-
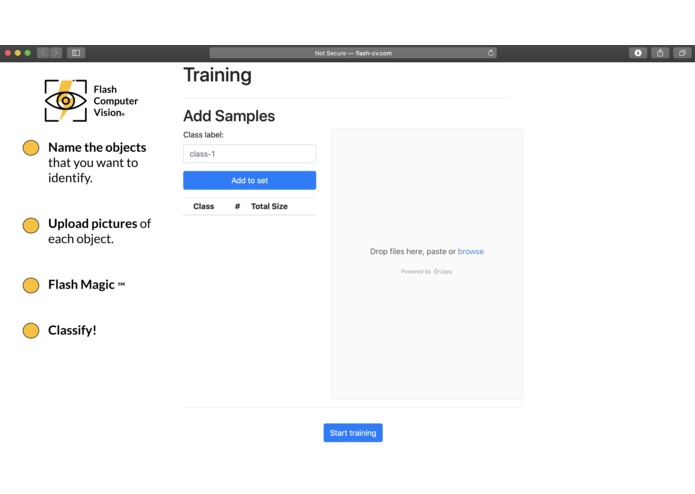
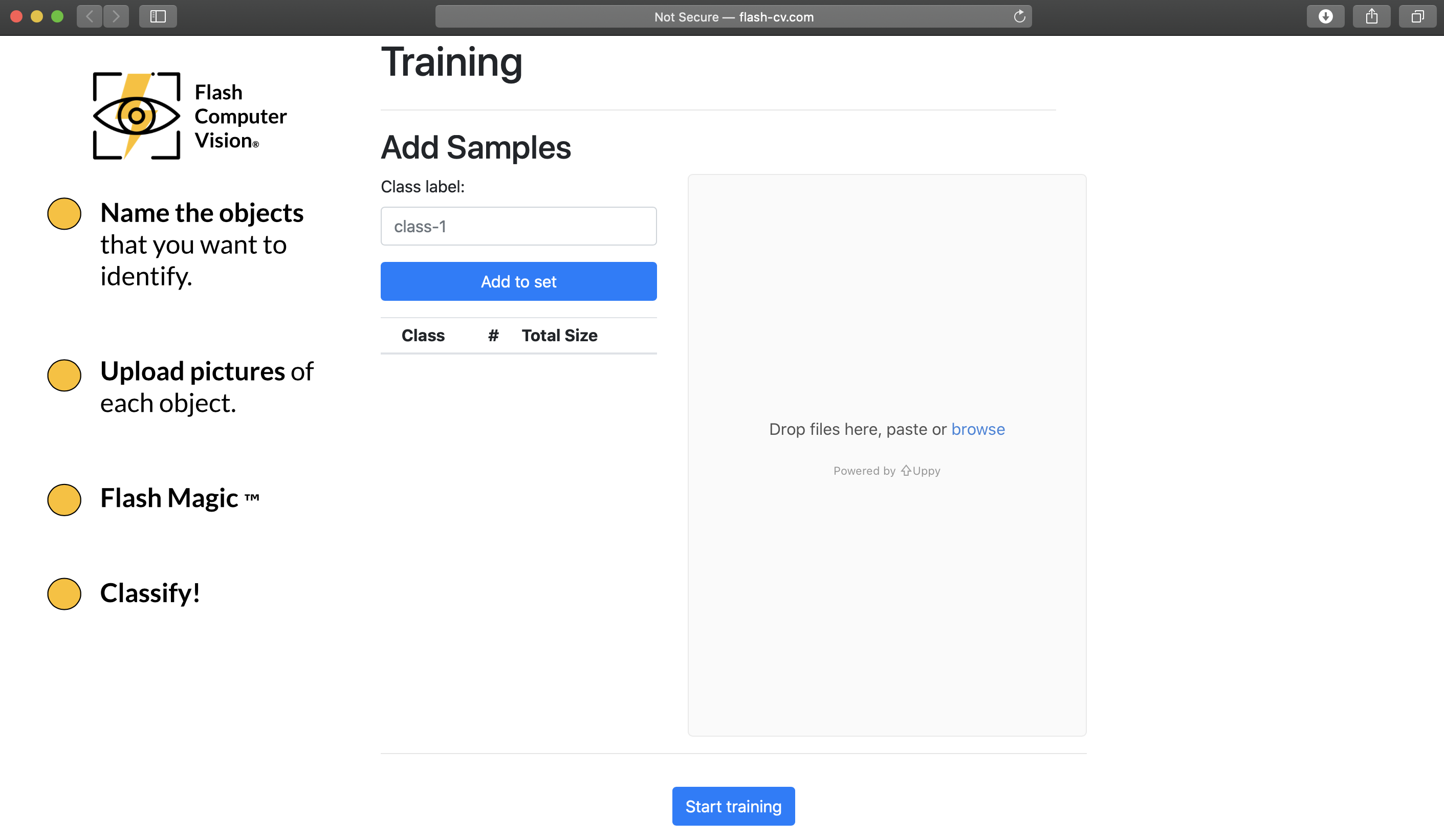
Simple and Intuitive Landing Page.
-
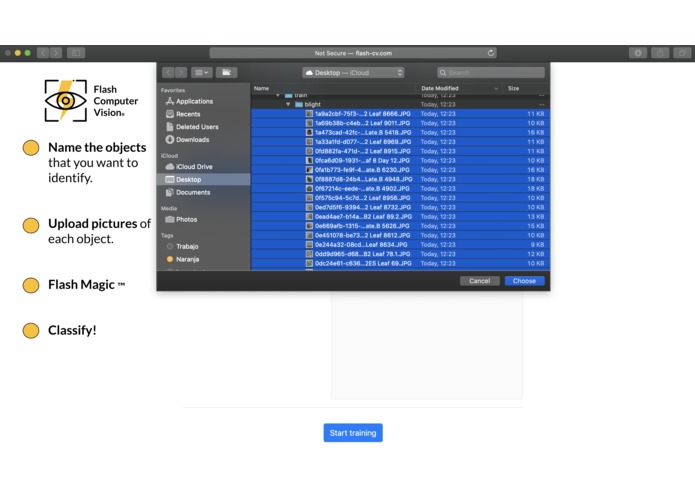
