-
-
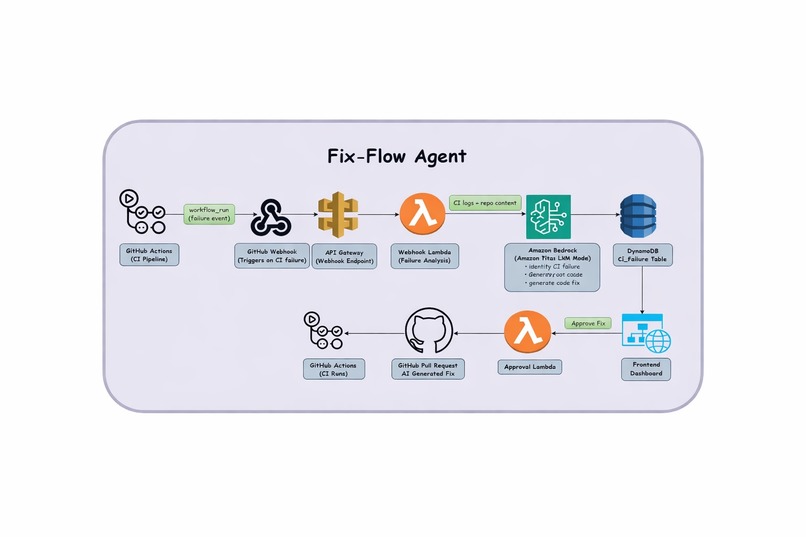
architecture
-
-
-
-
Inspiration
CI pipelines often fail due to small issues such as dependency mismatches, test failures, or configuration errors. Developers usually spend significant time investigating logs, identifying the root cause, and applying fixes manually.
We wanted to build a system that automatically analyzes CI failures, suggests fixes, and creates pull requests, reducing debugging time and helping developers maintain faster development cycles.
