-
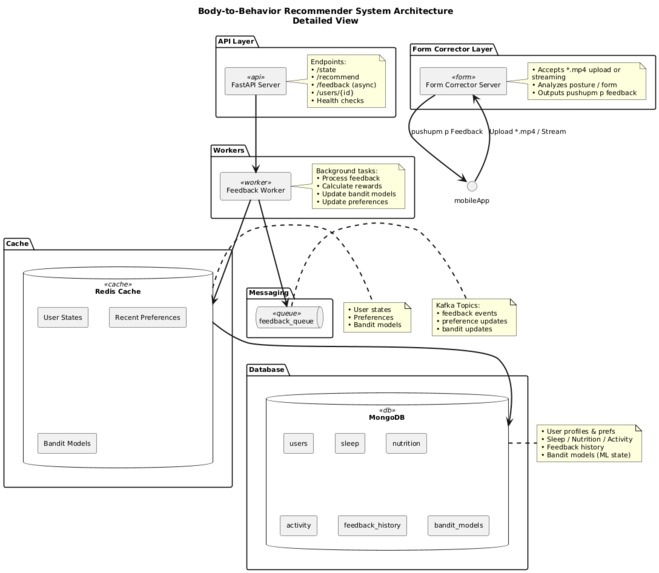
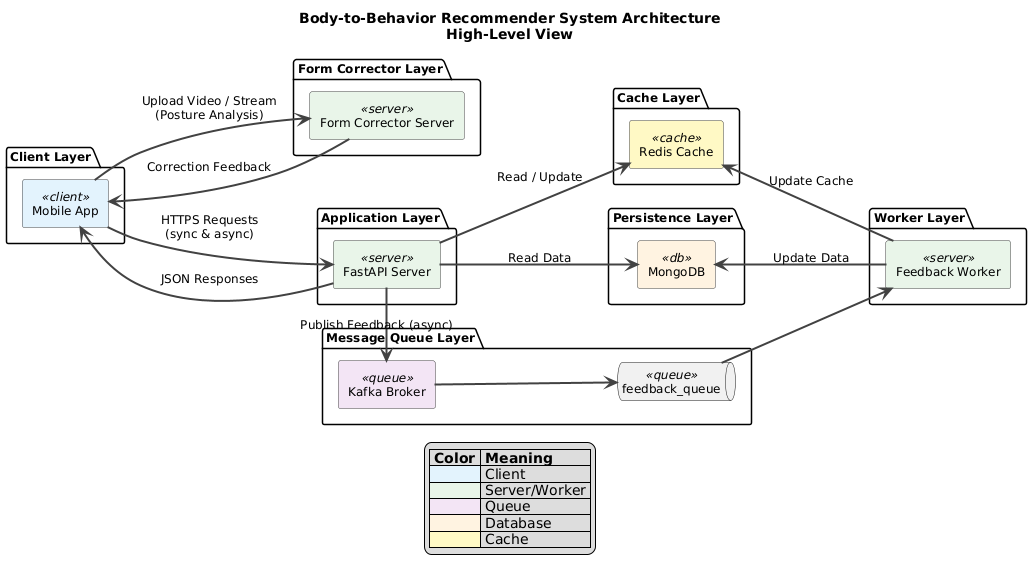
High-level Architecture
-
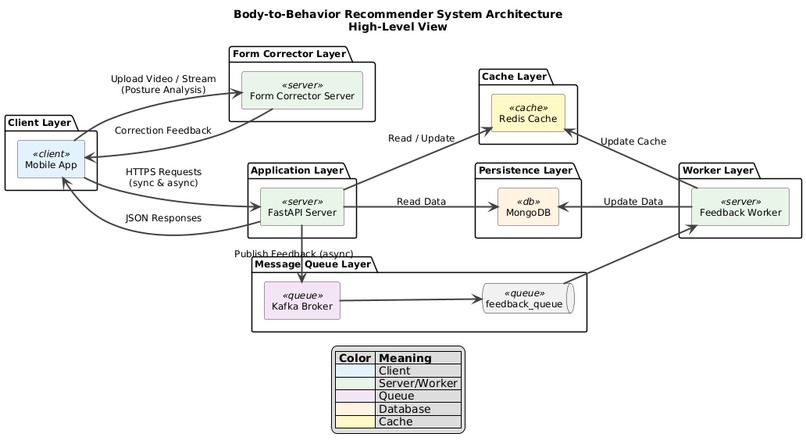
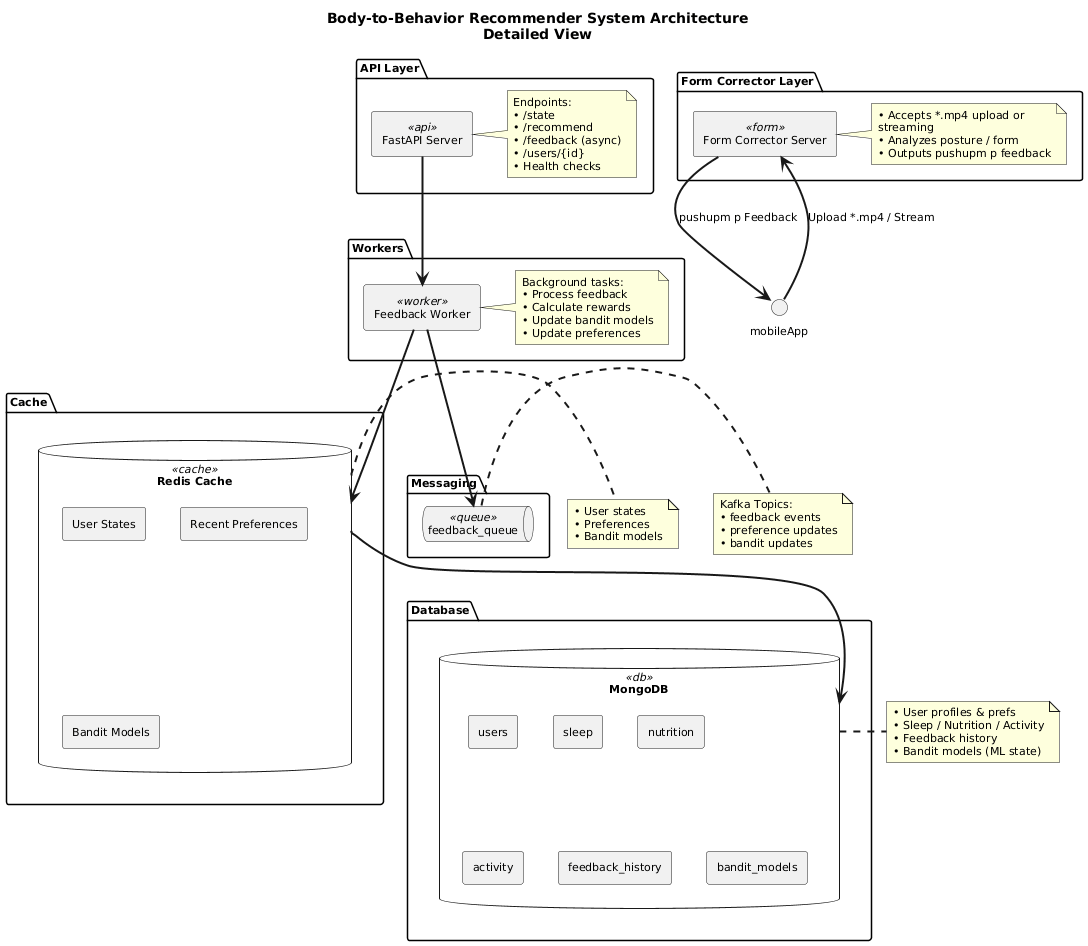
Detailed Architecture
Drive link: https://drive.google.com/drive/folders/1ktH9sNaFTbd5ufky4jjQHtsg8B3Qp7Ie Github link: https://github.com/YounesMakhlouf/seneca-hacks-2025
Inspiration
The modern wellness landscape is fragmented. People track their sleep with one app, nutrition with another, workouts with a third, and listen to music on a fourth platform—but none of these systems talk to each other. We were inspired by the untapped potential of connecting these health signals to create truly intelligent, adaptive recommendations.
