-

Homepage
-
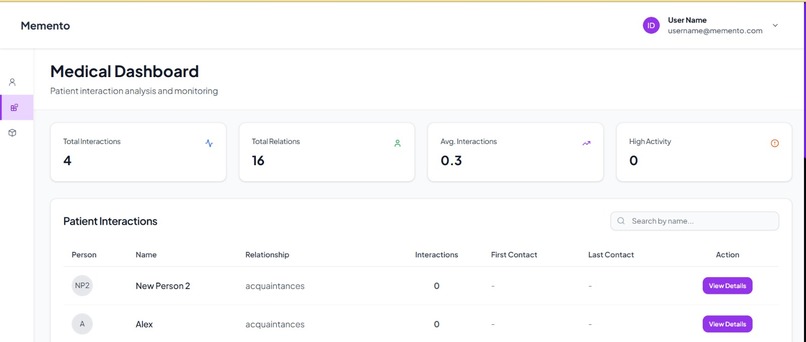
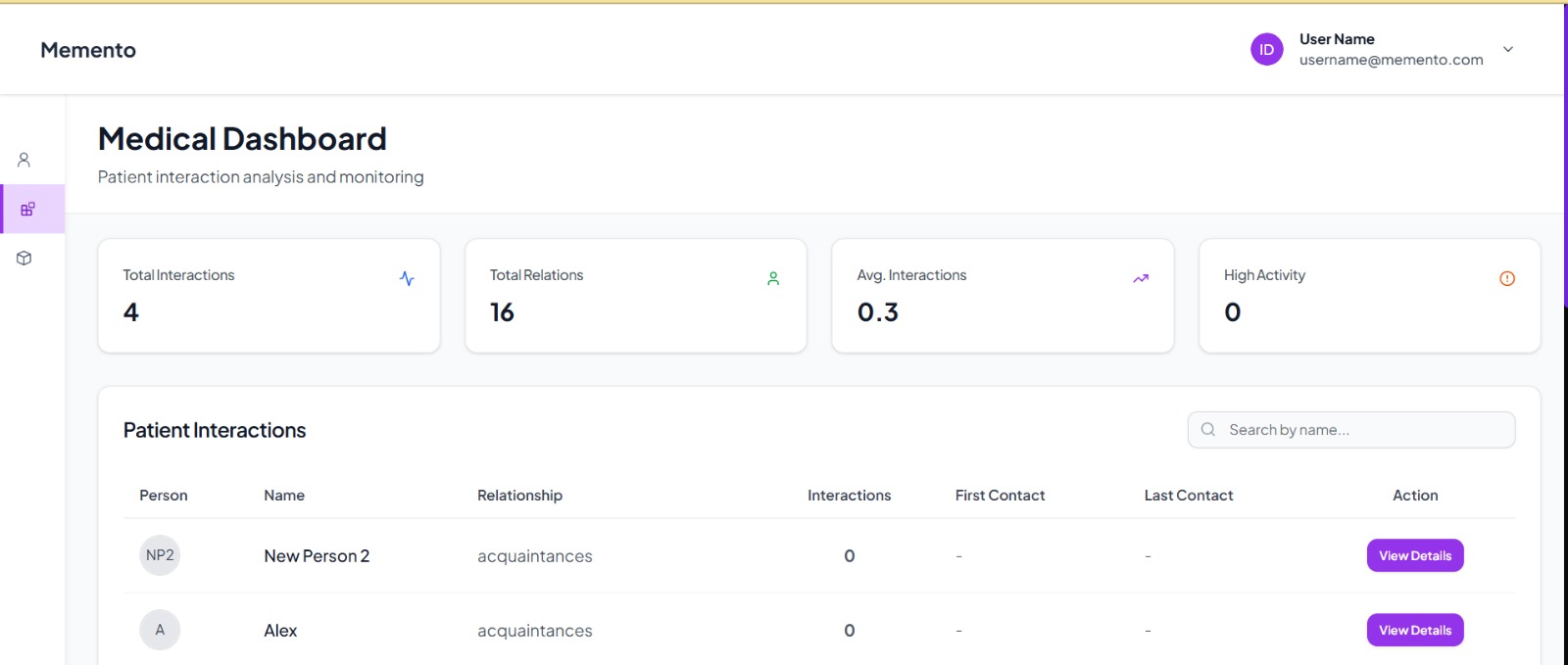
Dashboard
-
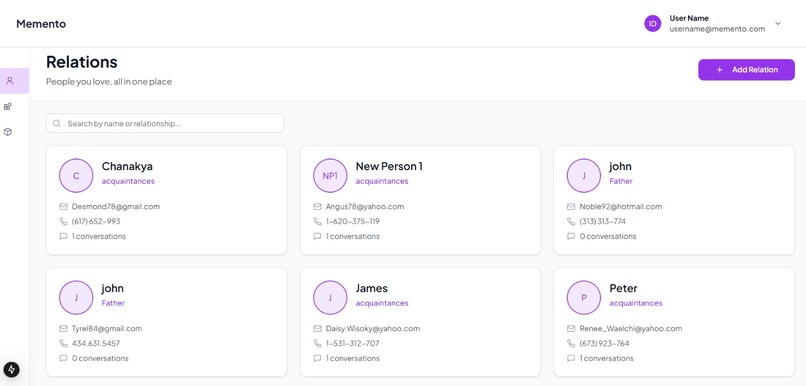
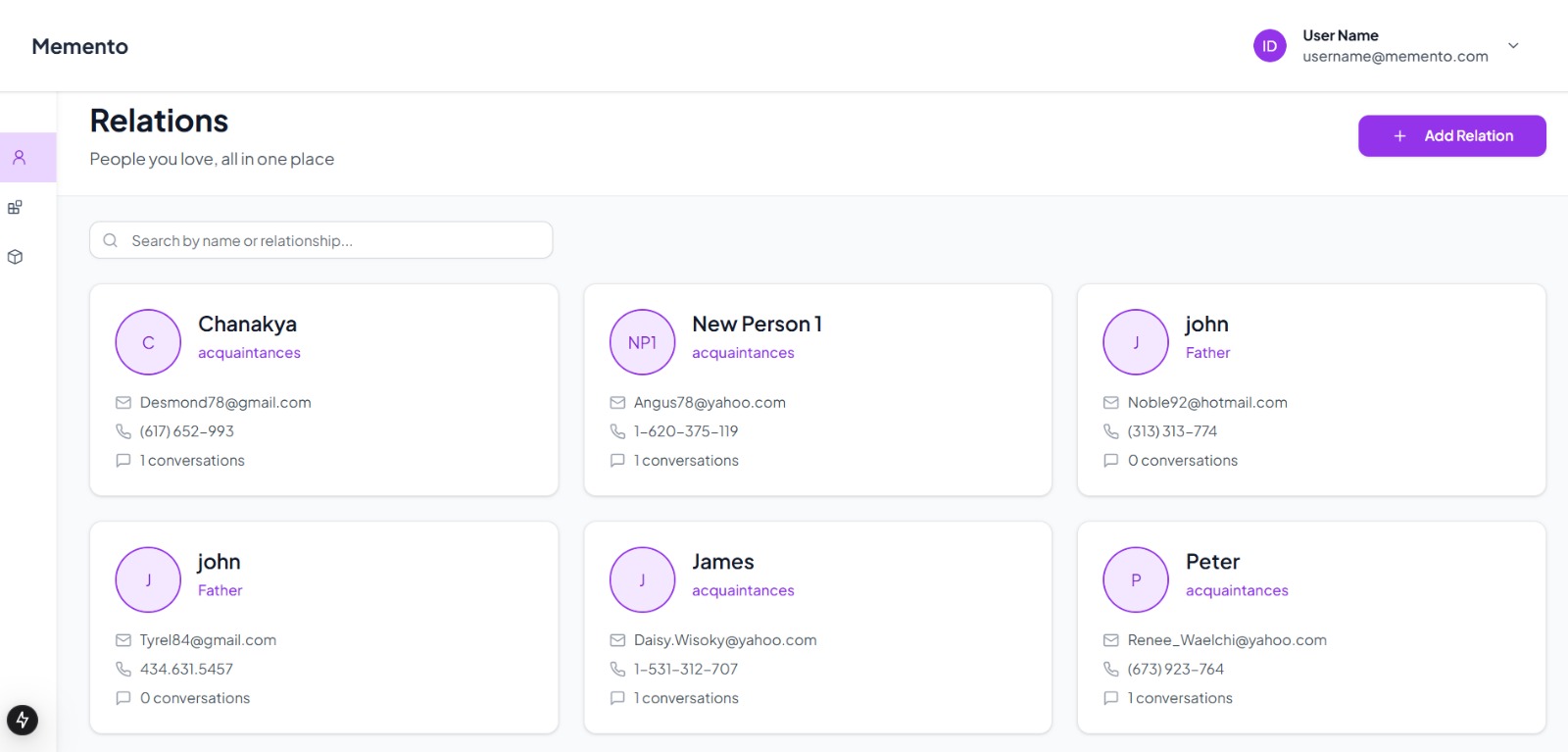
Relations
-

Real Time Detection
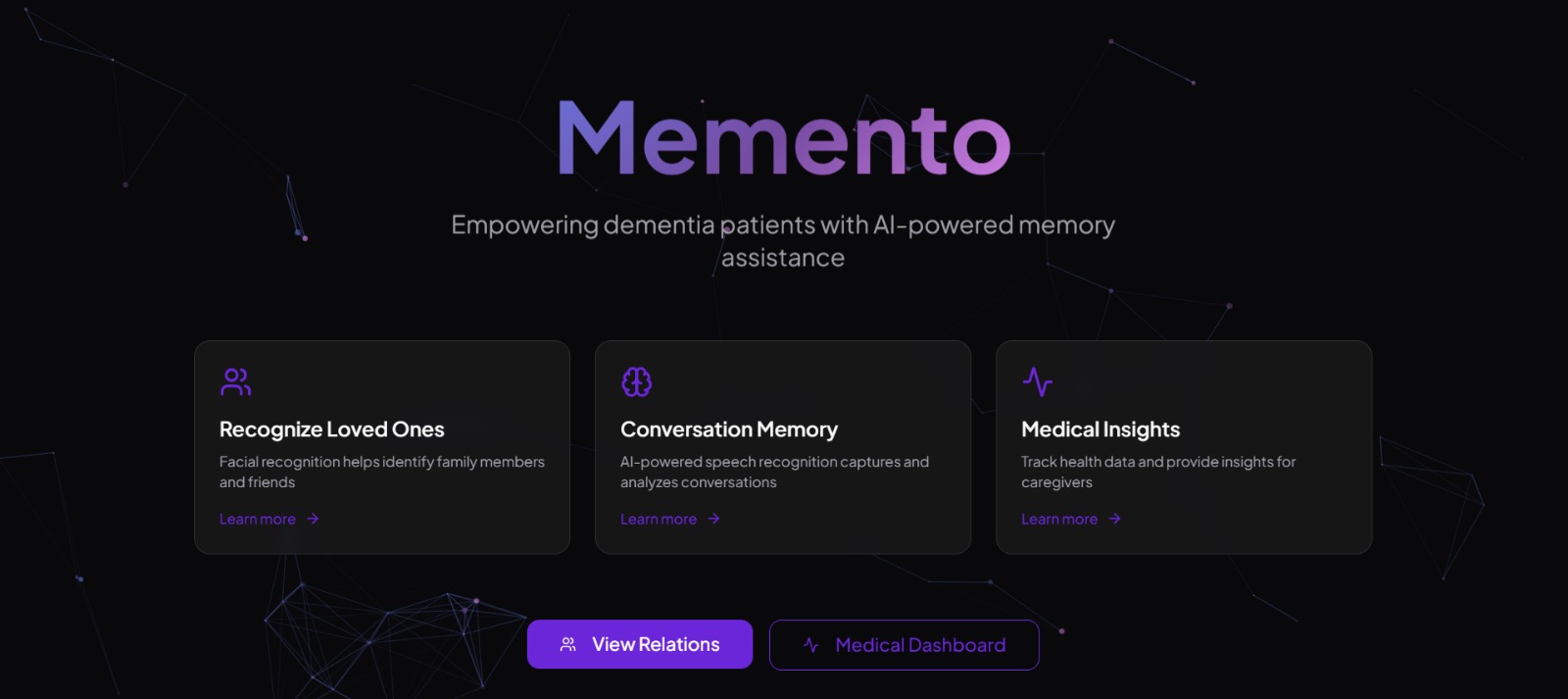

Inspiration
We saw older adults struggle to place familiar faces, turning warm moments into awkward pauses. Memento offers a gentle, timely name cue so interactions feel natural, not clinical or invasive.
What it does
When a familiar face is in view, Memento shows a discreet on-screen cue with their name and relationship. No long notes or recordings just a simple prompt to boost confidence in everyday encounters.
How we built it
Loved Ones lets you add family and caregivers with 2–3 photos and a label for instant, private cues. New people are added hands-free: a brief intro → speech-to-text → LLM extracts name/relationship and saves a safe, local label.
Challenges we ran into
Handling uncertainty without awkwardness like thresholds, short stabilization, and neutral language. Keeping latency low so names appear quickly enough to help in real conversations.
Accomplishments that we're proud of
Real-time performance: camera to on-screen name in ~120–180 ms, first recognition in ~2 seconds. Stable cues via 5-frame smoothing and adaptive confidence; press-to-talk summaries in ~1 second, all local.
What we learned
Small details beat extra features: clear typography, gentle timing, confidence-aware behavior. Simplicity and privacy-first design made the tool easier to trust and use.
What's next for Memento
Hands-free, context-aware use with wearables: camera glasses, smartwatch haptics, earbuds. Bluetooth relay, calendar and geofence pre-cues, faster enrollment, accessibility modes, Care Circle sharing, and lightweight AR overlays.


Log in or sign up for Devpost to join the conversation.