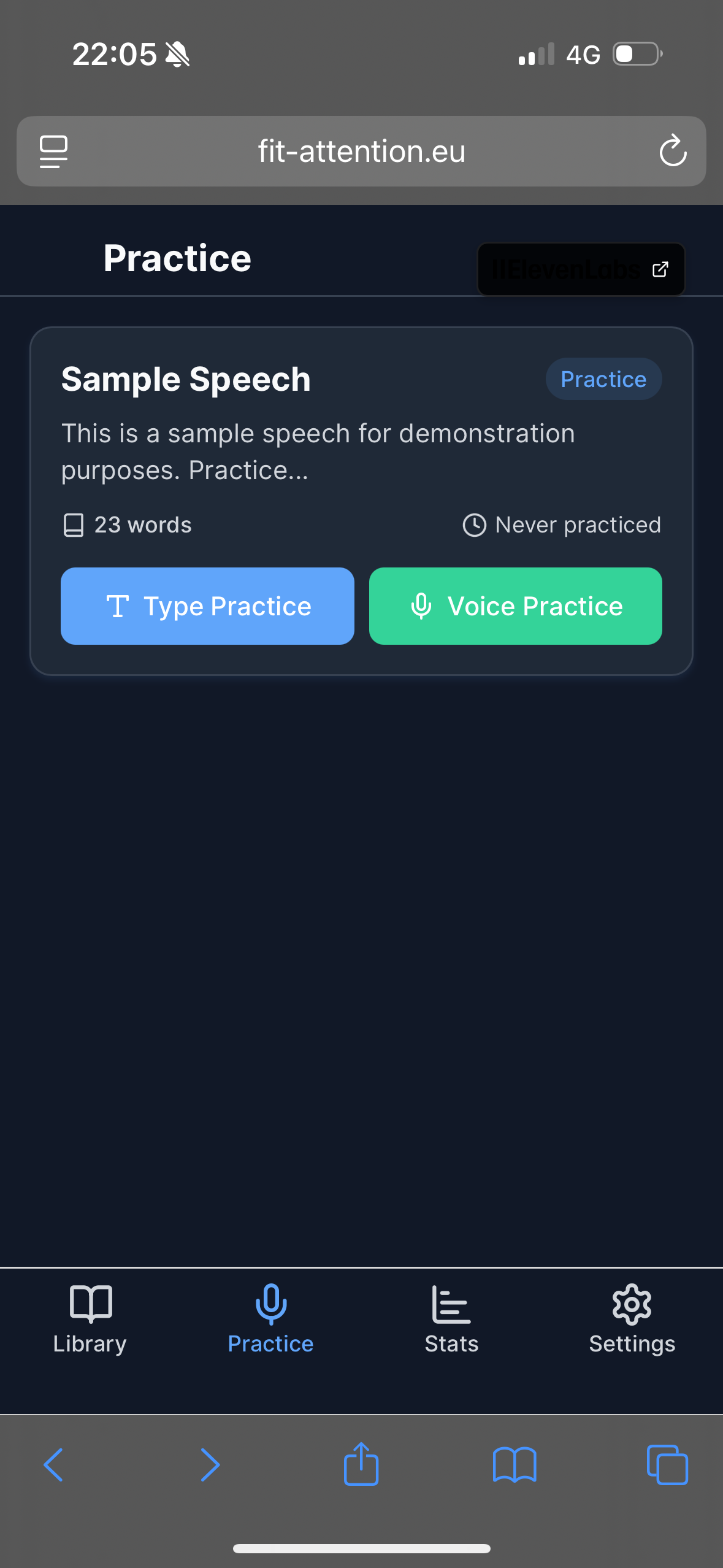
🌟 Inspiration FitAttention was born from a simple need: the ability to speak with confidence and clarity, especially when memorizing and delivering text under pressure — be it for exams, speeches, auditions, or therapy. While many apps focus on listening or learning languages, few guide users to train their voice, overcome hesitation, and master memorization using real-time feedback and AI voice support. We wanted to build something empowering, intuitive, and bilingual — helping people speak better, not just read better.
