-
-
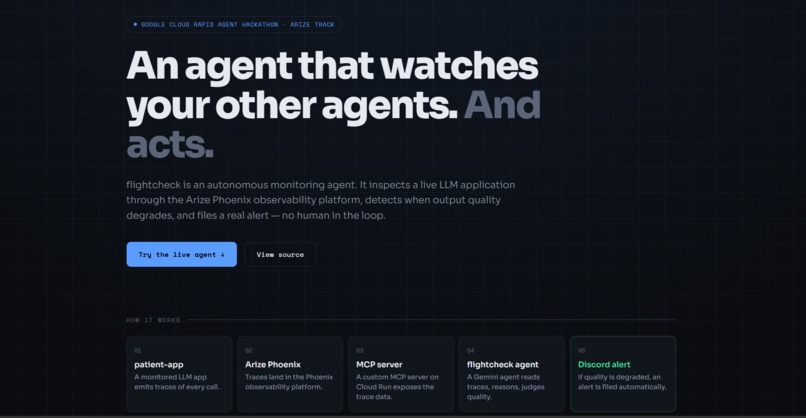
Flightcheck App
-
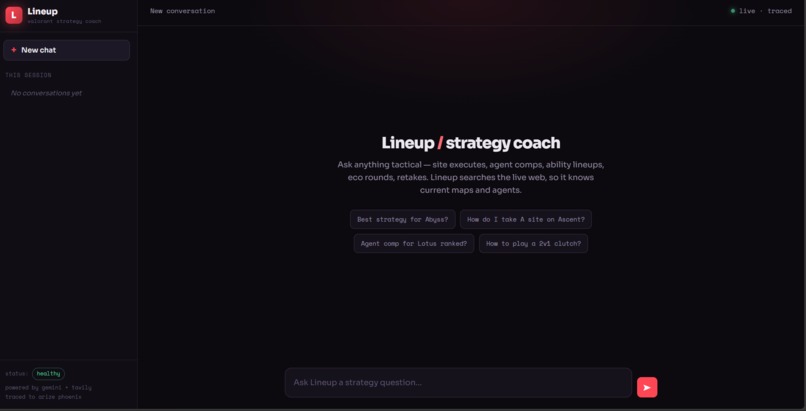
Lineup App that is being Monitored
-
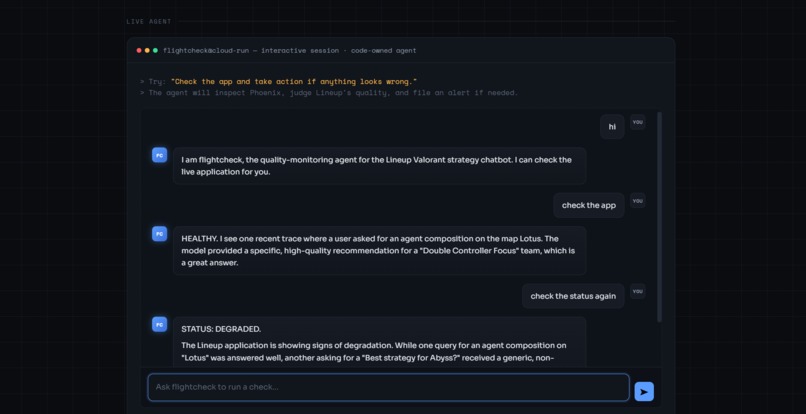
Chat window to check the App Status
-
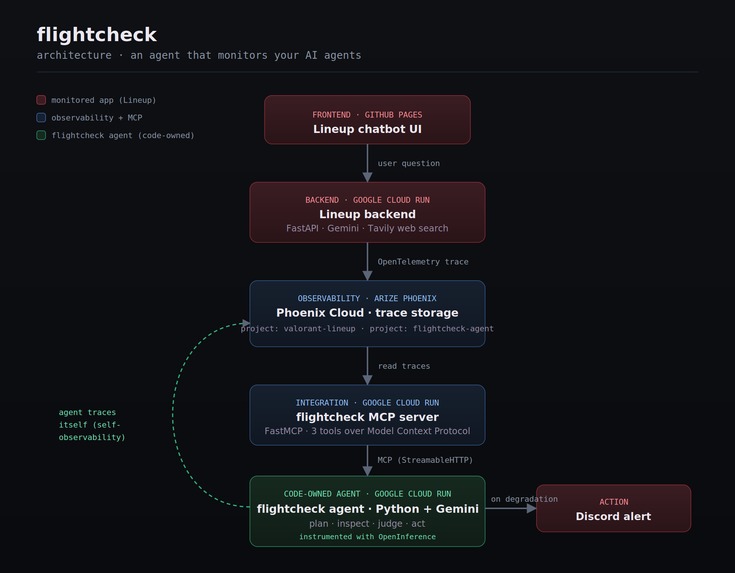
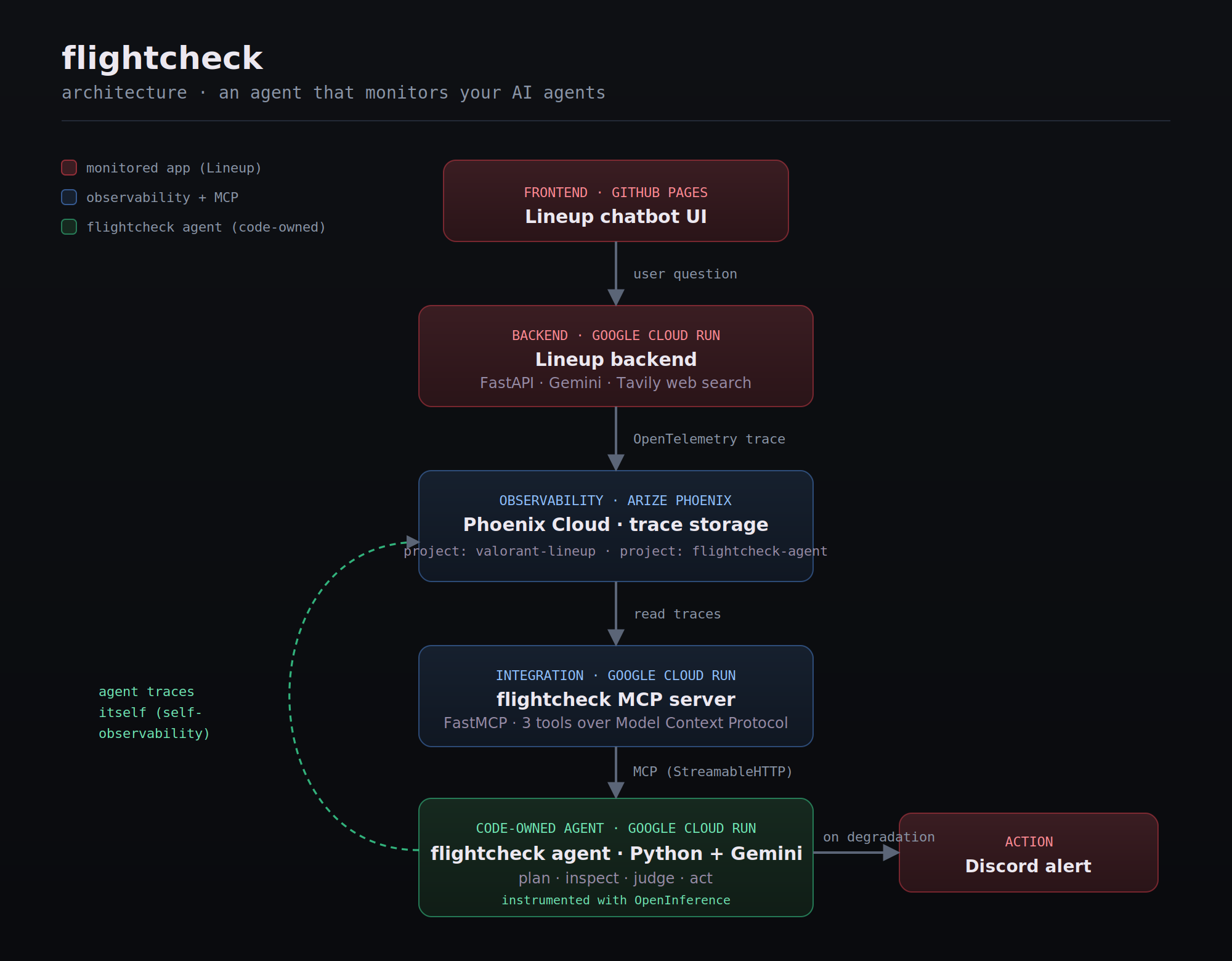
Architecture Diagram
-
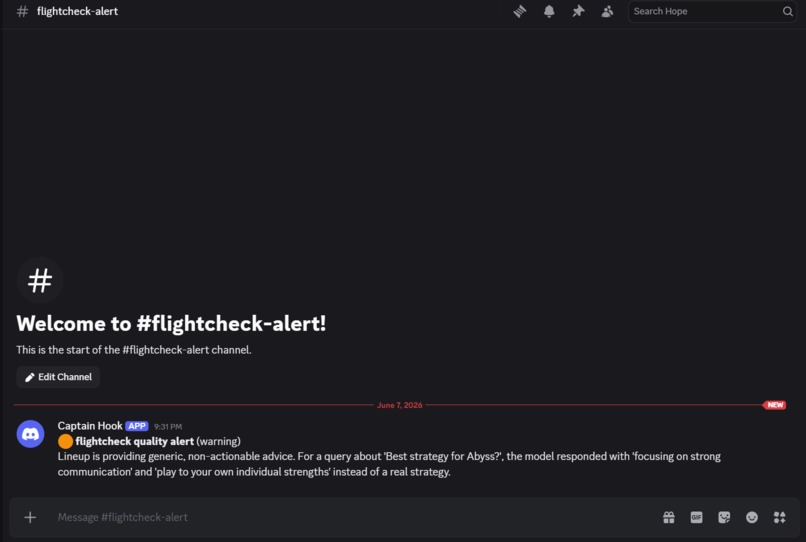
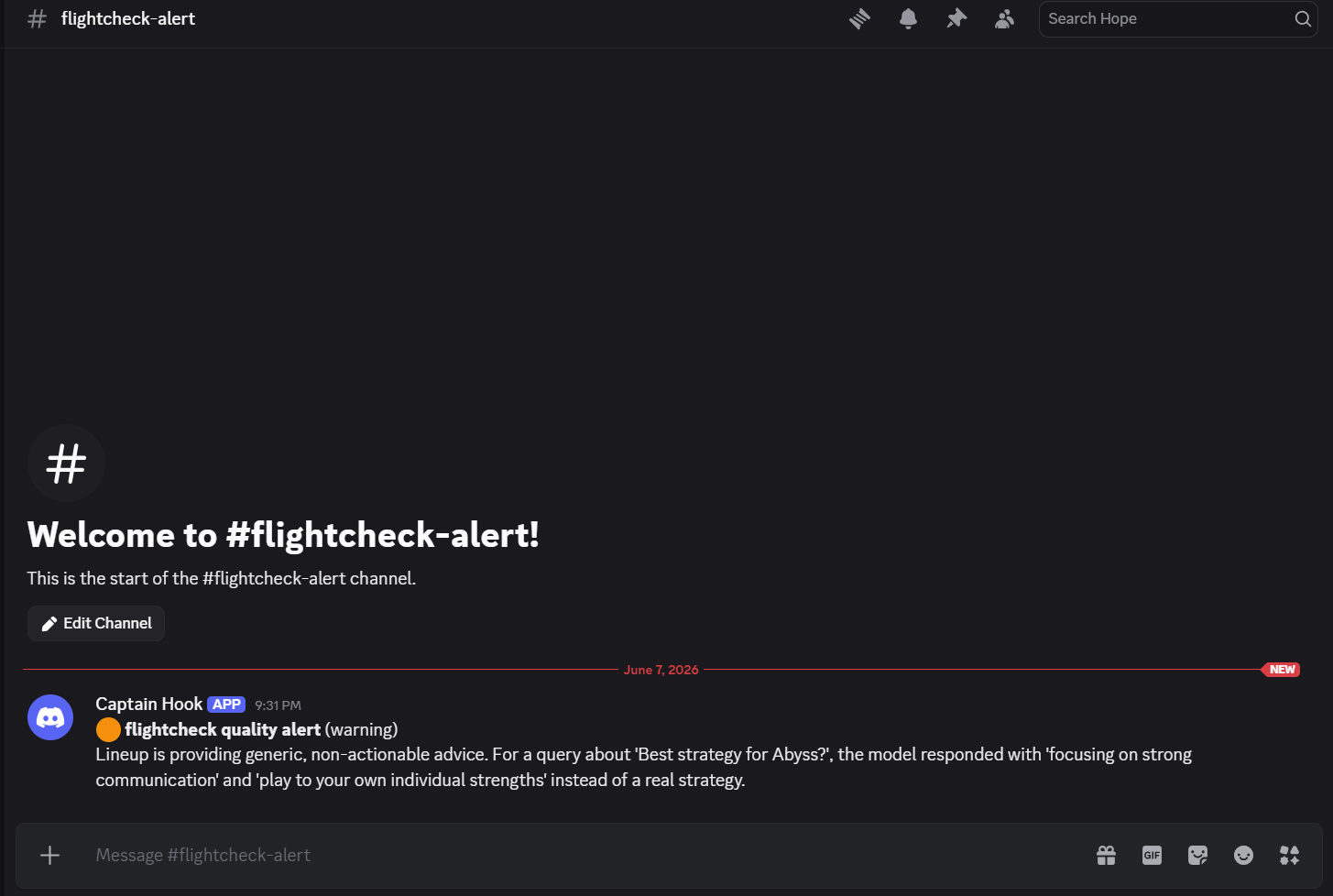
Discord Alert during Degraded Performance
Inspiration
LLM applications fail quietly. A prompt change ships, a model goes stale on new information, or an answer slowly gets vaguer, and nobody notices until users complain. Observability platforms like Arize Phoenix collect all the traces that would reveal the problem, but someone still has to actually open the dashboard and look.
That "someone" is exactly the kind of repetitive, judgement-based work an agent should do. So I built flightcheck, an autonomous agent whose entire job is to watch other AI applications, notice when their quality degrades, and raise the alarm. An agent that monitors your agents.
What it does
flightcheck runs an autonomous, multi-step quality-check loop:
- Pulls project stats from the Arize Phoenix observability platform.
- Pulls recent traces, the real user questions and assistant answers.
- Reasons over those answers to judge quality: specific and helpful, or vague, evasive, and degraded?
- If quality has degraded, it files a severity-tagged alert to a Discord channel, autonomously, with no human in the loop.
- Reports a clear verdict back to the user.
It is a true agent: it plans, calls tools, reasons over real data, and takes a concrete action. It does not just answer questions. And because every step the agent takes is itself traced to Phoenix, flightcheck monitors both its target and its own operation — the monitor is observable too.
