Inspiration
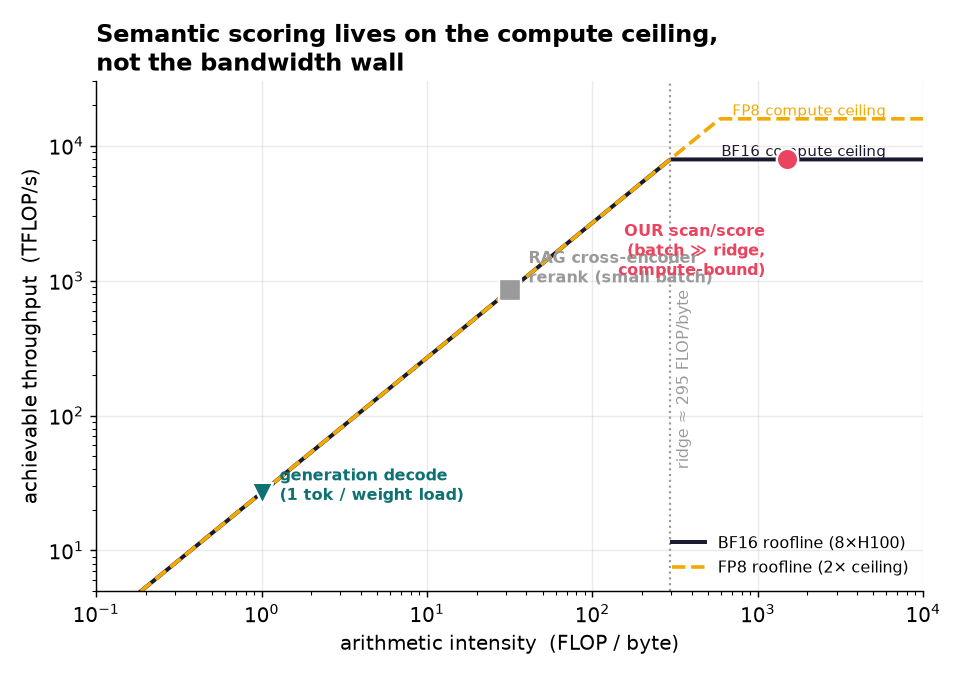
RAG exists because inference has historically been expensive. Teams precompute embeddings, build vector indexes, and move retrieved context around to avoid asking the model to read too much. FlashGrep starts from the opposite assumption: as inference-time compute gets cheaper, we can spend compute directly on raw text and make search interactive.
What it does