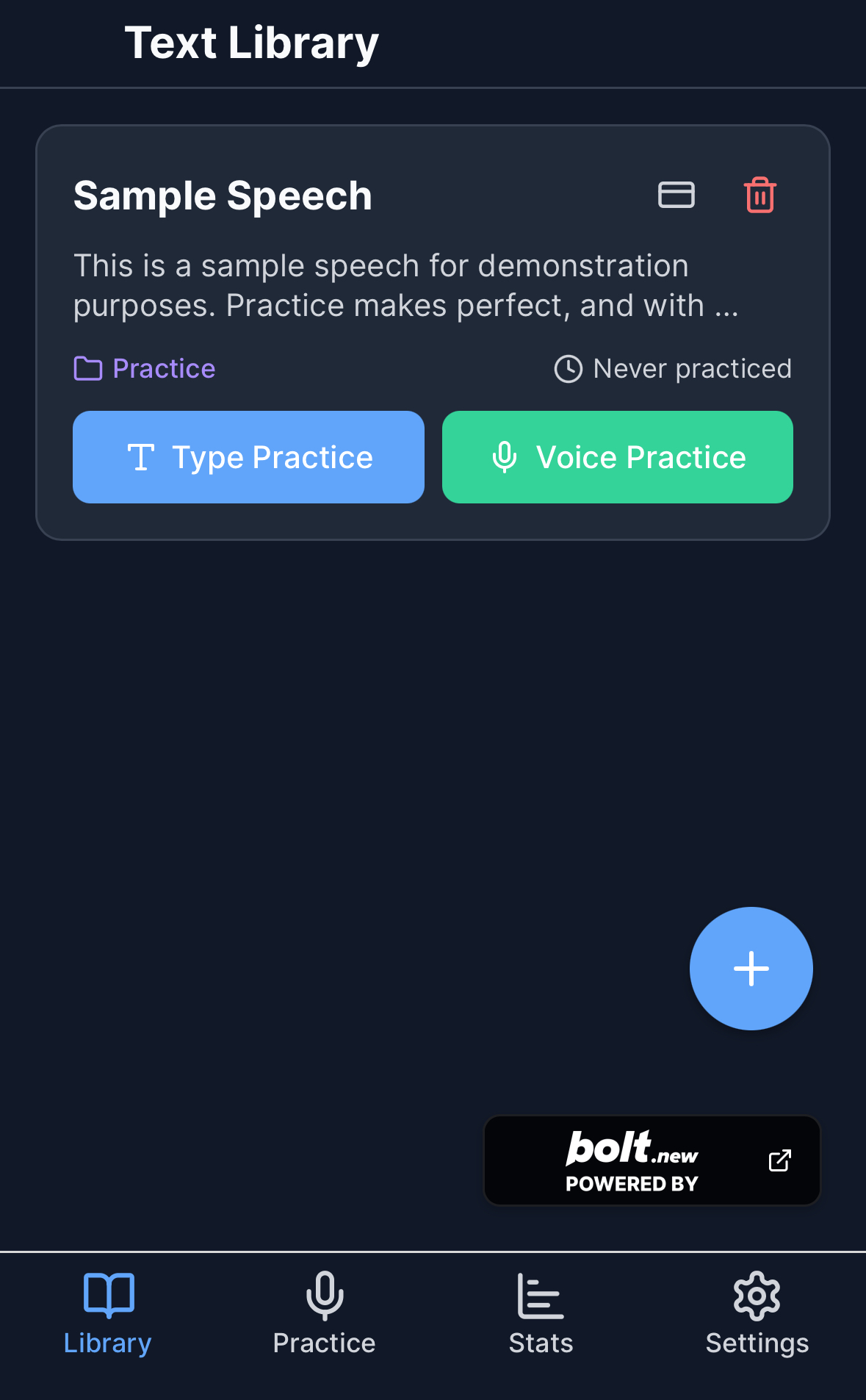
🧠 What it does FitAttention is a web app that helps users:
📝 Import or write custom texts (manually, by photo, or voice dictation),
🎧 Listen to each section read by a lifelike voice (via ElevenLabs),
🎙️ Record themselves reading the same text,
📊 Receive instant feedback on pace, intonation, and pauses using local audio analysis,
🗂️ Organize texts by category and track progress using Supabase,
📷 Use OCR with image preprocessing (Pica) to turn paper notes or slides into readable text.
The app is built to train both memory and oratory skills, and is fully bilingual (English/French).
🏗️ How we built it Frontend: Expo + React Native Web with Bolt for rapid no-code logic and UI components.
Voice generation: ElevenLabs API for lifelike speech synthesis.
Audio analysis: Local JavaScript functions (calculateSpeechStats) to assess pitch, WPM, and pauses.
Image preprocessing: Pica.js used to resize user-uploaded images before OCR.
OCR: Tesseract.js client-side for converting photos into text.
Backend: Supabase for authentication, data storage (Texts, Recordings), and optional Storage for optimized images.
🧱 Challenges we ran into 🐛 Parsing .env variables correctly in Expo with Bolt (invisible characters were breaking the build).
🎙️ Handling microphone and audio recording APIs across web and mobile.
📐 Integrating Pica within Bolt’s environment and chaining it properly before OCR.
🔑 Managing secure API calls to ElevenLabs while keeping keys safe in a client-facing app.
🕐 Timing: sequencing async steps (resize → OCR → inject text) smoothly in the UI.
🏆 Accomplishments that we're proud of Built a full voice feedback loop: Text → AI Voice → User Voice → Feedback.
Enabled OCR from photo with image optimization — all client-side.
Created a bilingual user experience with an intuitive onboarding flow.
Used Supabase effectively to track user progress across recordings and sessions.
Managed to deploy a fully working prototype with voice generation, audio comparison, and text memory tools — all in one place.
📚 What we learned The power of client-side preprocessing (like Pica) to improve UX without extra infrastructure.
ElevenLabs is incredibly natural — but requires smart control for repeated API calls.
Supabase makes full-stack deployment fast, but careful schema design is critical for scalability.
Building for speech means considering not only audio quality, but human behavior (breathing, hesitation, tone).
Creating something useful is not just about tech — it's about simplicity, clarity, and emotional safety for users.
🚀 What's next for FitAttention 🧠 Add spaced repetition scheduling to optimize memory retention.
🤖 Train a local model to provide smart feedback without API costs.
📱 Build a mobile-native version with offline mode and push notifications.
🗣️ Add gesture & posture detection via webcam to coach full body expression.
🧑🤝🧑 Enable sharing and peer feedback for collaborative rehearsal.
🎤 Introduce event modes (for pitch, TEDx, slam, oral exams, therapy).
Built With
- bolt
- database
- dotenv
- elevenlabs-api
- expo-audio
- expo.io
- javascript
- meyda
- pica.js
- react-native-web
- storage)
- supabase-(auth
- tesseract.js
- typescript

Log in or sign up for Devpost to join the conversation.