


Inspiration
Walking into a packed career fair, your heart rate spikes. Sitting in a waiting room before a diagnosis, your hands go cold. Standing backstage before a presentation, your breath gets shallow. These moments of acute anticipatory anxiety hit fast, hit hard, and hit 31% of U.S. college students at clinically significant levels (Moskow et al., Journal of American College Health, 2024).
The problem isn't that coping tools don't exist, it's that they intervene too late or in the wrong modality. You can't pull out a meditation app mid-conversation at a networking event. You can't do breathing exercises while walking through a noisy crowd. By the time you reach for your phone, the autonomic overdrive loop, rising heart rate, collapsing HRV, narrowing attention, has already set in.
We asked: what if the intervention was invisible, automatic, and already playing in your ears the moment your body started to shift?
Music is uniquely suited to this. A recent randomized trial demonstrated that music-based intervention significantly reduced acute anxiety in high-stress clinical settings (Goel et al., Journal of Clinical Medicine, 2024). The iso-principle, starting music at the listener's current arousal level and gradually guiding it down, is a well-established technique in music therapy. But no existing system can do this adaptively, in real time, personalized to both your physiology and your environment.
What it does
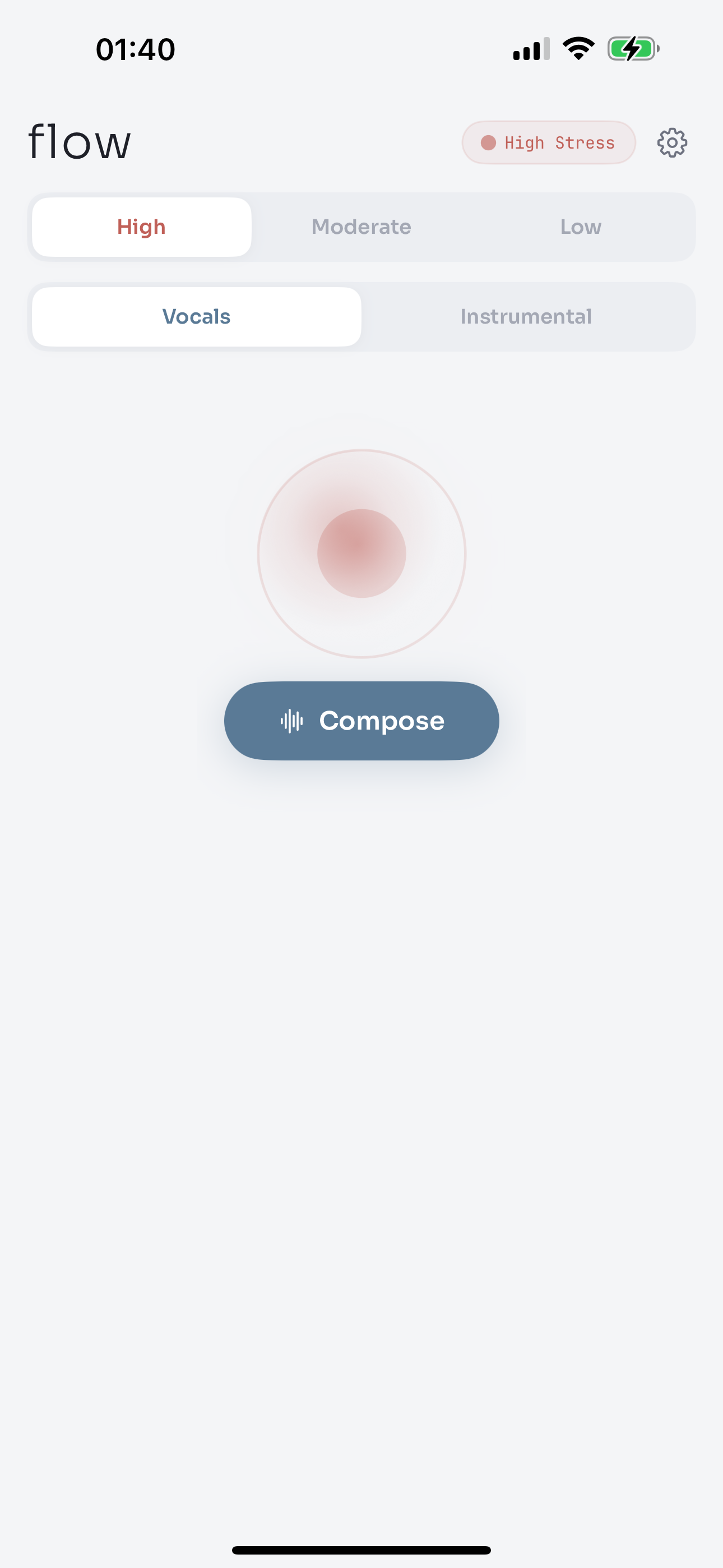
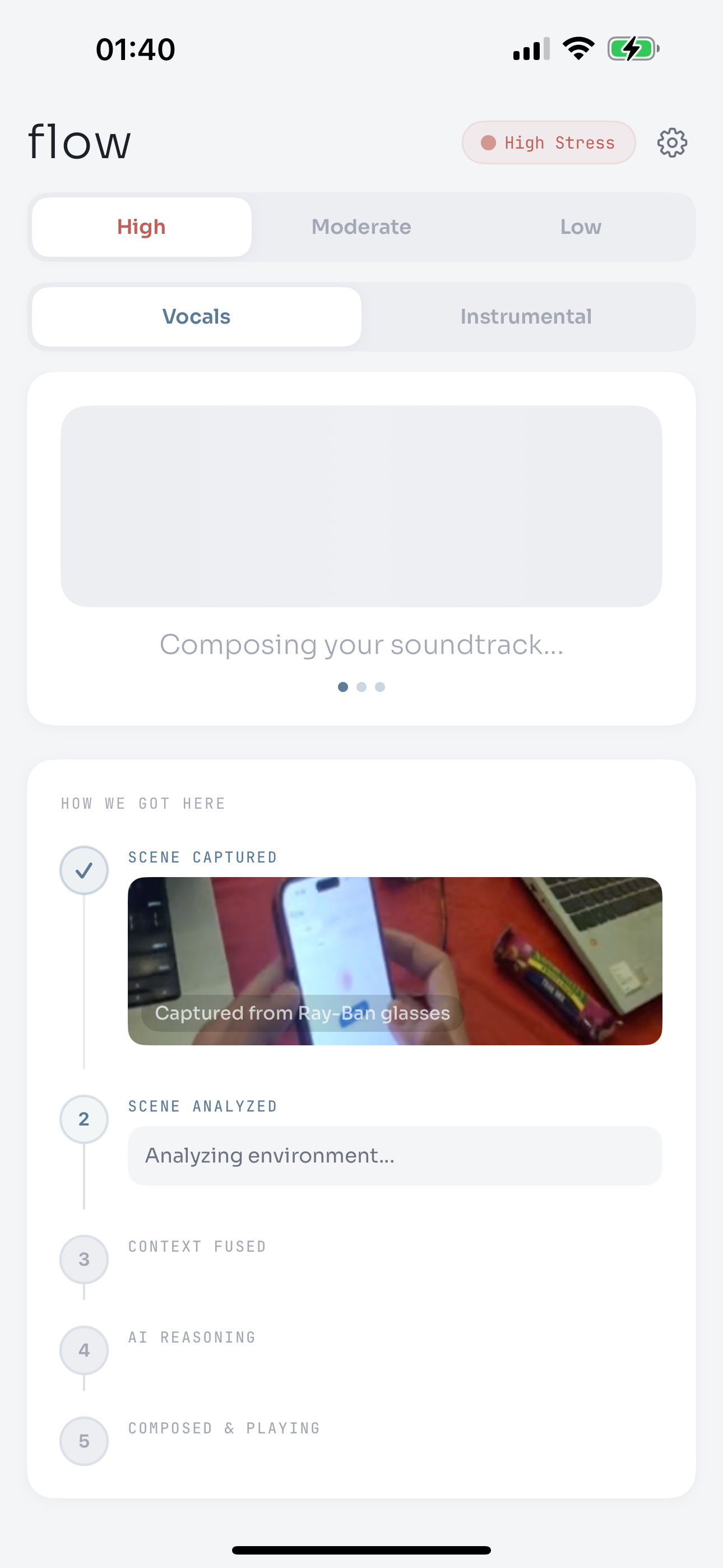
Flow is a wearable, context-aware music system that delivers just-in-time micro-interventions for acute stress and anticipatory anxiety in public, crowded, and performance contexts.