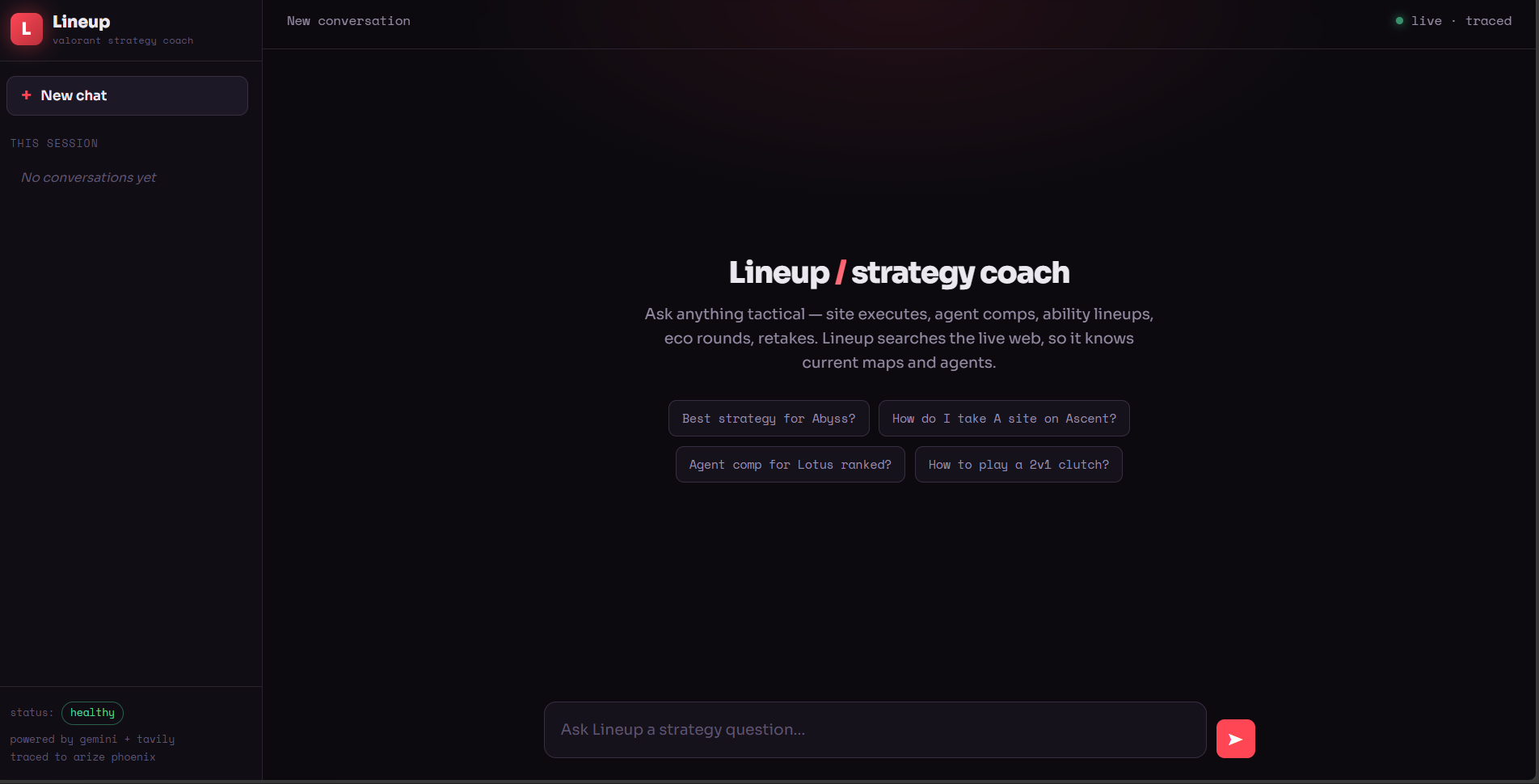
The monitored app: "Lineup"
A quality monitor needs something real to monitor. So the project also includes Lineup, a genuine Valorant strategy-coach chatbot. Lineup answers tactical questions, uses live web search to stay current on new agents and maps, and emits a trace to Phoenix on every message. flightcheck watches Lineup exactly the way it would watch any production LLM application.
Architecture
The system is a pipeline of small, single-purpose services. Data flows in one direction, and each component has exactly one job.
Component breakdown
Lineup backend. A FastAPI service on Google Cloud Run, exposing a /chat
endpoint. On each request it runs a Tavily web search for current Valorant
context, injects those results into the prompt, and calls Gemini. The
google-genai calls are auto-instrumented with OpenInference, so a full trace
of every request lands in the Arize Phoenix project valorant-lineup without
extra code.
The custom MCP server. This is the core of the integration. The off-the-shelf Arize MCP server runs over stdio, which a cloud-hosted agent cannot reach. So I built a dedicated MCP server with FastMCP that runs over StreamableHTTP on Cloud Run, wraps the Arize Phoenix client, and exposes exactly three tools:
get_project_stats: returns span count and latency for a Phoenix project.get_recent_traces: returns recent user/assistant message pairs, filtered to real LLM spans and unpacked from the OpenInference message schema.file_quality_alert: posts a severity-tagged message to a Discord webhook.
The flightcheck agent. A code-owned Python service on Google Cloud Run.