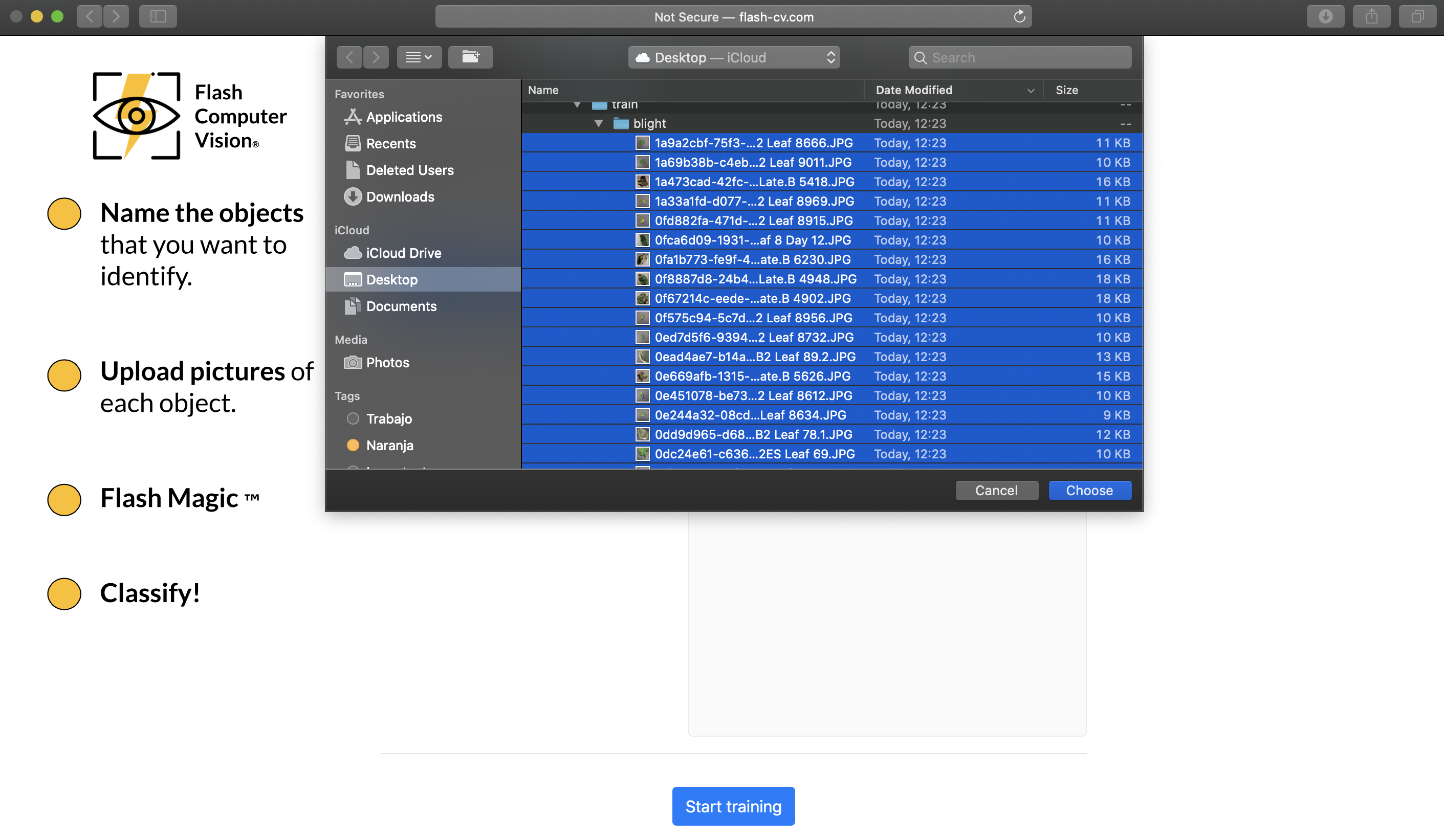
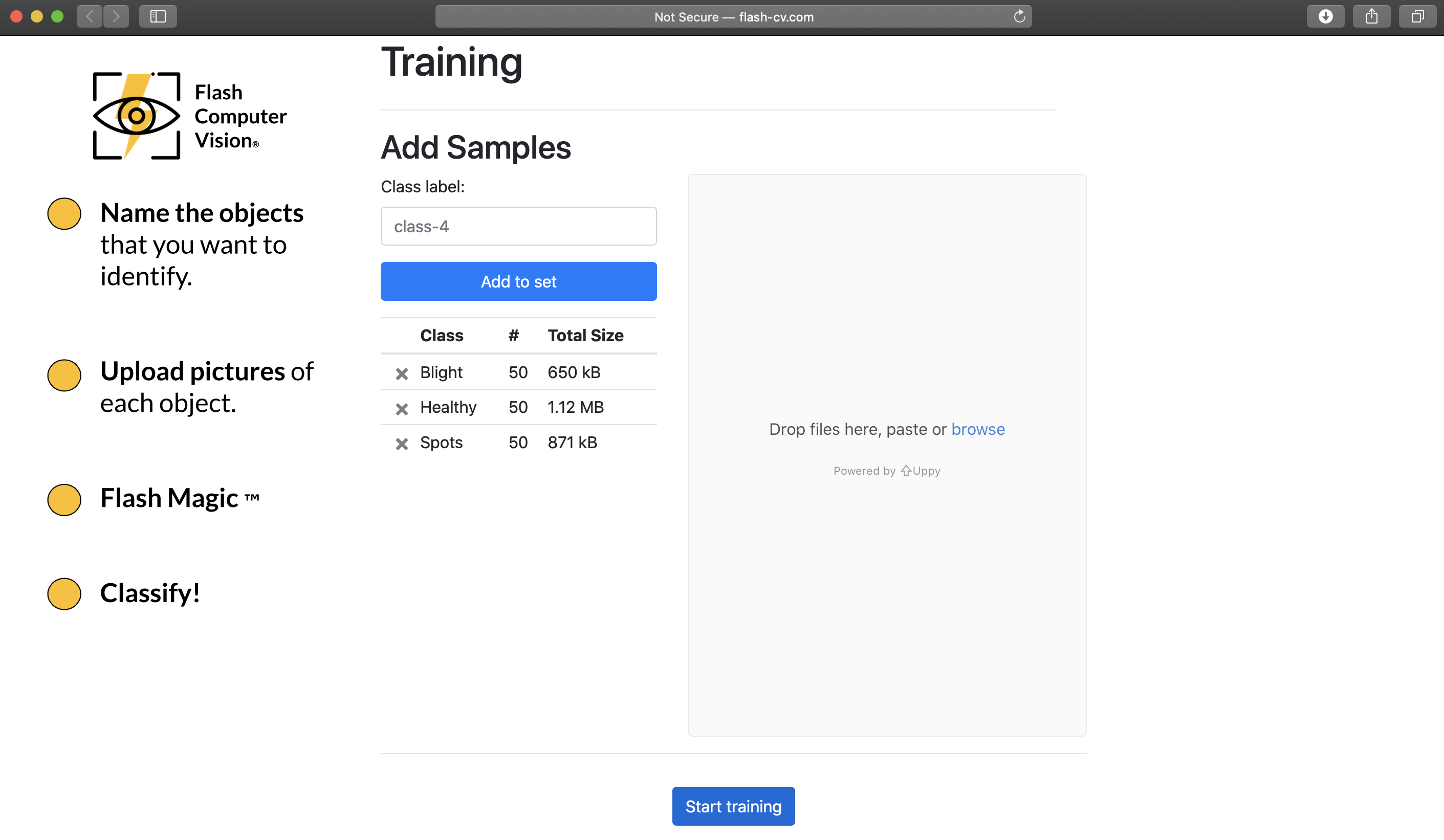
Easy to upload multiple images at once.