What it does
CI failed again? FixFlow Agent reads the logs, figures out what went wrong, and suggests a fix before you even finish your coffee. ☕🚀
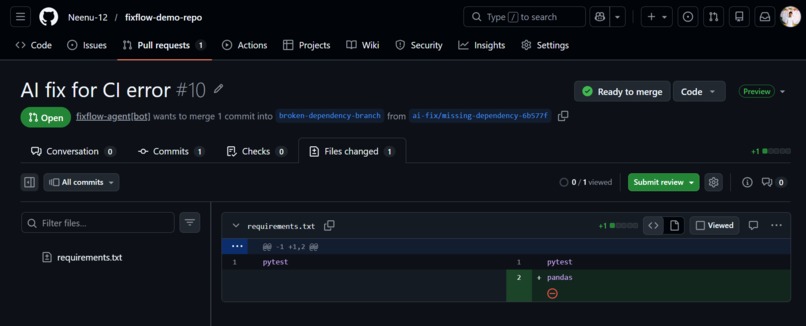
FixFlow Agent makes dealing with CI failures a lot less painful. When a GitHub Actions workflow fails, it automatically captures the failure event and analyzes the CI logs to understand what actually broke.
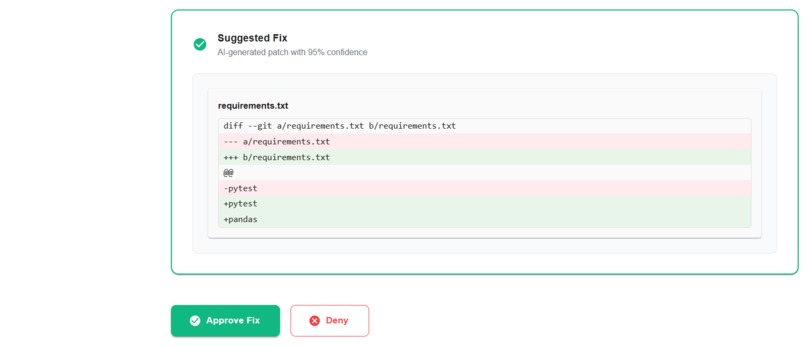
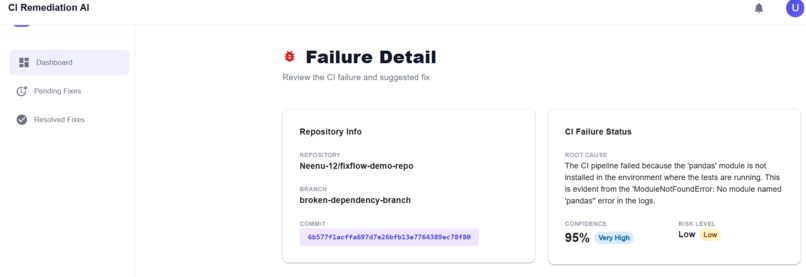
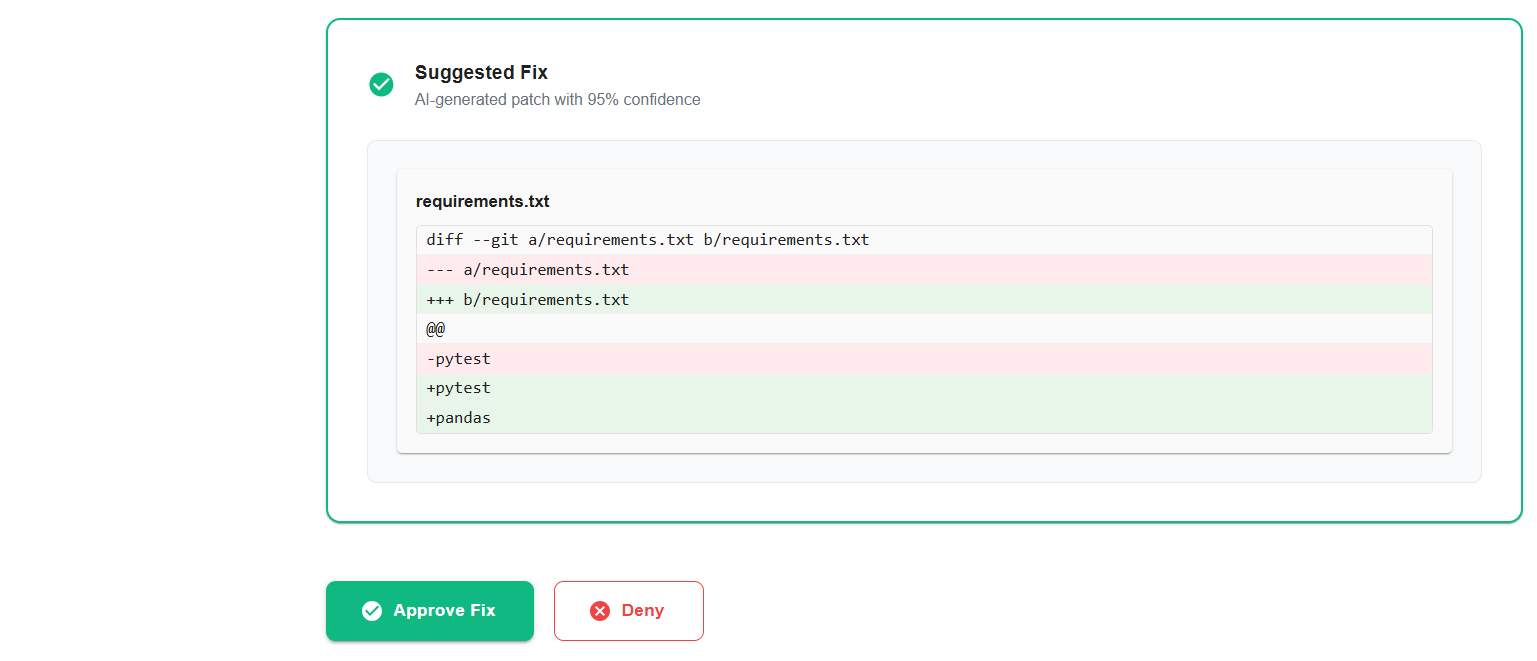