The breakthrough insight came from realizing that our bodies constantly broadcast signals about what we need: poor sleep might call for energizing music and a light workout, while high stress levels might suggest calming activities and nutrient-dense meals. What if we could create an AI system that learns from these patterns and proactively suggests the right intervention at the right time?
We envisioned a system that doesn't just track health data but transforms it into actionable intelligence—a personal assistant that understands the intricate relationships between sleep, nutrition, activity, and mood to deliver recommendations that truly matter.
What it does
FitMix is an adaptive AI system that ingests comprehensive health signals and delivers personalized recommendations across three key domains: music, nutrition, and physical activity.
Core Intelligence Engine
The system computes a real-time 3D health state for each user:
- 🛌 Readiness: Sleep quality + bedtime consistency + recovery metrics
- 🍎 Fuel: Protein/fiber adequacy - sugar/sodium penalties
- 💪 Strain: Activity levels + heart rate patterns + exercise intensity
Intelligent Recommendation Loop
Using this state vector, our AI follows a sophisticated decision process:
$$\text{Score} = 0.35 \times \text{GoalFit} + 0.30 \times \text{StateFit} + 0.25 \times \text{PrefFit} + 0.10 \times \text{Novelty} - \text{Penalties}$$
The system employs Thompson Sampling bandit algorithms with k-nearest neighbor context matching to continuously learn and adapt. Each recommendation becomes smarter based on user feedback, creating a personalized AI that evolves with individual preferences and health patterns.
Real-World Impact
- For the stressed executive: Detects elevated strain levels and suggests calming music + a 5-minute breathing exercise
- For the under-fueled athlete: Identifies protein deficiency and recommends a post-workout smoothie recipe
- For the sleep-deprived student: Recognizes poor sleep patterns and suggests energizing music + light movement
How we built it
Architecture & Scale
We built a production-grade microservices architecture capable of handling enterprise-level data:
- 📊 Data Layer: MongoDB with optimized indexing for 50,000+ users, 500,000+ sleep records, and 1M+ activity entries
- 🚀 API Layer: FastAPI with async/await for high-performance endpoints
- 🧠 ML Engine: MABWiser library implementing Thompson Sampling contextual bandits
- ⚡ Message Queue: Apache Kafka with Zookeeper for asynchronous feedback processing
- 🐳 Deployment: Docker Compose orchestrating 6 microservices with proper networking
Technical Innovation
# Real-time state computation
readiness = (sleep_quality * 0.4 + sleep_consistency * 0.3 + recovery_score * 0.3)
fuel = (protein_adequacy + fiber_score - sugar_penalty - sodium_penalty) / 4
strain = normalize(steps_zscore + hr_variability + active_minutes_score)
Asynchronous Learning Pipeline
We implemented a sophisticated feedback loop where user interactions are processed asynchronously through Kafka queues, allowing the system to learn continuously without blocking real-time recommendations.
Data Engineering Excellence
- Bulk ingestion pipelines for efficient data loading
- Compound indexes optimized for time-series health data
- Connection pooling for database performance
- Aggregation pipelines for real-time statistics
Challenges we ran into
1. Multi-Domain Context Learning
Challenge: How do you train a single AI model to make relevant recommendations across completely different domains—music, food, and exercise?
Solution: We developed domain-specific feature engineering while maintaining shared contextual understanding through normalized state vectors. Each domain has specialized ranking criteria but shares the same underlying health state representation.
2. Real-Time vs. Learning Trade-off
Challenge: Balancing immediate response times with continuous learning from user feedback.
Solution: We architected a dual-path system: synchronous recommendations for real-time responses and asynchronous Kafka-based feedback processing for model updates. This allows sub-100ms recommendation times while maintaining sophisticated learning capabilities.
3. Cold Start Problem
Challenge: Providing meaningful recommendations for new users with minimal historical data.
Solution: We implemented a hierarchical fallback system: user-specific preferences → demographic-based recommendations → global popularity rankings. The Thompson Sampling algorithm naturally handles exploration vs. exploitation for new users.
