-
-

-
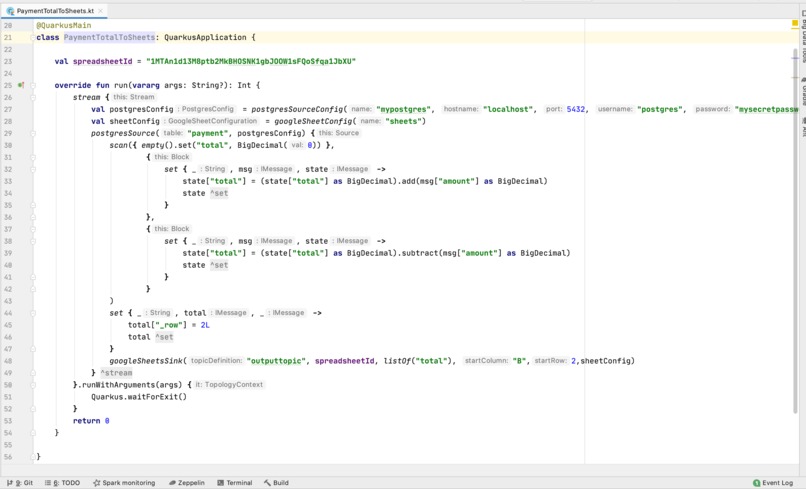
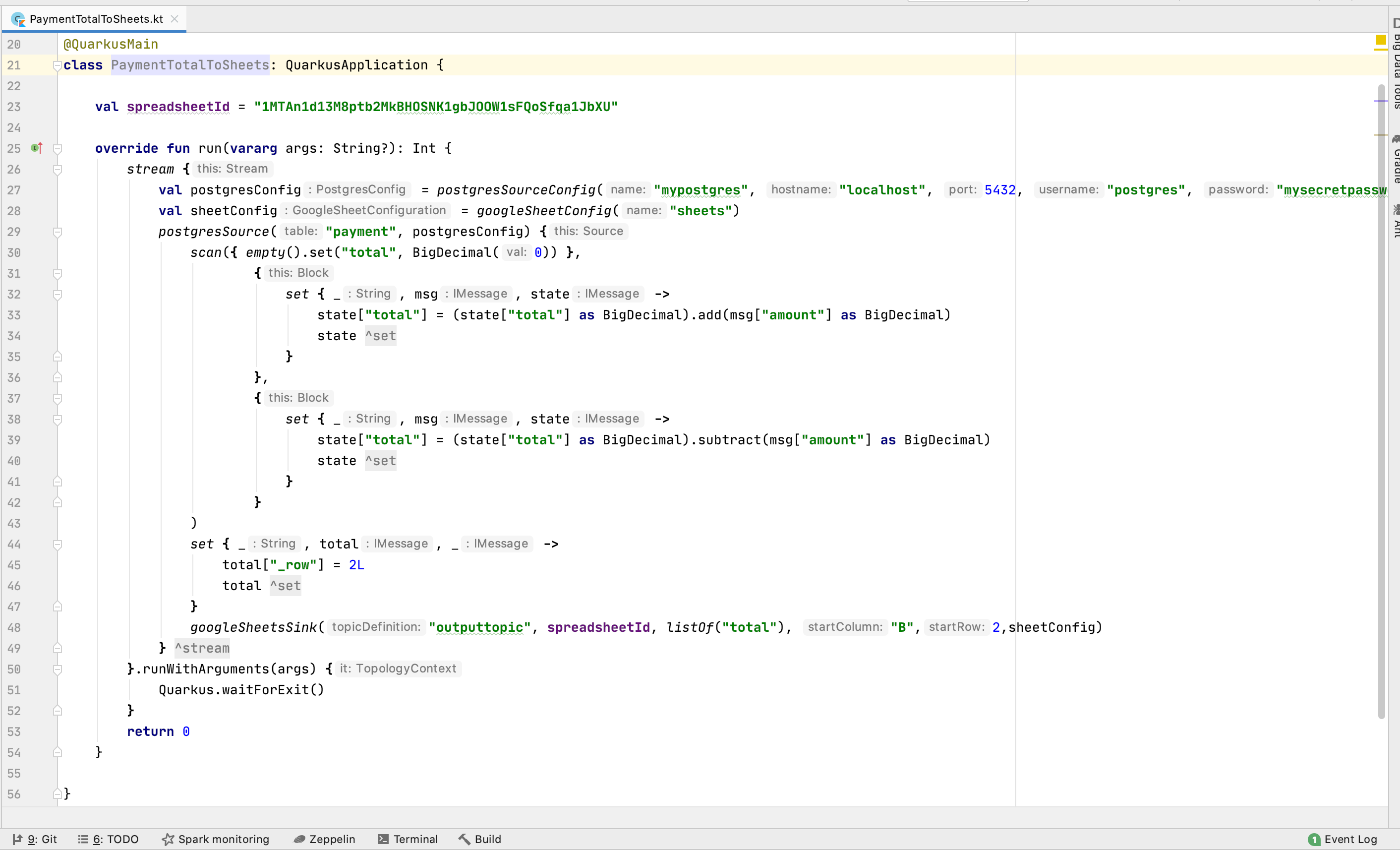
A simple Floodplain transformation