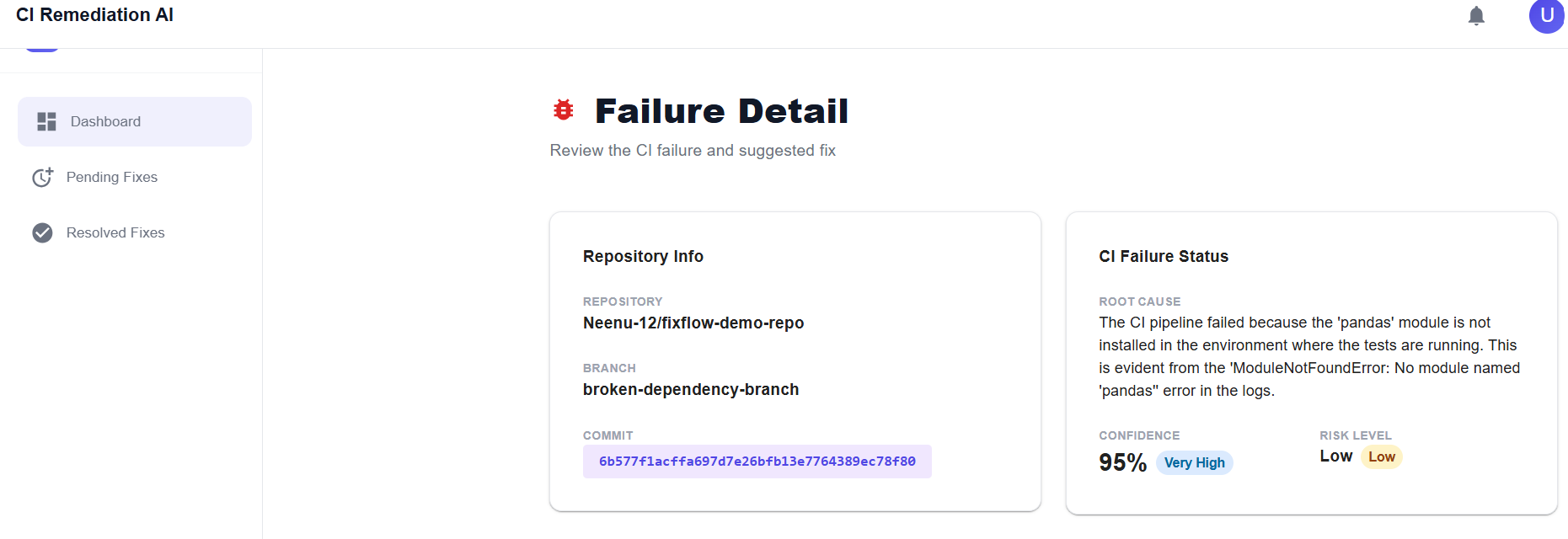
Using AI, it suggests a possible fix and also provides a confidence level and risk score, helping developers quickly judge how safe and reliable the suggested change might be.
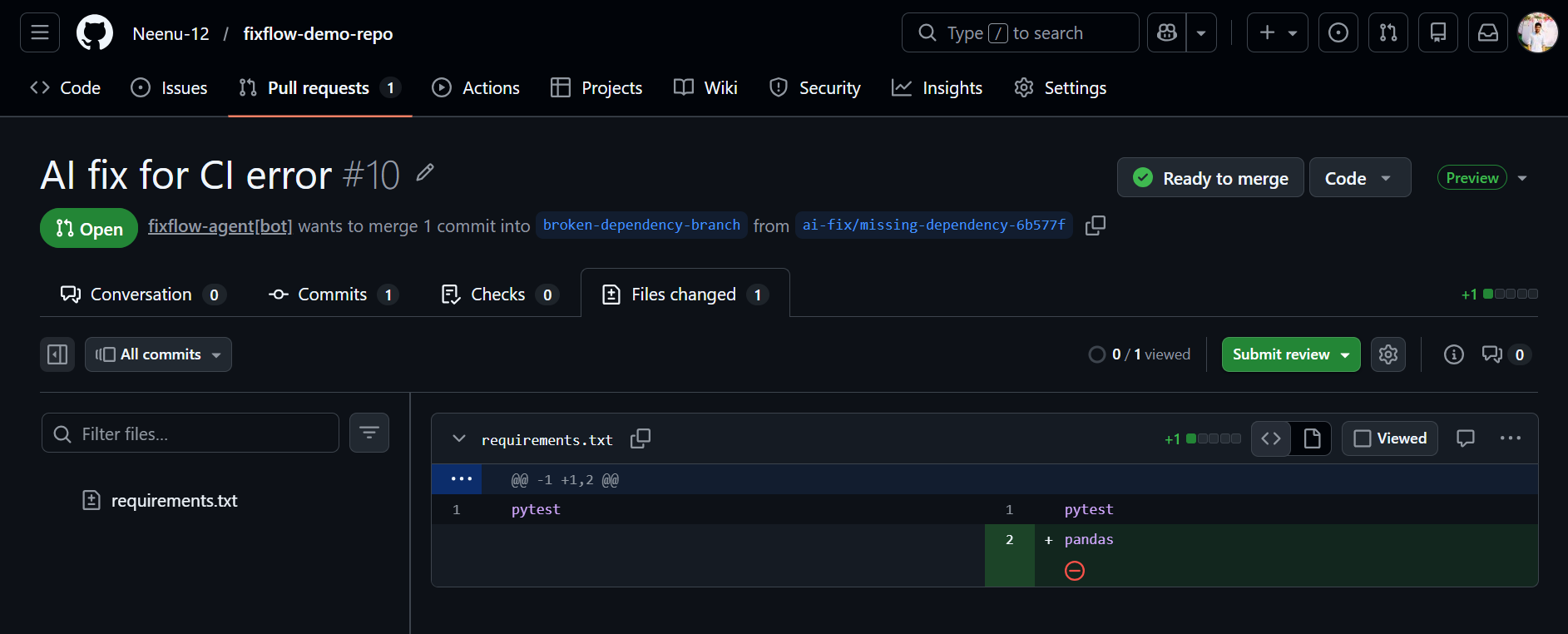
The fix is shown on a dashboard where developers can review the suggestion, check the confidence and risk levels, and decide whether to approve it. Once approved, FixFlow Agent automatically creates a pull request with the fix and reruns the CI pipeline.