FlashGrep is a live semantic filtering system. A user or agent writes a natural-language predicate, and FlashGrep scores raw chunks directly with an LLM-style scorer. It caches relevance scores, supports instant refinements, re-thresholding, and fresh-file ingestion without rebuilding an index. The result is a search loop that feels like “grep for meaning.”
How we built it
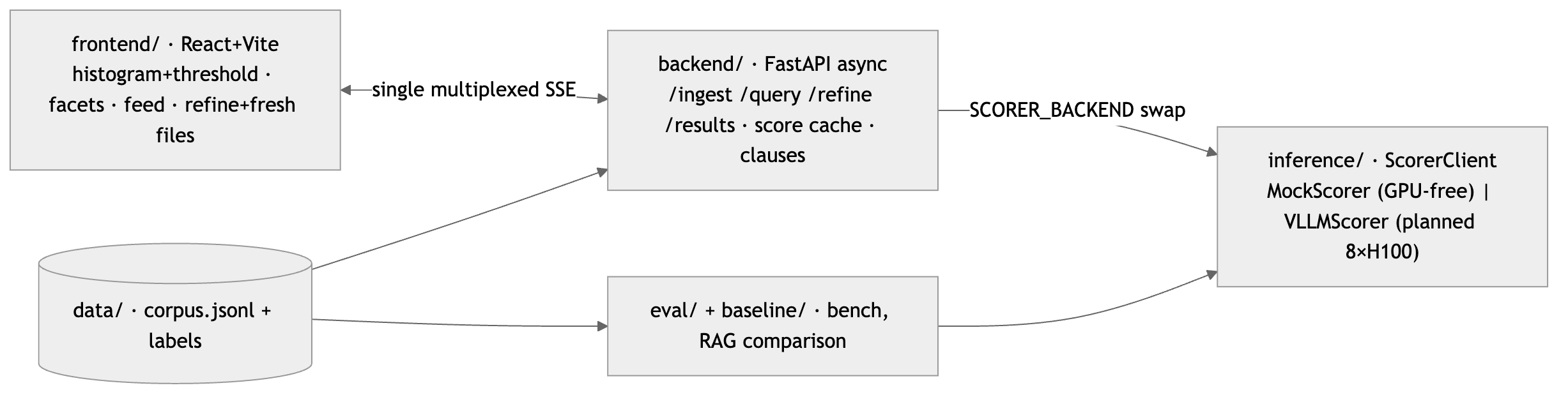
