-
-
Front landing page
-
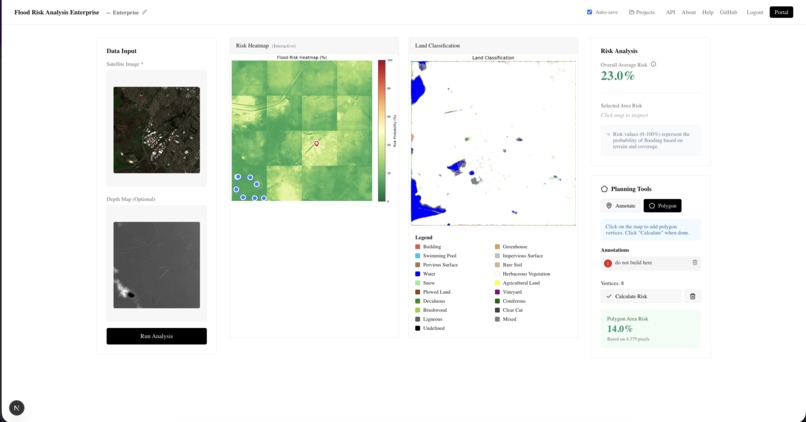
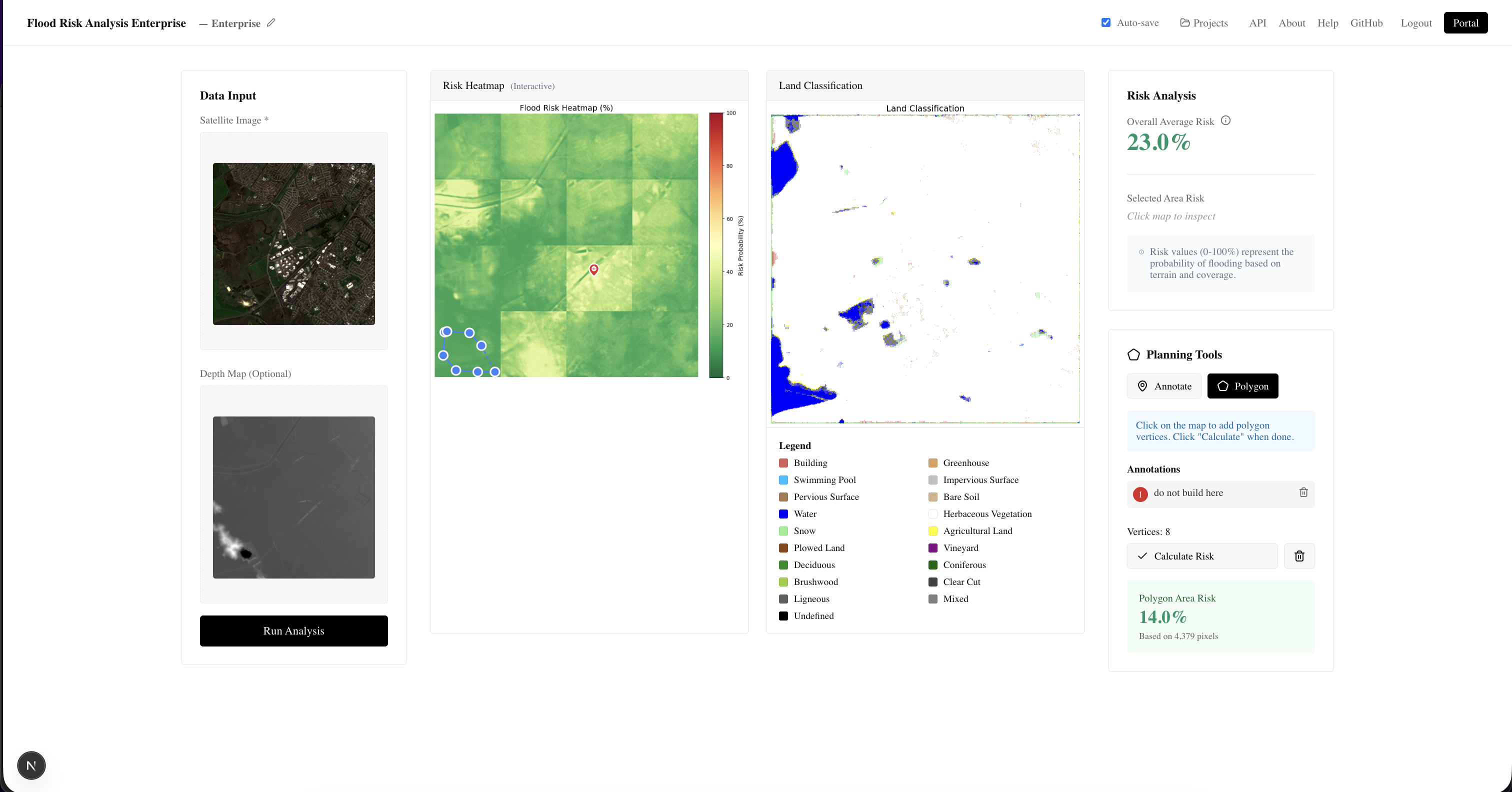
Enterprise dashboard
-
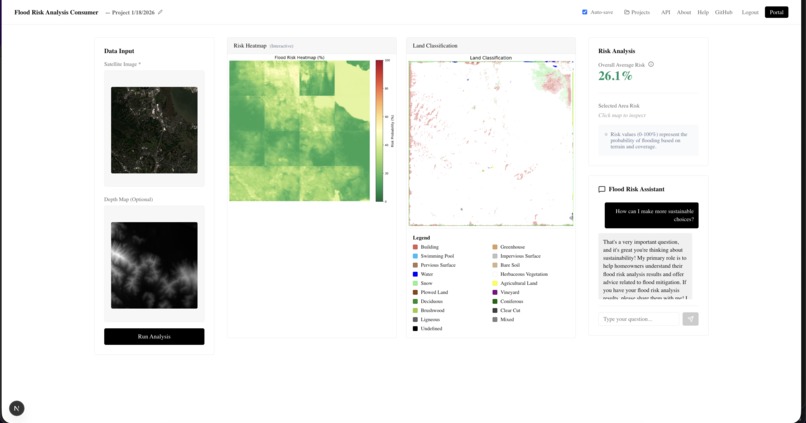
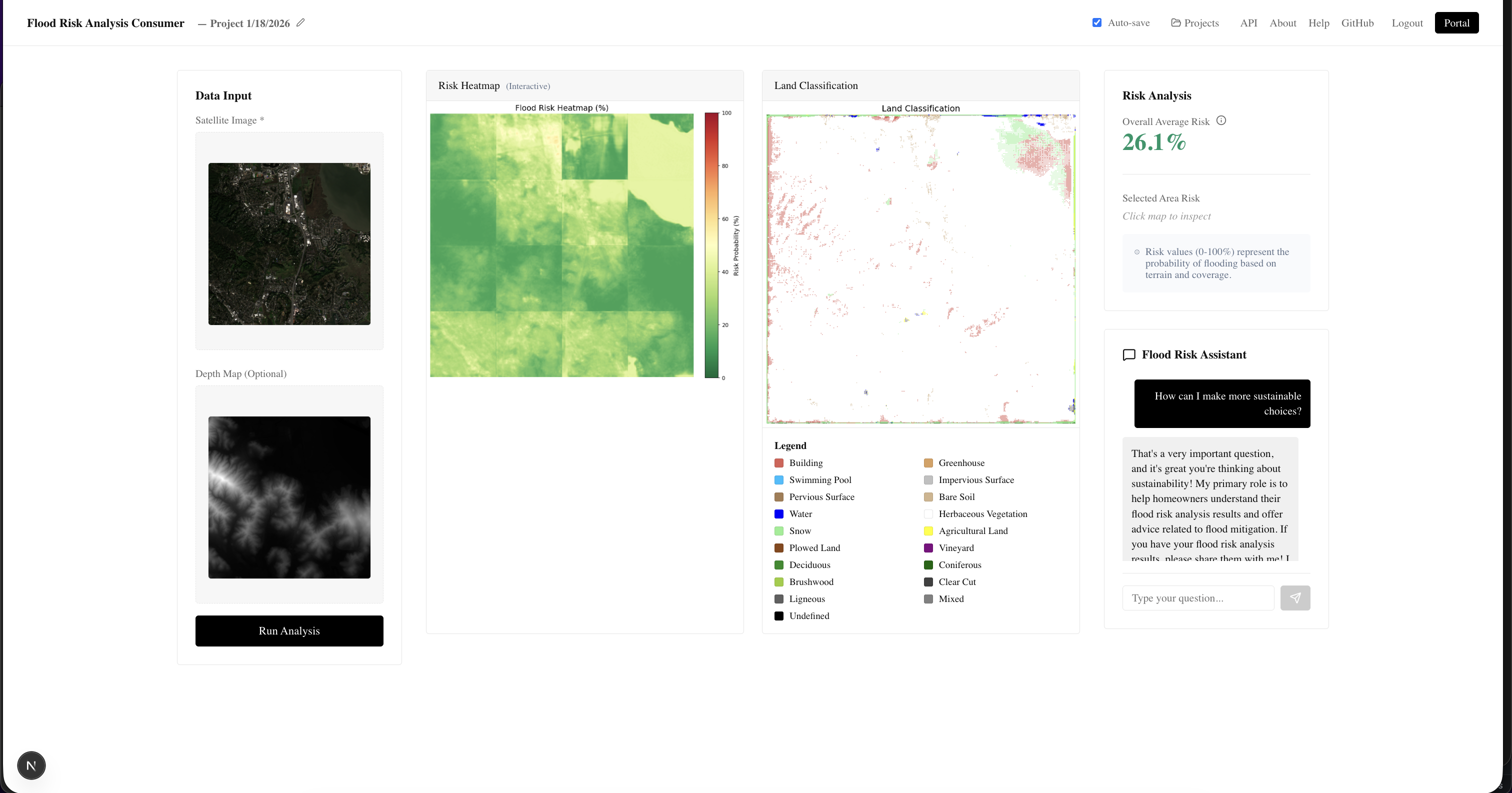
Consumer dashboard
-
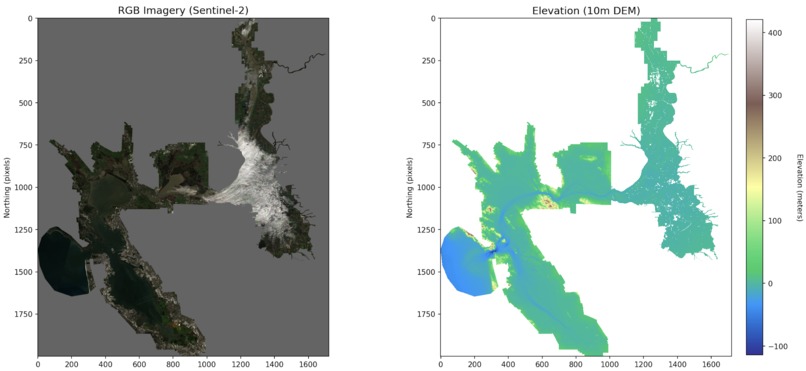
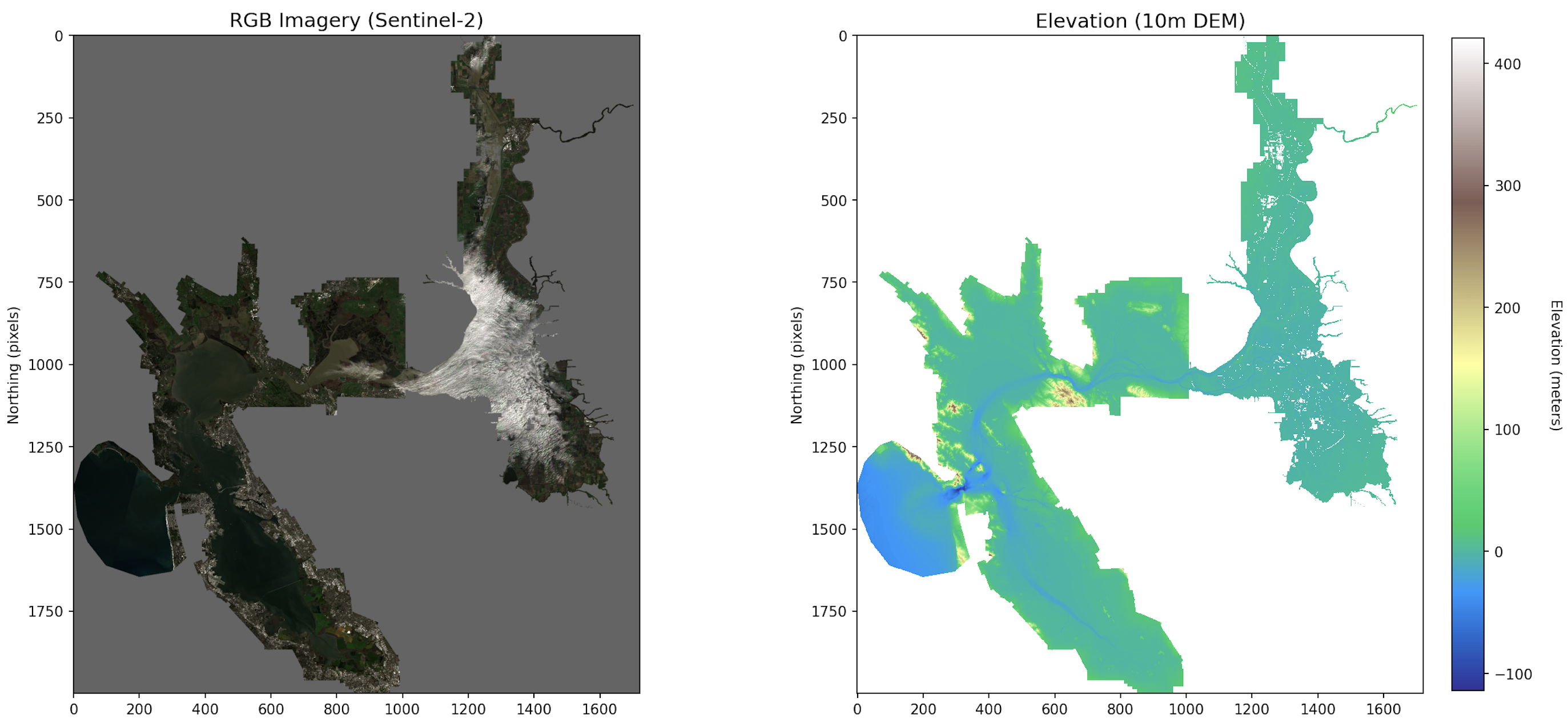
Custom dataset creation for elevation