In short, it helps teams spend less time digging through logs and more time shipping code. 🚀
How we built it
- GitHub Setup
- Create a GitHub App, register webhook URL, configure it to fire on workflow_run failure events
Generate installation tokens for repo API access
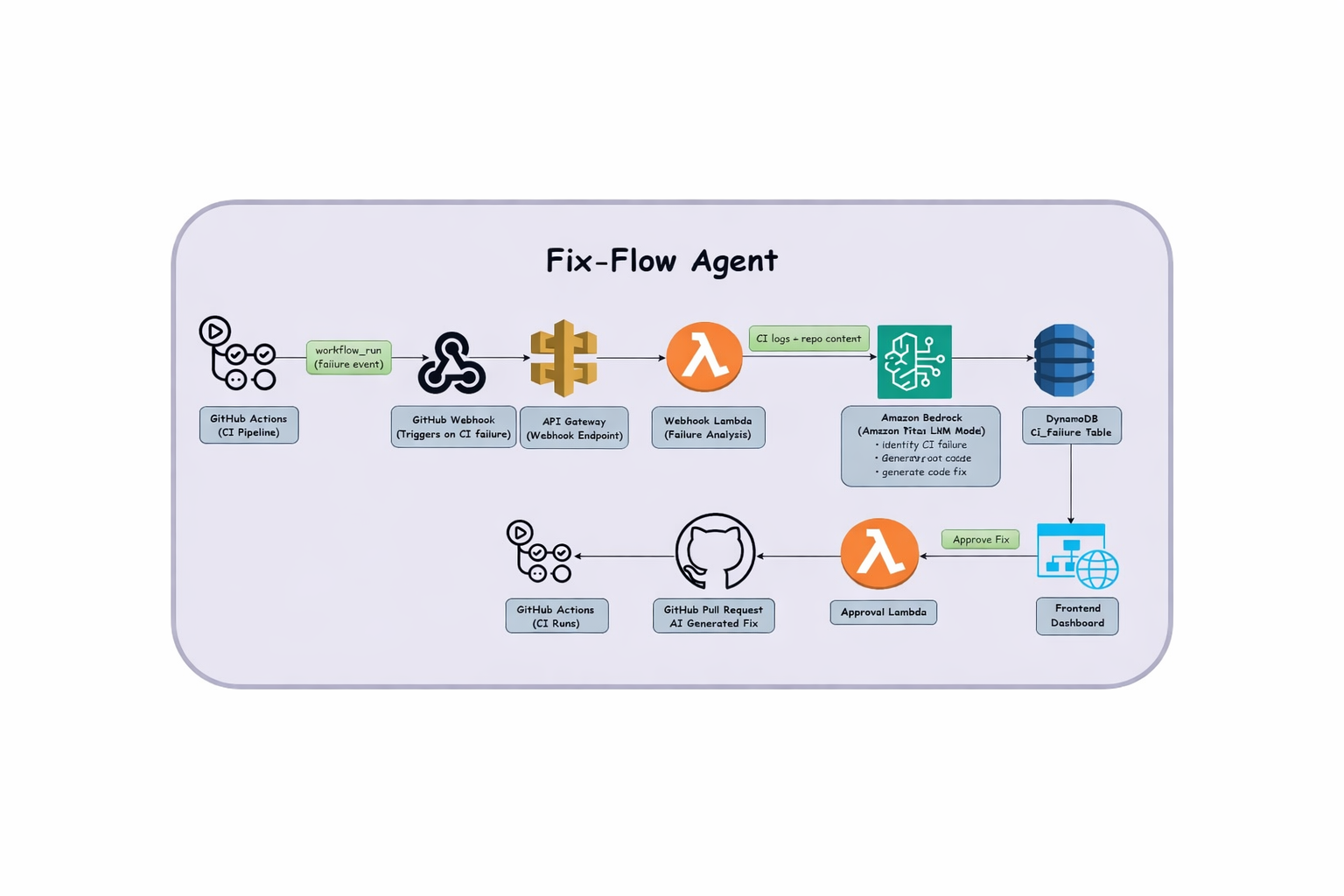
Backend (AWS)
API Gateway exposes 3 routes: POST /github/webhook, POST /approve, GET /failures
Webhook Lambda — validates GitHub signature → fetches CI logs → extracts failure block (40 lines around traceback) → calls Nova model → gets structured JSON (root cause + patch + confidence) → computes risk score → saves to DynamoDB with status = pending
Approval Lambda — on user click → creates a new branch → applies patch → commits → opens PR → updates DynamoDB
Status Lambda — returns failure list/details to frontend
Nova Model (Agentic Reasoning)
4-step reasoning: analyze logs → identify root cause → locate file → propose minimal fix Returns structured JSON with root_cause, files_to_modify, confidence
Risk Scoring
🟢 Low: <10 lines, source file only 🟡 Medium: dependency file changed 🔴 High: workflow file touched
- Frontend
Polls GET /failures every 10–15s Shows diff, root cause, risk badge, Approve/Reject buttons
DB (DynamoDB): Single table ci_failures tracking status: pending → approved → merged/resolved
Challenges we ran into
- Extracting useful information from CI logs – CI logs can be very large and noisy, so we had to implement preprocessing to extract only the relevant failure context before sending it to the model.
- Ensuring safe automated fixes – Automatically modifying repository code can be risky, so we introduced a human-in-the-loop approval step before creating pull requests.
- Reducing AI inference cost – Sending full CI logs to the model would increase token usage, so we optimized the system to send only the most relevant log sections.
- Handling GitHub App authentication – Securely generating installation tokens and interacting with the GitHub API required careful handling of authentication flows.