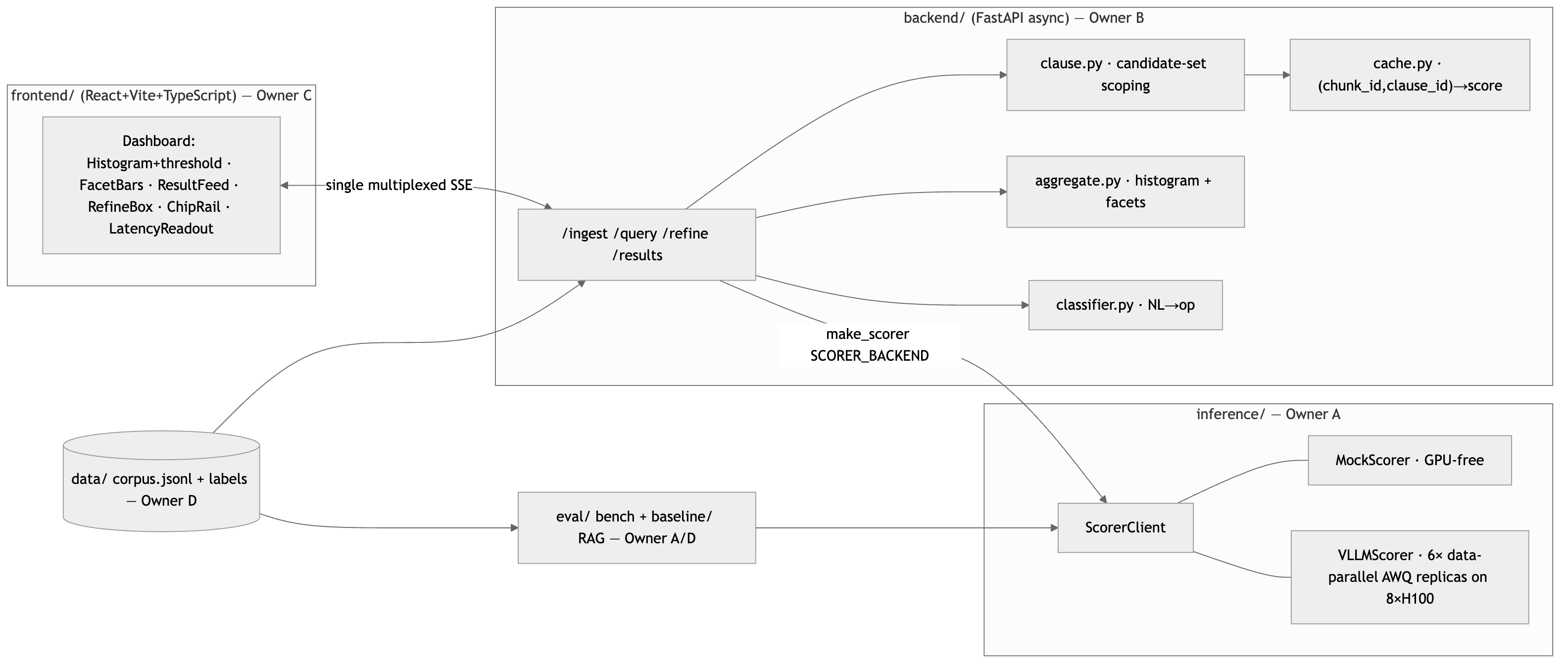
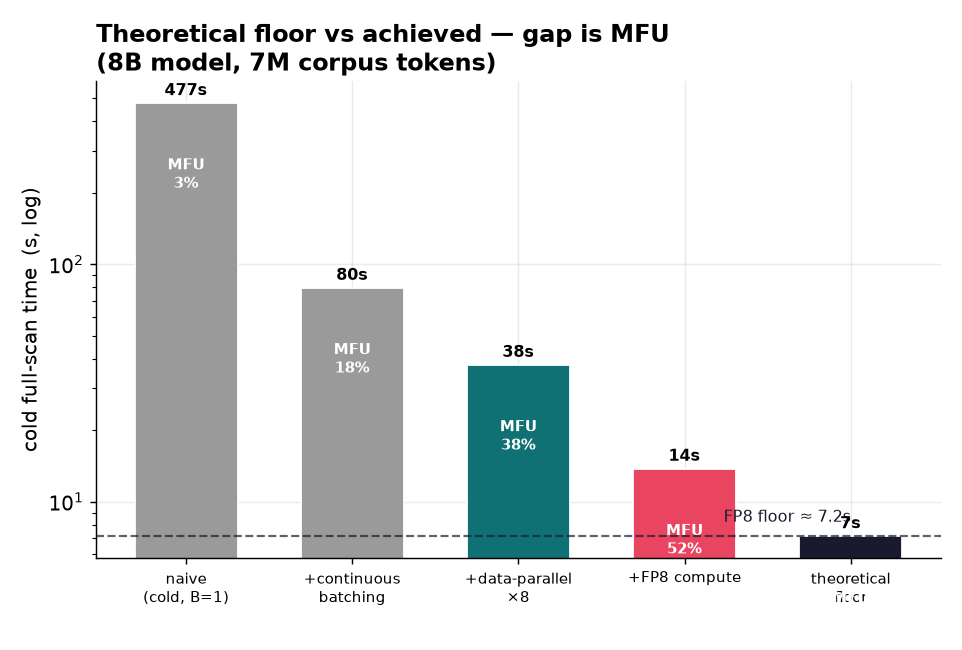
We built a FastAPI backend, React dashboard, score cache, refinement engine, RAG baseline, MCP tools, and H100 benchmarking harness. The core path scores chunks once, stores clause-level relevance, and scopes later refinements to cached survivors. We also added performance models, architecture assets, eval logging, and Prime/Modal benchmark artifacts.