Here's what happens in real time:
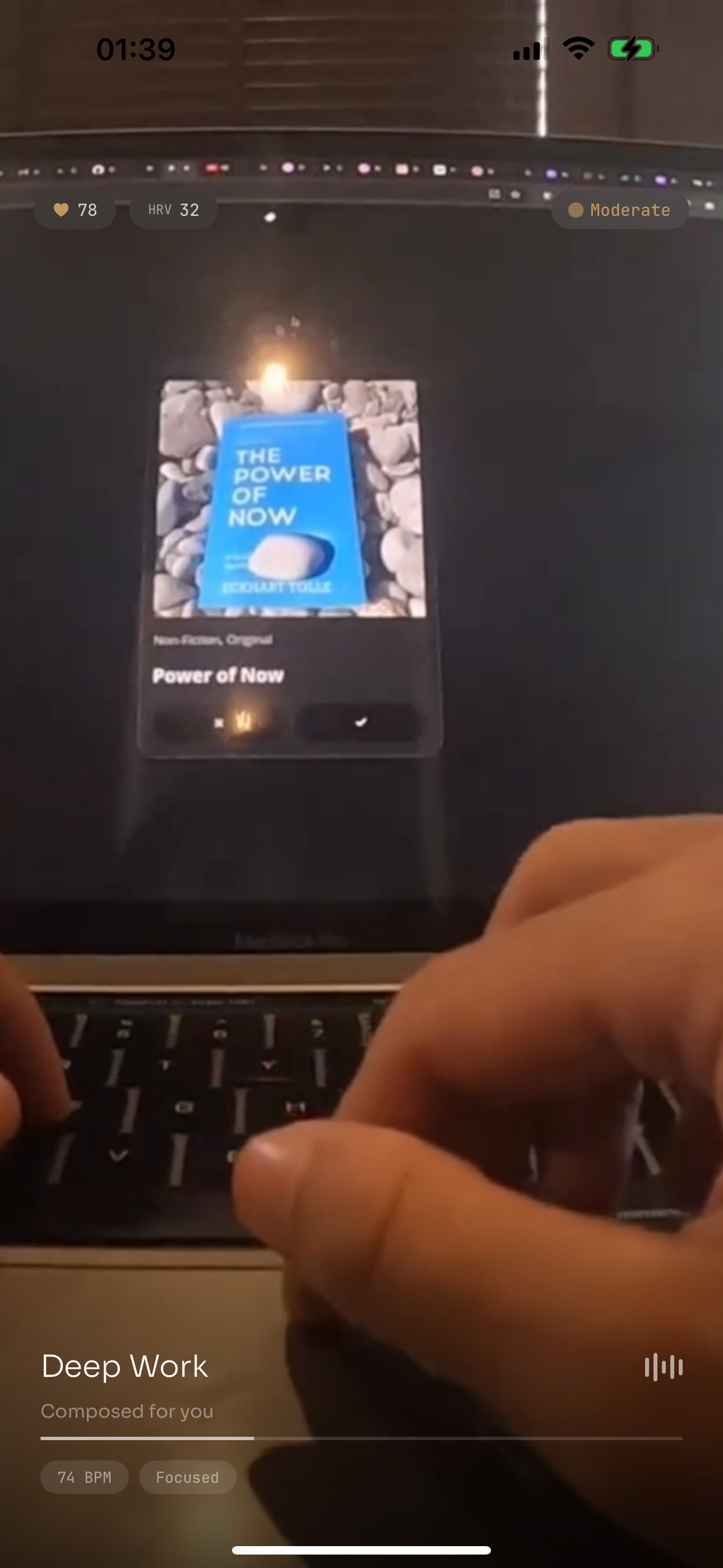
Sees what you see. Meta Ray-Ban smart glasses capture your environment, a crowded room, a quiet trail, a sterile waiting room. The visual context tells Flow where you are and what kind of stress you might be experiencing.
Feels what you feel. Your Apple Watch streams heart rate and heart rate variability via HealthKit. A spike in HR with a drop in HRV signals the onset of sympathetic activation, the body bracing for something.
Knows what you love. During onboarding, you tell Flow your music preferences, genres, favorite songs, artists. Every generated track is shaped by your taste, not generic "relaxation music."
Thinks before it composes. An LLM orchestrator (GPT-5.2 instant & Gemeni 2.5 flash) fuses the visual scene, biometric data, and music preferences into a therapeutic strategy, deciding the right BPM, mood, texture, and approach. For high stress, it applies the iso-principle: match your current arousal first, then gently guide it down. For moderate focus, it maintains momentum without adding tension. For low stress, it stays out of the way.
Composes a soundtrack that's never existed before. The LLM's strategy becomes a generative music prompt sent to Suno AI, which produces a unique, full-fidelity track in seconds, personalized to this person, this moment, this body, this place.
The result: you walk into a packed venue, and before the anxiety spiral begins, music that matches you is already playing, grounding you invisibly through your earbuds.
