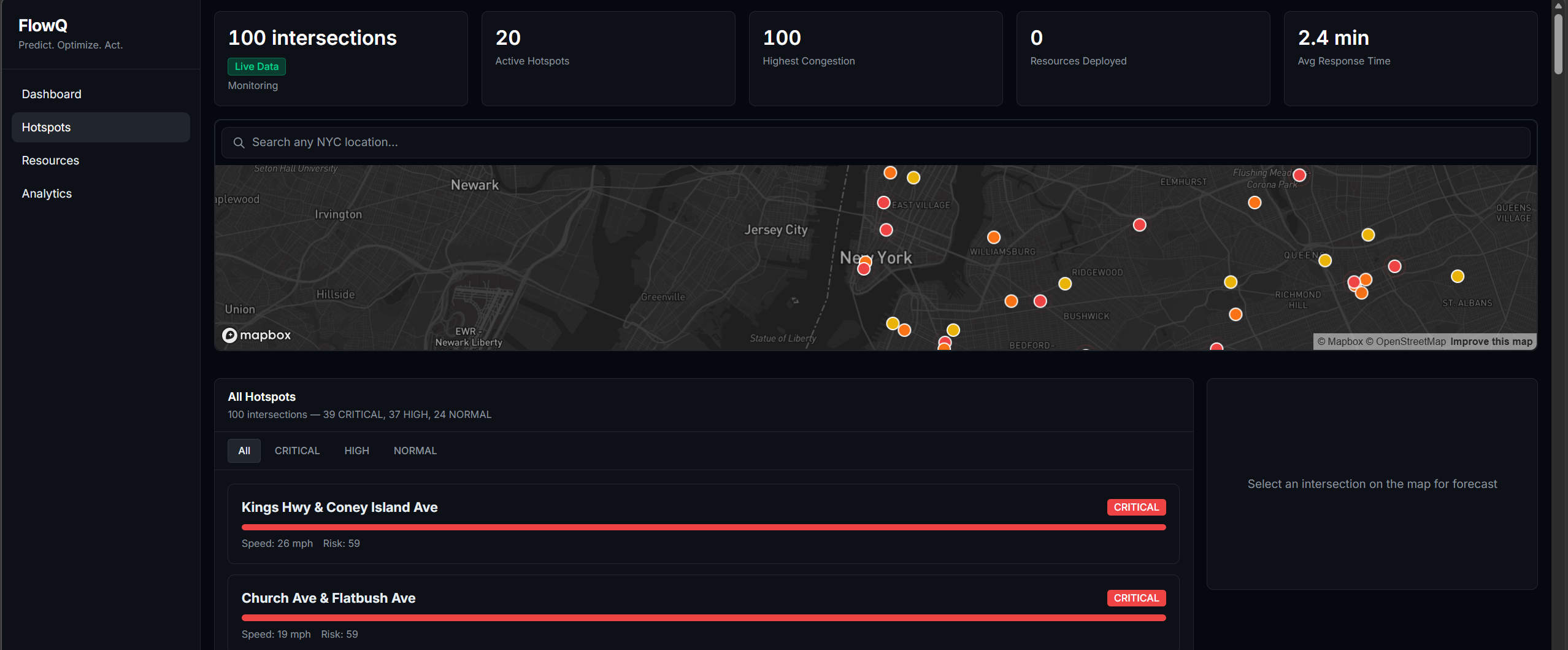
hotspots with normal traffic
-
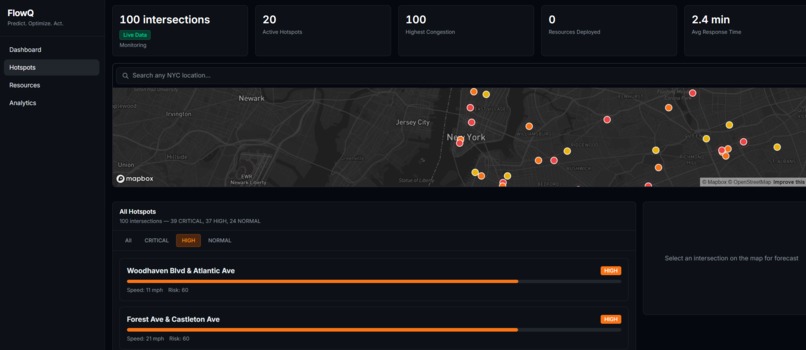
hotspots with medium traffic
-
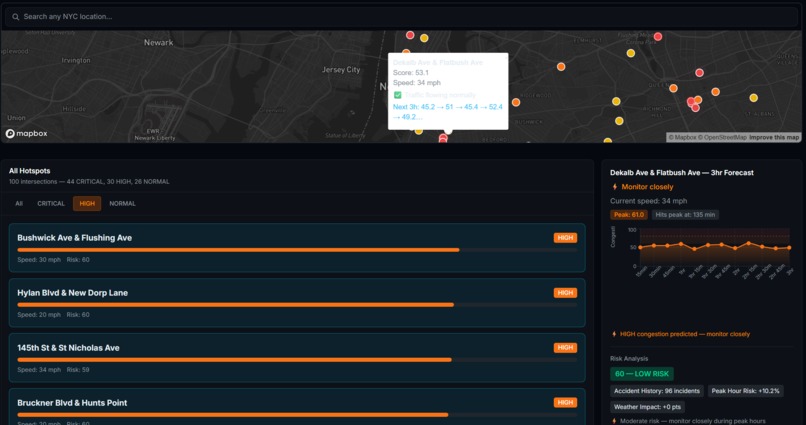
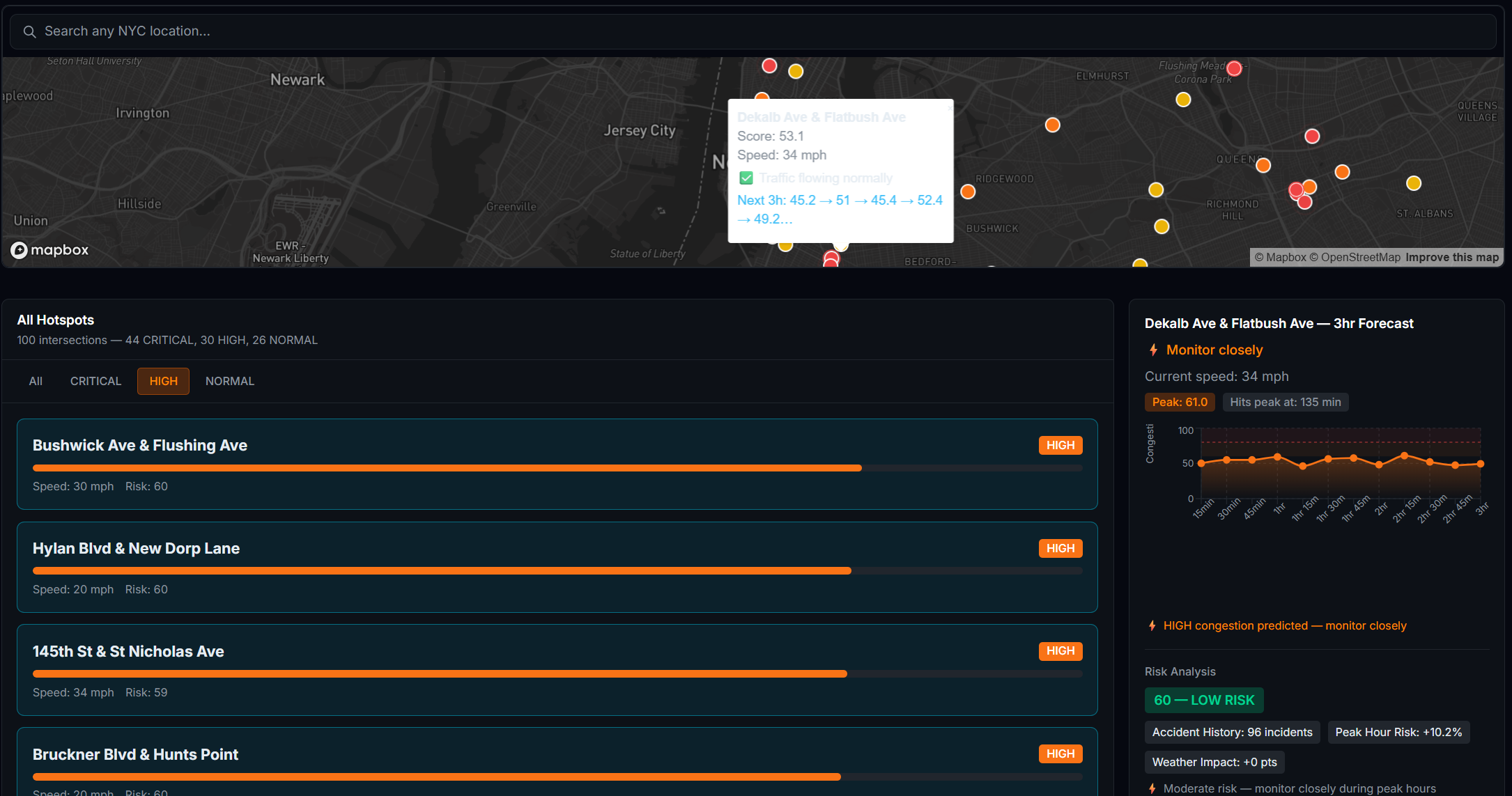
hotspots with medium traffic and prediction
-
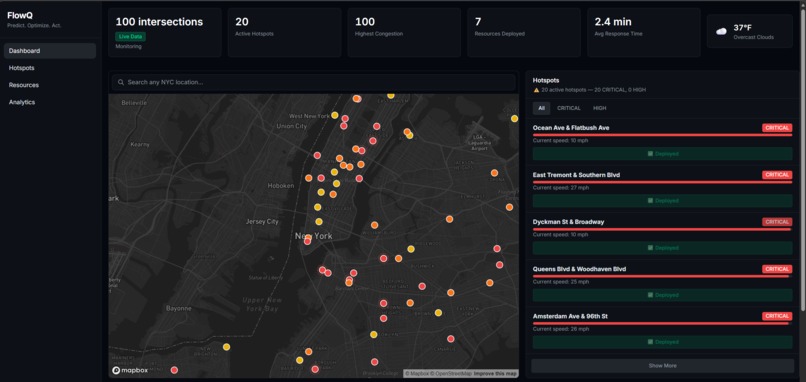
Dashboad
-
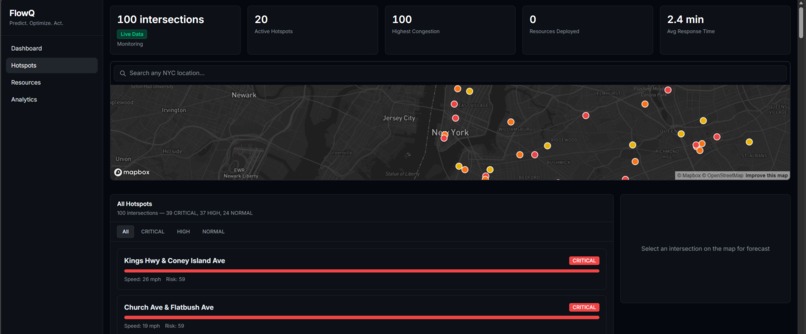
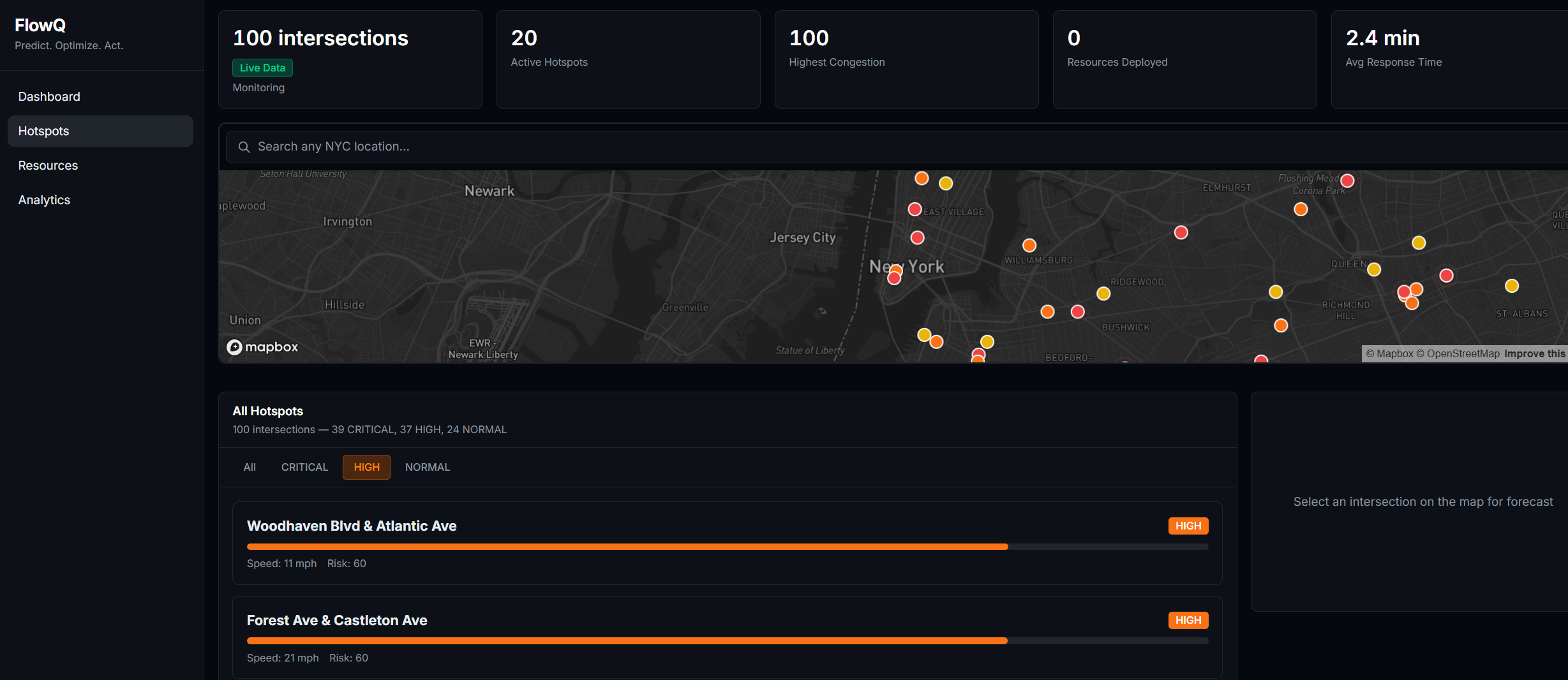
Hotspots
FlowIQ — Predictive City Traffic Intelligence Inspiration While researching urban mobility problems online, I kept coming across the same issue across cities worldwide — traffic congestion costs billions of dollars annually and wastes hundreds of hours of people's lives every year. What struck me wasn't just the scale of the problem, it was how preventable it seemed. Cities already collect live traffic speed data. The bottleneck isn't the data — it's that nobody has built a system to predict what happens next and act on it automatically. That gap is what FlowIQ tries to close. The goal was to build something city-agnostic — a platform that any city can plug into by swapping the intersection list and connecting their local data sources.