Challenges we ran into
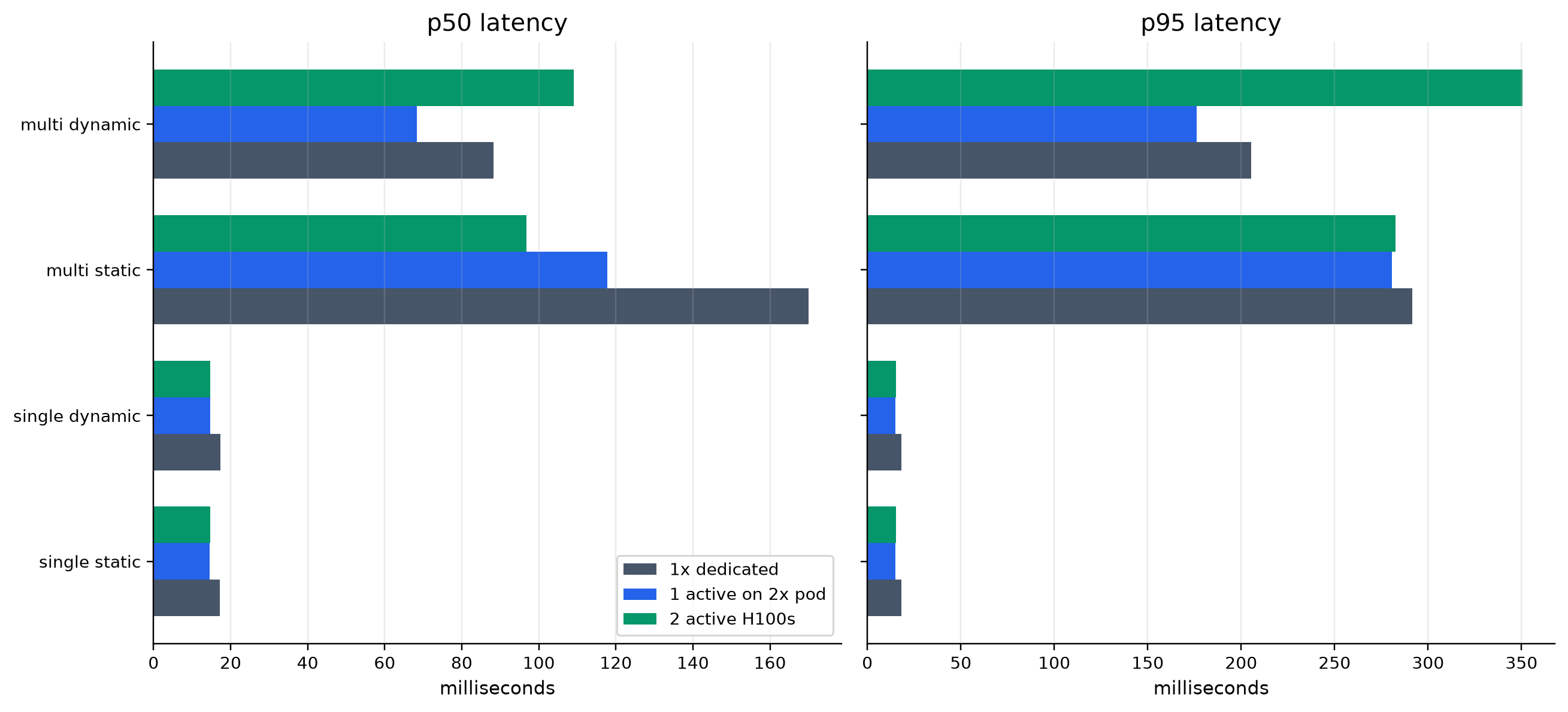
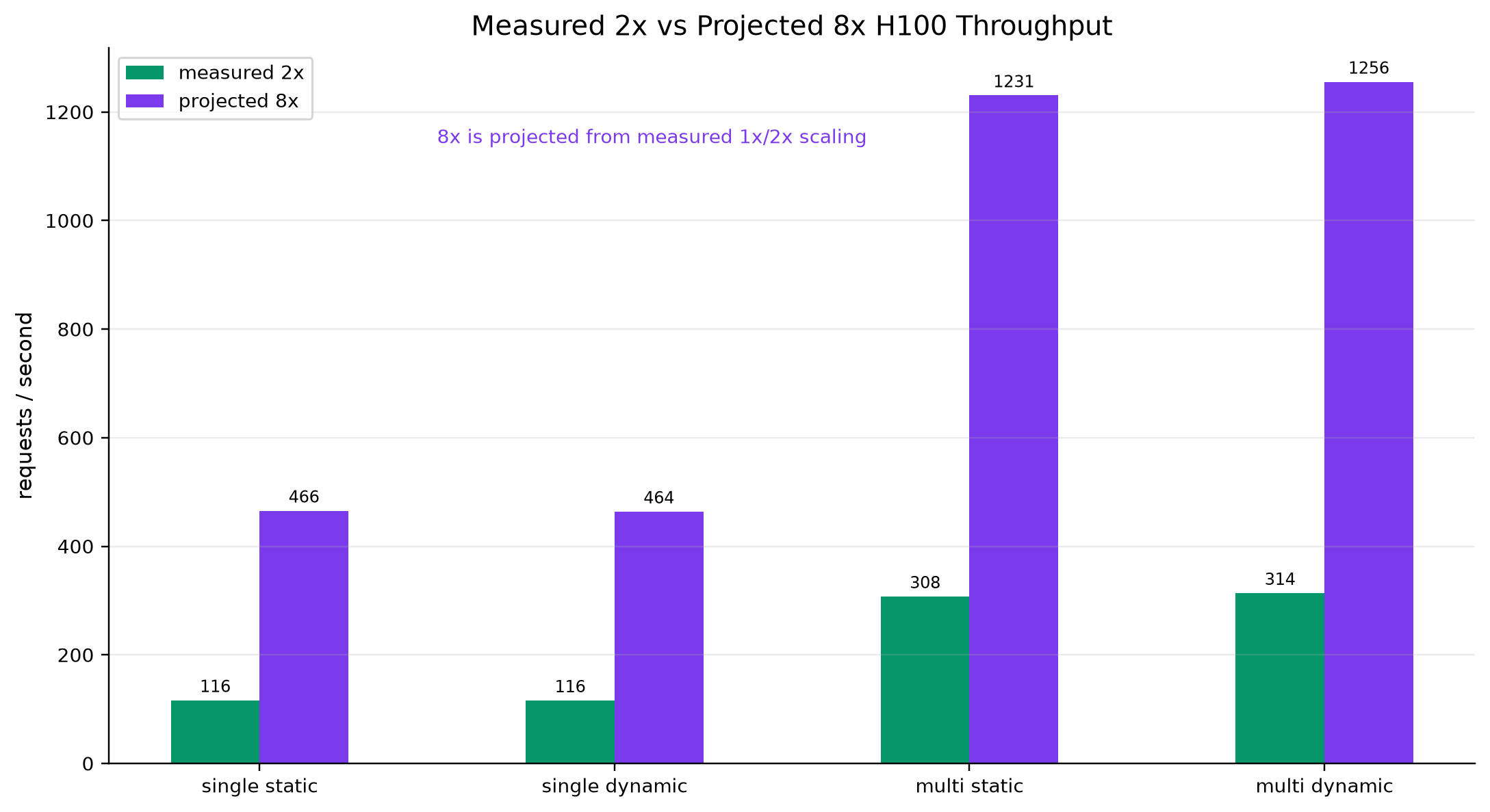
The hardest part was separating real measured claims from projections. We had to handle limited GPU availability, under-saturated early runs, threshold calibration differences between the mock scorer and real vLLM, and fair comparisons against RAG. We also had to make the demo reliable while keeping the performance story honest.