4. Data Heterogeneity
Challenge: Integrating diverse health data formats (continuous heart rate, categorical sleep stages, discrete activity events) into a unified recommendation framework.
Solution: We developed a sophisticated normalization pipeline that converts all health signals into comparable metrics, enabling cross-domain insights and recommendations.
Accomplishments that we're proud of
🚀 Technical Excellence
- Production-Ready Architecture: Built a scalable microservices system that can handle millions of health records
- Advanced AI Implementation: Successfully deployed Thompson Sampling contextual bandits for personalized learning
- Real-Time Performance: Achieved sub-100ms recommendation response times with continuous background learning
📊 Data Engineering
- Massive Scale Processing: Engineered efficient ingestion and querying for 50,000+ users and millions of health data points
- Smart Indexing Strategy: Optimized MongoDB performance with compound indexes for complex time-series queries
- Async Processing Pipeline: Implemented sophisticated Kafka-based message queuing for scalable feedback processing
🧠 AI Innovation
- Multi-Domain Intelligence: Created an AI system that understands relationships between sleep, nutrition, activity, and optimal recommendations
- Contextual Learning: Implemented k-nearest neighbor context matching for nuanced, personalized recommendations
- Adaptive Algorithms: Built a system that gets smarter with every user interaction through bandit learning
🏗️ System Design
- Docker Orchestration: Successfully deployed a 6-service microservices architecture with proper networking and dependencies
- API Excellence: Created comprehensive RESTful endpoints with full error handling and validation
- Type Safety: Implemented end-to-end type safety with Pydantic v2 models
What we learned
Technical Insights
- Async Architecture Patterns: Mastered the balance between real-time responsiveness and background processing through Kafka message queues
- Bandit Algorithm Implementation: Gained deep understanding of Thompson Sampling and contextual bandits for recommendation systems
- MongoDB Optimization: Learned advanced indexing strategies and aggregation pipelines for health data time-series analysis
Product Development Wisdom
- Multi-Domain AI Complexity: Discovered the intricate challenges of building AI that operates across diverse recommendation domains while maintaining coherent user experience
- Health Data Patterns: Learned to identify meaningful signals in noisy health data and translate them into actionable insights
- User Experience Design: Understood how to balance AI sophistication with intuitive, immediate value delivery
System Architecture Lessons
- Microservices Communication: Mastered service orchestration, proper networking, and inter-service communication patterns
- Production Deployment: Gained experience with Docker Compose for complex multi-service applications
- Scalability Planning: Learned to design systems that handle current needs while remaining extensible for future growth
What's next for FitMix
🚀 Immediate Roadmap (Next 3 Months)
- 📱 Real-Time Streaming: Implement live heart rate and activity streaming for instant health state updates
- 🌤️ Environmental Context: Integrate weather and location data for context-aware recommendations
- 📊 Advanced Analytics: Build ML-powered health insight dashboards with trend analysis and goal tracking
🎯 Growth Phase (6-12 Months)
- 👥 Social Features: Implement group challenges, shared goals, and collaborative health journeys
- 🛒 Ecosystem Integration: Connect with grocery delivery, fitness apps, and music streaming services
- 🧬 Biometric Expansion: Add support for glucose monitoring, stress tracking, and hormonal patterns
🌟 Vision (12+ Months)
- 🔮 Predictive Health: Develop early warning systems for health issues based on pattern recognition
- 🎪 Gamification Platform: Create engaging health challenges with rewards and community features
- 🏥 Healthcare Integration: Partner with healthcare providers for clinical-grade health monitoring and recommendations
📈 Business Scaling
- API Monetization: Offer recommendation APIs to fitness apps, nutrition platforms, and wellness companies
- Enterprise Solutions: Develop corporate wellness programs with team health insights and recommendations
- Research Partnerships: Collaborate with universities and health institutions for clinical validation studies
The future of personalized health isn't just about tracking—it's about intelligent, adaptive systems that understand the complex interplay between our bodies, minds, and daily choices. FitMix represents the first step toward truly intelligent health assistance that learns, adapts, and evolves with each user's unique health journey.

Log in or sign up for Devpost to join the conversation.