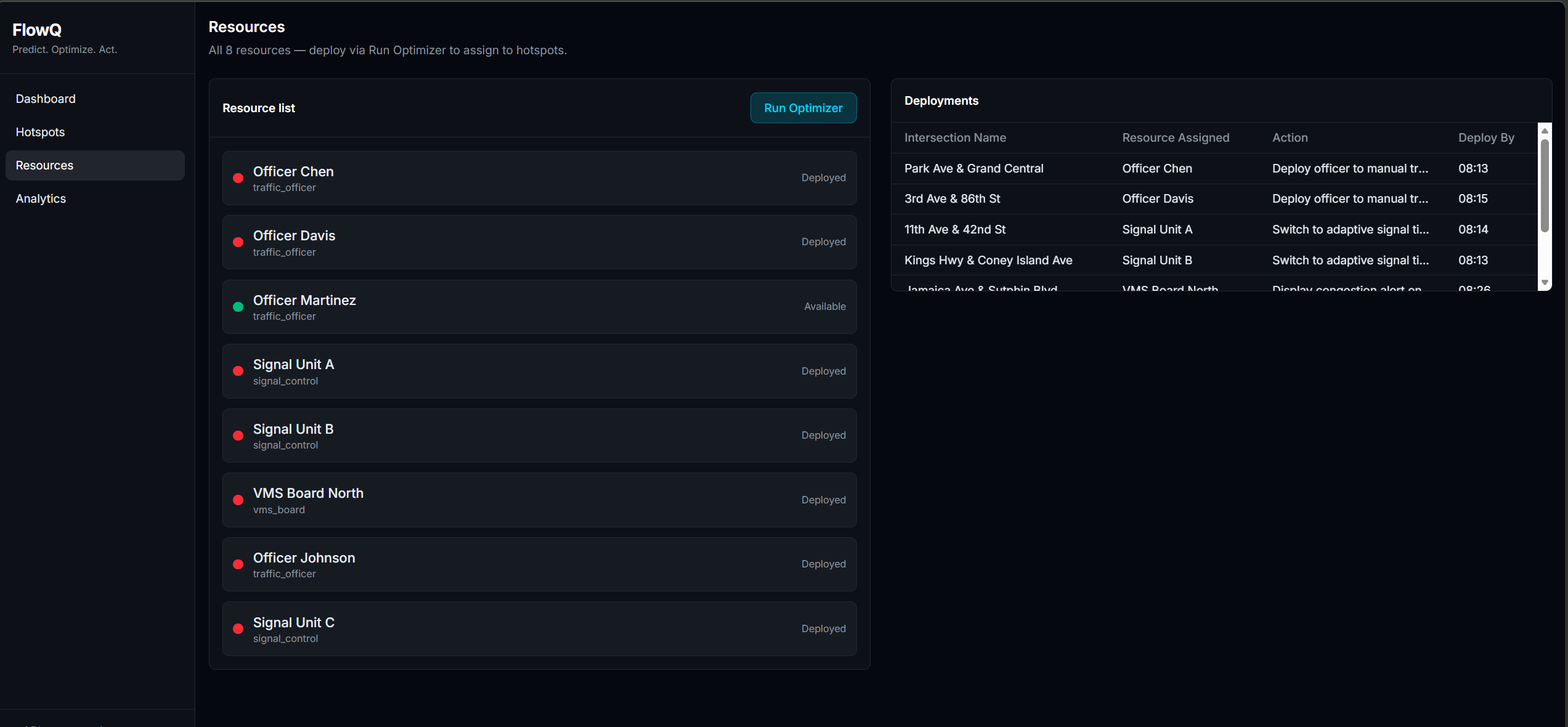
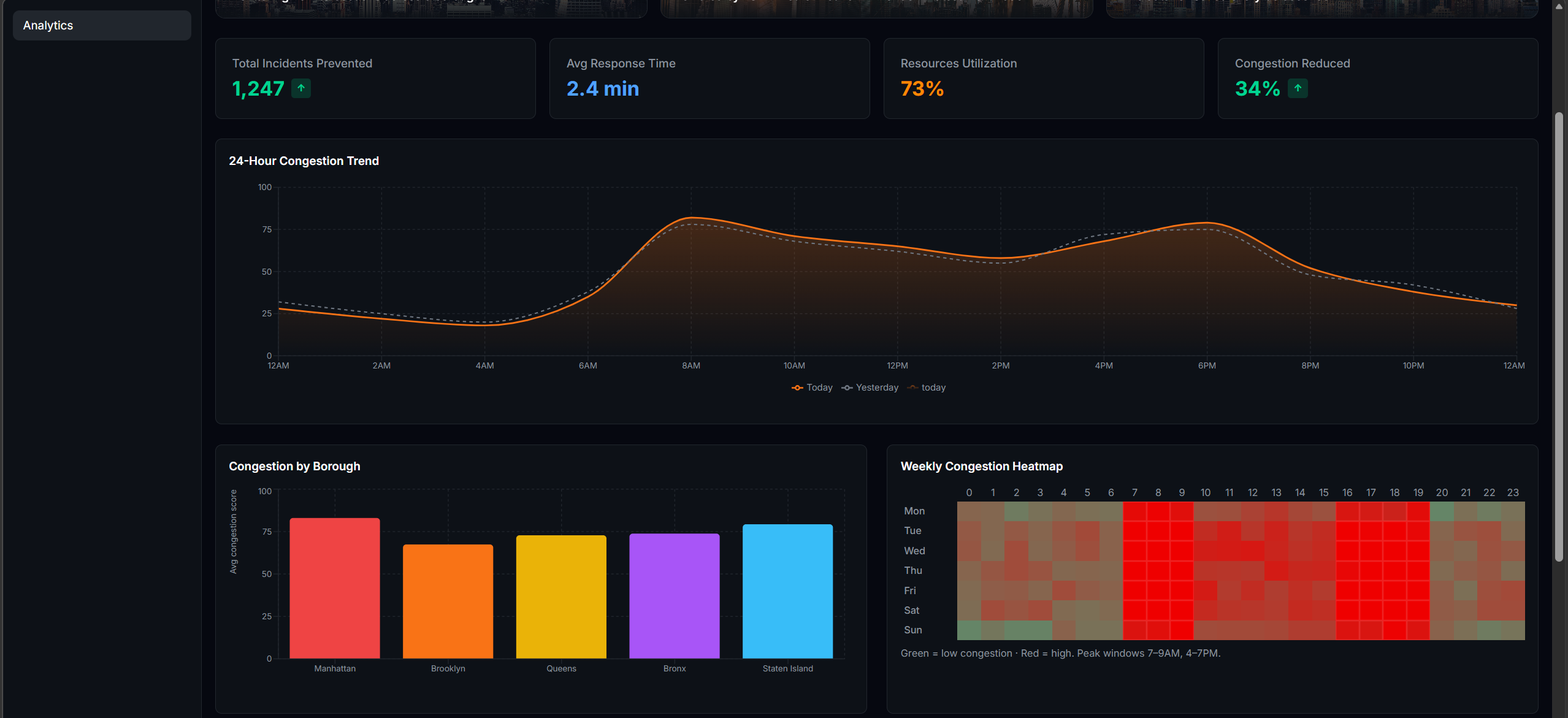
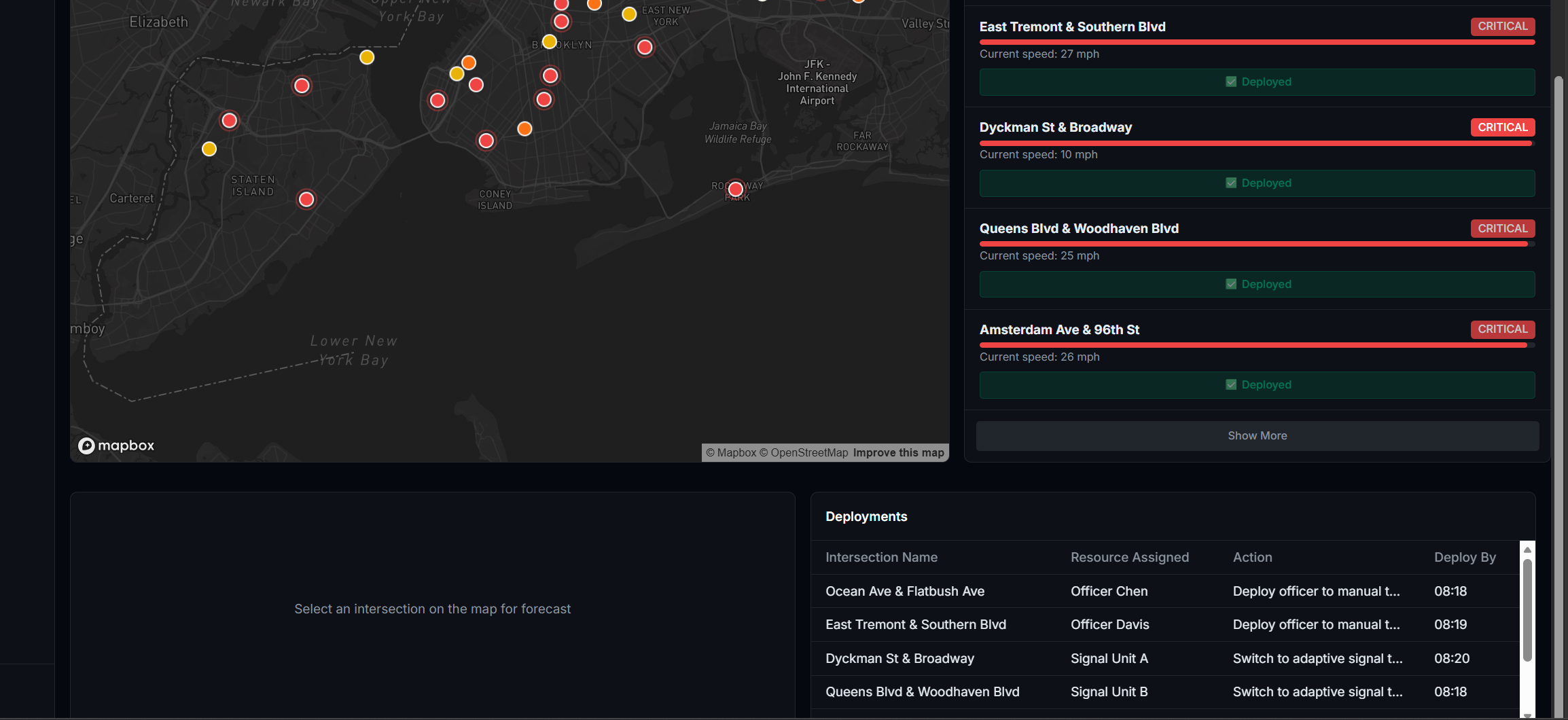
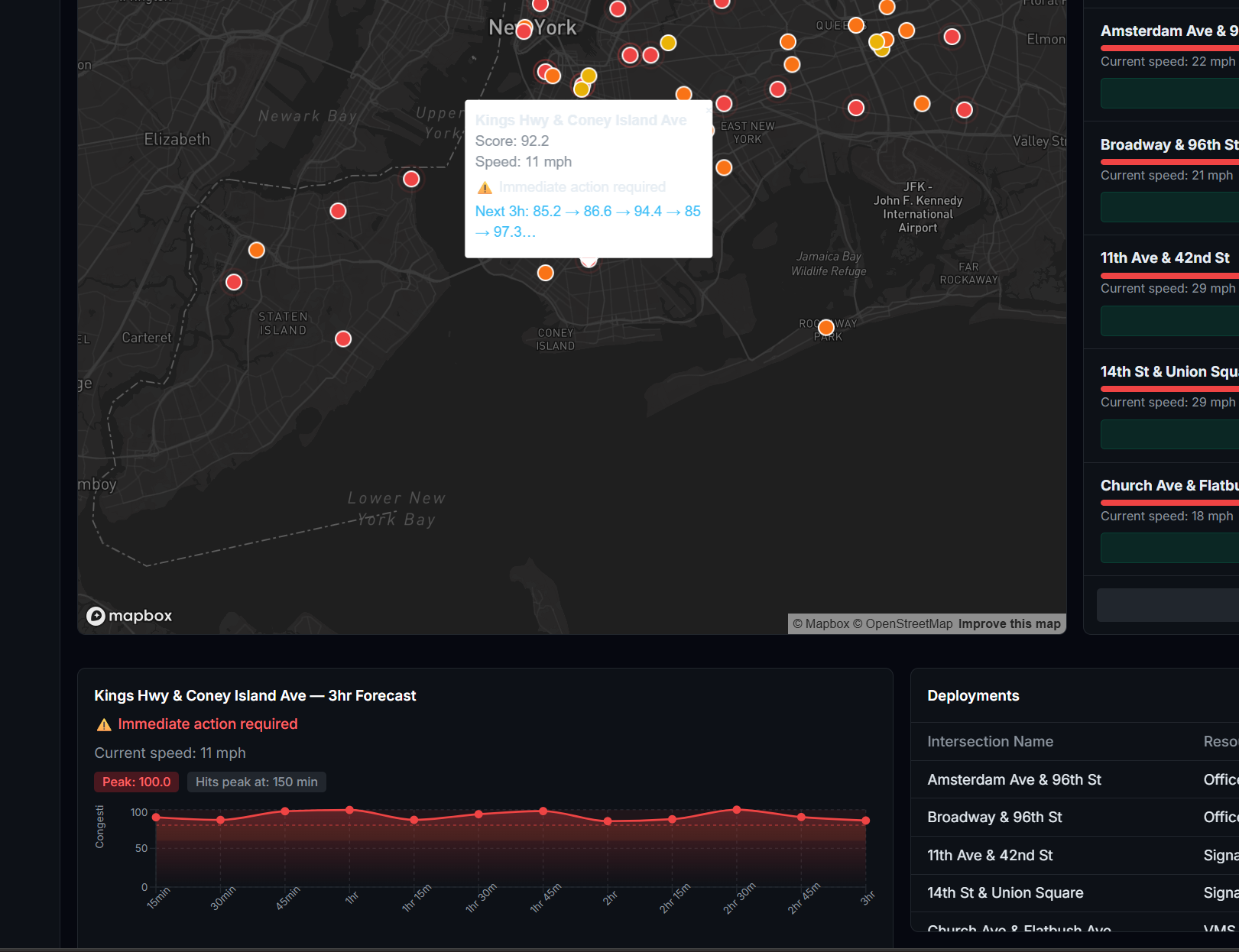
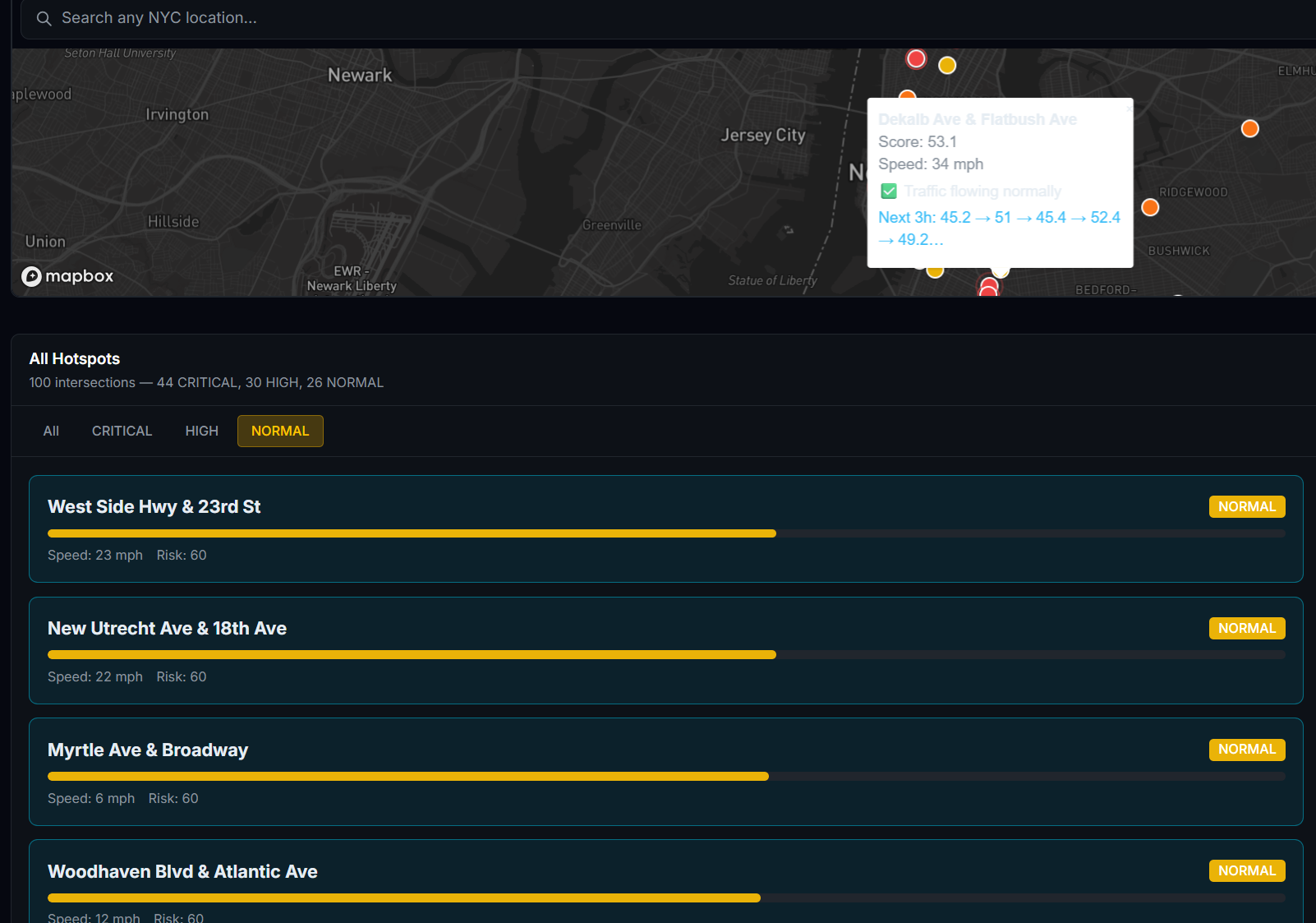
What I Built FlowIQ is a real-time traffic intelligence dashboard for city operations centers. It monitors live intersections across multiple boroughs or districts, forecasts congestion 3 hours ahead, scores accident risk at each location, and automatically assigns city resources — officers, signal units, VMS boards — to the worst hotspots before they form. There is also a commuter-facing view showing the best time to leave and which roads to avoid right now. For the hackathon demo the system is configured with 100 intersections across NYC, but the architecture is designed so any city can be onboarded by updating the location list and API keys.