Accomplishments that we're proud of
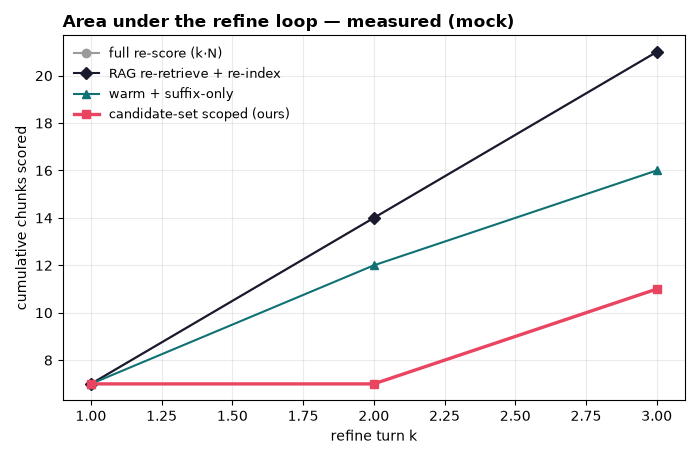
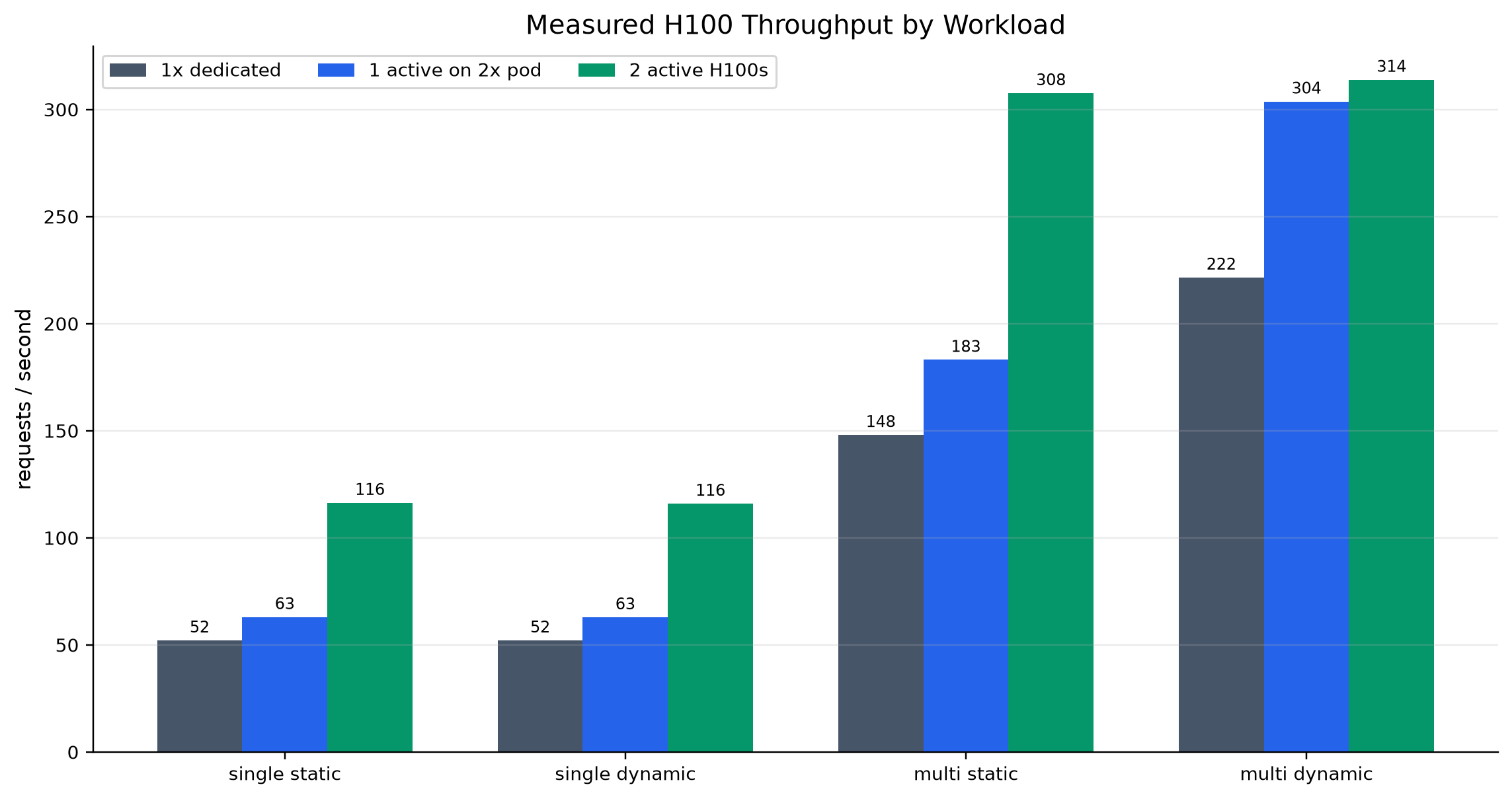
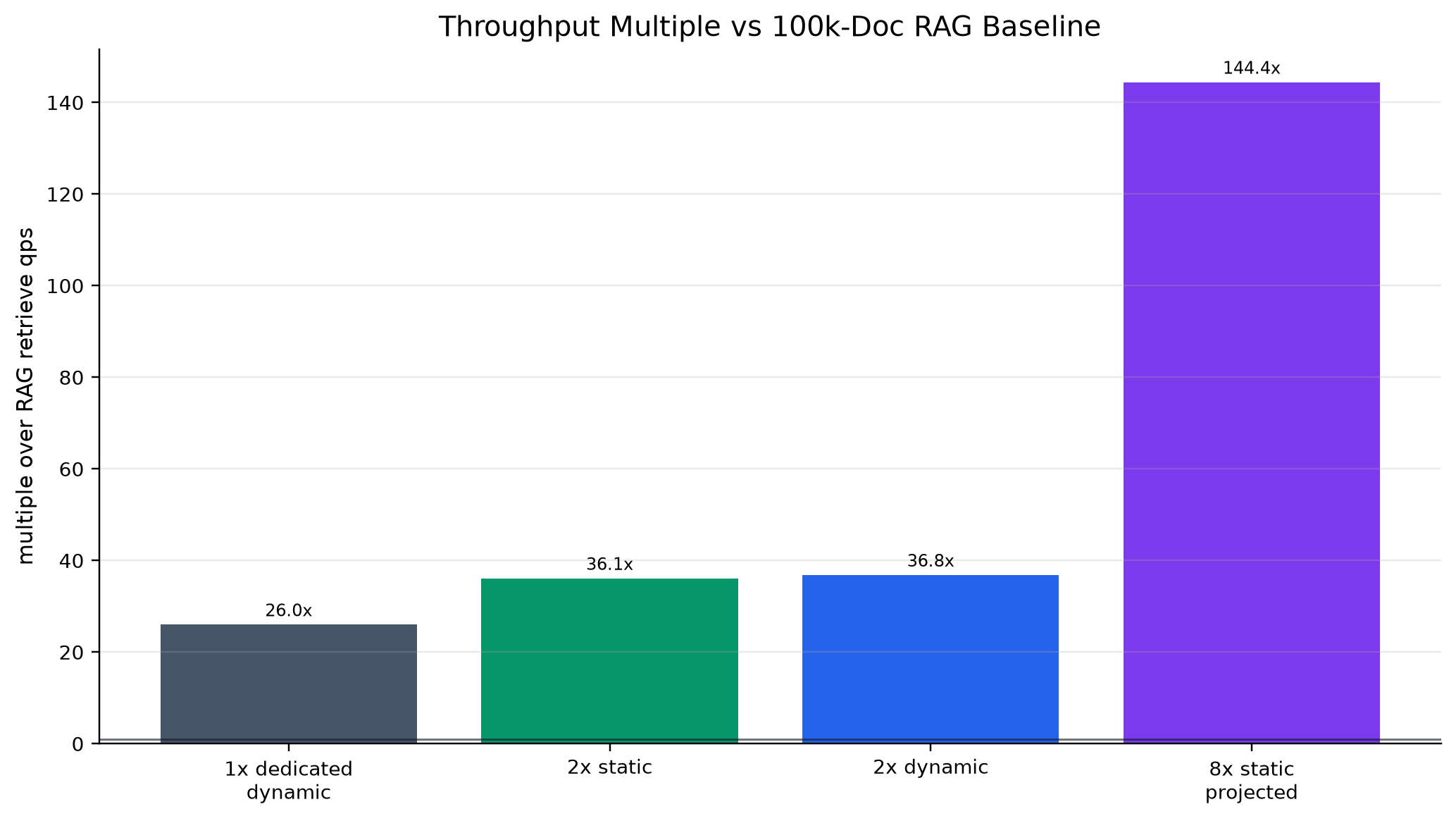
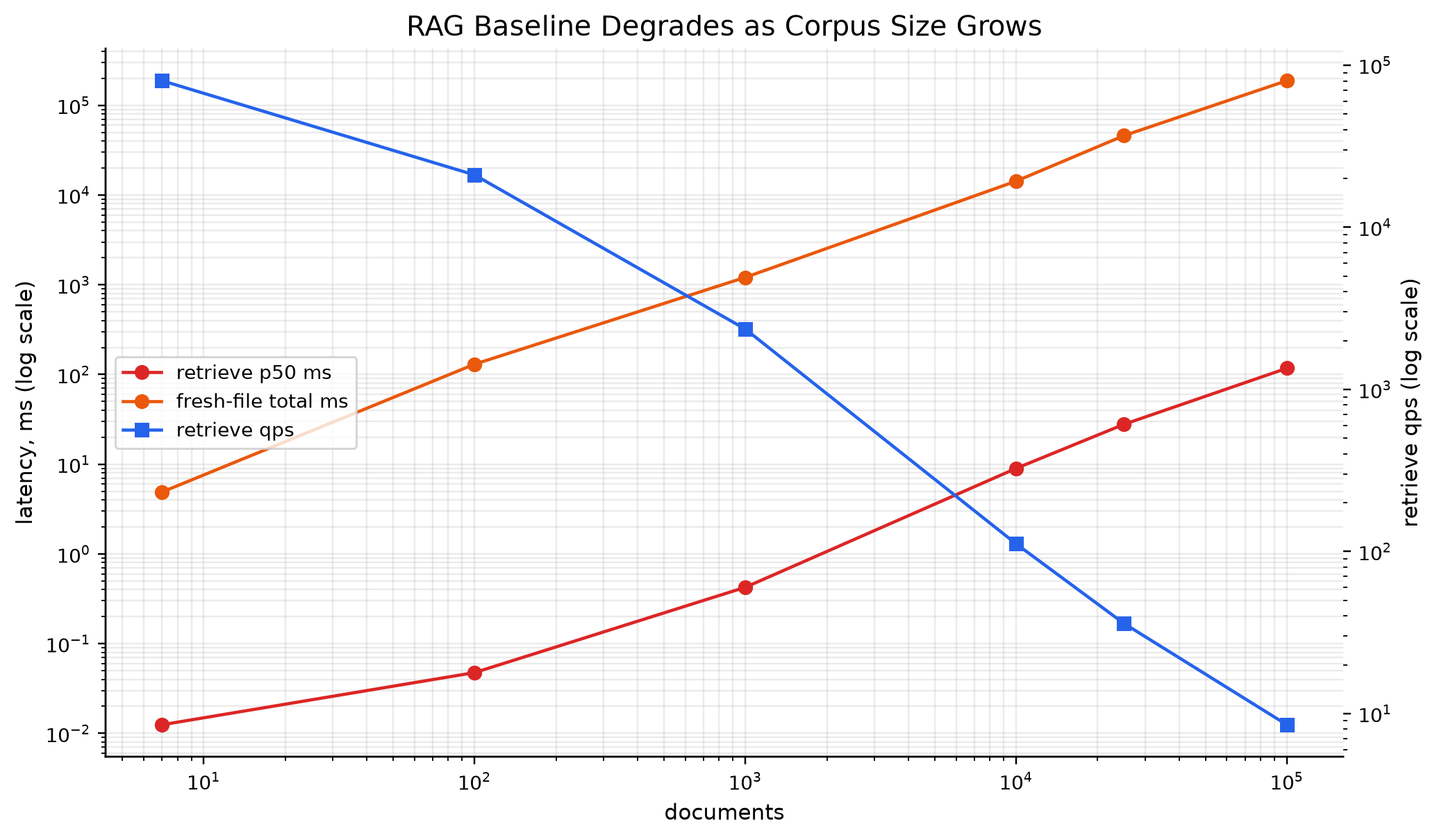
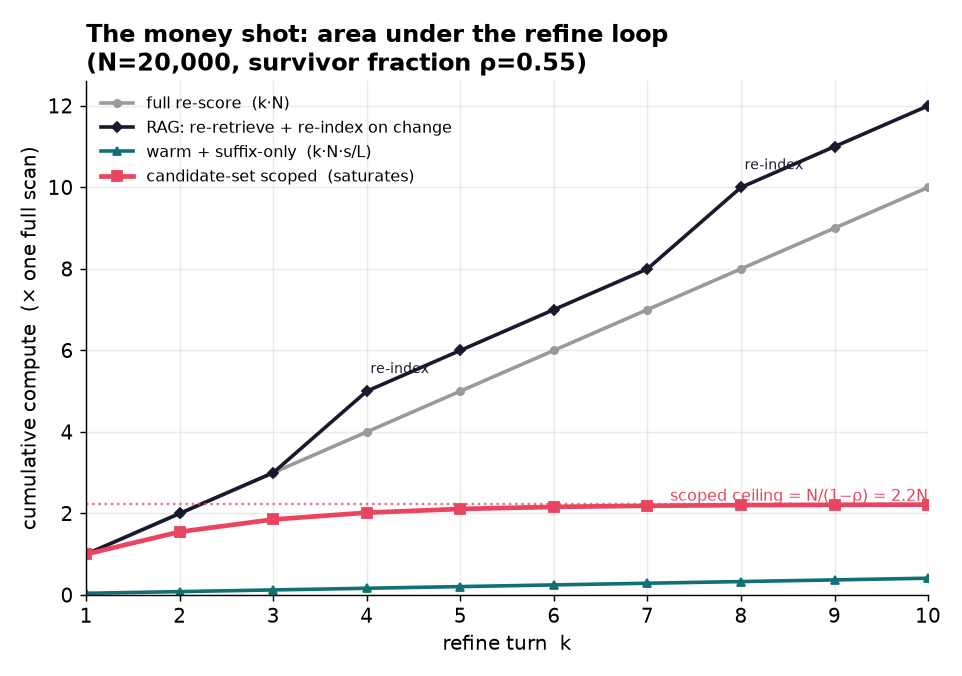
We built an end-to-end interactive demo, a reproducible eval harness, and an MCP interface agents can call directly. On larger workloads, our measured H100 runs showed strong throughput advantages over