-
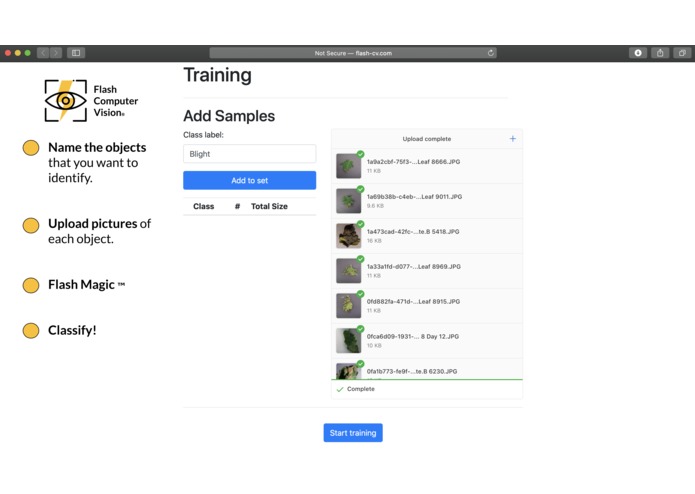
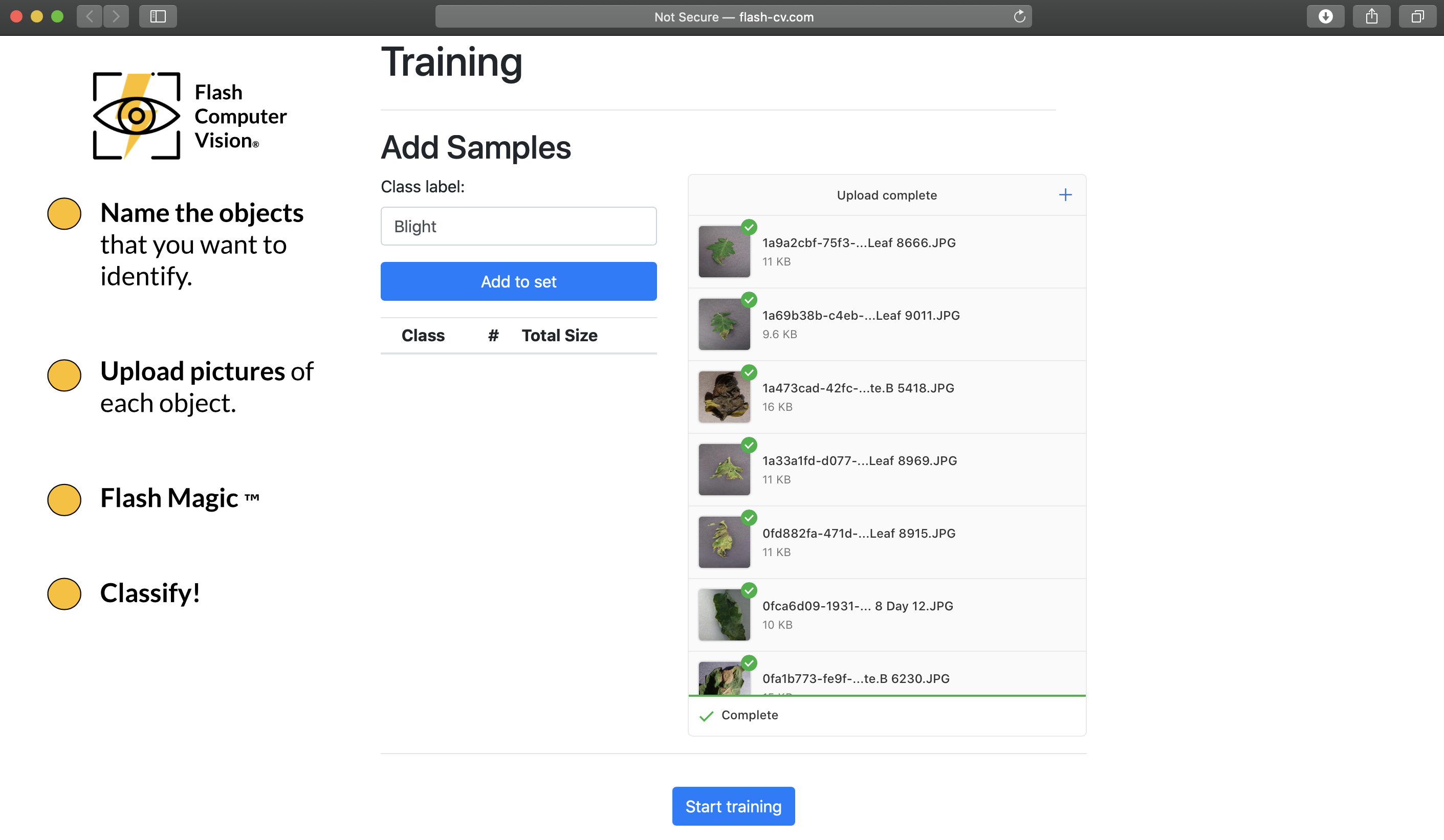
Easy to create the first category.
-
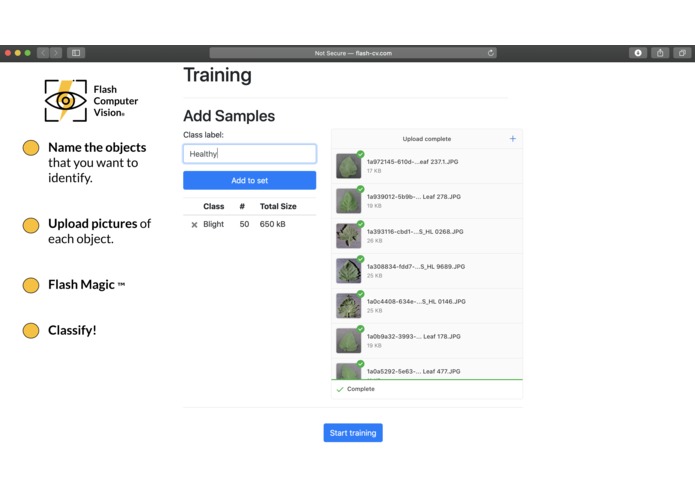
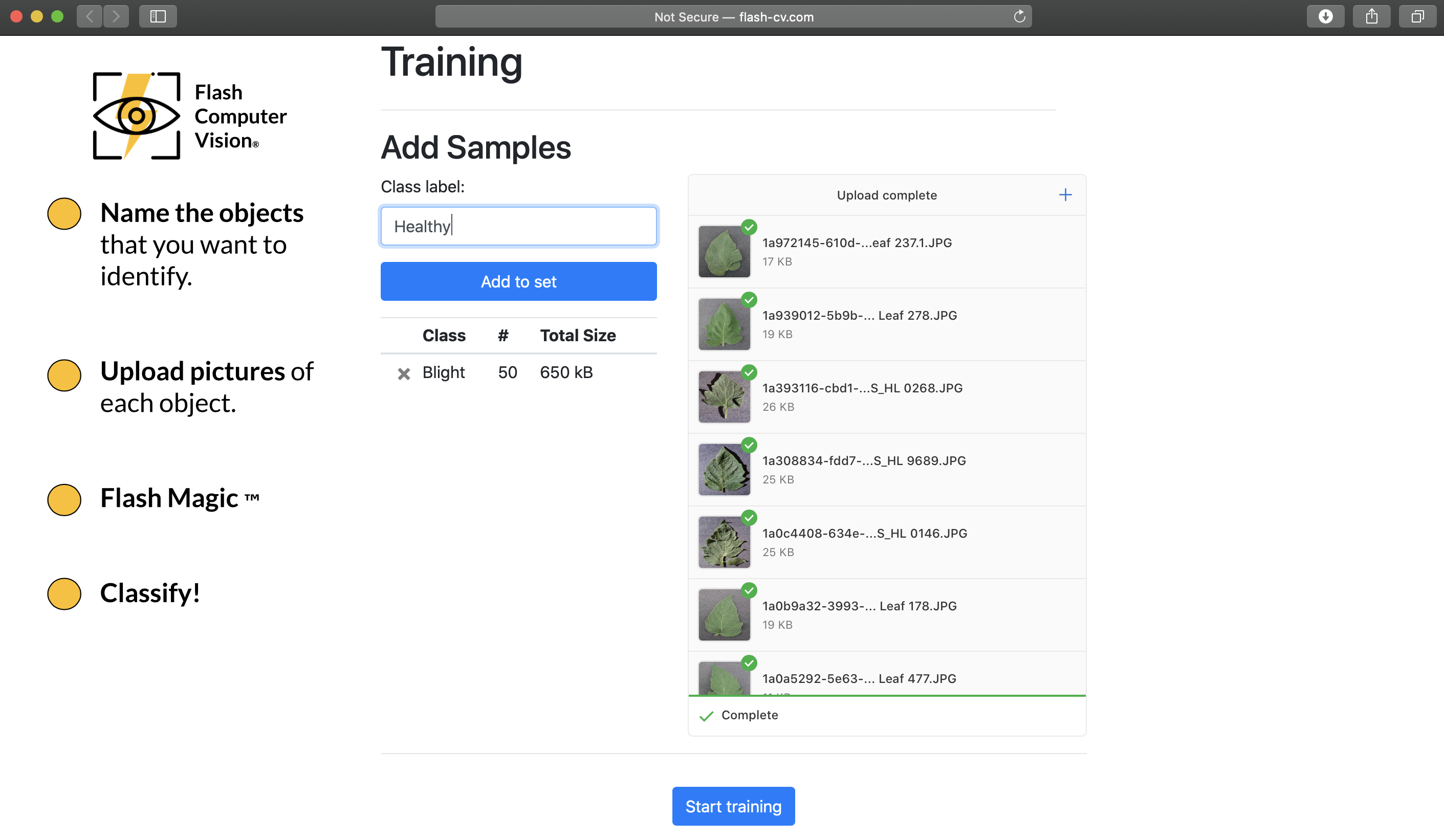
Easy to create the second category.
