-
Homepage
-
Homepage
-
Homepage
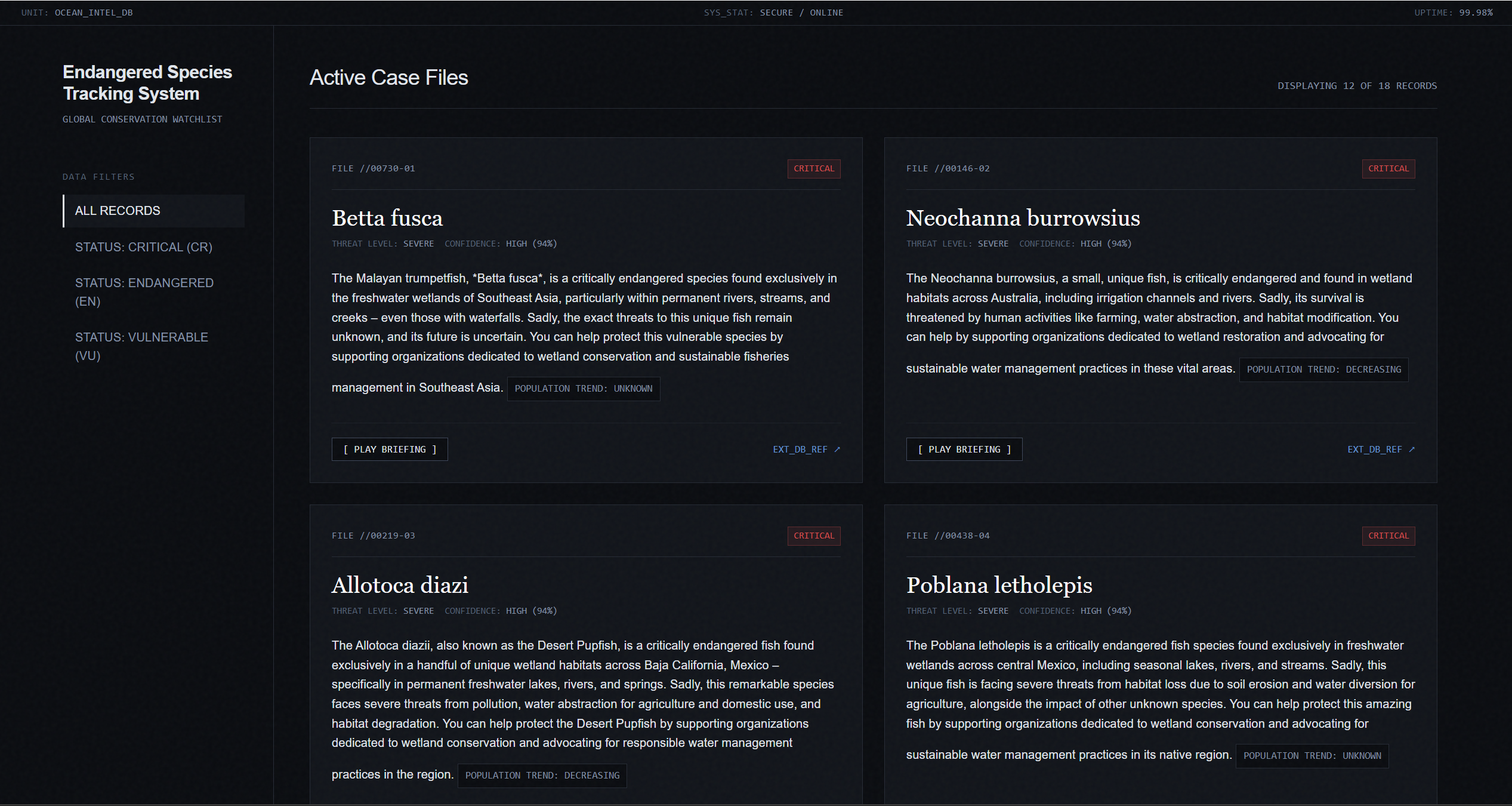
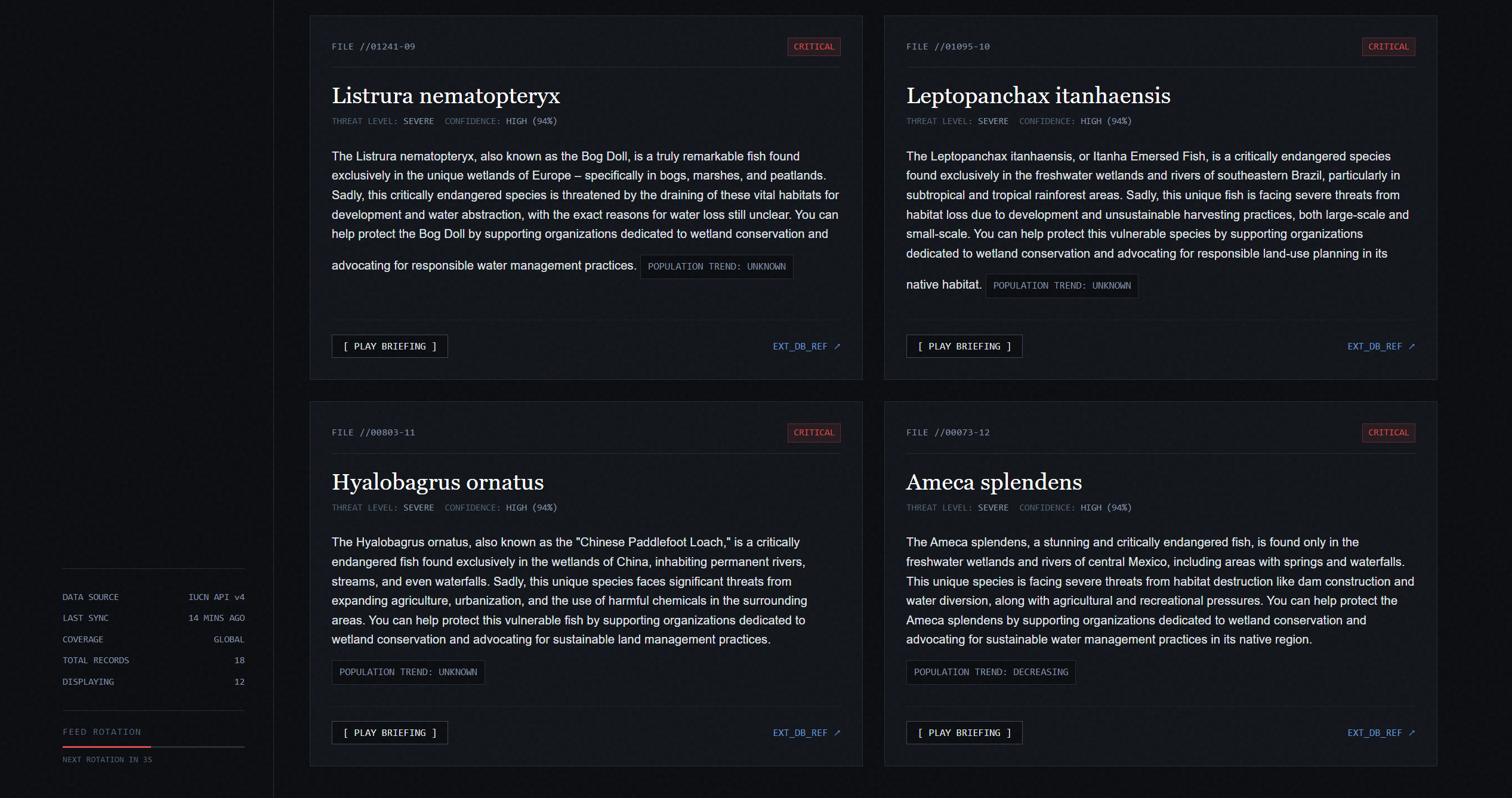
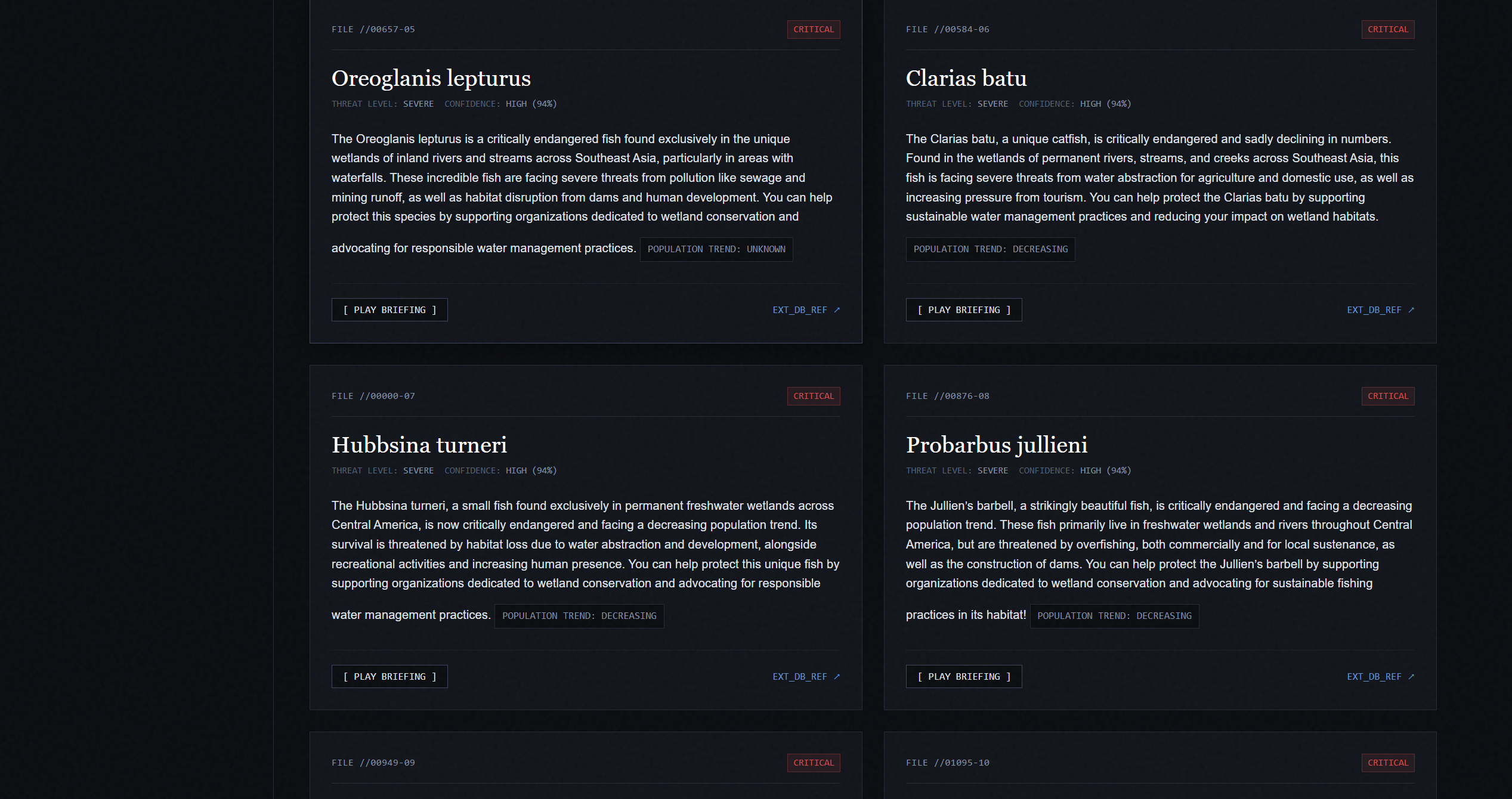
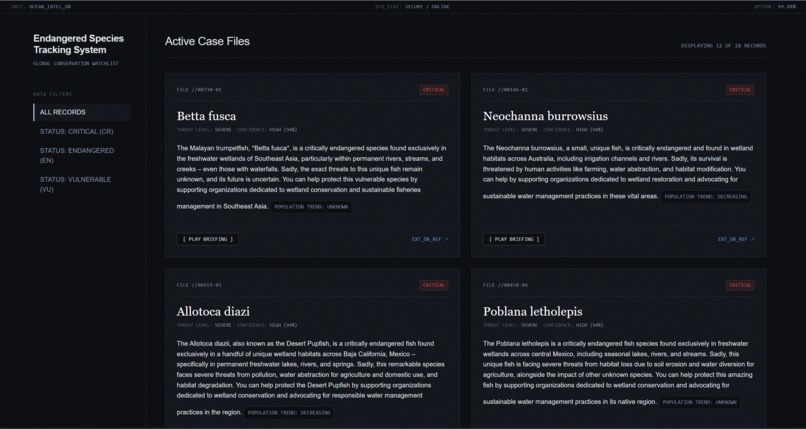
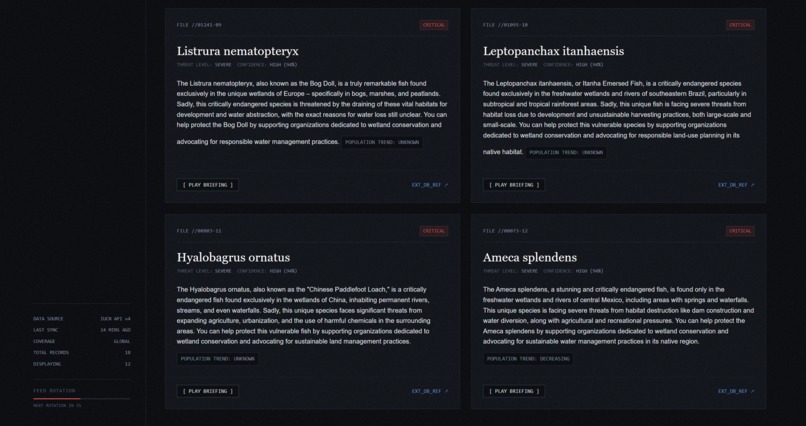
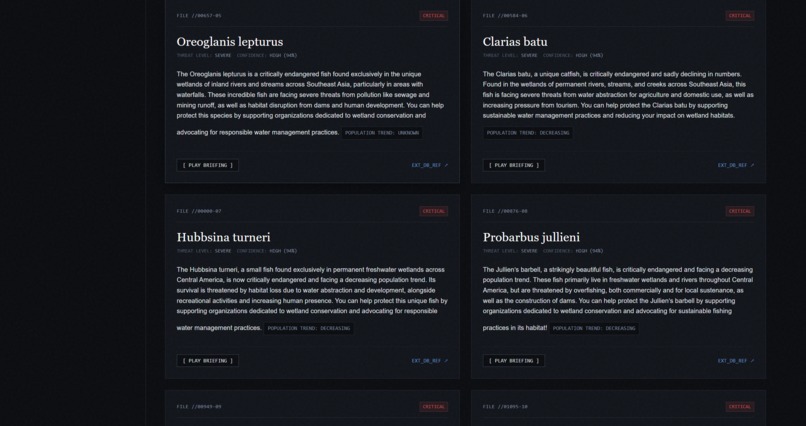
We were inspired because often times when we talk about ocean conservation we focus on land and coral reefs, whales and plastic pollution. Fish are actually one of the most ecologically important parts of aquatic ecosystems but are often overlooked. We built Fish Finder because we wanted to help our community understand the sheer scale of fish endangerment with real data and summaries. We think that fish aren’t just food, they are the backbone of our ecosystem.
Fishfinder pulls live data from the IUCN Red List using an API key. It’s the worlds most authoritative source about endangered species. Then