-
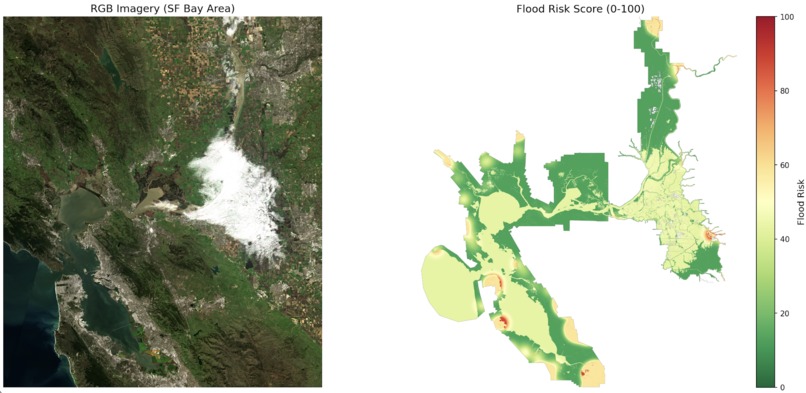
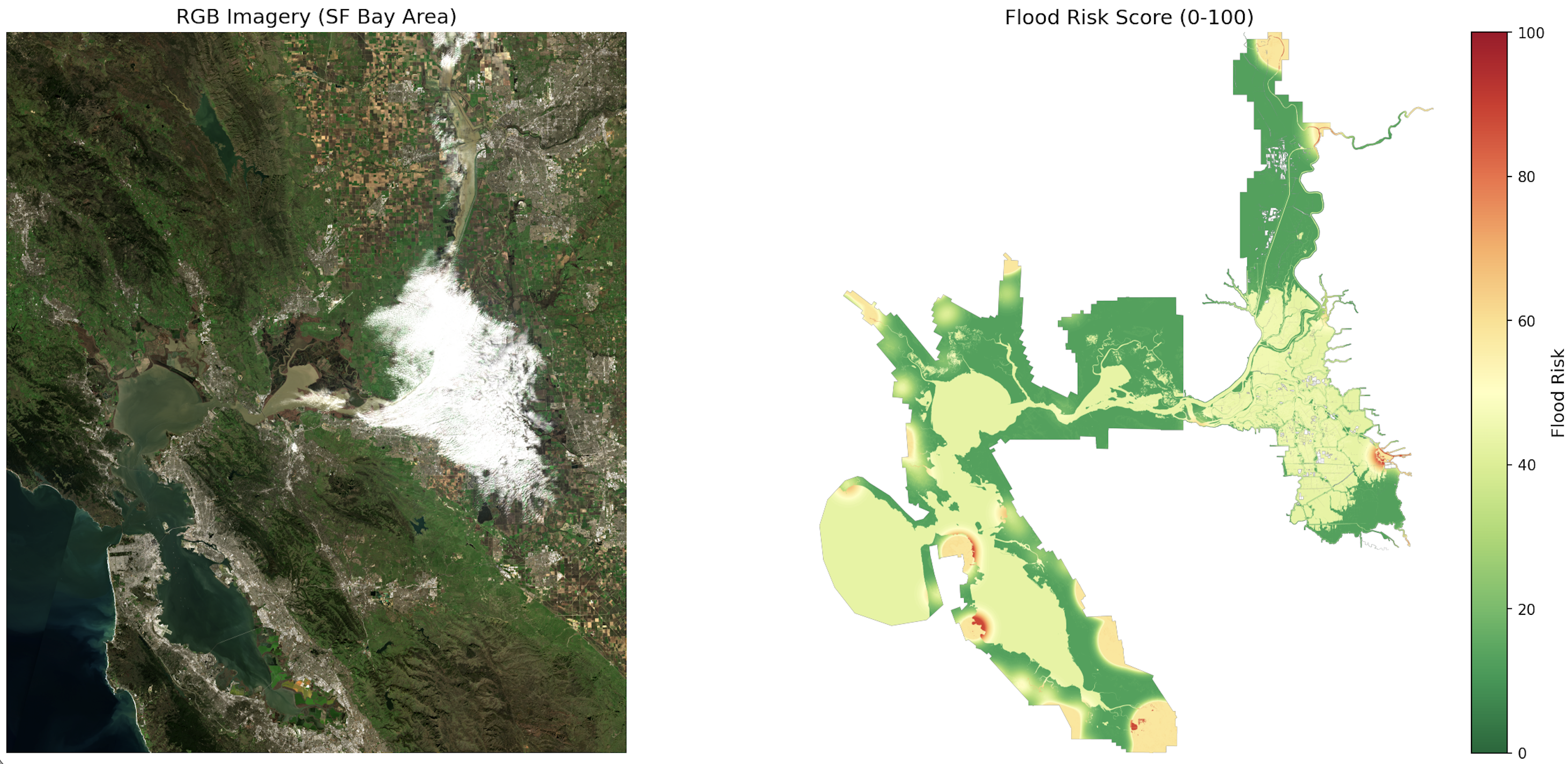
Custom dataset creation for risk
Inspiration
Flooding is one of the most prevalent and deadly natural disasters and is only becoming increasingly common with record rainfalls brought by climate change. Fooding has cost the United States 180 billion per year and has directly caused thousands of deaths since 2000 (1) (2). Continued urban development without proper flood risk analysis is unsafe, unsustainable, and incredibly costly. Current flood risk analysis is often constrained to flood plains, relies on anecdotal evidence, and can be difficult to access making it unreliable to use and just not good for life threatening situations (3). Our project, Flood Risk Analysis, provides a data driven and accessible approach of analyzing flood risk in areas allowing for smarter, more sustainable, and safer building and living choices.
What it does
Our project leverages 2 deep learning models to accurately identify flood risk across an area. The first model is a lightweight UNET to classify land usage (buildings, water, vegetation, crops, etc) from satellite imagery achieving over 70% accuracy. The second model is a UNET inspired encoder decoder architecture that considers factors such as historical rainfall, land use classification, and elevation maps to assess flood risk achieving over 90% accuracy.