-
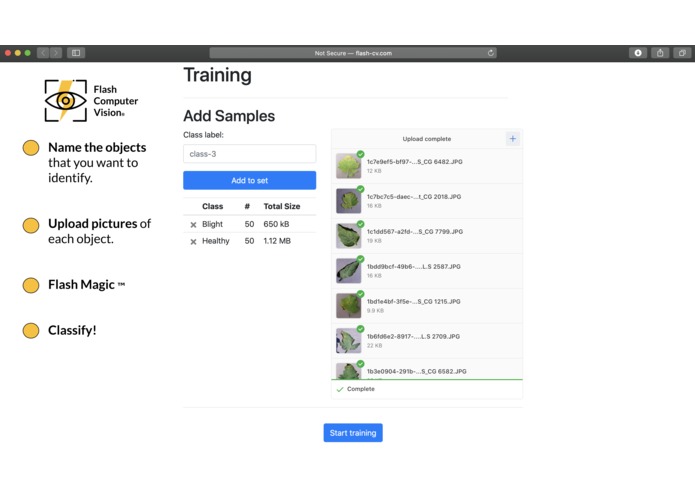
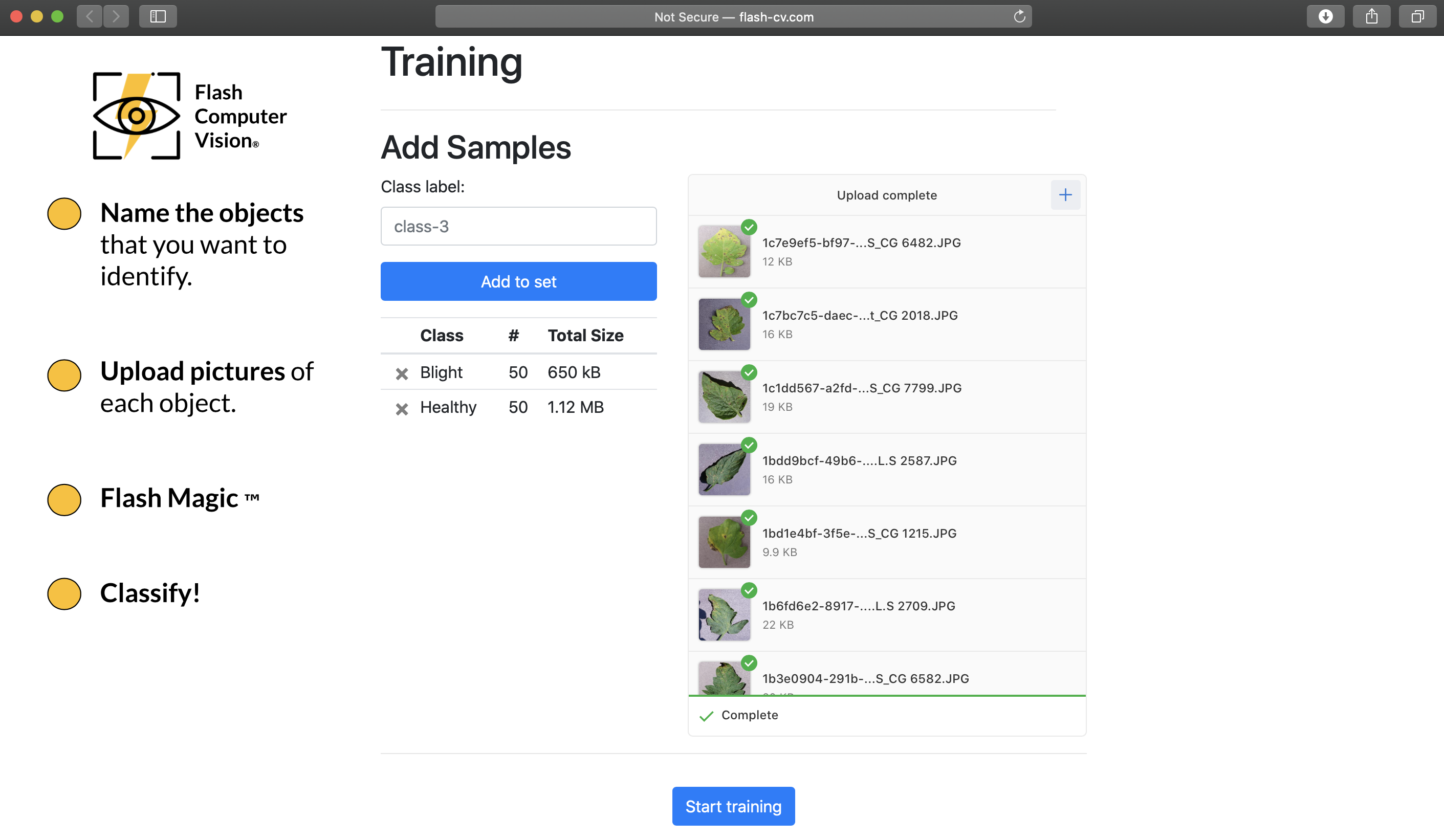
Easy to create the third category.