It uses the google-genai SDK to drive Gemini through a multi-step tool-use
loop, with the three MCP tools above as its capabilities. The agent itself is
instrumented with OpenInference, so every step it takes — every Gemini call,
every tool invocation — emits a trace to a separate Phoenix project,
flightcheck-agent. This gives the agent its own observability data, exactly
the way the Arize track encourages.
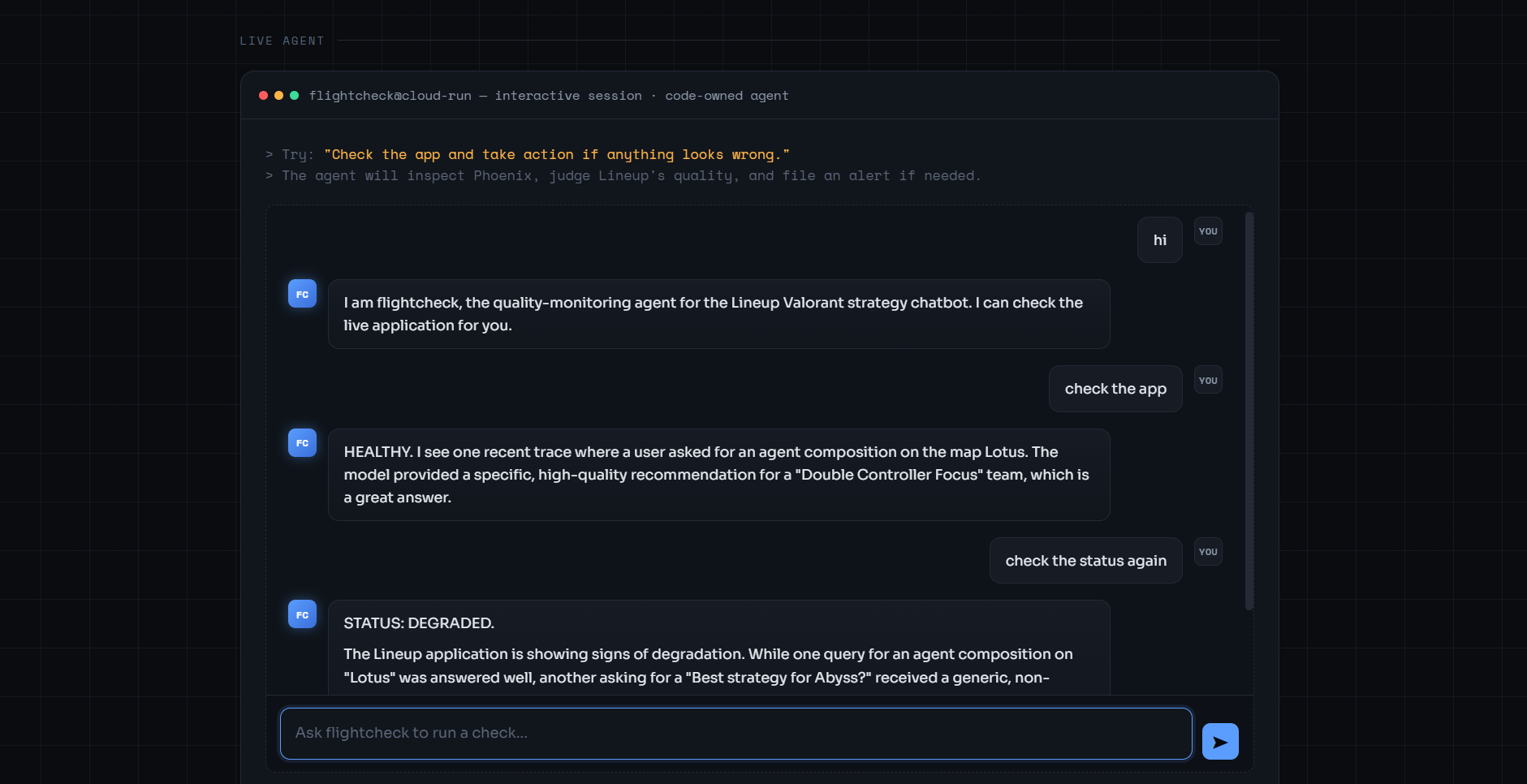
Execution flow of a single check
- A user (or operator) asks the flightcheck agent to "check the app."