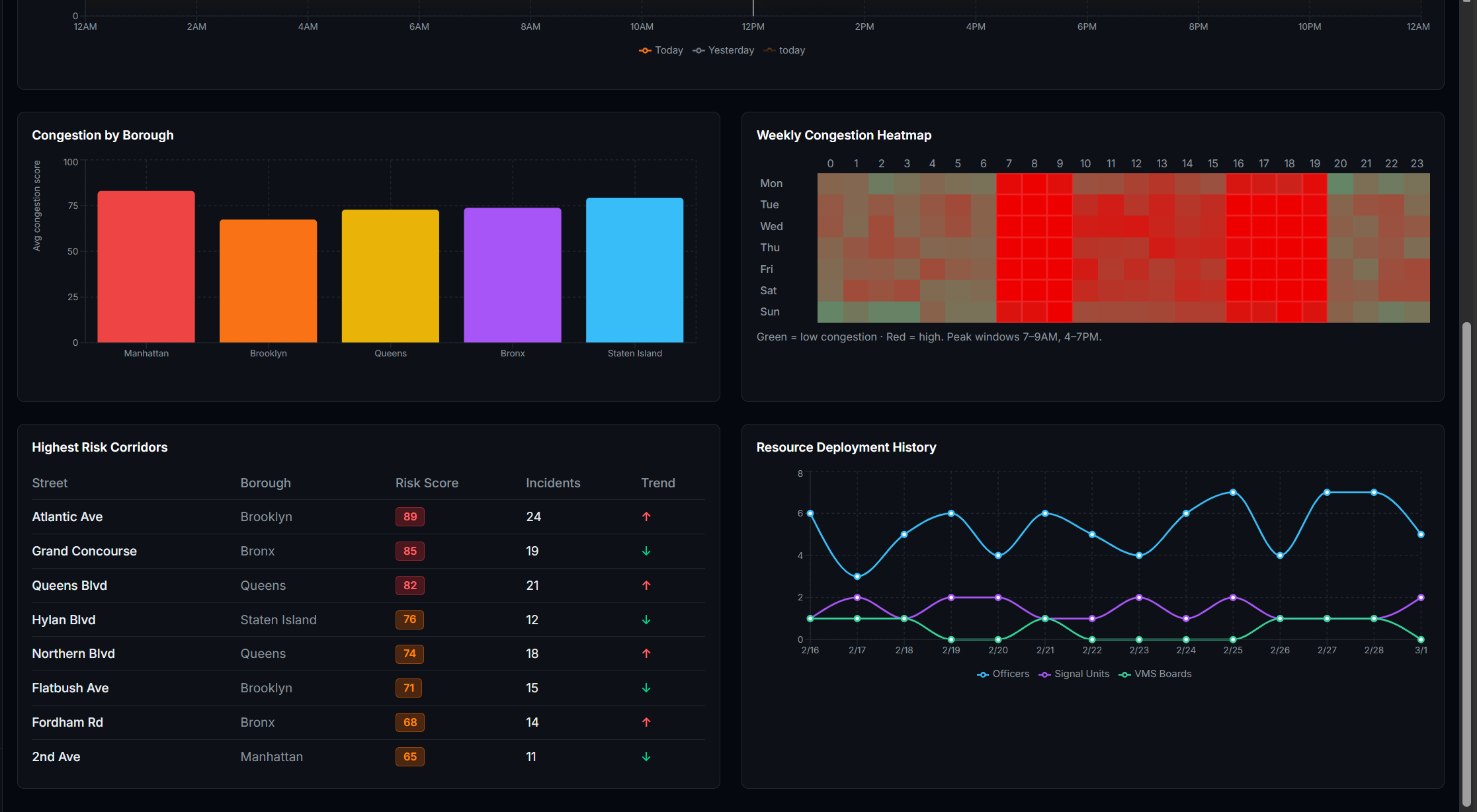
How I Built It The system is built in four layers: data ingestion, AI/ML inference, a REST API, and a React frontend. Data comes from the TomTom Traffic API (live speeds per intersection, refreshed every 60s), OpenWeather API (live weather conditions), a Kaggle traffic dataset (48,000+ records for LSTM training), and the US Accidents dataset (7 million records for risk model training). The forecasting model is an LSTM neural network built in PyTorch. It takes the past 24 timesteps as input and predicts the next 12 — covering 3 hours at 15-minute intervals. The risk model is a Random Forest classifier trained on the US Accidents dataset. It scores accident risk per location on a scale of 0–100 using 46 features including time of day, weather conditions, road type, and historical incident density. Score blending combines all three signals into one final congestion score: score=clamp(congestion+0.3⋅risk+0.5⋅weather, 0, 100) The backend is a FastAPI server on Python 3.11. All intersections are fetched in parallel using ThreadPoolExecutor, completing in under 5 seconds regardless of city size. Endpoints include /intersections, /hotspots, /predict, /optimize, and /borough-stats. The frontend is React + Vite with Mapbox GL for the live map and Recharts for forecast charts. Markers are color-coded by severity and auto-refresh every 60 seconds.
Challenges Model integration was the hardest part. Getting the LSTM and Random Forest to work together in a single prediction pipeline took significant debugging. The LSTM returns numpy types that FastAPI cannot serialize to JSON — this caused silent 500 errors on the /predict endpoint until I traced it back and wrote a recursive converter to map numpy types to native Python before returning the response. Blending the two model outputs into a single meaningful score without either one dominating the result also took several iterations to tune. API integration was more painful than expected. The original plan used a city open data API for live traffic feeds — after hours of connection timeouts and 503 errors I switched to TomTom, which was far more reliable. The OpenWeather key also takes time to activate after signup, so I had to build and test with a fallback before live weather data was available. Scaling to 100 intersections exposed a performance bottleneck — sequential API fetches took over 100 seconds, which I fixed by switching to parallel requests with ThreadPoolExecutor. Model Training was also painful. One of the datasets have 7 million rows so cleaning and retrieving required data required lot of unnecessary waste of time in cleaning as well as finding out right ammount of features. Finding best ML Model also took time.
What I Learned
How to train, serialize, and deploy two different ML models together in a single production API How to design a score blending formula that weights multiple signals without letting noise dominate That the hardest part of any ML project isn't the model — it's the data pipeline around it How to build for generalization from day one so the system is not locked to one city

Log in or sign up for Devpost to join the conversation.