-
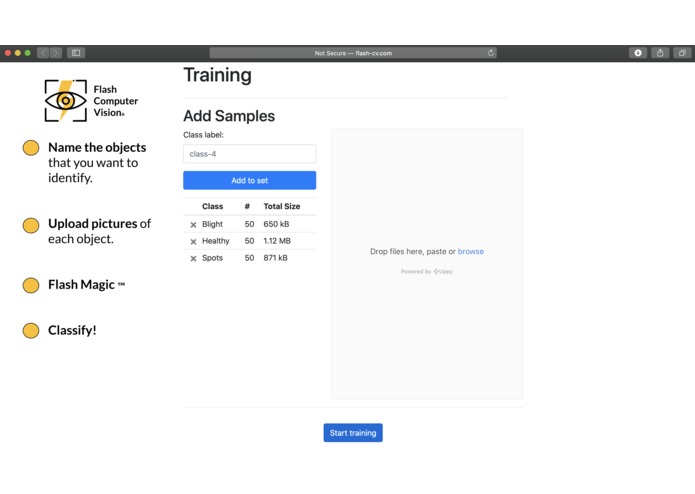
We are ready for training! Everything that the user needs to do to create an image classifier has been done.
-
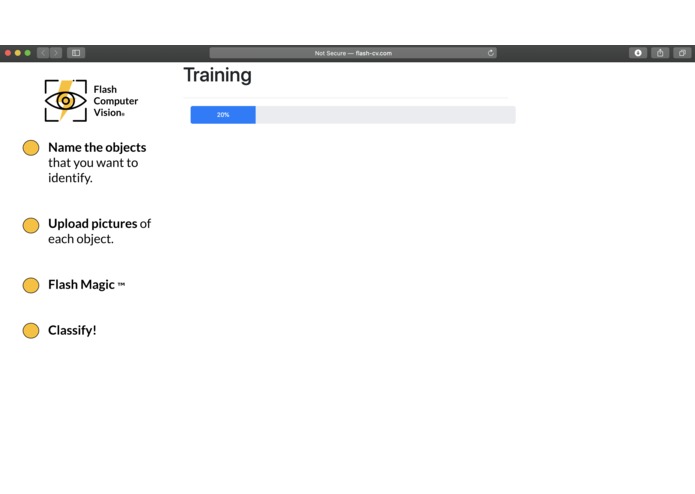
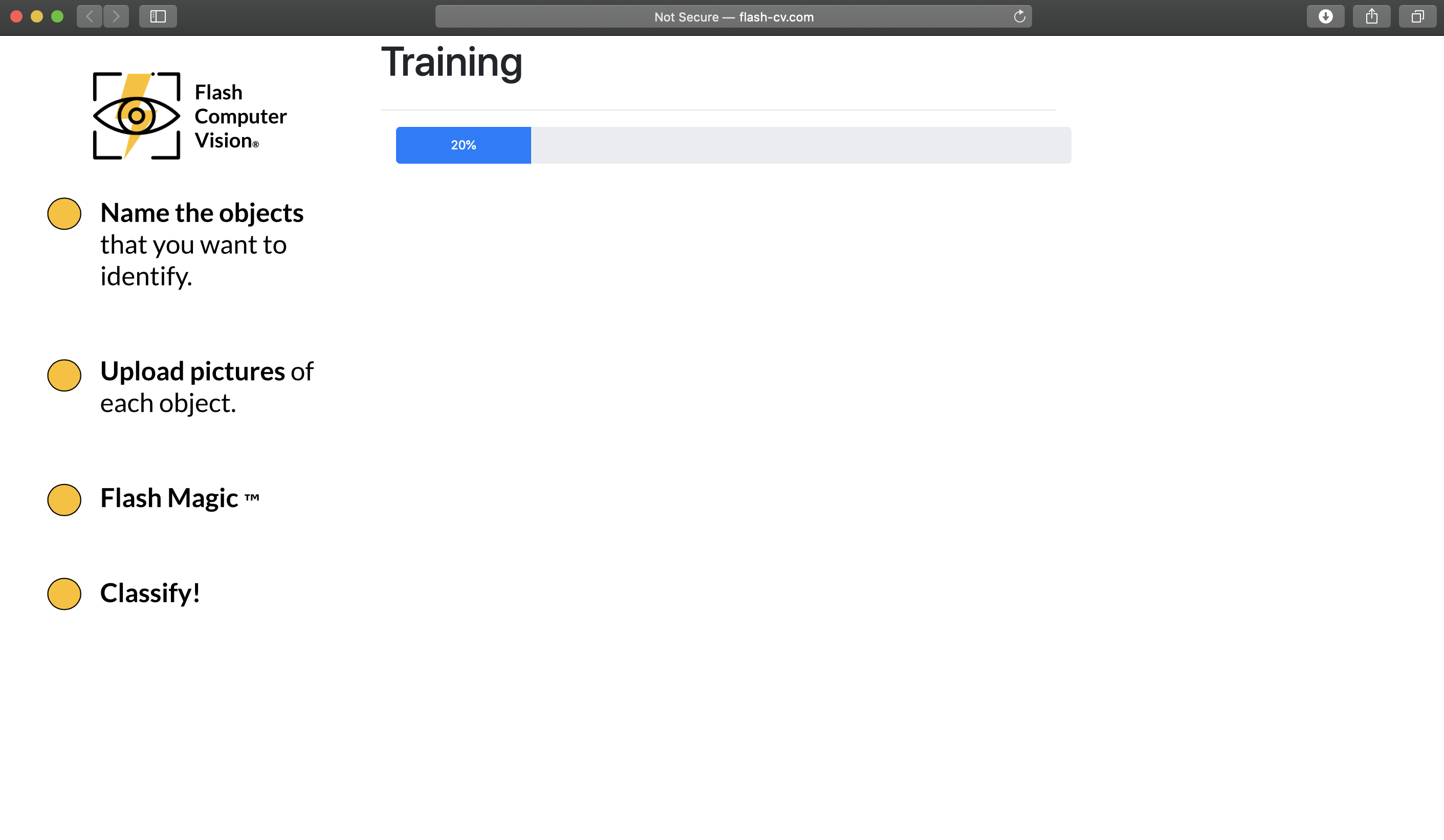
Training...