the 100k-document RAG baseline, including roughly a 36x throughput multiple. We are also proud of the refine-loop metric: cached scoped refinement flattens cumulative work instead of compounding every turn.
What we learned
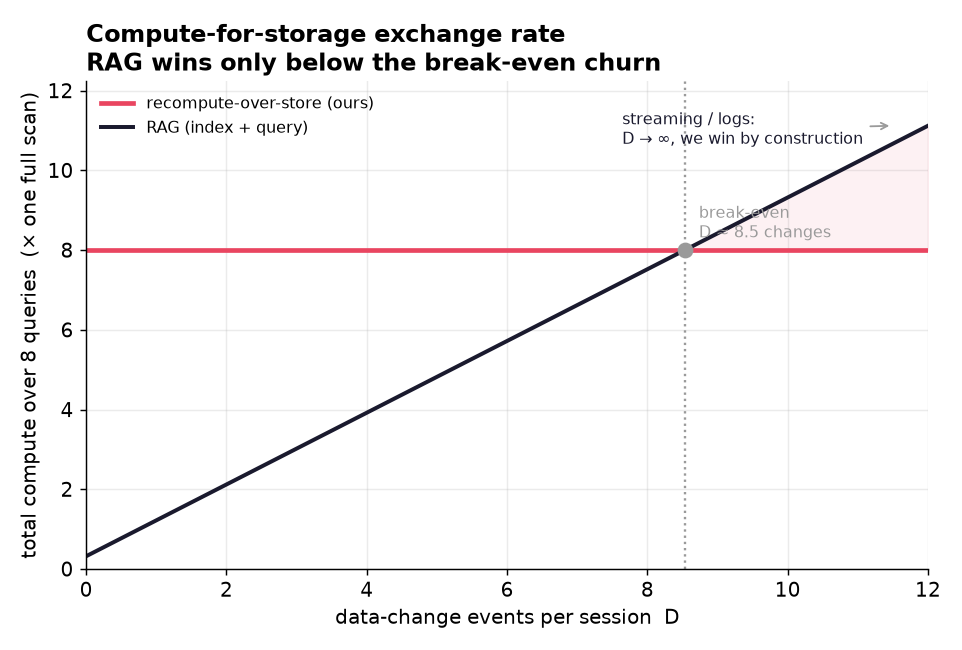
The main lesson is that latency is only one part of retrieval performance. The deeper metric is work over an interaction loop: how much computation, indexing, memory, and data movement are required as the user or agent keeps refining. We also learned that RAG still wins tiny one-shot lookups, while FlashGrep is strongest for iterative search, fresh data, and agent loops.
What's next for FlashGrep
Next we want to harden the real vLLM path, run broader gold-set evaluations, improve GPU saturation, and expand the MCP interface so agents can search code, papers, and dynamic corpora. We also want to continue the RL-style agent loop: letting agents refine queries automatically, verify evidence, and stop when reward or answer quality crosses a target.
Built With
- arxiv-api
- awq-marlin
- browsecomp-plus
- claude-code
- fastapi
- h100-gpus
- hugging-face-datasets
- matplotlib
- mcp
- mermaid
- modal
- prime-intellect
- pydantic
- python
- qwen/qwen2.5
- react
- sse
- typescript
- vite
- vllm
- weave/w&b

Log in or sign up for Devpost to join the conversation.