-
-
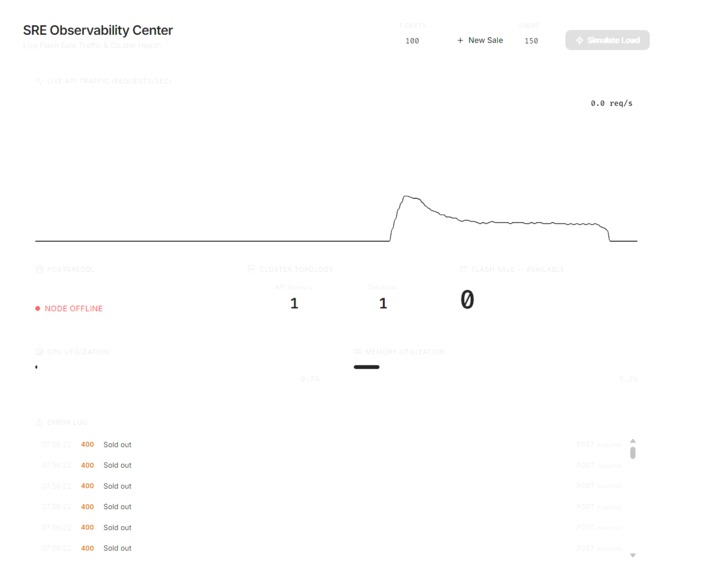
SRE dashbaord
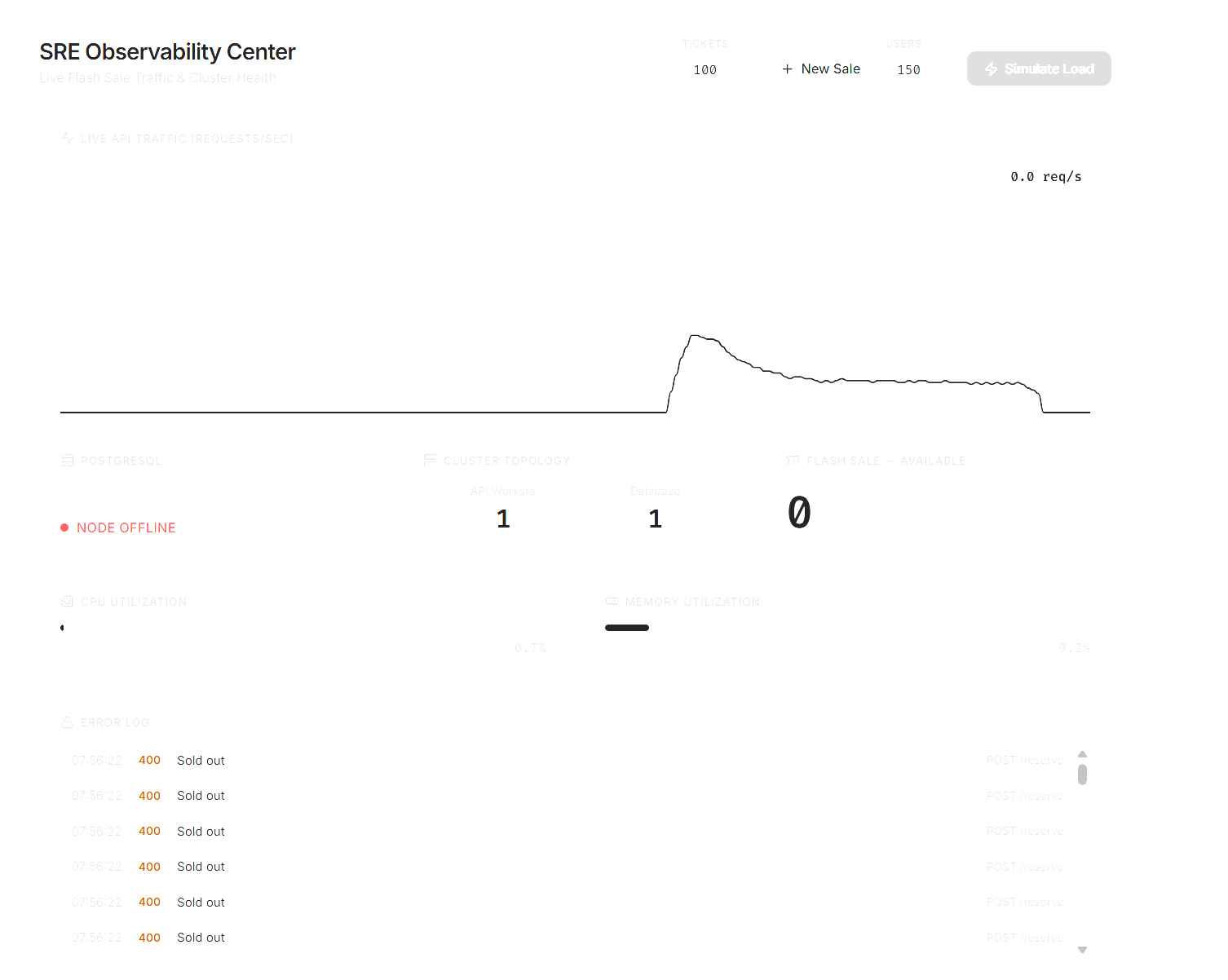
Inspiration
Flash sales are one of the hardest concurrency problems in production engineering. When thousands of users hit "Buy" at the same instant, most naive systems oversell inventory. We wanted to build a system that provably never oversells — and prove it can survive being killed mid-transaction.
What it does
A ticket reservation API that handles flash sale events under extreme concurrent load. Users create events with a fixed ticket count, and thousands of concurrent users race to reserve tickets. The system guarantees:
- Exactly N tickets sell — never more, never less
- Duplicate users are blocked — one reservation per user per event
- Crashes don't corrupt data — mid-flight transactions roll back automatically
- Containers self-heal — kill any service and it auto-restarts in seconds
A real-time React dashboard provides SRE-style observability: database health, CPU/RAM, Gunicorn worker count, live RPS charting, and an error log feed.
How we built it
- Flask + Peewee ORM on PostgreSQL with
SELECT ... FOR UPDATEpessimistic row-level locking insidedb.atomic()transactions - Gunicorn with
gthreadworkers and a custom autoscaler that scales 1–6 workers based on real-time RPS - Docker Compose orchestrating API, PostgreSQL, and React frontend with
restart: alwaysand persistent volumes - GitHub Actions CI with a coverage gate that blocks any push below 70%
- 38 pytest tests at 92% coverage including crash recovery, data consistency, and input boundary validation
Challenges we faced
- Duplicate reservation rollback — When a user tries to reserve twice, the ticket count was already decremented. We solved this with nested savepoints that restore the count on
IntegrityError. - RPS measurement across forked workers — Gunicorn forks processes, so module-level counters are process-local. We used
multiprocessing.Valuewith locks for the request counter andthreading.Lockfor the RPS computation. - Docker restart behavior on Windows —
docker kill+restart: alwayshas delayed recovery on Docker Desktop vs Linux. We documented this and verified recovery works correctly in production-like environments.
What we learned
- Pessimistic locking is the only safe approach for inventory systems — optimistic retry loops can still oversell under burst load
- Chaos engineering is more useful than unit tests for finding real production failures
- A live dashboard makes reliability features 10x more compelling to demonstrate
Built With
- docker
- docker-compose
- flask
- github-actions
- gunicorn
- peewee
- postgresql
- pytest
- python
- react
- vite

Log in or sign up for Devpost to join the conversation.