How we built it
Hardware layer:
- Meta Ray-Ban smart glasses for first-person environment capture via Bluetooth
- Apple Watch for real-time heart rate and HRV streaming via HealthKit + WatchConnectivity (stress detection through autonomic arousal patterns)
Intelligence layer:
- GPT-5.2 instant & Gemeni 2.5 flash as the orchestration LLM, receives the camera frame, biometric readings, and user music preferences in a single call
- Returns a structured therapeutic strategy: scene analysis, stress assessment, iso-principle application rationale, and a generative music prompt
Music generation layer:
- Suno AI API for real-time music composition from the LLM's prompt
- Parallel generation pipeline, three tracks generated simultaneously in ~20 seconds
- Audio pre-downloaded to local storage for instant, buffer-free playback
App layer:
- Native SwiftUI iOS app
- Custom design system: Sora typeface, Morning Fog color palette, breathing orb interaction pattern
- Full-screen cinematic demo mode with POV video playback synchronized to generated audio
- Onboarding flow with Spotify search integration for music preference capture
Demo experience:
- Three pre-filmed POV scenarios (hackathon at 2 AM, Squash mid-match intensity, nature walk) each paired with music generated from the user's actual preferences
- Same person, three stress levels, three completely different soundtracks, demonstrating adaptive response across the arousal spectrum
Challenges we ran into
The iso-principle is counterintuitive. Our first instinct was to play calming music when stress is high. But music therapy research says the opposite: you match the listener's current state first, then gradually shift. Explaining this to the LLM, "don't jump to calm, meet them where they are", required careful prompt engineering so the generated music actually follows therapeutic principles rather than naive assumptions.
Biometric noise. Heart rate alone isn't enough, someone running has a high HR but isn't anxious. HRV (heart rate variability) is the key autonomic signal, but Apple Watch HRV readings are noisy in real-time. We used contextual fusion: the camera scene disambiguates what the biometrics mean. High HR in a crowded room = anxiety. High HR on a trail = exercise. The LLM handles this reasoning naturally.
Making generated highly personalized AI music doesn't sound generic when prompted properly. The difference is the depth of the prompt. By feeding the user's specific artists and genres into the LLM's reasoning, and by giving it explicit BPM targets and textural directions, the output sounded increadibly similar to our music taste and favorite music for the specific vibes captured, not stock meditation audio.
Accomplishments that we're proud of
- The full pipeline works end-to-end. Camera capture → biometric reading → LLM reasoning → music generation → playback. Every piece connected in 12 hours.
- The contrast is audible. When you switch from high stress to low stress with the same music preferences, the generated tracks are dramatically different. You can hear the system thinking.
- The demo tells a story. Three POV videos, three stress levels, three unique soundtracks, all generated from the same person's preferences. Judges don't just see a product; they feel the difference.
- It's therapeutically grounded. This isn't "vibes-based" wellness tech. The iso-principle, autonomic arousal detection, and context-dependent intervention strategy are all rooted in peer-reviewed research.
What we learned
AI music isn't slop when it knows you. We came into this weekend assuming generative audio would sound like royalty-free elevator music, technically fine, emotionally empty. By Saturday night we were genuinely listening to tracks Flow made for me outside of testing. When the system has your actual favorite artists, your genres, your vibe and an LLM that reasons about why those preferences matter in this specific moment, the output stops sounding like AI slop and starts sounding like a fusion of everything you already love, shaped into something you've never heard before. That was the moment the project stopped feeling like a demo and started feeling like a product.
Multimodal LLMs are orchestrators, not just classifiers Using GPT-5.2 instant & Gemeni 2.5 flash to reason about the relationship between a visual scene, a physiological state, and a musical strategy, then output a creative prompt, is a fundamentally different use of AI than classification or summarization. The LLM isn't labeling emotions; it's practicing music therapy.
What's next for Flow
- Real-time continuous biometric streaming. Moving from periodic HealthKit reads to continuous background HRV monitoring with automatic moment detection, Flow intervenes the instant your autonomic state shifts, without you pressing anything.
- Longitudinal adaptation. Learning from weeks of data, which musical strategies actually reduce your stress over time, and shifting the model's approach accordingly.
- Clinical validation. Partnering with Stanford's psychiatry department to run a controlled study measuring pre/post anxiety (GAD-7) and physiological markers (HRV recovery time) in real-world acute stress contexts.
- Continuous ambient mode. Instead of discrete "moments," Flow runs silently in the background and only intervenes when it detects the onset of autonomic arousal, truly invisible, just-in-time support.

Log in or sign up for Devpost to join the conversation.