- Designing a clear developer experience – Presenting AI analysis, risk information, and code diffs in a way that developers can quickly review and trust required thoughtful UI design.
Accomplishments that we're proud of
- CI Reruns Automatically The moment the PR is raised, GitHub triggers CI on the new branch without any human intervention. If it passes, the fix is confirmed. If it fails again, our system captures that too and attempts a second analysis. The loop closes itself.
- Integrated Amazon Nova for root cause analysis of CI logs and generation of structured fix suggestions.
- Reduced CI debugging time from 5–20 minutes to a few seconds of automated analysis.
What we learned
- Building this project gave us hands-on experience with three technologies we'd only scratched the surface of before.
- The GitHub API taught us how webhook-driven systems behave in practice — payload verification, event handling, and extracting workflow logs programmatically.
- Serverless architecture shifted our thinking from servers to events. Designing around Lambda, API Gateway, and DynamoDB forced us to understand statelessness and event-driven data modelling truly. -Amazon Nova was the biggest unlock. Getting an LLM to return consistent, structured, risk-scored output from raw noisy logs — not freeform prose — taught us that prompt engineering is a real, learnable skill.
What's next for FixFlow Agent
There are several opportunities to expand FixFlow Agent further.
The system could support additional CI platforms such as:
- GitLab CI
- Jenkins
- Bitbucket Pipelines
Another improvement would be iterative debugging loops, where the system attempts additional fixes automatically if the first suggestion does not resolve the issue.
Integration with collaboration tools such as Slack or Microsoft Teams could also notify developers when CI failures occur along with AI-generated explanations.
Over time, the system could also learn from historical CI failures across repositories to improve the accuracy of its recommendations.
These improvements could evolve FixFlow Agent into a broader AI-powered developer productivity platform.



Log in or sign up for Devpost to join the conversation.