Inspiration
I've been working in change data streaming for a few years, and I think it is an underdeveloped area. Early this year I took a sabbatical (to travel and party :-/) but I ended up writing Floodplain.
Martin Kleppmann said it best in his book Data Intensive Applications:
"Why can't I just "mysql | elasticsearch"?
That is what I want to do here: Declaratively pipe different kinds of databases together, usually with some transformation in between.
The source database simple does its job and is unaware of the change data streaming, and all the down-stream database can materialize this data in all kind of fancy ways.
Like using materialized views, but then between completely different databases.
What it does
To take the specific MySQL -> ElasticSearch example, suppose I have an application that uses MySQL, and I want to add full text search to it, it is possible to do that in MySQL, but it is an advanced feature, and it might impact the performance of MySQL. Ideally, we wouldn't touch our production database at all. Changing data models of running databases is tricky, and should not be done lighly.
Alternatively, we can stream all MySQL changes to Elasticsearch. For ES, full text search is not an advanced feature. It is the 'hello world' of ElasticSearch. ES can do its thing while MySQL is unaware. If somehow the ElasticSearch cluster acts up or gets damaged, we can simply repopulate a new cluster and throw away the old one. Far less stressful that messing with indices and data models in the source database.
Want to do fancy graph analysis? Stream it to Neo4J Want to publish a subset of your data to the internet without exposing your own application? Stream it to a managed store like FireStore.
How I built it
Floodplain builds Kotlin based Kafka Streams applications. I chose Kotlin because it is a very pleasant language, and because it has very powerful features like extension functions and function types with receivers it is quite easy to expand.
I also like Kotlin because the Kotlin crowd is not the typical data engineering crowd, and I'd like the stream processing to be less intimidating, so for example Android developers can get started in this area without needing to jump into a completely foreign ecosystem.
Quarkus suddenly got interesting when 'command mode' was introduced, because Floodplain programs are essentially long-running commands, you start them, and they stream any changes that come in until someone stops it.
Quarkus solved the deployment problem for me. I tried using fat-jars, but due to the nature of Kafka Connect components (they tend to be deployed as Fat Jars), the instances got massive. Last time I built a fat-jar, it was a 55Mb jar for a very basic stream. With Quarkus, that same stream runner was only 200Kb. That is a very significant improvement, especially as I am targeting more low-end users.
Still, as Floodplain compiles to a Kafka Streams application, we still need a lot of infrastructure, even for a very basic streaming application: A Kafka Cluster, a Zookeeper cluster, a Kafka Connect cluster, and the Floodplain application itself. It isn't that bad, as you can spin up all of this with a simple docker-compose file, but it still has too many moving parts for my taste, especially if you want to simply stream data from one database to another.
When Debezium (the part that captures data from databases and usually writes it to Kafka) introduced a 'standalone' version, that wouldn't push changes to Kafka but allowed me to use it however I liked, I started thinking about running Floodplain entirely without Kafka. By adapting the test-runtime from Kafka Streams (originally used to test Kafka topologies), Debezium standalone, and directly using the Kafka Connect sink api, we can now run Floodplain without Kafka and Zookeeper.
Using Kafka still has a lot of value: For example, Floodplain instances kan run and be re-run without causing extra load on the source database, but with Floodplain we can now run the same stream instance with or without Kafka, depending on our needs.
Challenges I ran into
- The general perils of event driven architectures. Debugging why something doesn't happen is hard
- I pivoted half way to support the 'kafkaless' runtime, and that was pretty hard to back port, as it is quite a different runtime.
Accomplishments that I'm proud of
- Running Kafka Streams without Kafka is kinda cool.
- I'm biased of course, but I think the developer experience is actually quite nice
- The thin wrappers around Kafka Connect sinks makes it really simple to add new sinks
- Strong-typed configuration is so much nicer than weakly typed configuration.
What I learned
Lot of practical things. Kotlin, Gradle, publishing to Maven Central, gotten pretty intimate with the Kafka / Streams / Connect interface.
I've learned the value of using strong typing for configuration. If you create configuration objects in a strongly typed language (like Kotlin) you will know what you need to supply, what type it is and what you can optionally add. If you get it wrong, the editor will tell you. This is so much better than trying to craft the exact property or yaml file and getting some runtime error when there is a discrepancy.
On a more 'fluffy' level, I've learned the value of diversity (...awww..) If you look at the same data though the lens of a document database or a graph database you see different patterns and it does expand your thinking. For example streaming a live relational dataset into a graph database is just a really profound experience. It's the same data but you are looking at it with new eyes.
What's next for Floodplain
I hope it gains some traction, I believe strongly in this model. This is pretty much a sabbatical / lockdown project that got out of hand a bit. There is of course a ton of things to improve and optimize. There are many more sources and sinks to embed, I've focused mainly on mainstream databases, but there are many more connectors: MQTT, Azure IOT Hub, ArangoDB.
Right now, Floodplain creates a Kafka Streams application but that might not be right for all cases, for small local instances it might be even more efficient to run the code directly, even in memory with no persistence. Alternatively for larger deployments it might make sense to run on 'heavier' environments like Spark. Floodplain can provide a runtime agnostic programming model for all these environments.
Built With
- debezium
- kafka-streams
- kotlin

Log in or sign up for Devpost to join the conversation.