-
-
Inference Page
-

-

Inspiration
We kept seeing those "rate my outfit" posts everywhere and wondered, what if you could skip the comment section and go straight to the brain? Not metaphorically. Literally map what happens in someone's visual cortex when they look at your clothes. Meta Research published TRIBEv2 earlier this year, a model that predicts fMRI brain activity from video stimuli. It was built for neuroscience research, but we thought: what if we pointed it at a webcam and let people see how their outfit registers in the average viewer's brain?
What it does
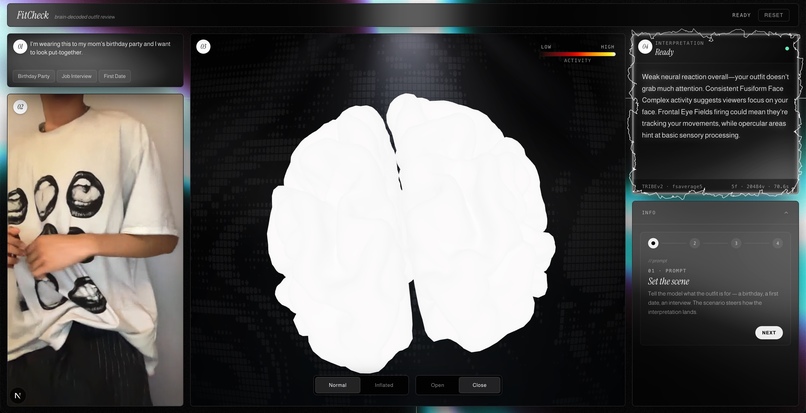
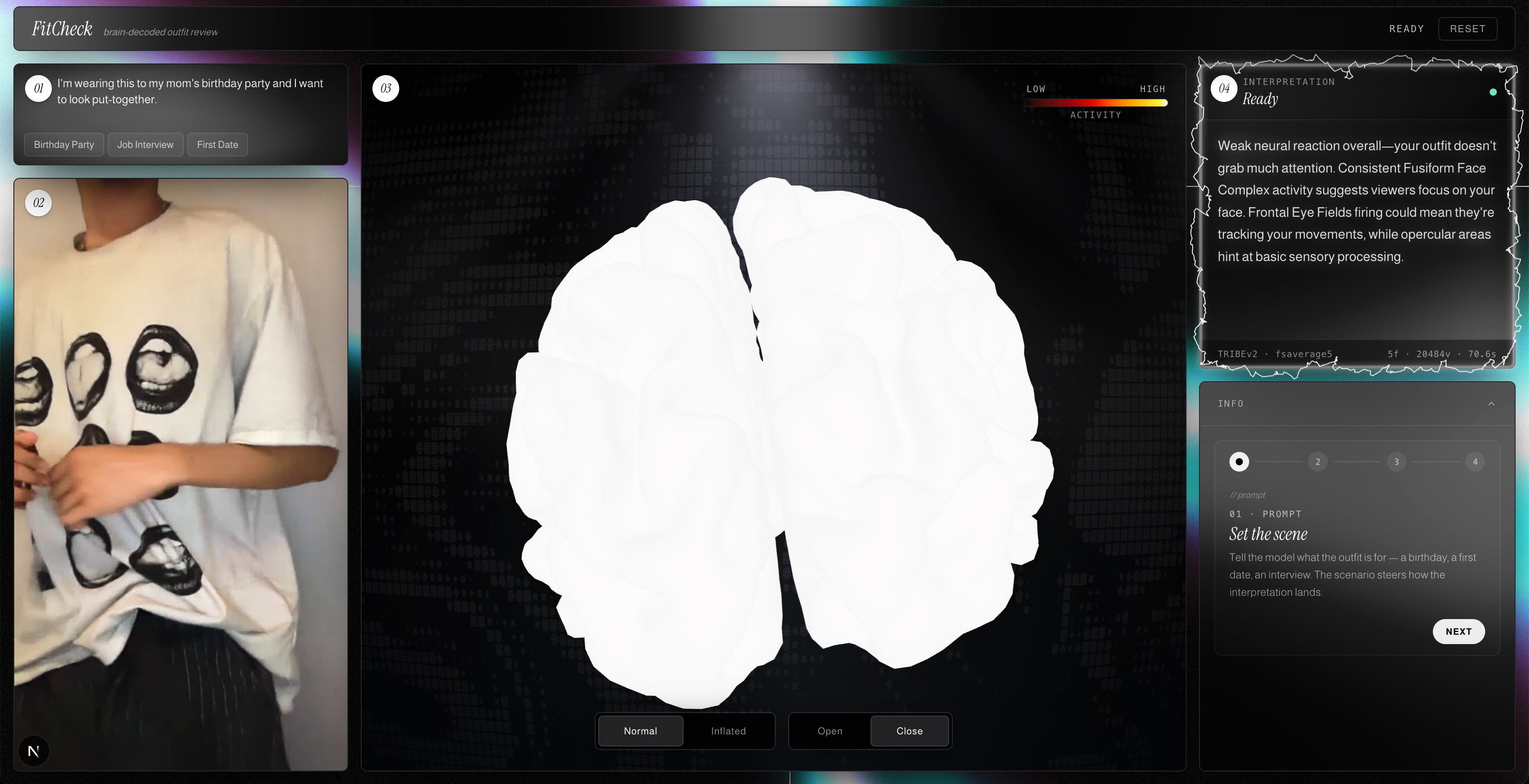
You open the app, type a scenario ("I'm going on a first date tonight"), hit record, and do a quick spin in front of your camera. The app sends your clip to TRIBEv2, which predicts what 20,484 points on the cortical surface would do if an average person watched your video. A 3D brain renders in the browser with hot regions glowing in real time, synced to your video playback. Then an LLM reads the activated regions and tells you what they could mean. "Strong activity in body-selective areas suggests people are noticing your silhouette."
The text you type actually matters. TRIBEv2 is multimodal. Your prompt gets split into words, distributed across the video timeline as Word events, and fed through Llama-3.2-3B's text encoder alongside the video features. "Job interview" and "beach party" activate different social cognition pathways, so the same outfit produces different brain maps depending on context.
How we built it