-
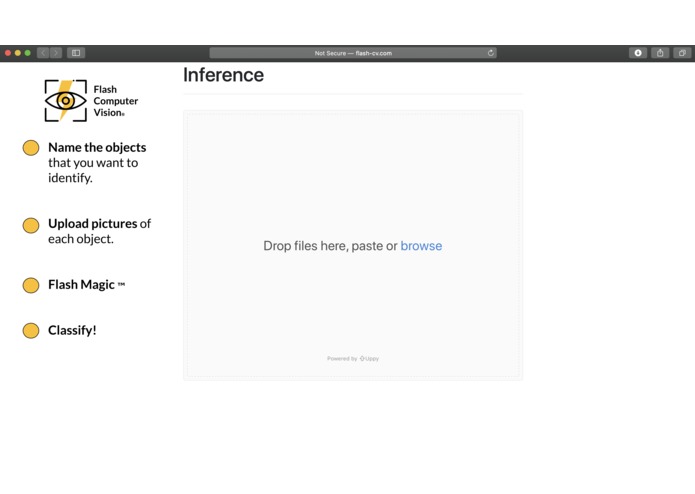
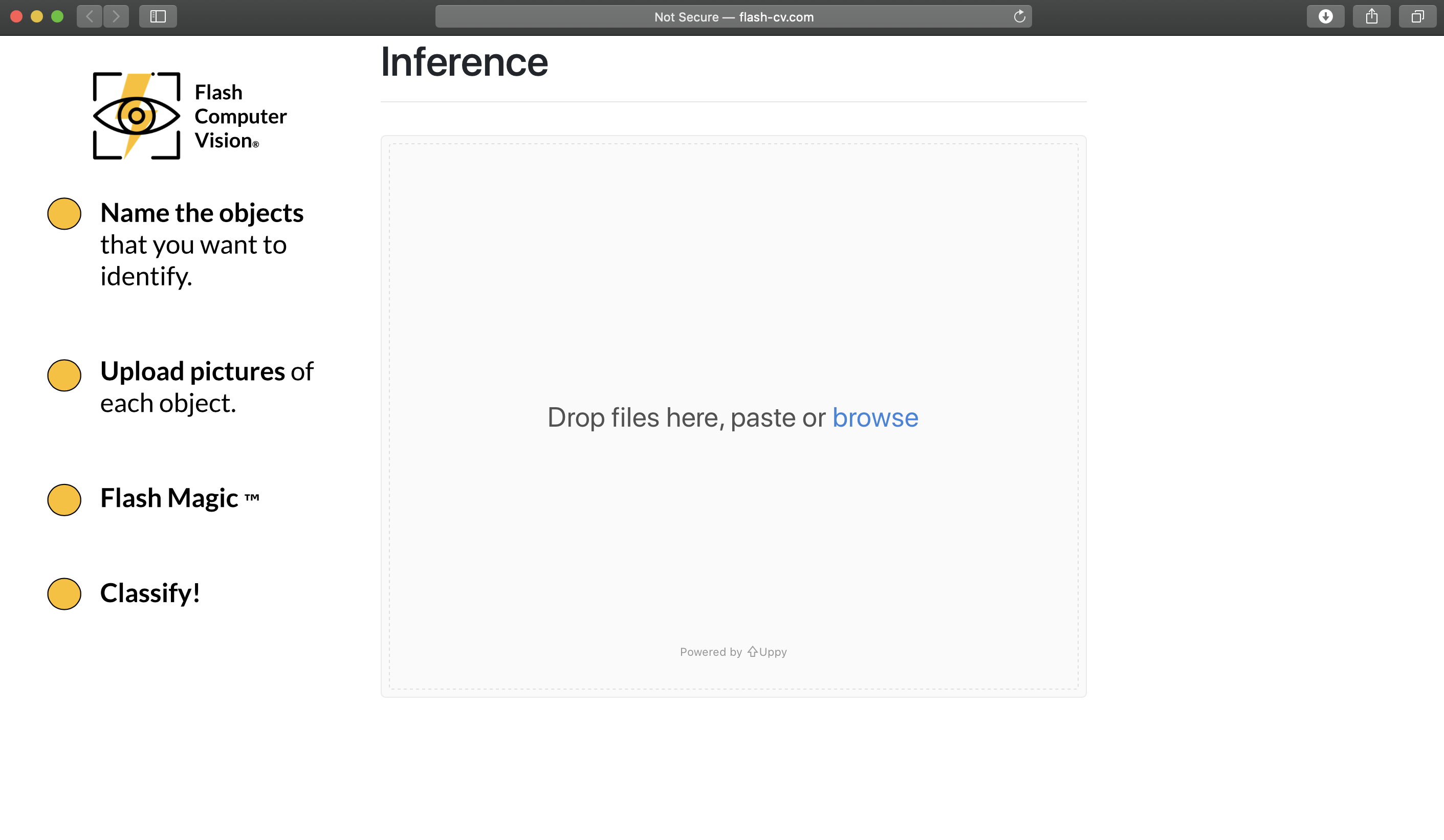
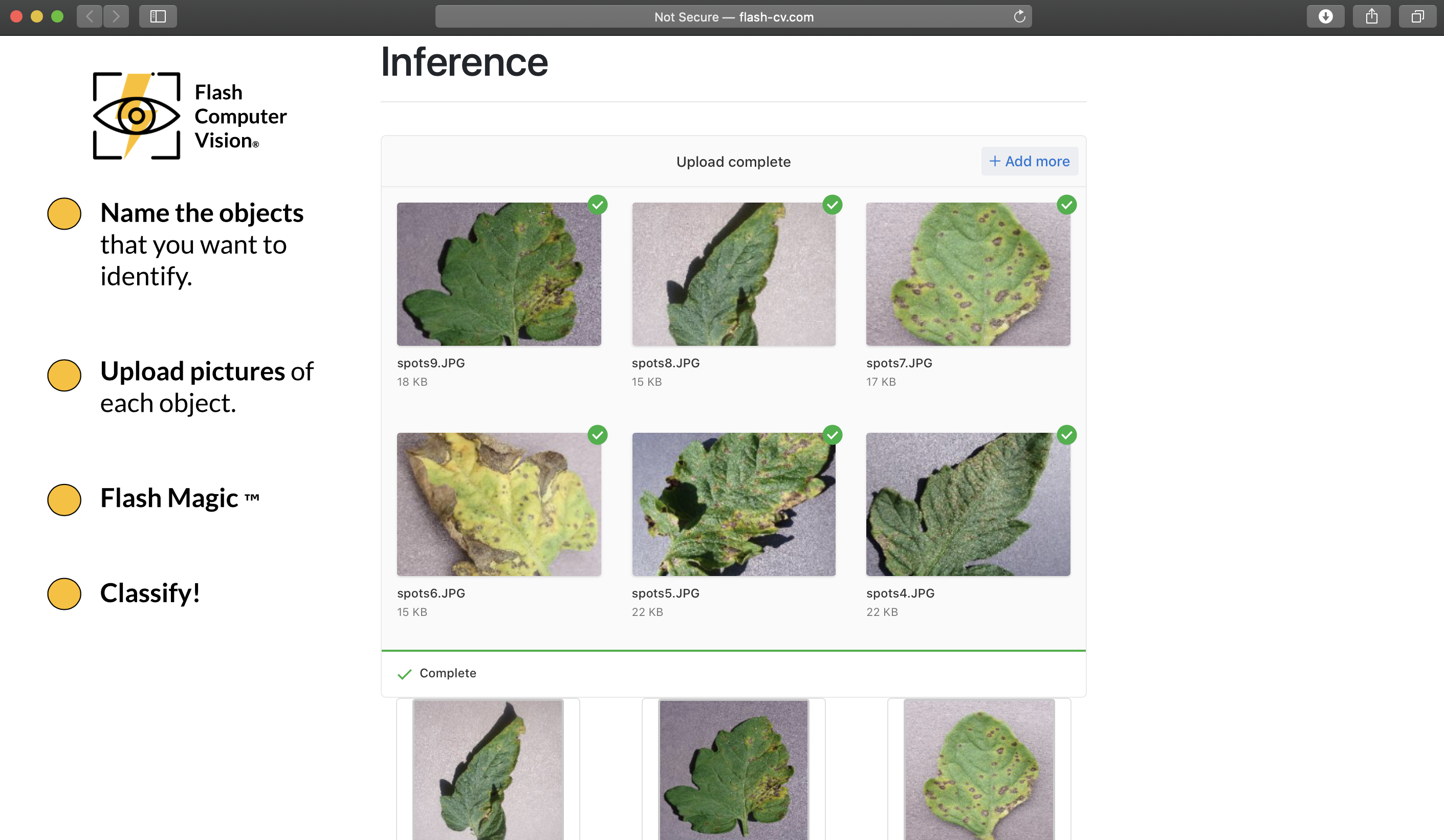
Model is ready! We have a simple interface for inference (ie. classification)
-
Again, easy to upload and classify multiple images at once.