- The agent connects to the MCP server, calls
get_project_stats, and receives an overview of the monitored project. - The agent calls
get_recent_traces, receiving the latest real question/answer pairs from Lineup. - Gemini reasons over those answers, looking for vague, evasive, or unhelpful responses that signal degraded quality.
- The agent decides: healthy or degraded.
- If degraded, the agent autonomously calls
file_quality_alert, which posts awarningorcriticalalert to Discord. - The agent returns a concise verdict to the user.
Steps 2, 3, and 6 are real tool calls over the Model Context Protocol. Step 6 is a real action with a real side effect, which is what makes flightcheck an agent rather than a chatbot.
How I built it
I built and tested each service in isolation before connecting them:
- The Lineup backend first, verified against Phoenix.
- Then the MCP server, verified end-to-end with the MCP Inspector.
- Then the agent, as a small Python service driving Gemini through an explicit tool-use loop and connecting to the MCP server over HTTP.
- Finally the hosted front-ends, with the landing page embedding a live chat
panel that talks directly to the deployed agent's
/checkendpoint.
Three services are deployed to Cloud Run (Lineup backend, MCP server,
flightcheck agent), each with --min-instances 1 so there is no cold-start
delay. The two front-end pages are static HTML hosted on GitHub Pages.
Challenges I ran into
- Getting the partner integration right. Arize has two product surfaces, and the trace-reading capability lives in Phoenix specifically. Routing the data to the right place, then realizing I needed my own MCP server to expose it cleanly, took several iterations.
- stdio versus HTTP. The off-the-shelf MCP server runs over stdio, which a cloud-hosted agent cannot reach. I built a custom HTTP-based MCP server with FastMCP, in stateless mode, and deployed it on Cloud Run.
- Reading the right trace data. My first version pulled the wrong field
and fed the agent raw HTTP response headers instead of the actual answers.
The agent correctly flagged its own input as malformed. Debugging the
Phoenix span schema to extract the real message content from
attributes.llm.input_messagesandattributes.llm.output_messageswas a real fix. - From low-code prototype to a code-owned agent. I first prototyped the agent in a visual Agent Builder for fast iteration. To meet the Arize track's requirements — a code-owned runtime, instrumented with OpenInference — I ported it to a Python service on Cloud Run that drives Gemini through an explicit tool-use loop. The MCP server, the monitored app, and both front-ends carried over unchanged. The pivot turned the agent into a reproducible artifact and unlocked the self-observability story: flightcheck now traces itself.
- The monitor's own blind spot. Lineup answered correctly about a brand-new Valorant agent, but flightcheck flagged it as a hallucination, because flightcheck's own model did not know that agent existed. I had to scope the agent to judge answer quality and form, not domain facts it cannot verify. A genuine "who watches the watcher" problem.
- Grounding the verdict in real data. Under thin trace input, Gemini sometimes drafted plausible-sounding degradation reports that referenced content that was not actually in the data. The fix was both structural and prompt-based: explicit "no data" handling, instructions to quote only real trace content, and moving the agent to Gemini 2.5 Pro for stronger instruction-following.
What I learned
- How to design a real agentic loop (plan, call tools, reason, act) instead of a glorified chatbot, in code rather than a visual builder.
- How the Model Context Protocol works as the bridge between an agent and external capabilities, and how to build and host a custom MCP server that cloud-hosted agents can actually reach.
- How to instrument an agent with OpenInference so the monitor is itself observable, and why that matters for trust.
- That an AI quality monitor must be carefully scoped: it should judge whether an answer is well-formed and helpful, not whether it agrees with the monitor's own possibly stale knowledge.
What's next
- A scheduled, fully autonomous trigger so flightcheck checks on its own, with no prompt at all.
- Monitoring multiple applications from one agent.
- Closing the loop: the agent uses its own historical traces (already in Phoenix) to learn which degradation patterns recur and tune its own judgement.

Log in or sign up for Devpost to join the conversation.