The backend is FastAPI on a RunPod GPU. TRIBEv2 loads at startup with V-JEPA2 (ViT-G) for video encoding and Llama-3.2-3B for text encoding. A single /analyze endpoint takes the video + prompt, builds a combined events DataFrame, and runs model.predict() under torch.autocast("cuda") for mixed precision inference.
The brain mesh is fsaverage5 — 10,242 vertices per hemisphere, packed into a custom binary format (we call it FTBM) with pial positions, inflated positions, sulcal depth, and a 256-entry fire colormap. One GET request, one blob, no glTF overhead.
On the frontend, Three.js renders the mesh with a custom vertex shader that samples a 2D texture atlas. The atlas packs the entire $T \times V$ prediction tensor (where $T$ is the number of time frames and $V = 20{,}484$ vertices) into a single RED/FLOAT DataTexture. The vertex shader computes:
$$\text{vStat} = \text{mix}\big(\text{tex}(f_0 \cdot V + \text{id}),; \text{tex}(f_1 \cdot V + \text{id}),; \alpha\big)$$
where $f_0, f_1$ are floor/ceil frame indices and $\alpha$ is the fractional part, all driven by video.currentTime every animation frame. The brain morphs continuously instead of jumping between timesteps.
Challenges
Encoding speed. V-JEPA2 ViT-G at fp32 took 6.2 seconds per frame. An 8-second recording meant a two-minute wait. We got it down to ~0.6s/frame with torch.autocast("cuda") and num_frames=32, cutting total inference from over a minute to about 15 seconds.
Built With
- bun
- fastapi
- featherless
- huggingface
- next
- react.js




Log in or sign up for Devpost to join the conversation.