-
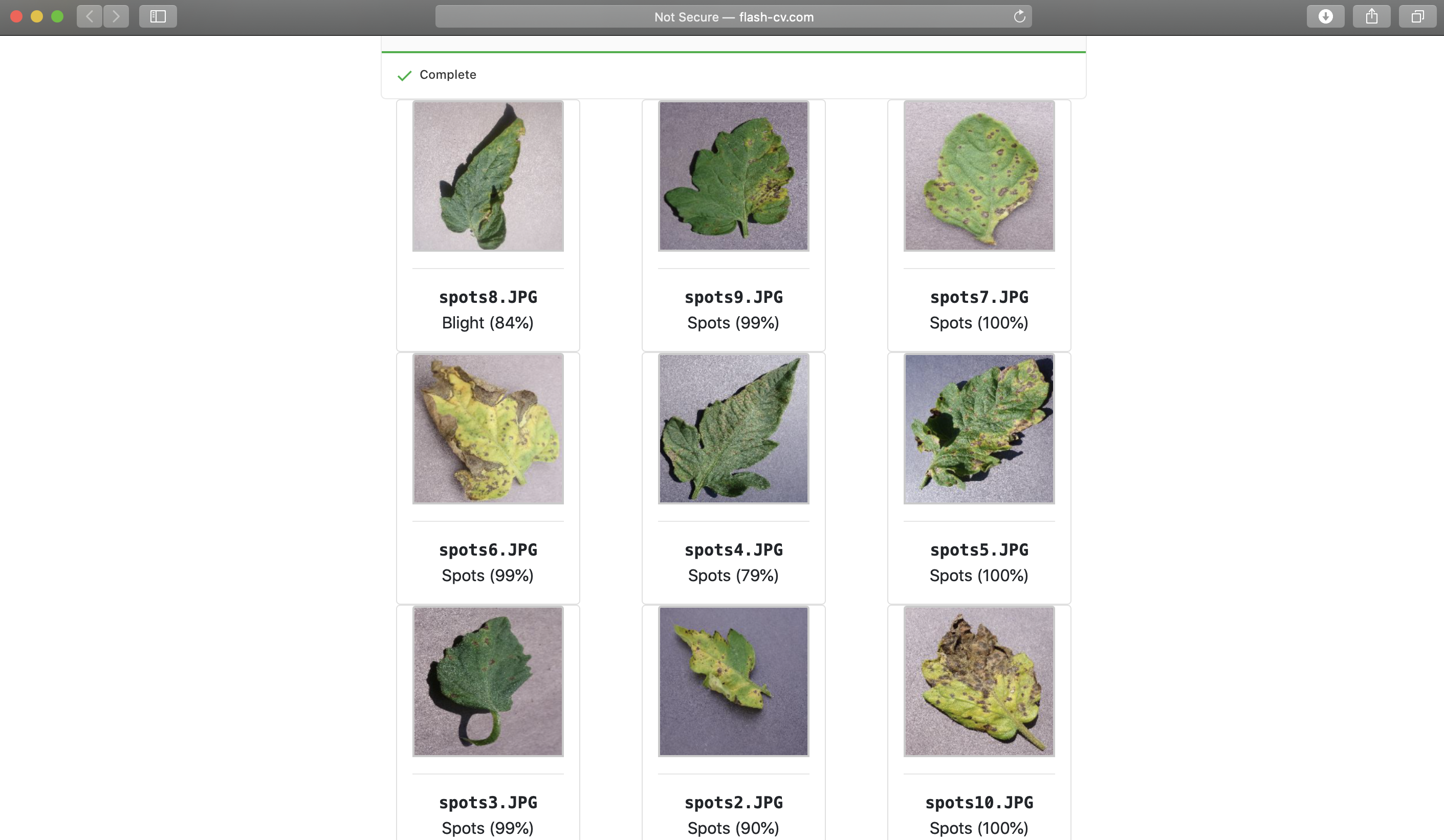
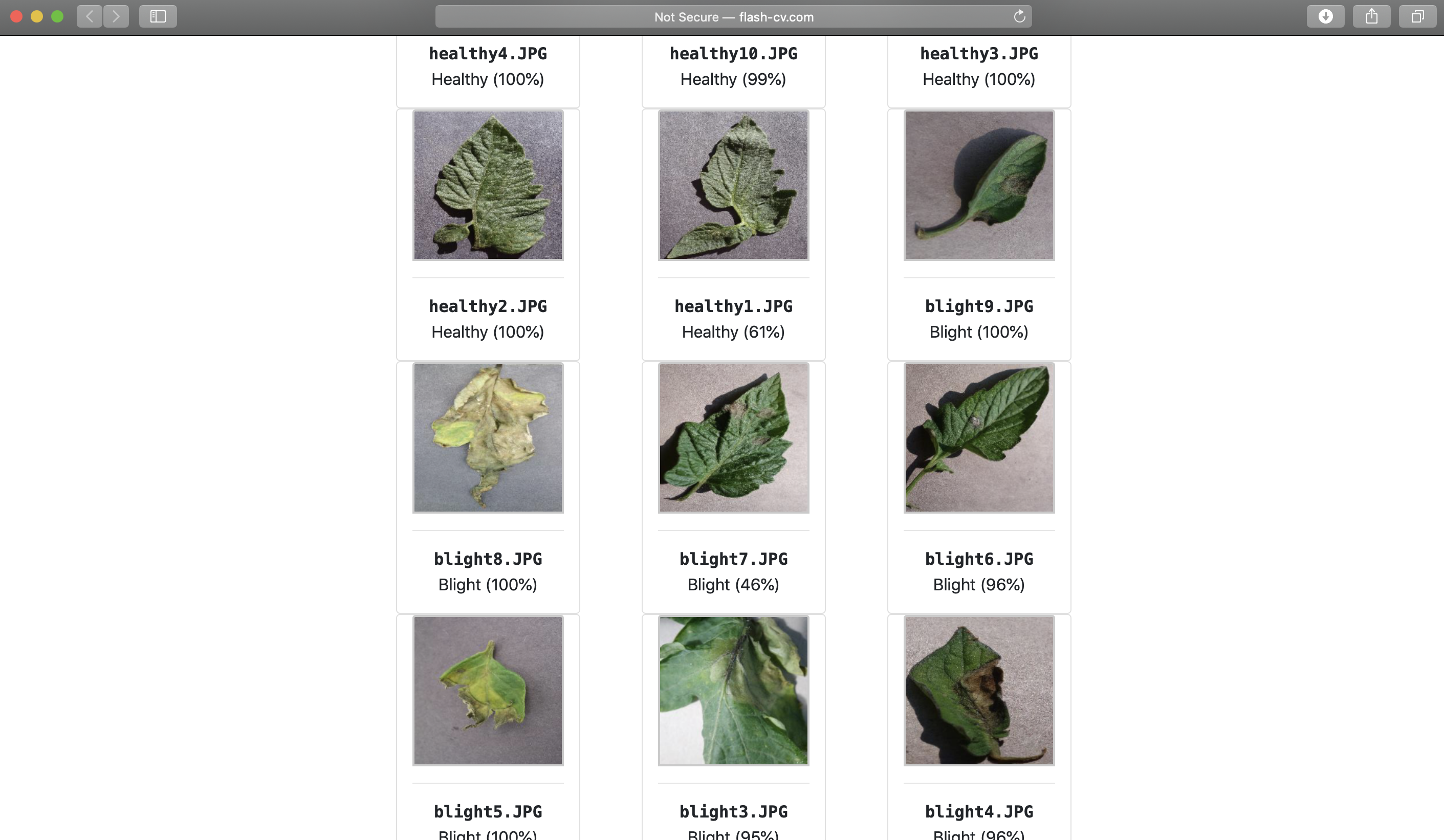
98% accuracy on a test set!!!
