-
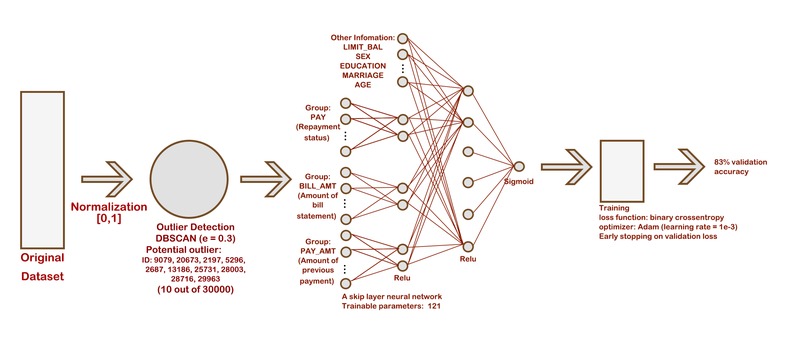
Machine Learning Model
-

Web Front-end & Back-end Model


Inspiration...
The Fiserv data made us very excited to use it! We wanted more experience in machine learning and this challenhe allowed us to do so :)
What it does...
The "frontend" that takes the input that the credit analyst puts in and sends that data to "middle man" and the "middle man" takes that data and turns it into a matrix that is then sent to the backend where pythons machine learning capabilities evaluated the data and outputs a number between 1 and 0 then sends that information back to the "middle man" which takes that number and decides whether or not the borrower with default or not( 1= yes if the returned number is greater than or equal to .5 and 0=no if number returned is the less than .5) than the output is sent to the frontend where it displays "[borrower name] is approved for credit" or "[borrower name] is not approved"
How I built it...
Import our data into Python by vectorizing the data. Simple normalization to make data look more clean and easy for the machine to process. We then used scikit-learn to detect outliers. After that, we used Tensorflow and Keras to build and train our machine learning model. Once we had a model, we then stored it in a h5 file.
Challenges I ran into...
1) Difficulty building a model that is compact and accurate. 2) Having platforms interact with each other. (e.g. Node.js and python)
Accomplishments that I'm proud of...
We together built an end-to-end complete web application.
What I learned...
We learned how to utilize each of our strengths and ideas to work better in a team. In addition, we learned many new technical skills in this challenge.
What's next for Fiserv's Credit Buster...
1) Refining the model and making it more accurate 2) Creating a more complete UI (loading button) and normalizing the data for the front end interface. 3) Hosting it in the cloud - so anyone can access!!
Built With
- express.js
- keras
- node.js
- python
- react
- scikit-learn
- tensorflow

Log in or sign up for Devpost to join the conversation.