Our platform allows for 2 separate ways to use the model. First, there is a RESTFul API built on FastAPI so our models can be directly integrated into other people's applications. Secondly, we have a web portal which allows users to start projects and upload satellite imagery and depth maps to get flood risk assessment. There is a separate portal for both consumers and enterprise users, where consumers have access to a chatbot built on the Gemini API to learn more about flood risk and enterprise users have the ability to annotate potential building zones or high risk areas.
How we built it
Our models and platform was built in 3 separate parts: developing the dataset, developing the foundation models, and developing the user interface.
Datasets for flood risk were not readily available because they were often incredibly low resolution, hard to access, and were not built on objective measures and instead reliant on community input. To create our dataset, we pulled elevation mapping data, high resolution satellite imagery, historical rainfall, and historical flood records. Our dataset was built on the Sacramento-San Joaquin Delta because of its ecological and elevation diversity, allowing us to create a representative and diverse dataset that would ideally prevent overfitting while still remaining manageable. Flood risk was then determined using industry standard techniques by using historical flooding records, locating lower vs higher ground, and surface permeability (4). For land use classification, we used the FLAIR HUB Toy dataset which gave us 19 separate classes.
Our Land Classification model was then developed as a 7.8m parameter UNET and was trained on the FLAIR HUB dataset and achieved over 70% accuracy. Then, our risk analysis model was developed as a multimodal encoder decoder architecture and trained on our custom dataset as well as land classification from our land classification model, achieving over 90% accuracy.
To keep our models as useful as possible, we built it as a RESTFul API service. We built a FastAPI service that would allow users to easily send GET requests with their satellite imagery and depth maps and get risk analysis as a result. However, most consumers and many enterprise users may be unwilling to develop their own application to access our models so we created a NextJS dashboard with Auth0 and MongoDB to keep the models easily accessible. We also implemented tools such as a chatbot built on the Gemini API to allow users to learn more about flood risk and annotation tools to better understand flood risk.
Challenges we ran into
The largest challenge we ran into was the dataset creation. As there was no readily available dataset, we had to parse over 5GB of data and create our own custom dataset. High resolution satellite imagery also had many rate limits for the free plan, and it was difficult to acquire that data. Additionally, satellite imagery, flood risk, and elevation all used different coordinate systems and it was very difficult to accurately merge the data.
We also struggled a lot with having our models converge. The land classification has 19 classes, and on a small subset of the dataset, the model struggled to accurately classify pixels before extensive hyperparameter tuning. Additionally, despite the large size of the dataset, the flood risk model struggled to generalize and quickly overfit due to the dataset having few areas with higher flood risk. This was ultimately solved by augmenting data to create a more balanced dataset as well as hyperparameter tuning.
Accomplishments that we're proud of
We are incredibly proud of successfully creating and shipping a product that includes 2 custom machine learning models, an API, and a full stack application with authentication and database usage. Having heavily time dependent steps such as model training slowed development drastically and made it difficult to complete on time. Additionally, the creation of the dataset was a very large undertaking as it required heavy research, alignment of multiple coordinate systems, and learning about how flood risk is calculated.
What we learned
Before this product, we had never used the Gemini API, MongoDB, Auth0, or NextJS. Throughout the creation of this project, we had to learn quickly to integrate all these tools into our project. Additionally, a lot was learned about developing more robust machine learning models by augmenting datasets and tuning. With many datasets having extensive bias towards some classes, it is important that we are able to still utilize them.
What's next for Flood Risk Analysis
The next steps for Flood Risk Analysis involve further fleshing out the consumer and enterprise portals to have more tools, collaboration, and other useful features. Additionally, Flood Risk Analysis still needs to be deployed on a cloud service like AWS to allow people to access it more easily. We also want to improve our land classification model to achieve higher accuracy, and augment the risk model with a computer modeling approach as well.
Sources
- https://www.jec.senate.gov/public/index.cfm/democrats/2024/6/flooding-costs-the-u-s-between-179-8-and-496-0-billion-each-year
- https://www.ketv.com/article/get-the-facts-deadliest-floods-in-the-us/65321053
- https://www.floods.org/news-views/research-and-reports/the-us-is-finally-curbing-floodplain-development-research-shows/
- https://www.fema.gov/flood-maps
Built With
- auth0
- fastapi
- javascript
- mongodb
- nextjs
- python
- pytorch


Log in or sign up for Devpost to join the conversation.