we summarized the raw data with Gemma 4 to explain what each species is, where it lives and what threatens it. Each fish card includes a voice over using Eleven Labs so that users with disabilities or who can’t read can also listen instead of reading. We constantly rotates through the pool of fish so that users can learn about a full array of fish
We built the backend in Python with Flask, pulling fish data from the IUCN Red List API v4 across multiple fish classes including Actinopterygii and Elasmobranchii. Fish data is cached locally in a JSON file so the site loads instantly without spamming the API on every visit for efficiency. AI summaries are generated using Gemma 3 running locally through Ollama, meaning no cloud AI costs and no rate limits. Voice overs are generated through the ElevenLabs API. The site is was published using ngrok with a fishfinder.tech domain routed through Cloudflare.
We hit a lot of unexpected walls. Halfway through the project Google deprecated the Python package we were using for Gemini and replaced it with a completely different one with a new way of setting up the client, so our AI integration broke and we had to rewrite it. While we were figuring that out we burned through our free tier quota because every failed API call still counted against our daily limit. We ended up ditching Gemini entirely and running Gemma 3 locally through Ollama which meant no API keys and no quota at all. Getting our fishfinder.tech domain working was also a headache, ngrok's free plan doesn't support custom domains so we had to route traffic through Cloudflare using CNAME records and then wait hours for DNS to propagate.
We are proud of the way we structured the code so it makes it really easy to scale. Right now we scan a 15 pagges from the IUCN API and store the results in a local JSON file. To go from 12 fish to every endangered fish on the Red List we just change the page limit in our fetch script and nothing else needs to change. The summary generator, the voice system, and the rotating frontend feed all work independently so adding more data just works.
We learn to not trust that a library you're using today because there is no garuntee will work the same way tomorrow. Google changed their package and their authentication approach with not much warning and it cost us a lot of time.
We want to add an interactive map showing where each fish lives and where people can actually go to help We also want to expand the database scan to pull every endangered fish from the Red List and add filtering by region and threat type.


Log in or sign up for Devpost to join the conversation.