-
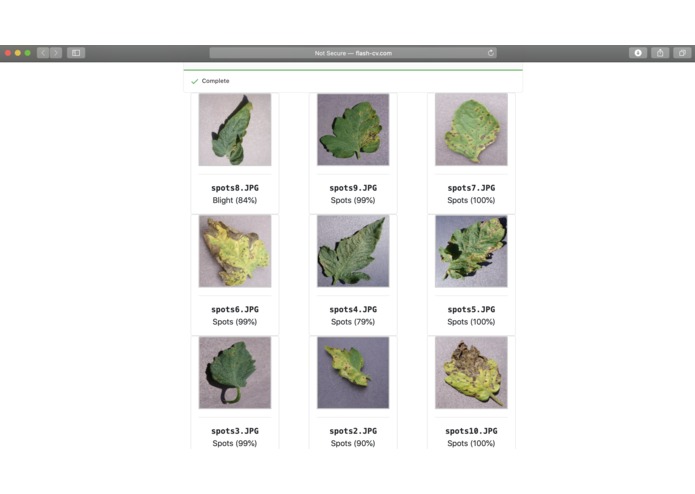
98% accuracy on a test set!!!
-

98% accuracy on a test set!!!
-
Team Members :)
Flash Computer Vision®
Computer Vision for the World
Github: https://github.com/AidanAbd/MA-3
Try it Out: http://flash-cv.comInspiration
Over the last century, computers have gained superhuman capabilities in computer vision. Unfortunately, these capabilities are not yet empowering everyday people because building an image classifier is still a fairly complicated task.
The easiest tools that currently exist still require a good amount of computing knowledge. A good example is Google AutoML: Vision which is regarded as the "simplest" solution and yet requires an extensive knowledge of web skills and some coding ability. We are determined to change that.
We were inspired by talking to farmers in Mexico who wanted to identify ready / diseased crops easily without having to train many workers. Despite the technology existing, their walk of life had not lent them the opportunity to do so. We were also inspired by people in developing countries who want access to the frontier of technology but lack the education to unlock it. While we explored an aspect of computer vision, we are interested in giving individuals the power to use all sorts of ML technologies and believe similar frameworks could be set up for natural language processing as well.
The product: Flash Computer Vision
Easy to use Image Classification Builder - The Front-end
Flash Magic is a website with an extremely simple interface. It has one functionality: it takes in a variable amount of image folders and gives back an image classification interface. Once the user uploads the image folders, he simply clicks the Magic Flash™ button. There is a short training process during which the website displays a progress bar. The website then returns an image classifier and a simplistic interface for using it. The user can use the interface (which is directly built on the website) to upload and classify new images. The user never has to worry about any of the “magic” that goes on in the backend.
Magic Flash™ - The Backend
The front end’s connection to the backend sets up a Train image folder on the server. The name of each folder is the category that the pictures inside of it belong to. The backend will take the folder and transfer it into a CSV file. From this CSV file it creates a Pytorch.utils.Dataset Class by inheriting Dataset and overriding three of its methods. When the dataset is ready, the data is augmented using a combination of 6 different augmentations: CenterCrop, ColorJitter, RandomAffine, RandomRotation, and Normalize. By doing those transformations, we ~10x the amount of data that we have for training. Once the data is in a CSV file and has been augmented, we are ready for training. We import SqueezeNet and use transfer learning to adjust it to our categories. What this means is that we erase the last layer of the original net, which was originally trained for ImageNet (1000 categories), and initialize a layer of size equal to the number of categories that the user defined, making sure to accurately match dimensions. We then run back-propagation on the network with all the weights “frozen” in place with exception to the ones in the last layer. As the model is training, it is informing the front-end that progress being made, allowing us to display a progress bar. Once the model converges, the final model is saved into a file that the API can easily call for inference (classification) when the user asks for prediction on new data.
How we built it
The website was built using Node.js and javascript and it has three main functionalities: allowing the user to upload pictures into folders, sending the picture folders to the backend, making API calls to classify new images once the model is ready.
The backend is built in Python and PyTorch. On top of Python we used torch, torch.nn as nn, torch.optim as optim, torch.optim import lr_scheduler, numpy as np, torchvision, from torchvision import datasets, models, and transforms, import matplotlib.pyplot as plt, import time, import os, import copy, import json, import sys.
Accomplishments that we're proud of
Going into this, we were not sure if 36 hours were enough to build this product. The proudest moment of this project was the successful testing round at 1am on Sunday. While we had some machine learning experience on our team, none of us had experience with transfer learning or this sort of web application. At the beginning of our project, we sat down, learned about each task, and then drew a diagram of our project. We are especially proud of this step because coming into the coding portion with a clear API functionality understanding and delegated tasks saved us a lot of time and helped us integrate the final product.
Obstacles we overcame and what we learned
Machine learning models are often finicky in their training patterns. Because our application allows users with little experience, we had to come up with a robust training pipeline. Designing this pipeline took a lot of thought and a few failures before we converged on a few data augmentation techniques that do the trick. After this hurdle, integrating a deep learning backend with the website interface was quite challenging, as the training pipeline requires very specific labels and file structure. Iterating the website to reflect the rigid protocol without over complicating the interface was thus a challenge. We learned a ton over this weekend. Firstly, getting the transfer learning to work was enlightening as freezing parts of the network and writing a functional training loop for specific layers required diving deep into the pytorch API. Secondly, the human-design aspect was a really interesting learning opportunity as we had to come up with the right line between abstraction and functionality. Finally, and perhaps most importantly, constantly meeting and syncing code taught us the importance of keeping a team on the same page at all times.
What's next for Flash Computer Vision
Application companion + Machine Learning on the Edge
We want to build a companion app with the same functionality as the website. The companion app would be even more powerful than the website because it would have the ability to quantize models (compression for ml) and to transfer them into TensorFlow Lite so that models can be stored and used within the device. This would especially benefit people in developing countries, where they sometimes cannot depend on having a cellular connection.
Charge to use
We want to make a payment system within the website so that we can scale without worrying about computational cost. We do not want to make a business model out of charging per API call, as we do not believe this will pave a path forward for rapid adoption. We want users to own their models, this will be our competitive differentiator. We intentionally used a smaller neural network to reduce hosting and decrease inference time. Once we compress our already small models, this vision can be fully realized as we will not have to host anything, but rather return a mobile application.

Log in or sign up for Devpost to join the conversation.